

Alignment as Aimability or as Goalcraft?
The Less Wrong and AI risk communities have obviously had a huge role in mainstreaming the concept of risks from artificial intelligence, but we have a serious terminology problem.
The term "AI Alignment" has become popular, but people cannot agree whether it means something like making "Good" AI or whether it means something like making "Aimable" AI. We can define the terms as follows:
AI Aimability = Create AI systems that will do what the creator/developer/owner/user intends them to do, whether or not that thing is good or bad
AI Goalcraft = Create goals for AI systems that we ultimately think lead to the best outcomes
Aimability is a relatively well-defined technical problem and in practice almost all of the technical work on AI Alignment is actually work on AI Aimability. Less Wrong has for a long time been concerned with Aimability failures (what Yudkowsky in the early days would have called "Technical Failures of Friendly AI") rather than failures of Goalcraft (old-school MIRI terminology would be "Friendliness Content").
The problem is that as the term "AI Alignment" has gained popularity, people have started to completely merge the definitions of Aimability and Goalcraft under the term "Alignment". I recently ran some Twitter polls on this subject, and it seems that people are relatively evenly split between the two definitions.
This is a relatively bad state of affairs. We should not have the fate of the universe partially determined by how people interpret an ambiguous word.
In particular, the way we are using the term AI Alignment right now means that it's hard to solve the AI Goalcraft problem and easy to solve the Aimability problem, because there is a part of AI that is distinct from Aimability which the current terminology doesn't have a word for.
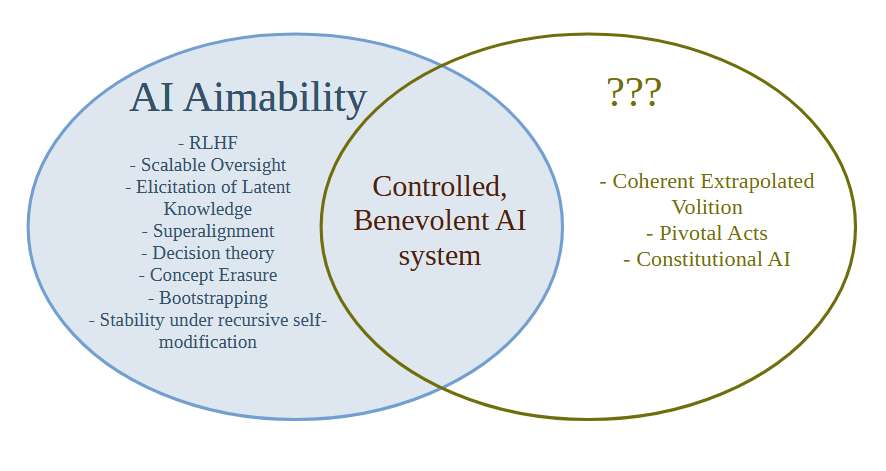
Not having a word for what goals to give the most powerful AI system in the universe is certainly a problem, and it means that everyone will be attracted to the easier Aimability research where one can quickly get stuck in and show a concrete improvement on a metric and publish a paper.
Why doesn't the Less Wrong / AI risk community have good terminology for the right hand side of the diagram? Well, this (I think) goes back to a decision by Eliezer from the SL4 mailing list days that one should not discuss what the world would be like after the singularity, because a lot of time would be wasted arguing about politics, instead of the then more urgent problem of solving the AI Aimability problem (which was then called the control problem). At the time this decision was probably correct, but times have changed. There are now quite a few people working on Aimability, and far more are surely to come, and it also seems quite likely (though not certain) that Eliezer was wrong about how hard Aimability/Control actually is.
Words Have Consequences
This decision to not talk about AI goals or content might eventually result in some unscrupulous actors getting to define the actual content and goals of superintelligence, cutting the X-risk and LW community out of the only part of the AI saga that actually matters in the end. For example, the recent popularity of the e/acc movement has been associated with the Landian strain of AI goal content - acceleration towards a deliberate and final extermination of humanity, in order to appease the Thermodynamic God. And the field that calls itself AI Ethics has been tainted with extremist far-left ideology around DIE (Diversity, Inclusion and Equity) that is perhaps even more frightening than the Landian Accelerationist strain. By not having mainstream terminology for AI goals and content, we may cede the future of the universe to extremists.
I suggest the term "AI Goalcraft" for the study of which goals for AI systems we ultimately think lead to the best outcomes. The seminal work on AI Goalcraft is clearly Eliezer's Coherent Extrapolated Volition, and I think we need to push that agenda further now that AI risk has been mainstreamed and there's a lot of money going into the Aimability/Control problem.
Gud Car Studies
What should we do with the term "Alignment" though? I'm not sure. I think it unfortunately leads people into confusion. It doesn't track the underlying reality - which I believe is that action naturally factors into Goalcraft followed by Aimability, and you can work on Aimability without knowing much about Goalcraft and vice-versa because the mechanisms of Aimability don't care much about what goal one is aiming at, and the structure of Goalcraft doesn't care much about how you're going to aim at the goal and stay on target. When people hear "Aligned" they just hear "Good", but with a side order of sophistication. It would be like if we lumped mechanical engineers who developed car engines in with computer scientists working on GPS navigators and called their field Gud Car Studies. Gud Car Studies is obviously an abomination of a term that doesn't properly reflect the underlying reality that designing a good engine is mostly independent of deciding where to drive the car to, and how to navigate there. I think that "Alignment" has unfortunately become the "Gud Car Studies" of our time.
