This is a special post for quick takes by Alexander Gietelink Oldenziel. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
My mainline prediction scenario for the next decades.
My mainline prediction * :
- LLMs will not scale to AGI. They will not spawn evil gremlins or mesa-optimizers. BUT Scaling laws will continue to hold and future LLMs will be very impressive and make a sizable impact on the real economy and science over the next decade. EDIT: since there is a lot of confusion about this point. BY LLM I mean the paradigm of pre-trained transformers. This does not include different paradigms that follow pre-trained transformers but are still called large language models. EDIT2: since I'm already anticipating confusion on this point: when I say scaling laws will continue to hold that means that the 3-way relation between model size, compute, data will probably continue to hold. It has been known for a long time that amount of data used by gpt-4 level models is already within perhaps an OOM of the maximum. ]
- there is a single innovation left to make AGI-in-the-alex sense work, i.e. coherent, long-term planning agents (LTPA) that are effective and efficient in data sparse domains over long horizons.
- that innovation will be found within the next 10-15 years
- It will be clear to the general public that t
governments will act quickly and (relativiely) decisively to bring these agents under state-control. national security concerns will dominate.
I dunno, like 20 years ago if someone had said “By the time somebody creates AI that displays common-sense reasoning, passes practically any written test up including graduate-level, (etc.), obviously governments will be flipping out and nationalizing AI companies etc.”, to me that would have seemed like a reasonable claim. But here we are, and the idea of the USA govt nationalizing OpenAI seems a million miles outside the Overton window.
Likewise, if someone said “After it becomes clear to everyone that lab leaks can cause pandemics costing trillions of dollars and millions of lives, then obviously governments will be flipping out and banning the study of dangerous viruses—or at least, passing stringent regulations with intrusive monitoring and felony penalties for noncompliance etc,” then that would also have sounded reasonable to me! But again, here we are.
So anyway, my conclusion is that when I ask my intuition / imagination whether governments will flip out in thus-and-such circumstance, my intuition / imagination is really ba...
One strong reason to think the AI case might be different is that US national security will be actively using AI to build weapons and thus it will be relatively clear and salient to US national security when things get scary.
8
For one thing, COVID-19 obviously had impacts on military readiness and operations, but I think that fact had very marginal effects on pandemic prevention.
For another thing, I feel like there’s a normal playbook for new weapons-development technology, which is that the military says “Ooh sign me up”, and (in the case of the USA) the military will start using the tech in-house (e.g. at NRL) and they’ll also send out military contracts to develop the tech and apply it to the military. Those contracts are often won by traditional contractors like Raytheon, but in some cases tech companies might bid as well.
I can’t think of precedents where a tech was in wide use by the private sector but then brought under tight military control in the USA. Can you?
The closest things I can think of is secrecy orders (the US military gets to look at every newly-approved US patent and they can choose to declare them to be military secrets) and ITAR (the US military can declare that some area of tech development, e.g. certain types of high-quality IR detectors that are useful for night vision and targeting, can’t be freely exported, nor can their schematics etc. be shared with non-US citizens).
Like, I presume there are lots of non-US-citizens who work for OpenAI. If the US military were to turn OpenAI’s ongoing projects into classified programs (for example), those non-US employees wouldn’t qualify for security clearances. So that would basically destroy OpenAI rather than control it (and of course the non-USA staff would bring their expertise elsewhere). Similarly, if the military was regularly putting secrecy orders on OpenAI’s patents, then OpenAI would obviously respond by applying for fewer patents, and instead keeping things as trade secrets which have no normal avenue for military review.
By the way, fun fact: if some technology or knowledge X is classified, but X is also known outside a classified setting, the military deals with that in a very strange way: people with cl
2
'when things get scary' when then?
2
Registering that it does not seem that far out the Overton window to me anymore. My own advance prediction of how much governments would be flipping out around this capability level has certainly been proven a big underestimate.
I think this will look a bit outdated in 6-12 months, when there is no longer a clear distinction between LLMs and short term planning agents, and the distinction between the latter and LTPAs looks like a scale difference comparable to GPT2 vs GPT3 rather than a difference in kind. At what point do you imagine a national government saying "here but no further?".
1
So you are predicting that within 6-12 months, there will no longer be a clear distinction between LLMs and "short term planning agents". Do you mean that agentic LLM scaffolding like Auto-GPT will qualify as such?
I think scaffolding is the wrong metaphor. Sequences of actions, observations and rewards are just more tokens to be modeled, and if I were running Google I would be busy instructing all work units to start packaging up such sequences of tokens to feed into the training runs for Gemini models. Many seemingly minor tasks (e.g. app recommendation in the Play store) either have, or could have, components of RL built into the pipeline, and could benefit from incorporating LLMs, either by putting the RL task in-context or through fine-tuning of very fast cheap models.
So when I say I don't see a distinction between LLMs and "short term planning agents" I mean that we already know how to subsume RL tasks into next token prediction, and so there is in some technical sense already no distinction. It's a question of how the underlying capabilities are packaged and deployed, and I think that within 6-12 months there will be many internal deployments of LLMs doing short sequences of tasks within Google. If that works, then it seems very natural to just scale up sequence length as generalisation improves.
Arguably fine-tuning a next-token predictor on action, observation, reward sequences, or doing it in-context, is inferior to using algorithms like PPO. However, the advantage of knowledge transfer from the rest of the next-token predictor's data distribution may more than compensate for this on some short-term tasks.
3
I think o1 is a partial realization of your thesis, and the only reason it's not more successful is because the compute used for GPT-o1 and GPT-4o were essentially the same:
https://www.lesswrong.com/posts/bhY5aE4MtwpGf3LCo/openai-o1
And yeah, the search part was actually quite good, if a bit modest in it's gains.
8
As far as I can tell Strawberry is proving me right: it's going beyond pre-training and scales inference - the obvious next step.
A lot of people said just scaling pre-trained transformers would scale to AGI. I think that's silly and doesn't make sense. But now you don't have to believe me - you can just use OpenAIs latest model.
The next step is to do efficient long-horizon RL for data-sparse domains.
Strawberry working suggest that this might not be so hard. Don't be fooled by the modest gains of Strawberry so far. This is a new paradigm that is heading us toward true AGI and superintelligence.
8
Yeah actually Alexander and I talked about that briefly this morning. I agree that the crux is "does this basic kind of thing work" and given that the answer appears to be "yes" we can confidently expect scale (in both pre-training and inference compute) to deliver significant gains.
I'd love to understand better how the RL training for CoT changes the representations learned during pre-training.
in my reading, Strawberry is showing that indeed scaling just pretraining transformers will *not* lead to AGI. The new paradigm is inference-scaling - the obvious next step is doing RL on long horizons and sparse data domains. I have been saying this ever since gpt-3 came out.
For the question of general intelligence imho the scaling is conceptually a red herring: any (general purpose) algorithm will do better when scaled. The key in my mind is the algorithm not the resource, just like I would say a child is generally intelligent while a pocket calculator is not even if the child can't count to 20 yet. It's about the meta-capability to learn not the capability.
As we spoke earlier - it was predictable that this was going to be the next step. It was likely it was going to work, but there was a hopeful world in which doing the obvious thing turned out to be harder. That hope has been dashed - it suggests longer horizons might be easy too. This means superintelligence within two years is not out of the question.
2
We have been shown that this search algorithm works, and we not yet have been shown that the other approaches don't work.
Remember, technological development is disjunctive, and just because you've shown that 1 approach works, doesn't mean that we have been shown that only that approach works.
Of course, people will absolutely try to scale this one up now that they found success, and I think that timelines have definitely been shortened, but remember that AI progress is closer to a disjunctive scenario than conjunctive scenario:
I agree with this quote below, but I wanted to point out the disjunctiveness of AI progress:
https://gwern.net/forking-path
4
strong disagree. i would be highly surprised if there were multiple essentially different algorithms to achieve general intelligence*.
I also agree with the Daniel Murfet's quote. There is a difference between a disjunction before you see the data and a disjunction after you see the data. I agree AI development is disjunctive before you see the data - but in hindsight all the things that work are really minor variants on a single thing that works.
*of course "essentially different" is doing a lot of work here. some of the conceptual foundations of intelligence haven't been worked out enough (or Vanessa has and I don't understand it yet) for me to make a formal statement here.
2
Re different algorithms, I actually agree with both you and Daniel Murfet in that conditional on non-reversible computers, there is at most 1-3 algorithms to achieve intelligence that can scale arbitrarily large, and I'm closer to 1 than 3 here.
But once reversible computers/superconducting wires are allowed, all bets are off on how many algorithms are allowed, because you can have far, far more computation with far, far less waste heat leaving, and a lot of the design of computers is due to heat requirements.
2
Reversible computing and superconducting wires seem like hardware innovations. You are saying that this will actually materially change the nature of the algorithm you'd want to run?
I'd bet against. I'd be surprised if this was the case. As far as I can tell everything we have so seen so far points to a common simple core of general intelligence algorithm (basically an open-loop RL algorithm on top of a pre-trained transformers). I'd be surprised if there were materially different ways to do this. One of the main takeaways of the last decade of deep learning process is just how little architecture matters - it's almost all data and compute (plus I claim one extra ingredient, open-loop RL that is efficient on long horizons and sparse data novel domains)
I don't know for certain of course. If I look at theoretical CS though the universality of computation makes me skeptical of radically different algorithms.
I'm a bit confused by what you mean by "LLMs will not scale to AGI" in combination with "a single innovation is all that is needed for AGI".
E.g., consider the following scenarios:
- AGI (in the sense you mean) is achieved by figuring out a somewhat better RL scheme and massively scaling this up on GPT-6.
- AGI is achieved by doing some sort of architectural hack on top of GPT-6 which makes it able to reason in neuralese for longer and then doing a bunch of training to teach the model to use this well.
