Alignment as Aimability or as Goalcraft?
The Less Wrong and AI risk communities have obviously had a huge role in mainstreaming the concept of risks from artificial intelligence, but we have a serious terminology problem.
The term "AI Alignment" has become popular, but people cannot agree whether it means something like making "Good" AI or whether it means something like making "Aimable" AI. We can define the terms as follows:
AI Aimability = Create AI systems that will do what the creator/developer/owner/user intends them to do, whether or not that thing is good or bad
AI Goalcraft = Create goals for AI systems that we ultimately think lead to the best outcomes
Aimability is a relatively well-defined technical problem and in practice almost all of the technical work on AI Alignment is actually work on AI Aimability. Less Wrong has for a long time been concerned with Aimability failures (what Yudkowsky in the early days would have called "Technical Failures of Friendly AI") rather than failures of Goalcraft (old-school MIRI terminology would be "Friendliness Content").
The problem is that as the term "AI Alignment" has gained popularity, people have started to completely merge the definitions of Aimability and Goalcraft under the term "Alignment". I recently ran some Twitter polls on this subject, and it seems that people are relatively evenly split between the two definitions.
This is a relatively bad state of affairs. We should not have the fate of the universe partially determined by how people interpret an ambiguous word.
In particular, the way we are using the term AI Alignment right now means that it's hard to solve the AI Goalcraft problem and easy to solve the Aimability problem, because there is a part of AI that is distinct from Aimability which the current terminology doesn't have a word for.
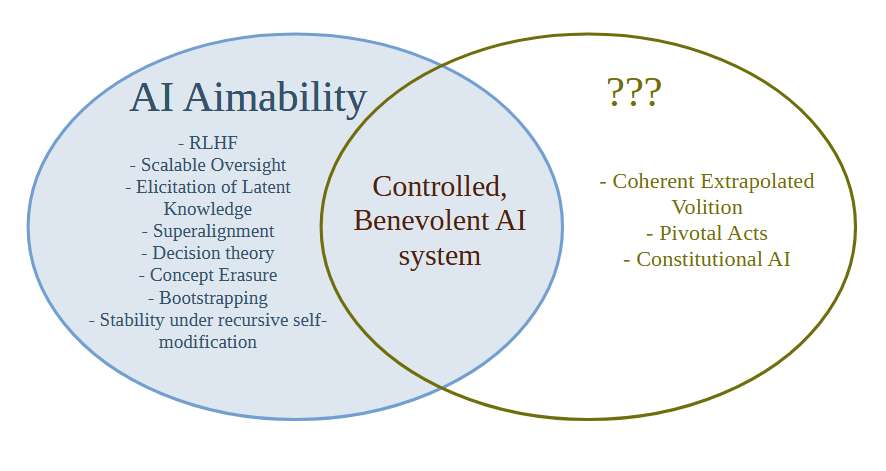
Not having a word for what goals to give the most powerful AI system in the universe is certainly a problem, and it means that everyone will be attracted to the easier Aimability research where one can quickly get stuck in and show a concrete improvement on a metric and publish a paper.
Why doesn't the Less Wrong / AI risk community have good terminology for the right hand side of the diagram? Well, this (I think) goes back to a decision by Eliezer from the SL4 mailing list days that one should not discuss what the world would be like after the singularity, because a lot of time would be wasted arguing about politics, instead of the then more urgent problem of solving the AI Aimability problem (which was then called the control problem). At the time this decision was probably correct, but times have changed. There are now quite a few people working on Aimability, and far more are surely to come, and it also seems quite likely (though not certain) that Eliezer was wrong about how hard Aimability/Control actually is.
Words Have Consequences
This decision to not talk about AI goals or content might eventually result in some unscrupulous actors getting to define the actual content and goals of superintelligence, cutting the X-risk and LW community out of the only part of the AI saga that actually matters in the end. For example, the recent popularity of the e/acc movement has been associated with the Landian strain of AI goal content - acceleration towards a deliberate and final extermination of humanity, in order to appease the Thermodynamic God. And the field that calls itself AI Ethics has been tainted with extremist far-left ideology around DIE (Diversity, Inclusion and Equity) that is perhaps even more frightening than the Landian Accelerationist strain. By not having mainstream terminology for AI goals and content, we may cede the future of the universe to extremists.
I suggest the term "AI Goalcraft" for the study of which goals for AI systems we ultimately think lead to the best outcomes. The seminal work on AI Goalcraft is clearly Eliezer's Coherent Extrapolated Volition, and I think we need to push that agenda further now that AI risk has been mainstreamed and there's a lot of money going into the Aimability/Control problem.
Gud Car Studies
What should we do with the term "Alignment" though? I'm not sure. I think it unfortunately leads people into confusion. It doesn't track the underlying reality - which I believe is that action naturally factors into Goalcraft followed by Aimability, and you can work on Aimability without knowing much about Goalcraft and vice-versa because the mechanisms of Aimability don't care much about what goal one is aiming at, and the structure of Goalcraft doesn't care much about how you're going to aim at the goal and stay on target. When people hear "Aligned" they just hear "Good", but with a side order of sophistication. It would be like if we lumped mechanical engineers who developed car engines in with computer scientists working on GPS navigators and called their field Gud Car Studies. Gud Car Studies is obviously an abomination of a term that doesn't properly reflect the underlying reality that designing a good engine is mostly independent of deciding where to drive the car to, and how to navigate there. I think that "Alignment" has unfortunately become the "Gud Car Studies" of our time.