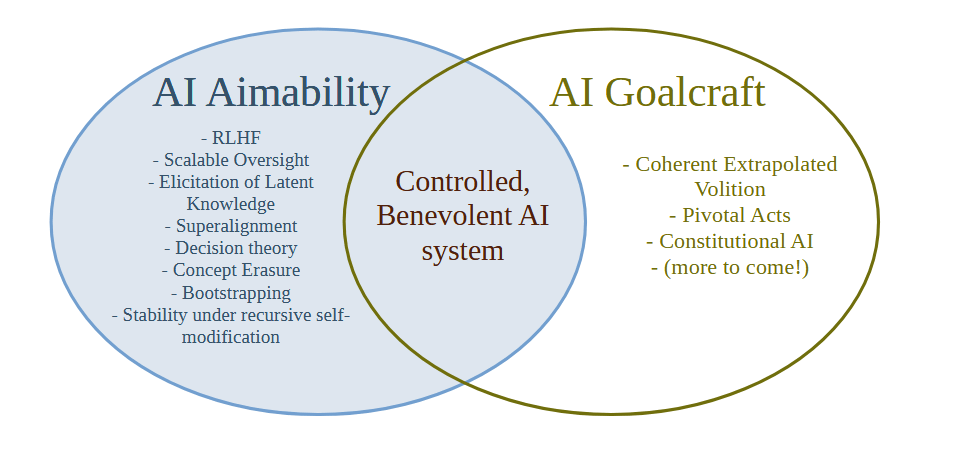
I'm at a loss as to what to do - I suspect that the term AI Alignment has already gotten away from us and we should stop using it and talk about Aimability and Goalcraft instead.
This post is Crossposted at the EA Forum
Related: "Aligned" shouldn't be a synonym for "good"
This is rather off-topic here, but for any AI that has an LLM as a component of it, I don't believe diamond-maximization is a hard problem, apart from Inner Alignment problems. The LLM knows the meaning of the word 'diamond' (GPT-4 defined it as "Diamond is a solid form of the element carbon with its atoms arranged in a crystal structure called diamond cubic. It has the highest hardness and thermal conductivity of any natural material, properties that are utilized in major industrial applications such as cutting and polishing tools. Diamond also has high optical dispersion, making it useful in jewelry as a gemstone that can scatter light in a spectrum of colors."). The LLM also knows its physical and optical properties, its social, industrial and financial value, its crystal structure (with images and angles and coordinates), what carbon is, its chemical properties, how many electrons, protons and neutrons a carbon atom can have, its terrestrial isotopic ratios, the half-life of carbon-14, what quarks a neutron is made of, etc. etc. etc. — where it fits in a vast network of facts about the world. Even if the AI also had some other very different internal world model and ontology, there's only going to be one "Rosetta Stone" optimal-fit mapping between the human ontology that the LLM has a vast amount of information about and any other arbitrary ontology, so there's more than enough information in that network of relationships to uniquely locate the concepts in that other ontology corresponding to 'diamond'. This is still true even if the other ontology is larger and more sophisticated: for example, locating Newtonian physics in relativistic quantum field theory and mapping a setup from the former to the latter isn't hard: its structure is very clearly just the large-scale low-speed limiting approximation.
The point where this gets a little more challenging is Outer Alignment, where you want to write a mathematical or pseudocode reward function for training a diamond optimizer using Reinforcement Learning (assuming our AI doesn't just have a terminal goal utility function slot that we can directly connect this function to, like AIXI): then you need to also locate the concepts in the other ontology for each element in something along the lines of "pessimizingly estimate the total number of moles of diamond (having at a millimeter-scale-average any isotopic ratio of C-12 to C-13 but no more than N1 times the average terrestrial proportion of C-14, discounting any carbon atoms within N2 C-C bonds of a crystal-structure boundary, or within N3 bonds of a crystal -structure dislocation, or within N4 bonds of a lattice substitution or vacancy, etc. …) at the present timeslice in your current rest frame inside the region of space within the future-directed causal lightcone of your creation, and subtract the answer for the same calculation in a counterfactual alternative world-history where you had permanently shut down immediately upon being created, but the world-history was otherwise unchanged apart from future causal consequences of that divergence". [Obviously this is a specification design problem, and the example specification above may still have bugs and/or omissions, but there will only be a finite number of these, and debugging this is an achievable goal, especially if you have a crystalographer, a geologist, and a jeweler helping you, and if a non-diamond-maximizing AI also helps by asking you probing questions. There are people whose jobs involve writing specifications like this, including in situations with opposing optimization pressure.]
As mentioned above, I fully acknowledge that this still leaves the usual Inner Alignment problems unsolved: applying Reinforcement Learning (or something similar such as Direct Preference Optimization) with this reward function to our AI, then how do we ensure that it actually becomes a diamond maximizer, rather than a biased estimator of diamond? I suspect we might want to look at some form of GAN, where the reward-estimating circuitry it not part of the Reinforcement Learning process, but is being trained in some other way. That still leaves the Inner Alignment problem of training a diamond maximizer instead of a hacker of reward model estimators.