- AGI is achieved via doing some sort of iterative RL/synth data/self-improvement process for GPT-6 in which GPT-6 generates vast amounts of synthetic data for itself using various tools.
IMO, these sound very similar to "LLMs scale to AGI" for many practical purposes:
- LLM scaling is required for AGI
- LLM scaling drives the innovation required for AGI
- From the public's perspective, it maybe just looks like AI is driven by LLMs getting better over time and various tweaks might be continuously introduced.
Maybe it is really key in your view that the single innovation is really discontinuous and maybe the single innovation doesn't really require LLM scaling.
I think a single innovation left to create LTPA is unlikely because it runs contrary to the history of technology and of machine learning. For example, in the 10 years before AlphaGo and before GPT-4, several different innovations were required-- and that's if you count "deep learning" as one item. ChatGPT actually understates the number here because different components of the transformer architecture like attention, residual streams, and transformer++ innovations were all developed separately.
2
I mostly regard LLMs = [scaling a feedforward network on large numbers of GPUs and data] as a single innovation.
Then I think you should specify that progress within this single innovation could be continuous over years and include 10+ ML papers in sequence each developing some sub-innovation.
6
Agreed on all points except a couple of the less consequential, where I don't disagree.
Strongest agreement: we're underestimating the importance of governments for alignment and use/misuse. We haven't fully updated from the inattentive world hypothesis. Governments will notice the importance of AGI before it's developed, and will seize control. They don't need to nationalize the corporations, they just need to have a few people embedded at theh company and demand on threat of imprisonment that they're kept involved with all consequential decisions on its use. I doubt they'd even need new laws, because the national security implications are enormous. But if they need new laws, they'll create them as rapidly as necessary. Hopping borders will be difficult, and just put a different government in control.
Strongest disagreement: I think it's likely that zero breakthroughs are needed to add long term planning capabilities to LLM-based systems, and so long term planning agents (I like the terminology) will be present very soon, and improve as LLMs continue to improve. I have specific reasons for thinking this. I could easily be wrong, but I'm pretty sure that the rational stance is "maybe". This maybe advances the timelines dramatically.
Also strongly agree on AGI as a relatively discontinuous improvement; I worry that this is glossed over in modern "AI safety" discussions, causing people to mistake controlling LLMs for aligning the AGIs we'll create on top of them. AGI alignment requires different conceptual work.
2
Do you think the final big advance happens within or with-out labs?
4
Probably within.
1
So somebody gets an agent which efficiently productively indefinitely works on any specified goal, then they just let the government find out and take it? No countermeasures?
1
What "coherent, long-term planning agents" means, and what is possible with these agents, is not clear to me. How would they overcome lack of access to knowledge, as was highlighted by F.A. Hayek in "The Use of Knowledge in Society"? What actions would they plan? How would their planning come to replace humans' actions? (Achieving control over some sectors of battlefields would only be controlling destruction, of course, it would not be controlling creation.)
Some discussion is needed that recognizes and takes into account differences among governance structures. What seems the most relevant to me are these cases: (1) totalitarian governments, (2) somewhat-free governments, (3) transnational corporations, (4) decentralized initiatives. This is a new kind of competition, but the results will be like with major wars: Resilient-enough groups will survive the first wave or new groups will re-form later, and ultimately the competition will be won by the group that outproduces the others. In each successive era, the group that outproduces the others will be the group that leaves people the freest.
John wrote an explosive postmortem on the alignment field, boldy proclaiming that almost all alignment research is trash. John held the ILIAD conference [which I helped organize] as one of the few examples of places where research is going in the right direction. While I share some of his concerns about the field's trajectory, and I am flattered that ILIAD was appreciated, I feel ambivalent about ILIAD being pulled into what I can only describe as an alignment culture war.
There's plenty to criticise about mainstream alignment research but blanket dismissals feel silly to me? Sparse auto-encoders are exciting! Research on delegated oversight & safety-by-debate is vitally important. Scary demos isn't exciting as Deep Science but its influence on policy is probably much greater than that long-form essay on conceptual alignment. AI psychology doesn't align with a physicist's aesthetic but as alignment is ultimately about attitudes of artifical intelligences maybe just talking with Claude about his feelings might prove valuable. There's lots of experimental work in mainstream ML on deep learning that will be key to constructing a grounded theory of deep learning. And I'm sure ...
I think that there are two key questions we should be asking:
- Where is the value of a an additional researcher higher on the margin?
- What should the field look like in order to make us feel good about the future?
I agree that "prosaic" AI safety research is valuable. However, at this point it's far less neglected than foundational/theoretical research and the marginal benefits there are much smaller. Moreover, without significant progress on the foundational front, our prospects are going to be poor, ~no matter how much mech-interp and talking to Claude about feelings we will do.
John has a valid concern that, as the field becomes dominated by the prosaic paradigm, it might become increasingly difficult to get talent and resources to the foundational side, or maintain memetically healthy coherent discourse. As to the tone, I have mixed feelings. Antagonizing people is bad, but there's also value in speaking harsh truths the way you see them. (That said, there is room in John's post for softening the tone without losing much substance.)
Scary demos isn't exciting as Deep Science but its influence on policy
There maybe should be a standardly used name for the field of generally reducing AI x-risk, which would include governance, policy, evals, lobbying, control, alignment, etc., so that "AI alignment" can be a more narrow thing. I feel (coarsely speaking) grateful toward people working on governance, policy, evals_policy, lobbying; I think control is pointless or possibly bad (makes things look safer than they are, doesn't address real problem); and frustrated with alignment.
What's concerning is watching a certain strain of dismissiveness towards mainstream ideas calcify within parts of the rationalist ecosystem. As Vanessa notes in her comment, this attitude of isolation and attendant self-satisfied sense of superiority certainly isn't new. It has existed for a while around MIRI & the rationalist community. Yet it appears to be intensifying as AI safety becomes more mainstream and the rationalist community's relative influence decreases
What should one do, who:
- thinks that there's various specific major defeaters to the narrow project of understanding how to align AGI;
- finds partial consensus with some o
5
What is a defeater and can you give some examples ?
A thing that makes alignment hard / would defeat various alignment plans or alignment research plans.
E.g.s: https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities#Section_B_
E.g. the things you're studying aren't stable under reflection.
E.g. the things you're studying are at the wrong level of abstraction (SLT, interp, neuro) https://www.lesswrong.com/posts/unCG3rhyMJpGJpoLd/koan-divining-alien-datastructures-from-ram-activations
E.g. https://tsvibt.blogspot.com/2023/03/the-fraught-voyage-of-aligned-novelty.html
This just in: Alignment researchers fail to notice skulls from famous blog post "Yes, we have noticed the skulls".
2
"E.g. the things you're studying are at the wrong level of abstraction (SLT, interp, neuro)"
Let's hear it. What do you mean here exactly?
4
From the linked post:
2
You'll have to be a little more direct to get your point across I fear.
I am sensing you think mechinterp, SLT, and neuroscience aren't at a high enough level of abstraction. I am curious why you think so and would benefit from understanding more clearly what you are proposing instead.
They aren't close to the right kind of abstraction. You can tell because they use a low-level ontology, such that mental content, to be represented there, would have to be homogenized, stripped of mental meaning, and encoded. Compare trying to learn about arithmetic, and doing so by explaining a calculator in terms of transistors vs. in terms of arithmetic. The latter is the right level of abstraction; the former is wrong (it would be right if you were trying to understand transistors or trying to understand some further implementational aspects of arithmetic beyond the core structure of arithmetic).
What I'm proposing instead, is theory.
6
I think I disagree, or need some clarification. As an example, the phenomenon in question is that the physical features of children look more or less like combinations of the parents features. Is the right kind of abstraction a taxonomy and theory of physical features at the level of nose-shapes and eyebrow thickness? Or is it at the low-level ontology of molecules and genes, or is it in the understanding of how those levels relate to eachother?
Or is that not a good analogy?
9
I'm unsure whether it's a good analogy. Let me make a remark, and then you could reask or rephrase.
The discovery that the phenome is largely a result of the genome, is of course super important for understanding and also useful. The discovery of mechanically how (transcribe, splice, translate, enhance/promote/silence, trans-regulation, ...) the phenome is a result of the genome is separately important, and still ongoing. The understanding of "structurally how" characters are made, both in ontogeny and phylogeny, is a blob of open problems (evodevo, niches, ...). Likewise, more simply, "structurally what"--how to even think of characters. Cf. Günter Wagner, Rupert Riedl.
I would say the "structurally how" and "structurally what" is most analogous. The questions we want to answer about minds aren't like "what is a sufficient set of physical conditions to determine--however opaquely--a mind's effects", but rather "what smallish, accessible-ish, designable-ish structures in a mind can [understandably to us, after learning how] determine a mind's effects, specifically as we think of those effects". That is more like organology and developmental biology and telic/partial-niche evodevo (<-made up term but hopefully you see what I mean).
https://tsvibt.blogspot.com/2023/04/fundamental-question-what-determines.html
4
I suppose it depends on what one wants to do with their "understanding" of the system? Here's one AI safety case I worry about: if we (humans) don’t understand the lower-level ontology that gives rise to the phenomenon that we are more directly interested in (in this case I think thats something like an AI systems behavior/internal “mental” states - your "structurally what", if I'm understanding correctly, which to be honest I'm not very confident I am), then a sufficiently intelligent AI system that does understand that relationship will be able to exploit the extra degrees of freedom in the lower level ontology to our disadvantage, and we won’t be able to see it coming.
I very much agree that structurally what matters a lot, but that seems like half the battle to me.
I very much agree that structurally what matters a lot, but that seems like half the battle to me.
But somehow this topic is not afforded much care or interest. Some people will pay lip service to caring, others will deny that mental states exist, but either way the field of alignment doesn't put much force (money, smart young/new people, social support) toward these questions. This is understandable, as we have much less legible traction on this topic, but that's... undignified, I guess is the expression.