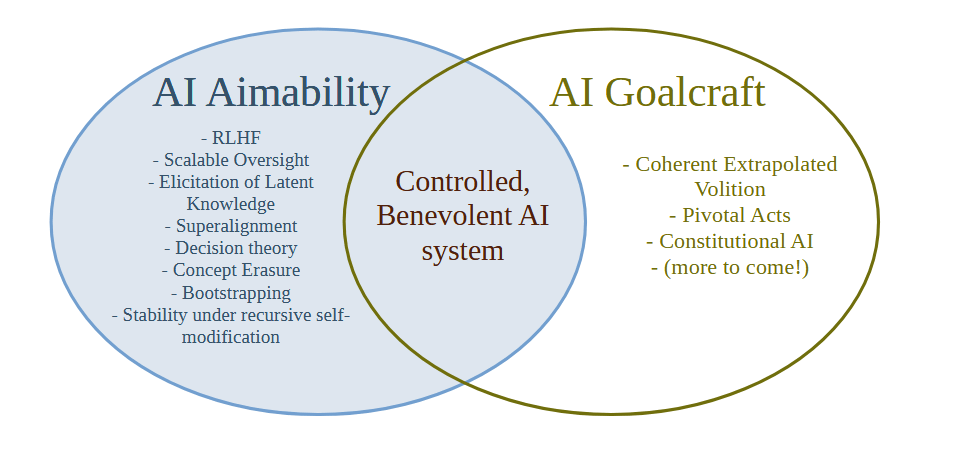
I'm at a loss as to what to do - I suspect that the term AI Alignment has already gotten away from us and we should stop using it and talk about Aimability and Goalcraft instead.
This post is Crossposted at the EA Forum
Related: "Aligned" shouldn't be a synonym for "good"
I think it's a great idea to think about what you call goalcraft.
I see this problem as similar to the age-old problem of controlling power. I don't think ethical systems such as utilitarianism are a great place to start. Any academic ethical model is just an attempt to summarize what people actually care about in a complex world. Taking such a model and coupling that to an all-powerful ASI seems a highway to dystopia.
(Later edit: also, an academic ethical model is irreversible once implemented. Any goal which is static cannot be reversed anymore, since this will never bring the current goal closer. If an ASI is aligned to someone's (anyone's) preferences, however, the whole ASI could be turned off if they want it to, making the ASI reversible in principle. I think ASI reversibility (being able to switch it off in case we turn out not to like it) should be mandatory, and therefore we should align to human preferences, rather than an abstract philosophical framework such as utilitarianism.)
I think letting the random programmer that happened to build the ASI, or their no less random CEO or shareholders, determine what would happen to the world, is an equally terrible idea. They wouldn't need the rest of humanity for anything anymore, making the fates of >99% of us extremely uncertain, even in an abundant world.
What I would be slightly more positive about is aggregating human preferences (I think preferences is a more accurate term than the more abstract, less well defined term values). I've heard two interesting examples, there are no doubt a lot more options. The first is simple: query chatgpt. Even this relatively simple model is not terrible at aggregating human preferences. Although a host of issues remain, I think using a future, no doubt much better AI for preference aggregation is not the worst option (and a lot better than the two mentioned above). The second option is democracy. This is our time-tested method of aggregating human preferences to control power. For example, one could imagine an AI control council consisting of elected human representatives at the UN level, or perhaps a council of representative world leaders. I know there is a lot of skepticism among rationalists on how well democracy is functioning, but this is one of the very few time tested aggregation methods we have. We should not discard it lightly for something that is less tested. An alternative is some kind of unelected autocrat (e/autocrat?), but apart from this not being my personal favorite, note that (in contrast to historical autocrats), such a person would also in no way need the rest of humanity anymore, making our fates uncertain.
Although AI and democratic preference aggregation are the two options I'm least negative about, I generally think that we are not ready to control an ASI. One of the worst issues I see is negative externalities that only become clear later on. Climate change can be seen as a negative externality of the steam/petrol engine. Also, I'm not sure a democratically controlled ASI would necessarily block follow-up unaligned ASIs (assuming this is at all possible). In order to be existentially safe, I would say that we would need a system that does at least that.
I think it is very likely that ASI, even if controlled in the least bad way, will cause huge externalities leading to a dystopia, environmental disasters, etc. Therefore I agree with Nathan above: "I expect we will need to traverse multiple decades of powerful AIs of varying degrees of generality which are under human control first. Not because it will be impossible to create goal-pursuing ASI, but because we won't be sure we know how to do so safely, and it would be a dangerously hard to reverse decision to create such. Thus, there will need to be strict worldwide enforcement (with the help of narrow AI systems) preventing the rise of any ASI."
About terminology, it seems to me that what I call preference aggregation, outer alignment, and goalcraft mean similar things, as do inner alignment, aimability, and control. I'd vote for using preference aggregation and control.
Finally, I strongly disagree with calling diversity, inclusion, and equity "even more frightening" than someone who's advocating human extinction. I'm sad on a personal level that people at LW, an otherwise important source of discourse, seem to mostly support statements like this. I do not.
As I understand it, the distinction is that "Goalcraft" is the problem of deciding what we want, while Outer Alignment is the problem of encoding that goal into the reward function of a Reinforcement Learning process.So they're at different abstraction levels, or steps in the process.