2
Even if you do understand the lower level, you couldn't stop such an adversarial AI from exploiting it, or exploiting something else, and taking control. If you understand the mental states (yeah, the structure), then maybe you can figure out how to make an AI that wants to not do that. In other words, it's not sufficient, and probably not necessary / not a priority.
1
Ok. How would this theory look like and how would it cache out into real world consequences ?
9
This is a derail. I can know that something won't work without knowing what would work. I don't claim to know something that would work. If you want my partial thoughts, some of them are here: https://tsvibt.blogspot.com/2023/09/a-hermeneutic-net-for-agency.html
In general, there's more feedback available at the level of "philosophy of mind" than is appreciated.
1
I think I am asking a very fair question.
What is the theory of change of your philosophy of mind caching out into something with real-world consequences ?
I.e. a training technique? Design principles? A piece of math ? Etc
5
All of those, sure? First you understand, then you know what to do. This is a bad way to do peacetime science, but seems more hopeful for
1. cruel deadline,
2. requires understanding as-yet-unconceived aspects of Mind.
No, you're derailing from the topic, which is the fact that the field of alignment keeps failing to even try to avoid / address major partial-consensus defeaters to alignment.
4
I'm confused why you are so confident in these "defeaters" by which I gather objection/counterarguments to certain lines of attack on the alignment problem.
E.g. I doubt it would be good if the alignment community would outlaw mechinterp/slt/ neuroscience just because of some vague intuition that they don't operate at the right abstraction.
Certainly, the right level of abstraction is a crucial concern but I dont think progress on this question will be made by blanket dismissals. People in these fields understand very well the problem you are pointing towards. Many people are thinking deeply how to resolve this issue.
why you are so confident in these "defeaters"
More than any one defeater, I'm confident that most people in the alignment field don't understand the defeaters. Why? I mean, from talking to many of them, and from their choices of research.
People in these fields understand very well the problem you are pointing towards.
I don't believe you.
if the alignment community would outlaw mechinterp/slt/ neuroscience
This is an insane strawman. Why are you strawmanning what I'm saying?
I dont think progress on this question will be made by blanket dismissals
Progress could only be made by understanding the problems, which can only be done by stating the problems, which you're calling "blanket dismissals".
8
Okay seems like the commentariat agrees I am too combative. I apologize if you feel strawmanned.
Feels like we got a bit stuck. When you say "defeater" what I hear is a very confident blanket dismissal. Maybe that's not what you have in mind.
7
Defeater, in my mind, is a failure mode which if you don't address you will not succeed at aligning sufficiently powerful systems.[1] It does not mean work outside of that focused on them is useless, but at some point you have to deal with the defeaters, and if the vast majority of people working towards alignment don't get them clearly, and the people who do get them claim we're nowhere near on track to find a way to beat the defeaters, then that is a scary situation.
This is true even if some of the work being done by people unaware of the defeaters is not useless, e.g. maybe it is successfully averting earlier forms of doom than the ones that require routing around the defeaters.
1. ^
Not best considered as an argument against specific lines of attack, but as a problem which if unsolved leads inevitably to doom. People with a strong grok of a bunch of these often think that way more timelines are lost to "we didn't solve these defeaters" than the problems being even plausibly addressed by the class of work being done by most of the field. This does unfortunately make it get used as (and feel like) an argument against those approaches by people who don't and don't claim to understand those approaches, but that's not the generator or important nature of it.
5
I say "AI x-safety" and "AI x-safety technical research". I potentially cut the "x-" to just "AI safety" or "AI safety technical research".
4
Alternative: "AI x-derisking"
4
"AI x-safety" seems ok. The "x-" is a bit opaque, and "safety" is vague, but I'll try this as my default.
(Including "technical" to me would exclude things like public advocacy.)
4
Yeah, I meant that I use "AI x-safety" to refer to the field overall and "AI x-safety technical research" to specifically refer to technical research in that field (e.g. alignment research).
(Sorry about not making this clear.)
1
I’ve often preferred a frame of ‘catastrophe avoidance’ over a frame of x-risk. This has a possible downside of people underfeeling the magnitude of risk, but also an upside of IMO feeling way more plausible. I think it’s useful to not need to win specific arguments about extinction, and also to not have some of the existential/extinction conflation happening in ‘x-‘.
6
FWIW this seems overall highly obfuscatory to me. Catastrophic clearly includes things like "A bank loses $500M" and that's not remotely the same as an existential catastrophe.
3
It’s much more the same than a lot of prosaic safety though, right?
Let me put it this way: If an AI can’t achieve catastrophe on that order of magnitude, it also probably cannot do something truly existential.
One of the issues this runs into is if a misaligned AI is playing possum, and so doesn’t attempt lesser catastrophes until it can pull off a true takeover. I nonetheless though think this framing points generally at the right type of work (understood that others may disagree of course)
Not confident, but I think that "AIs that cause your civilization problems" and "AIs that overthrow your civilization" may be qualitatively different kinds of AIs. Regardlesss, existential threats are the most important thing here, and we just have a short term ('x-risk') that refers to that work.
And anyway I think the 'catastrophic' term is already being used to obfuscate, as Anthropic uses it exclusively on their website / in their papers, literally never talking about extinction or disempowerment[1], and we shouldn't let them get away with that by also adopting their worse terminology.
- ^
(And they use the term 'existential' 3 times in oblique ways that barely count.)
2
Yes - the word 'global' is a minimum necessary qualification for referring to catastrophes of the type we plausibly care about - and even then, it is not always clear that something like COVID-19 was too small an event to qualify.
2
How about "AI outcomes"
2
Insufficiently catchy
2
perhaps. but my reasoning is something like -
better than "alignment": what's being aligned? outcomes should be (citation needed)
better than "ethics": how does one act ethically? by producing good outcomes (citation needed).
better than "notkilleveryoneism": I actually would prefer everyone dying now to everyone being tortured for a million years and then dying, for example, and I can come up with many other counterexamples - not dying is not the (fundamental) problem, achieving good things is the problem (and would produce not-dying).
might not work for deontologists. that seems fine to me, I float somewhere between virtue ethics and utilitarianism anyway.
perhaps there are more catchy words that could be used, though. hope to see someone suggest one someday.
2
[After I wrote down the thing, I became more uncertain about how much weight to give to it. Still, I think it's a valid consideration to have on your list of considerations.]
"AI alignment", "AI safety", "AI (X-)risk", "AInotkilleveryoneism", "AI ethics" came to be associated with somewhat specific categories of issues. When somebody says "we should work (or invest more or spend more) on AI {alignment,safety,X-risk,notkilleveryoneism,ethics}", they communicate that they are concerned about those issues and think that deliberate work on addressing those issues is required or otherwise those issues are probably not going to be addressed (to a sufficient extent, within relevant time, &c.).
"AI outcomes" is even broader/[more inclusive] than any of the above (the only step left to broaden it even further would be perhaps to say "work on AI being good" or, in the other direction, work on "technology/innovation outcomes") and/but also waters down the issue even more. Now you're saying "AI is not going to be (sufficiently) good by default (with various AI outcomes people having very different ideas about what makes AI likely not (sufficiently) good by default)".
----------------------------------------
It feels like we're moving in the direction of broadening our scope of consideration to (1) ensure we're not missing anything, and (2) facilitate coalition building (moral trade?). While this is valid, it risks (1) failing to operate on the/an appropriate level of abstraction, and (2) diluting our stated concerns so much that coalition building becomes too difficult because different people/groups endorsing stated concerns have their own interpretations/beliefs/value systems. (Something something find an optimum (but also be ready and willing to update where you think the optimum lies when situation changes)?)
4
but how would we do high intensity, highly focused research on something intentionally restructured to be an "AI outcomes" research question? I don't think this is pointless - agency research might naturally talk about outcomes in a way that is general across a variety of people's concerns. In particular, ethics and alignment seem like they're an unnatural split, and outcomes seems like a refactor that could select important problems from both AI autonomy risks and human agency risks. I have more specific threads I could talk about.
2
7
Why do you think it's uninformed? John specifically says that he's taking "this work is trash" as background and not trying to convince anyone who disagrees. It seems like because he doesn't try, you assume he doesn't have an argument?
I kinda think it was necessary. (In that, the thing ~needed to be written and "you should have written this with a lot less antagonism" is not a reasonable ask.)
4
1) "there are many worlds in which it is too late or fundamentally unable to deliver on its promise while prosaic alignment ideas do. And in worlds in which theory does bear fruit" - Yudkowsky had a post somewhere about you only getting to do one instance of deciding to act as if the world was like X. Otherwise you're no longer affecting our actual reality. I'm not describing this well at all, but I found the initial point quite persuasive.
2) Highly relevant LW post & concept: The Tale of Alice Almost: Strategies for Dealing With Pretty Good People. People like Yudkowsky and johnswentworth think that vanishingly few people are doing something that's genuinely helpful for reducing x-risk, and most people are doing things that are useless at best or actively harmful (by increasing capabilities) at worst. So how should they act towards those people? Well, as per the post, that depends on the specific goal:
The mainstream wins the war of ideas by default. So if you think everyone dies if the mainstream wins, then you must argue against the mainstream, right?
1
I'm curious what you think John's valid criticisms are. His piece is so hyperbolic that I have to consider all arguments presented there somewhat suspect by default.
Edit: Clearly people disagree with this sentiment. I invite (and will strongly upvote) strong rebuttals.
Highly recommended video on drone development in the Ukraine-Russia war, interview with a Russian private military drone developer.
some key takeaways
- Drones now account for >70% of kills on the battlefields.
- There are few to none effective counters to drones. The on
- Electronic jamming is a rare exception but drones carrying 5-15km fiber optic cables are immune to jamming. In the future AI-controlled drones will be immune to jamming.
- 'Laser is currently a joke. It works in theory, not in practice. Western demonstrations at expos are always in ideal conditions. ' but he also says that both Russia and Ukraine are actively working on the technology and he thinks it could be an effective weapon.
- Nets can be effective but fiber-optic drones can fly very low and not lose connection are increasingly used to slip under the nets.
- Soldiers are increasingly opting for bikes instead of vehicles as the latter don't offer much protection to drones.
- The big elephant in the room: AI drones.
- It seems like the obvious next step - why hasn't it happened yet?
- 'at Western military expos everybody is talking AI-controlled drones. This is nonsense of course' Apparently the limitation is that it's currentl
I second the video recommendation.
A friend in China, in a rare conversation we had about international politics, was annoyed at US politicians for saying China was "supporting" Russia. "China has the production capacity to make easily 500,000 drones per day.[1]", he said. "If China were supporting Russia, the war would be over". And I had to admit I had not credited the Chinese government for keeping its insanely competitive companies from smuggling more drones into Russia.
- ^
This seemed like a drastic underestimate to me.
Adding context/(kind-of) counter argument from reddit (the link has a link to the main article and contains a summary of it):
I think the comments are also worth a read. I want to share one particular comment here, which I think has a good explanation/hypothesis regarding the situation:
...The scaling up of FPV drones for the Ukrainians was definitely the result of artillery and mortar ammo shortages. But that can't be the only answer, as Russia never suffered that degree of shortage and they've gone as hardcore into FPV drones, if not more so, than the Ukrainians.
I think the biggest problem relying on artillery and mortars in THIS war is the ultra static nature of it. With the lines barely moving, it's very hard to create an artillery or mortar firing position that has decent survivability. Enemy recon drones, which can't be jammed or shot down easily (as most use freq hopping, fly at altitude, have limited radar signatures, etc), they are prowling the tactical rear areas. Since the start of the war, indirect fire has had to greatly disperse, especially artillery, which operate
4
Very interesting! But I'm not convinced. Some speculation to follow:
In a more dynamic war of maneuver, won't finding/locating your enemy be even more of an issue than it is today? If there are columns of friendly and enemy forces driving every which way in a hurried confusion, trying to exploit breakthroughs or counterattack, having "drone superiority" so that you can see where they are and they can't see where you are seems super important. OK, so that's an argument that air superiority drones will be crucial, but what about bomber drones vs. drone-corrected artillery? Currently bomber drones have something like 20km range compared to 40km range for artillery. Since they are quadcopters though I think that they'll quickly be supplanted by longer-ranged variants, e.g. fixed-wing drones. (Zipline's medical supply drones currently have 160km range) So I think there will be a type of future platform that's basically a pickup truck with a rail for launching fixed-wing bomber drones capable of taking out a tank. This truck will be to a self-propelled artillery piece what a carrier is to a battleship: Before the battleship/artillery gets in range, it'll be detected and obliterated by a concentrated airstrike launched from the carrier/truck. As a bonus the truck can also carry and launch air superiority drones too. Like the Pacific in WW2, most major battles will take place beyond artillery range, between flights of drones launched by groups of carriers/trucks. Oh, and yeah another advantage of the drone carriers vs. the artillery is that they are much, much cheaper & also can potentially take cover more easily (e.g. if your column of trucks is spotted, your men can get out and take the drones into the basements of nearby houses and continue to fight from there, whereas you can't hide your artillery in a basement.)
Also: The ultra static nature of the Russo-Ukrainian war is generally thought to be because of drones. The reason it's been a stalemate is that drones curren
8
https://youtu.be/tgkP0W7OvMc?si=hoa0l2mu5B6aRbpy
Perhaps of interest, 16:33 the guy mentions the development of a new type of drone resistant "turtle" tank
The YouTube channel was banned last week for being suspected propaganda because he used to work for state media channel RT. This is pretty sad to me because the content was very informative with slight if any pro Russia bias. AFAIK the only place he posts now is telegram https://t.me/RealReporter_tg
2
Oh wild. It's clearly propaganda. But also incredibly valuable information. itsThe West would so well to listen carefully to what adversaries are saying. They are certainly listening carefully to us!
Thanks for the alert Thomas. Subscribed.
1
Fucking campers, man.
Honestly not surprising, you'd need a mix of powerful but cheap chips and still quite light AI to make it work on device. And the problem would also be, if the AI is too simple, there's higher risk of friendly fire. Am reminded of that classic Philip K. Dick story, "Second Variety", where the basic autonomous drone model is essentially just a small ball full of blades that kills anyone who comes close enough, unless they carry some special radioactive plaque that deters them. That sort of IFF system might in fact be cheaper and simpler to work with than an AI fully capable of doing it on its own reliably.
Obviously I consider this sort of thing generally a bad idea. But it's clearly the direction this is going. I wonder how long before full drone-on-drone warfare.
The cynical amateur geopolitical analyst in me says also that this is why it's so dumb of the West to let Ukraine fail. You got a perfect laboratory to experiment and develop this new type of warfare and then eventually you can cannibalize Ukrainian know-how for yourself and make leaps and bounds without losing a single soldier yourself. Even someone who was evil but cunning would see the benefits here. But of course the US right now are being run by a moron so it's not surprising he misses this detail.
The Ammann Hypothesis: Free Will as a Failure of Self-Prediction
A fox chases a hare. The hare evades the fox. The fox tries to predict where the hare is going - the hare tries to make it as hard to predict as possible.
Q: Who needs the larger brain?
A: The fox.
This is a little animal tale meant to illustrate the following phenomenon:
Generative complexity can be much smaller than predictive complexity under partial observability. In other words, when partially observing a blackbox there are simple internal mechanism that create complex patterns that require very large predictors to predict well.
Consider the following simple 2-state HMM
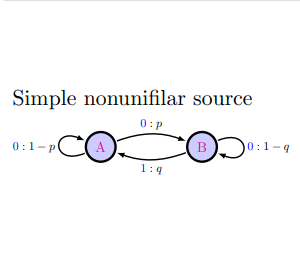
Note that the symbol 0 is output in three different ways: A -> A, A-> B, and B -> B. This means that if we see the symbol 0 we don't know where we are. We can use Bayesian updating to guess where we are but starting from a stationary distribution our belief states can become extremely complicated - in fact, the data sequence generated by the simple nonunifalar source has an optimal predictor HMM that requires infinitely many states :
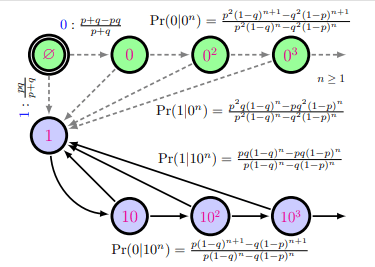
This simple example illustrates the gap between generative complexity an...
in my opinion, this is a poor choice of problem for demonstrating the generator/predictor simplicity gap.
If not restricted to Markov model based predictors, we can do a lot better simplicity-wise.
Simple Bayesian predictor tracks one real valued probability B in range 0...1. Probability of state A is implicitly 1-B.
This is initialized to B=p/(p+q) as a prior given equilibrium probabilities of A/B states after many time steps.
P("1")=qA is our prediction with P("0")=1-P("1") implicitly.
Then update the usual Bayesian way:
if "1", B=0 (known state transition to A)
if "0", A,B:=(A*(1-p),A*p+B*(1-q)), then normalise by dividing both by the sum. (standard bayesian update discarding falsified B-->A state transition)
In one step after simplification: B:=(B(1+p-q)-p)/(Bq-1)
That's a lot more practical than having infinite states. Numerical stability and achieving acceptable accuracy of a real implementable predictor is straightforward but not trivial. A near perfect predictor is only slightly larger than the generator.
A perfect predictor can use 1 bit (have we ever observed a 1) and ceil(log2(n)) bits counting n, the number of observed zeroes in the last run to calculate the perfectly correct prediction. Technically as n-->infinity this turns into infinite bits but scaling is logarithmic so a practical predictor will never need more than ~500 bits given known physics.
2
Yes - this is specifically staying within the framework of hidden markov chains.
Even if you go outside though it seems you agree there is a generative predictive gap - you're just saying it's not infinite.
Eggsyntax below gives the canonical example of hash function where prediction is harder than generation which hold for general computable processes.
6
Can a Finite-State Fox Catch a Markov Mouse? for more details
4
Eliezer made that point nicely with respect to LLMs here:
1
I first heard this idea from Joscha Bach, and it is my favorite explanation of free will. I have not heard it called as a 'predictive-generative gap' before though, which is very well formulated imo
Misgivings about Category Theory
[No category theory is required to read and understand this screed]
A week does not go by without somebody asking me what the best way to learn category theory is. Despite it being set to mark its 80th annivesary, Category Theory has the evergreen reputation for being the Hot New Thing, a way to radically expand the braincase of the user through an injection of abstract mathematics. Its promise is alluring, intoxicating for any young person desperate to prove they are the smartest kid on the block.
Recently, there has been significant investment and attention focused on the intersection of category theory and AI, particularly in AI alignment research. Despite the influx of interest I am worried that it is not entirely understood just how big the theory-practice gap is.
I am worried that overselling risks poisoning the well for the general concept of advanced mathematical approaches to science in general, and AI alignment in particular. As I believe mathematically grounded approaches to AI alignment are perhaps the only way to get robust worst-case safety guarantees for the superintelligent regime I think this would be bad.
I find it difficult...
Modern mathematics is less about solving problems within established frameworks and more about designing entirely new games with their own rules. While school mathematics teaches us to be skilled players of pre-existing mathematical games, research mathematics requires us to be game designers, crafting rule systems that lead to interesting and profound consequences
I don't think so. This probably describes the kind of mathematics you aspire to do, but still the bulk of modern research in mathematics is in fact about solving problems within established frameworks and usually such research doesn't require us to "be game designers". Some of us are of course drawn to the kinds of frontiers where such work is necessary, and that's great, but I think this description undervalues the within-paradigm work that is the bulk of what is going on.
3
Yes thats worded too strongly and a result of me putting in some key phrases into Claude and not proofreading. :p
I agree with you that most modern math is within-paradigm work.
8
I shall now confess to a great caveat. When at last the Hour is there the Program of the World is revealed to the Descendants of Man they will gaze upon the Lines Laid Bare and Rejoice; for the Code Kernel of God is written in category theory.
2
Typo, I think you meant singularity theory :p
7
You should not bury such a good post in a shortform
5
my dude, top level post- this does not read like a shortform
4
I was at an ARIA meeting with a bunch of category theorists working on safeguarded AI and many of them didn't know what the work had to do with AI.
epistemic status: short version of post because I never got around to doing the proper effort post I wanted to make.
3
Great post!
It's a habit of mine to think in very high levels of abstraction (I haven't looked much into category theory though, admittedly), and while it's fun, it's rarely very useful. I think it's because of a width-depth trade-off. Concrete real-world problems have a lot of information specific to that problem, you might even say that the unique information is the problem. An abstract idea which applies to all of mathematics is way too general to help much with a specific problem, it can just help a tiny bit with a million different problems.
I also doubt the need for things which are so complicated that you need a team of people to make sense of them. I think it's likely a result of bad design. If a beginner programmer made a slot machine game, the code would likely be convoluted and unintuitive, but you could probably design the program in a way that all of it fits in your working memory at once. Something like "A slot machine is a function from the cartesian product of wheels to a set of rewards". An understanding which would simply the problem so that you could write it much shorter and simpler than the beginner. What I mean is that there may exist simple designs for most problems in the world, with complicated designs being due to a lack of understanding.
The real world values the practical way more than the theoretical, and the practical is often quite sloppy and imperfect, and made to fit with other sloppy and imperfect things.
The best things in society are obscure by statistical necessity, and it's painful to see people at the tail ends doubt themselves at the inevitable lack of recognition and reward.
2
As a layman, I have not seen much unrealistic hype. I think the hype-level is just about right.
2
One needs only to read 4 or so papers on category theory applied to AI to understand the problem. None of them share a common foundation on what type of constructions to use or formalize in category theory. The core issue is that category theory is a general language for all of mathematics, and as commonly used just exponentially increase the search space for useful mathematical ideas.
I want to be wrong about this, but I have yet to find category theory uniquely useful outside of some subdomains of pure math.
3
In the past we already had examples ("logical AI", "Bayesian AI") where galaxy-brained mathematical approaches lost out against less theory-based software engineering.
ADHD is about the Voluntary vs Involuntary actions
The way I conceptualize ADHD is as a constraint on the quantity and magnitude of voluntary actions I can undertake. When others discuss actions and planning, their perspective often feels foreign to me—they frame it as a straightforward conscious choice to pursue or abandon plans. For me, however, initiating action (especially longer-term, less immediately rewarding tasks) is better understood as "submitting a proposal to a capricious djinn who may or may not fulfill the request." The more delayed the gratification and the longer the timeline, the less likely the action will materialize.
After three decades inhabiting my own mind, I've found that effective decision-making has less to do with consciously choosing the optimal course and more with leveraging my inherent strengths (those behaviors I naturally gravitate toward, largely outside my conscious control) while avoiding commitments that highlight my limitations (those things I genuinely intend to do and "commit" to, but realistically never accomplish).
ADHD exists on a spectrum rather than as a binary condition. I believe it serves an adaptive purpose—by restricting the number of...
My partner has ADHD. She and I talk about it often because I don’t, and understanding and coordinating with each other takes a lot of work.
Her environment is a strong influence on what tasks she considers and chooses. If she notices a weed in the garden walking from the car to the front door, she can get caught up for hours weeding before she makes it into the house. If she’s in her home office trying to work from home and notices something to tidy, same thing.
All the tasks her environment suggests to her seem important and urgent, because she’s not comparing them to some larger list of potential priorities that apply to different contexts - she’s always working on the top priority strictly with reference to the context she’s in at the moment.
She is much better than me at accomplishing tasks that her environment naturally suggests to her - cooking (inspired by recipes she finds on social media), cleaning, shopping, gardening, socializing, and making social plans in response to texts and notifications on her phone.
I am much better than her at constructing an organized list of global priorities and working through them systematically. However, I find it very difficult to be opportuni...
6
I have ADHD, and also happen to be a psychiatry resident.
As far as I can tell, it has been nothing but negative in my personal experience. It is a handicap, one I can overcome with coping mechanisms and medication, but I struggle to think of any positive impact on my life.
For a while, there were evopsych theories that postulated that ADHD had an adaptational benefit, but evopsych is a shakey field at the best of times, and no clear benefit was demonstrated.
https://pubmed.ncbi.nlm.nih.gov/32451437/
>All analyses performed support the presence of long-standing selective pressures acting against ADHD-associated alleles until recent times. Overall, our results are compatible with the mismatch theory for ADHD but suggest a much older time frame for the evolution of ADHD-associated alleles compared to previous hypotheses.
The ancient ancestral environment probably didn't reward strong executive function and consistency in planning as strongly as agricultural societies did. Even so, the study found that prevalence was dropping even during Palaeolithic times, so it wasn't even something selected for in hunter-gatherers!
I hate having ADHD, and sincerely hope my kids don't. I'm glad I've had a reasonably successful life despite having it.
2
I’m slowly accepting that my ADHD sucks to inhabit, but that it is objectively working and my feeling that it is a secret superpower isn’t entirely cope. Certainly I miss deadlines and raise my advisor’s blood pressure, but at this point I’ve got multiple CVPR papers.
The question is: do my research results trace back to me involuntarily exploring the beautiful research directions, even when I am trying very hard to focus on the work in front of me, that I am expected/required to be doing?
Or, do I have innate ability that is being held back by ADHD, and I would be far more successful if I could just have self control? I think fear of this possibility contributes an unhealthy level of ambition: if I’m successful enough, it wouldn’t leave room above for the “far more successful” version of me without ADHD to eclipse me.
The Padding Argument or Simplicity = Degeneracy
[I learned this argument from Lucius Bushnaq and Matthias Dellago. It is also latent already in Solomonoff's original work]
Consider binary strings of a fixed length
Imagine feeding these strings into some turing machine; we think of strings as codes for a function. Suppose we have a function that can be coded by a short compressed string of length . That is, the function is computable by a small program.
Imagine uniformly sampling a random code for . What number of the codes implement the same function as the string ? It's close to .[1] Indeed, given the string of length we can 'pad' it to a string of length by writing the code
"run skip "
where is an arbitrary string of length where is a small constant accounting for the overhead. There are approximately of such binary strings. If our programming language has a simple skip / commenting out functionality then we expect approximately codes encoding the same function as ...
Re: the SLT dogma.
For those interested, a continuous version of the padding argument is used in Theorem 4.1 of Clift-Murfet-Wallbridge to show that the learning coefficient is a lower bound on the Kolmogorov complexity (in a sense) in the setting of noisy Turing machines. Just take the synthesis problem to be given by a TM's input-output map in that theorem. The result is treated in a more detailed way in Waring's thesis (Proposition 4.19). Noisy TMs are of course not neural networks, but they are a place where the link between the learning coefficient in SLT and algorithmic information theory has already been made precise.
For what it's worth, as explained in simple versus short, I don't actually think the local learning coefficient is algorithmic complexity (in the sense of program length) in neural networks, only that it is a lower bound. So I don't really see the LLC as a useful "approximation" of the algorithmic complexity.
For those wanting to read more about the padding argument in the classical setting, Hutter-Catt-Quarel "An Introduction to Universal Artificial Intelligence" has a nice detailed treatment.
5
Thank you for the references Dan.
I agree neural networks probably don't actually satisfy the padding argument on the nose and agree that the exact degeneracy is quite interesting (as I say at the end of the op).
I do think for large enough overparameterization the padding argument suggests the LLC might come close to the K-complexity in many cases. But more interestingly to me is that the padding argument doesn't really require the programming language to be Turing-complete. In those cases the degeneracy will be proportional to complexity/simplicity measures that are specific to the programming language (/architecture class). Inshallah I will get to writing something about that soon.
3
Small addendum: The padding argument gives a lower bound of the multiplicity. Above it is bounded by the Kraft-McMillan inequality.
2
I have written a post where I explain the classical version of the padding argument / coding theorem in a fair amount of detail.
2
The sentence seems cut off.
Why Do the French Dominate Mathematics?
France has an outsized influence in the world of mathematics despite having significantly fewer resources than countries like the United States. With approximately 1/6th of the US population and 1/10th of its GDP, and French being less widely spoken than English, France's mathematical achievements are remarkable.
This dominance might surprise those outside the field. Looking at prestigious recognitions, France has won 13 Fields Medals compared to the United States' 15 a nearly equal achievement despite the vast difference in population and resources. Other European nations lag significantly behind, with the UK having 8, Russia/Soviet Union 6/9, and Germany 2.
France's mathematicians are similarly overrepresented in other mathematics prizes and honors, confirming this is not merely a statistical anomaly.
I believe two key factors explain France's exceptional performance in mathematics while remaining relatively average in other scientific disciplines:
1. The "Classes Préparatoires" and "Grandes Écoles" System
The French educational system differs significantly from others through its unique "classes préparatoires" (preparatory classes) and "grandes ...
I don't buy your factors (1) or (2). Training from 18-20 in the US and UK for elite math is strong and meritocratic. And brilliant mathematicians have career stability in the US and UK.
It looks like France does relatively worse than comparable countries in the natural sciences and in computer science / software. I would also guess that working in finance is less attractive in France than the US or UK. So one possible factor is opportunity cost.
https://royalsocietypublishing.org/doi/10.1098/rsos.180167
4
Those are some good points certainly.
The UK/US system typically gives tenure around ~40, typically after ~two postdocs and a assistant -> associate -> full prof.
In the French system a typical case might land an effectively tenured job at 30. Since 30-40 is a decade of peak creativity for scientists in general, mathematicians in particular I would say this is highly
Laurent Lafforgue is a good example. Iirc he published almost nothing for seven years after his PhD until the work that he did for the Fields medal. He wouldnt have gotten a job in the American system.
He is an extreme example but generically having many more effectively tenured positions at a younger age means that mathematicians feel the freedom to doggedly pursue important, but perhaps obscure-at-present, research bets.
My point is primarily that the selection is at 20, instead of at 18. It s not about training per se, although here too the French system has an advantage. Paris has ~ 14 universities, a number of grand ecolees, research labs, etc a large fraction which do serious research mathematics. Paris consequently has the largest and most diverse assortiment of advanced coursework in the world. I don't believe there is any place in the US that compares [I've researched this in detail in the past].
2
The UK does not have the same tenure system as the US. I believe top mathematicians have historically (i.e. last 70 years) often become permanent lecturers fairly young (e.g. by age 32).
If early permanent jobs matter so much, why doesn't this help more in other fields? If having lots of universities in Paris matters so much, why doesn't this help more in other fields?
2
I wouldn't claim to be an expert on the UK system but from talking with colleagues at UCL it seems to be the case that French positions are more secure and given out earlier [and this was possibly a bigger difference in the past]. I am not entirely sure about the number 32. Anecdotally, I would say many of the best people I know did not obtain tenure this early. This is something that may also vary by field - some fields are more popular, better funded because of [perceived] practical applications.
Mathematiscs is very different from other fields. For instance: it is more long-tailed, benefits from ' deep research, deep ideas' far more than other fields, is difficult to paralellize, has ultimate ground truth [proofs], and in large fraction of subfields [e.g. algebraic geometry, homotopy theory ...] the amount of prerequisite knowledge is very large,[1] has many specialized subdisciplines , there are no empirical
All these factors suggest that the main relevant factor of production is how many positions that allow intellectuall freedom, are secure, at a young age plus how they are occupied by talented people is.
1. ^
e.g. it often surprises outsiders that in certian subdisciplines of mathematics even very good PhD students will often struggle reading papers at the research frontier - even after four years of specialized study.
1
I'd defend a version of claim (1): My understanding is that to a greater extent than anywhere else, top French students wanting to concentrate in STEM subjects must take rigorous math coursework from 18-20. In my one year experience in the French system, I also felt that there was a greater cultural weight and institutionalized preference (via course requirements and choice of content) for theoretical topics in ML compared to US universities.
I know little about ENS, but somewhat doubt that it's as significantly different of an experience from US/UK counterparts.
2
Certainly for many/most other subjects the French system is not so good. E.g. for ML all that theory is mostly a waste.
The intellectual maturation between ages 18 and 20 is profound
This is the first time I've heard this claim. Any background/cites I should look into for this?
Alternative model: French mathematicians don't overperform in an objective sense. Rather, French mathematicians happened to end up disproportionately setting fashion trends in pure mathematics for a while, for reasons which are mostly just signalling games and academic politics rather than mathematical merit.
The Bourbaki spring to mind here as a central example.
6
Sure happy to disagree on this one.
Fwiw, the French dominance isn't confined to Bourbakist topics. E.g. Pierre Louis Lions won one of the French medals and is the world most cited mathematician, with a speciality in PDEs. Some of his work investigates the notion of general nonsmooth ("viscosity") solutions for the general Hamilton-Jacobi(-Bellmann) equation both numerically and analytically. It's based on a vast generalization of the subgradient calculus ("nonsmooth" calculus), and is very directly related to good numerical approximation schemes.
5
Maryna Viazovska, the Ukrainian Fields medalist, did her PhD in Germany under Don Zagier.
---
I once saw at least one French TV talkshow where famous mathematicians were invited (I don't find the links anymore). Something like that would be pretty much unthinkable in Germany. So I wonder if math has generally more prestige in France than e.g. in Germany.
3
One point evoked by other comments, which I've realized only after leaving France and living in the UK, is that there is still a massive prestige for engineering. ENS is not technically an engineering school, but it benefits from this prestige by being lumped with them, and by being accessed mainly from the national contests at the end of Prepas.
As always with these kind of cultural phenomena, I didn't really notice them until I left France for the UK. There is a sense in France (more when I was a student, but still there) that the most prestigious jobs are engineering ones. Going to engineering school is considered one of the top options (with medecine), and it is considered a given that any good student with a knack for maths, physics, science, will go to prepa and engineering school.[1] It's almost free (and in practice is free if your parents don't make more than a certain amount), and it is guaranteed to lead to a good future.
This means that the vast majority of mathematical talent studies the equivalent of a undergraduate degree in maths, compressed in the span of 2 years. In addition of giving the standard french engineer much more of a mathematical training, it shows to the potential mathematicians, by default, a lot of what they could do. And if they decide to go to ENS (or Polytechnique, which is the best engineering school but still quite researchy if you want to), this is actually one of the most prestigious options you could take.
Similarly, the prestige of engineering (and science to some extent) impacts what people decide to do after their degrees. I remember that in my good prepa and my good engineering school, the cool ones were those going to build planes and bridges. The ones who went into consulting and finance were pitied and mocked as the failures, not the impressive successes to emulate. Yet what my UK friends tell me is that this is the exact opposite of what happens even in great universities in the UK.
1. ^
This has becom
2
I'm not 100% sure about the second factor but the first is definitely a big factor. There's no institution which is more dense in STEM talent than ENS to my knowledge, and elites there are extremely generalist compared to equivalent elites I've met in other countries like the US (e.g. MIT) for instance. The core of "Classes Préparatoires" is that it pushes even the world best people to grind like hell for 2 years, including weekends, every evenings etc.
ENS is the result of: push all your elite to grind like crazy for 2 years on a range of STEM topics, and then select the top 20 to 50.
2
Maybe I'm going crazy, but the frequent use of qualifiers for almost every noun in your writing screams of "LLM" to me. Did you use LLM assistance? I don't get that same feel from your comments, so I'm learning toward an AI having written only the Shortform itself.
If you did use AI, I'd be in favor of you disclosing that so that people like me don't feel like they're gradually going insane.
If not, then I'm sorry and retract this. (Though not sure what to tell you—I think this writing style feels too formal and filled with fluff like "crucial" or "invaluable", and I bet you'll increasingly be taken for an AI in other contexts.)
3
Yes I use LLMs in my writing [not this comment] and I strongly encourage others to do so too.
This the age of Cyborgism. Jumping on making use of the new capabilities opening up will likely be key to getting alignment right. AI is coming, whether you like it or not.
There is also a mundane reason: I have an order of magnitude more ideas than I can write down. Using LLMs allows me to write an essay in 30 min which otherwise would take half a day.
1
Oh yeah no problem with writing with LLMs, only doing it without disclosing it. Though I guess this wasn't the case here, sry for flagging this.
I'm not sure I want to change my approach next time though, bc I do feel like I should be on my toes. Beware of drifting too much toward the LLM's stylebook I guess.
2
If the same pattern of other innovations hold, then it seems more likely that it is more a questions of concentration in one place (for software: Silicon Valley). Maybe one French university, maybe the École Normale Supérieure, managed to become the leading place for math and now every mathematician tries to go there.
2
I wonder about the extent to which having an additional level of selection helps.
High school curricula are generally limited by having to be able to be taught by a large number of teachers all around the country and by needing a minimum number of students at the school who are capable of the content.
If the préparatoires can put more qualified teachers and students together that would allow significant development and running selection for elite universities after such an intermediate preparatory program it would reduce the chance that talented students aren't missed due to having attended a high school that is weaker at maths (even though it sounds like the preparatories have a selection bar too, I assume it's quite a bit lower than performing well enough to get into a top institution).
2
I agree with the previous points, but I would also add historical events that led to this.
Pre-WW I Germany was much more important and plays the role that France is playing today (maybe even more central), see University of Göttingen at the time.
After two world wars the German mathematics community was in shambles, with many mathematicians fleeing during that period (Grothendieck, Artin, Gödel,...). The university of Bonn (and the MPI) were the post-war project of Hirzebruch to rebuild the math community in Germany.
I assume France then was then able to rise as the hotspot and I would be curious to imagine what would have happened in an alternative timeline.
Forecasting and scenario building has become quite popular and prestigious in EA-adjacent circles. I see extremely detailed scenario building & elaborate narratives.
Yes AI will be big, AGI plausibly close. But how much detail can one really expect to predict? There were a few large predictions that some people got right, but once one zooms in the details don't fit while the correct predictions were much more widespread within the group of people that were paying attention.
I can't escape the feeling that we're quite close to the limits of the knowable and 80% of EA discourse on this is just larp.
Does anybody else feel this way?
I think for many years there was a lot of frustration from people outside of the community about people inside of it not going into a lot of detail. My guess is we are dealing with a bit of a pendulum swing of now people going hard in the other direction. I do think we are just currently dealing with one big wave of this kind of content. It's not like there was much of any specific detailed scenario work two years ago.
I think the value proposition of AI 2027-style work lies largely in communication. Concreteness helps people understand things better. The details are mostly there to provide that concreteness, not to actually be correct.
If you imagine the set of possible futures that people like Daniel, you or I think plausible as big distributions, with high entropy and lots of unknown latent variables, the point is that the best way to start explaining those distributions to people outside the community is to draw a sample from them and write it up. This is a lot of work, but it really does seem to help. My experience matches habryka's here. Most people really want to hear concrete end-to-end scenarios, not abstract discussion of the latent variables in my model and their relationships.
4
I have the same experience, whenever I try to explain AI X-risk to a “layman” they want a concrete story about how AGI could take over.
4
I feel this way and generally think that on-the-margin we have too much forecasting and not enough “build plans for what to do if there is a sudden shift in political will” or “just directly engage with policymakers and help them understand things not via longform writing but via conversations/meetings.”
Many details will be ~impossible to predict and many details will not matter much (i.e., will not be action-relevant for the stakeholders who have the potential to meaningfully affect the current race to AGI).
That’s not to say forecasting is always unhelpful. Things like AI2027 can certainly move discussions forward and perhaps get new folks interested. But EG, my biggest critique of AI2027 is that I suspect they’re spending too much time/effort on detailed longform forecasting and too little effort on arranging meetings with Important Stakeholders, developing a strong presence in DC, forming policy recommendations, and related activities. (And TBC I respect/admire the AI2027 team, have relayed this feedback to them, and imagine they have thoughtful reasons for taking the approach they’re taking.)
4
FWIW, I was always concerned about people trying to make long-horizon forecast predictions because they assumed superforecasting would extrapolate beyond the sub-1-year predictions that were tested.
As an alternative, that's why I wrote about strategic foresight to focus on robust plans rather than trying to accurately predict the actual scenario.
Why don't animals have guns?
Or why didn't evolution evolve the Hydralisk?
Evolution has found (sometimes multiple times) the camera, general intelligence, nanotech, electronavigation, aerial endurance better than any drone, robots more flexible than any human-made drone, highly efficient photosynthesis, etc.
First of all let's answer another question: why didn't evolution evolve the wheel like the alien wheeled elephants in His Dark Materials?
Is it biologically impossible to evolve?
Well, technically, the flagella of various bacteria is a proper wheel.
No the likely answer is that wheels are great when you have roads and suck when you don't. Roads are build by ants to some degree but on the whole probably don't make sense for an animal-intelligence species.
Aren't there animals that use projectiles?
Hold up. Is it actually true that there is not a single animal with a gun, harpoon or other projectile weapon?
Porcupines have quils, some snakes spit venom, a type of fish spits water as a projectile to kick insects of leaves than eats insects. Bombadier beetles can produce an explosive chemical mixture. Skunks use some other chemicals. Some snails shoot harpoons from very c...
6
Please develop this question as a documentary special, for lapsed-Starcraft player homeschooling dads everywhere.
6
Most uses of projected venom or other unpleasant substance seem to be defensive rather than offensive. One reason for this is that it's expensive to make the dangerous substance, and throwing it away wastes it. This cost is affordable if it is used to save your own life, but not easily affordable to acquire a single meal. This life vs meal distinction plays into a lot of offense/defense strategy expenses.
For the hunting options, usually they are also useful for defense. The hunting options all seem cheaper to deploy: punching mantis shrimp, electric eel, fish spitting water...
My guess it that it's mostly a question of whether the intermediate steps to the evolved behavior are themselves advantageous. Having a path of consistently advantageous steps makes it much easier for something to evolve. Having to go through a trough of worse-in-the-short-term makes things much less likely to evolve. A projectile fired weakly is a cost (energy to fire, energy to producing firing mechanism, energy to produce the projectile, energy to maintain the complexity of the whole system despite it not being useful yet). Where's the payoff of a weakly fired projectile? Humans can jump that gap by intuiting that a faster projectile would be more effective. Evolution doesn't get to extrapolate and plan like that.
7
Jellyfish have nematocysts, which is a spear on a rope, with poison on the tip. The spear has barbs, so when it goes in, it sticks. Then the jellyfish pulls in its prey. The spears are microscopic, but very abundant.
4
Yes, but I think snake fangs and jellyfish nematocysts are a slightly different type of weapon. Much more targeted application of venom. If the jellyfish squirted their venom as a cloud into the water around them when a fish came near, I expect it would not be nearly as effective per unit of venom. As a case where both are present, the spitting cobra uses its fangs to inject venom into its prey. However, when threatened, it can instead (wastefully) spray out its venom towards the eyes of an attacker. (the venom has little effect on unbroken mammal skin, but can easily blind if it gets into their eyes).
4
Fair argument I guess where I'm lost is that I feel I can make the same 'no competitive intermediate forms' for all kinds of wondrous biological forms and functions that have evolved, e.g. the nervous system. Indeed, this kind of argument used to be a favorite for ID advocates.
3
There are lots of excellent applications for even very simple nervous systems. The simplest surviving nervous systems are those of jellyfish. They form a ring of coupled oscillators around the periphery of the organism. Their goal is to synchronize muscular contraction so the bell of the jellyfish contracts as one, to propel the jellyfish efficiently. If the muscles contracted independently, it wouldn’t be nearly as good.
Any organism with eyes will profit from having a nervous system to connect the eyes to the muscles. There’s a fungus with eyes and no nervous system, but as far as I know, every animal with eyes also has a nervous system. (The fungus in question is Pilobolus, which uses its eye to aim a gun. No kidding!)
5
My naive hypothesis: Once you're able to launch a projectile at a predator or prey such that it breaks skin or shell, if you want it to die, its vastly cheaper to make venom at the ends of the projectiles than to make the projectiles launch fast enough that there's a good increase in probability the adversary dies quickly.
4
Why don't lions, tigers, wolves, crocodiles, etc have venom-tipped claws and teeth?
(Actually, apparently many ancestral mammal species like did have venom spurs, similar to the male platypus)
9
My completely naive guess would be that venom is mostly too slow for creatures of this size compared with gross physical damage and blood loss, and that getting close enough to set claws on the target is the hard part anyway. Venom seems more useful as a defensive or retributive mechanism than a hunting one.
4
Another huge missed opportunity is thermal vision. Thermal infrared vision is a gigantic boon for hunting at night, and you might expect eg owls and hawks to use it to spot prey hundreds of meters away in pitch darkness, but no animals do (some have thermal sensing, but only extremely short range)
7
Snakes have thermal vision, using pits on their cheeks to form pinhole cameras. It pays to be cold-blooded when you’re looking for nice hot mice to eat.
5
Thermal vision for warm-blooded animals has obvious problems with noise.
2
Care to explain? Noise?
5
If you are warm, any warm-detectors inside your body will detect mostly you. Imagine if blood vessels in your own eye radiated in visible spectrum with the same intensity as daylight environment.
4
Can't you filter that out? .
How do fighter planes do it?
8
It‘s possible to filter out a constant high value, but not possible to filter out a high level of noise. Unfortunately warmth = random vibration = noise. If you want a low noise thermal camera, you have to cool the detector, or only look for hot things, like engine flares. Fighter planes do both.
2
Woah great example didn't know bout that. Thanks Tao
1
Animals do have guns. Humans are animals. Humans have guns. Evolution made us, we made guns, therefore guns indirectly exist because of evolution.
Or do you mean "why don't animals have something like guns but permanently attached to them instead of regular guns?" There, I'd start with wondering why humans prefer to have our guns separate from our bodies, compared to affixing them permanently or semi-permanently to ourselves. All the drawbacks of choosing a permanently attached gun would also disadvantage a hypothetical creature that got the accessory through a longer, slower selection process.
How to prepare for the coming Taiwan Crisis? Should one short TSMC? Dig a nuclear cellar?
Metaculus gives a 25% of a fullscale invasion of Taiwan within 10 years and a 50% chance of a blockade. It gives a 65% chance that if China invades Taiwan before 2035 the US will respond with military force.
Metaculus has very strong calibration scores (apparently better than prediction markets). I am inclined to take these numbers as the best guess we currently have of the situation.
Is there any way to act on this information?
4
Come to think of it, I don't think most compute-based AI timelines models (e.g. EPOCH's) incorporate geopolitical factors such as a possible Taiwan crisis. I'm not even sure whether they should. So keep this in mind while consuming timelines forecasts I guess?
2
Also: anybody have any recommendations for pundits/analysis sources to follow on the Taiwan situation? (there's Sentinel but I'd like something more in-depth and specifically Taiwan-related)
4
I don't have any. I'm also wary of soothsayers.
Phillip Tetlock pretty convingingly showed that most geopolitics experts are no such thing. The inherent irreducible uncertainty is just quite high.
On Taiwan specifically you should know that the number of Westerners that can read Chinese at a high enough level that they can actually co. Chinese is incredibly difficult. Most China experts you see on the news will struggle with reading the newspaper unassisted (learning Chinese is that hard. I know this is surprising; I was very surprised when I realized this during an attempt to learn chinese).
I did my best on writing down some of the key military facts on the Taiwan situation that can be reasonably inferred recently. You can find it in my recent shortforms.
Even when confining too concrete questions like how many missiles, how much shipbuilding capacity, how well would an amphibious landing go, how would US allies be able to assist, how vulnerable/obsolete are aircraft carriers etc the net aggregated uncertainty on the balance of power is still quite large.
1
The CSIS wargamed a 2026 Chinese invasion of Taiwan, and found outcomes ranging from mixed to unfavorable for China (CSIS report). If you trust both them and Metaculus, then you ought to update downwards on your estimate of the PRC's strategic ability. Personally, I think Metaculus overestimates the likelihood of an invasion, and is about right about blockades.
3
Why would you trust CSIS here? A US think tank like that is going to seek to publically say that invading Taiwan is bad for the Chinese.
1
Why would they? It's not like the Chinese are going to believe them. And if their target audience is US policymakers, then wouldn't their incentive rather be to play up the impact of marginal US defense investment in the area?
3
I note that the PRC doesn't have a single "strategic ability" in terms of war. They can be better or worse at choosing which wars to fight, and this seems likely to have little influence on how good they are at winning such wars or scaling weaponry.
Eg in the US often "which war" is much more political than "exactly what strategy should we use to win this war" is much more political than "how much fuel should our jets be able to carry", since more people can talk & speculate about the higher level questions. China's politics are much more closed than the US's, but you can bet similar dynamics are at play.
0
I should have been more clear. With "strategic ability", I was thinking about the kind of capabilities that let a government recognize which wars have good prospects, and to not initiate unfavorable wars despite ideological commitments.
Novel Science is Inherently Illegible
Legibility, transparency, and open science are generally considered positive attributes, while opacity, elitism, and obscurantism are viewed as negative. However, increased legibility in science is not always beneficial and can often be detrimental.
Scientific management, with some exceptions, likely underperforms compared to simpler heuristics such as giving money to smart people or implementing grant lotteries. Scientific legibility suffers from the classic "Seeing like a State" problems. It constrains endeavors to the least informed stakeholder, hinders exploration, inevitably biases research to be simple and myopic, and exposes researchers to constant political tug-of-war between different interest groups poisoning objectivity.
I think the above would be considered relatively uncontroversial in EA circles. But I posit there is something deeper going on:
Novel research is inherently illegible. If it were legible, someone else would have already pursued it. As science advances her concepts become increasingly counterintuitive and further from common sense. Most of the legible low-hanging fruit has already been picked, and novel research requires venturing higher into the tree, pursuing illegible paths with indirect and hard-to-foresee impacts.
Novel research is inherently illegible.
I'm pretty skeptical of this and think we need data to back up such a claim. However there might be bias: when anyone makes a serendipitous discovery it's a better story, so it gets more attention. Has anyone gone through, say, the list of all Nobel laureates and looked at whether their research would have seemed promising before it produced results?
Thanks for your skepticism, Thomas. Before we get into this, I'd like to make sure actually disagree. My position is not that scientific progress is mostly due to plucky outsiders who are ignored for decades. (I feel something like this is a popular view on LW). Indeed, I think most scientific progress is made through pretty conventional (academic) routes.
I think one can predict that future scientific progress will likely be made by young smart people at prestigious universities and research labs specializing in fields that have good feedback loops and/or have historically made a lot of progress: physics, chemistry, medicine, etc
My contention is that beyond very broad predictive factors like this, judging whether a research direction is fruitful is hard & requires inside knowledge. Much of this knowledge is illegible, difficult to attain because it takes a lot of specialized knowledge etc.
Do you disagree with this ?
I do think that novel research is inherently illegible. Here are some thoughts on your comment :
1.Before getting into your Nobel prize proposal I'd like to caution for Hindsight bias (obvious reasons).
-
And perhaps to some degree I'd like to argue the burden of proo
I guess I'm not sure what you mean by "most scientific progress," and I'm missing some of the history here, but my sense is that importance-weighted science happens proportionally more outside of academia. E.g., Einstein did his miracle year outside of academia (and later stated that he wouldn't have been able to do it, had he succeeded at getting an academic position), Darwin figured out natural selection, and Carnot figured out the Carnot cycle, all mostly on their own, outside of academia. Those are three major scientists who arguably started entire fields (quantum mechanics, biology, and thermodynamics). I would anti-predict that future scientific progress, of the field-founding sort, comes primarily from people at prestigious universities, since they, imo, typically have some of the most intense gatekeeping dynamics which make it harder to have original thoughts.
8
Good point.
I do wonder to what degree that may be biased by the fact that there were vastly less academic positions before WWI/WWII. In the time of Darwin and Carnot these positions virtually didn't exist. In the time of Einstein they did exist but they were quite rare still.
How many examples do you know of this happening past WWII?
Shannon was at Bell Labs iirc
As counterexample of field-founding happening in academia: Godel, Church, Turing were all in academia.
6
Oh, I actually 70% agree with this. I think there's an important distinction between legibility to laypeople vs legibility to other domain experts. Let me lay out my beliefs:
* In the modern history of fields you mentioned, more than 70% of discoveries are made by people trying to discover the thing, rather than serendipitously.
* Other experts in the field, if truth-seeking, are able to understand the theory of change behind the research direction without investing huge amounts of time.
* In most fields, experts and superforecasters informed by expert commentary will have fairly strong beliefs about which approaches to a problem will succeed. The person working on something will usually have less than 1 bit advantage about whether their framework will be successful than the experts, unless they have private information (e.g. already did the crucial experiment). This is the weakest belief and I could probably be convinced otherwise just by anecdotes.
* The successful researchers might be confident they will succeed, but unsuccessful ones could be almost as confident on average. So it's not that the research is illegible, it's just genuinely hard to predict who will succeed.
* People often work on different approaches to the problem even if they can predict which ones will work. This could be due to irrationality, other incentives, diminishing returns to each approach, comparative advantage, etc.
If research were illegible to other domain experts, I think you would not really get Kuhnian paradigms, which I am pretty confident exist. Paradigm shifts mostly come from the track record of an approach, so maybe this doesn't count as researchers having an inside view of others' work though.
Thank you, Thomas. I believe we find ourselves in broad agreement. The distinction you make between lay-legibility and expert-legibility is especially well-drawn.
One point: the confidence of researchers in their own approach may not be the right thing to look at. Perhaps a better measure is seeing who can predict not only their own approach will succed but explain in detail why other approaches won't work. Anecdotally, very succesful researchers have a keen sense of what will work out and what won't - in private conversation many are willing to share detailed models why other approaches will not work or are not as promising. I'd have to think about this more carefully but anecdotally the most succesful researchers have many bits of information over their competitors not just one or two. (Note that one bit of information means that their entire advantage could be wiped out by answering a single Y/N question. Not impossible, but not typical for most cases)
5
What areas of science are you thinking of? I think the discussion varies dramatically.
I think allowing less legibility would help make science less plodding, and allow it to move in larger steps. But there's also a question of what direction it's plodding. The problem I saw with psych and neurosci was that it tended to plod in nearly random, not very useful directions.
And what definition of "smart"? I'm afraid that by a common definition, smart people tend to do dumb research, in that they'll do galaxy brained projects that are interesting but unlikely to pay off. This is how you get new science, but not useful science.
In cognitive psychology and neuroscience, I want to see money given to people who are both creative and practical. They will do new science that is also useful.
In psychology and neuroscience, scientists pick the grantees, and they tend to give money to those whose research they understand. This produces an effect where research keeps following one direction that became popular long ago. I think a different method of granting would work better, but the particular method matters a lot.
Thinking about it a little more, having a mix of personality types involved would probably be useful. I always appreciated the contributions of the rare philospher who actually learned enough to join a discussion about psych or neurosci research.
I think the most important application of meta science theory is alignment research.
3
It might also be that a legible path would be low status to pursue in the existing scientific communities and thus nobody pursues it.
If you look at a low-hanging fruit that was unpicked for a long time, airborne transmission of many viruses like the common cold, is a good example. There's nothing illegible about it.
2
mmm Good point. Do you have more examples?
2
The core reason for holding the belief is because the world does not look to me like there's little low hanging fruit in a variety of domains of knowledge I have thought about over the years. Of course it's generally not that easy to argue for the value of ideas that the mainstream does not care about publically.
Wei Dei recently wrote:
If you look at the broader field of rationality, the work of Judea Pearl and that of Tetlock both could have been done twenty years earlier. Conceptually, I think you can argue that their work was some of the most important work that was done in the last decades.
Judea Pearl writes about how allergic people were against the idea of factoring in counterfactuals and causality.
2
I don’t think the application to EA itself would be uncontroversial.
You May Want to Know About Locally Decodable Codes
In AI alignment and interpretability research, there's a compelling intuition that understanding equals compression. The idea is straightforward: if you truly understand a system, you can describe it more concisely by leveraging that understanding. This philosophy suggests that better interpretability techniques for neural networks should yield better compression of their behavior or parameters.
jake_mendel asks: if understanding equals compression, then shouldn't ZIP compression of neural network weights count as understanding? After all, ZIP achieves remarkable compression ratios on neural network weights - likely better than any current interpretability technique. Yet intuitively, having a ZIP file of weights doesn't feel like understanding at all! We wouldn't say we've interpreted a neural network just because we've compressed its weights into a ZIP file.
Compressing a bit string means finding a code for that string, and the study of such codes is the central topic of both algorithmic and Shannon information theory. Just compressing the set of weights as small as possible is too naive - we probably want to impose additional proper...
I don't remember the details, but IIRC ZIP is mostly based on Lempel-Ziv, and it's fairly straightforward to modify Lempel-Ziv to allow for efficient local decoding.
My guess would be that the large majority of the compression achieved by ZIP on NN weights is because the NN weights are mostly-roughly-standard-normal, and IEEE floats are not very efficient for standard normal variables. So ZIP achieves high compression for "kinda boring reasons", in the sense that we already knew all about that compressibillity but just don't leverage it in day-to-day operations because our float arithmetic hardware uses IEEE.
4
Could this be verified? Like, estimate the compression ratio under the assumption that it's all about compressing IEEE floats, then run the ZIP and compare the actual result to the expectation?
2
Easiest test would be to zip some trained net params, and also zip some randomly initialized standard normals of the same shape as the net params (including e.g. parameter names if those are in the net params file), and see if they get about the same compression.
-3
John, you know much coding theory much better than I do so I am inclinced to defer to your superior knowledge.
Now behold the awesome power of gpt-Pro
Using ZIP as compression metric for NNs (I assume you do something along the lines of "take all the weights and line them up and then ZIP") is unintuitive to me for the following reason:
ZIP, though really this should apply to any other coding scheme that just tries to compress the weights by themselves, picks up on statistical patterns in the raw weights. But NNs are not just simply a list of floats, they are arranged in highly structured manner. The weights themselves get turned into functions and it is 1.the functions, and 2. the way the functions interact that we are ultimately trying to understand (and therefore compress).
To wit, a simple example for the first point : Assume that inside your model is a 2x2 matrix with entries M=[0.587785, -0.809017, 0.809017, 0.587785]. Storing it like this will cost you a few bytes and if you compress it you can ~ half the cost I believe. But really there is a much more compact way to store this information: This matrix represents a rotation by 36 degrees. Storing it this way, requires less than 1 byte.
This phenomenon should get worse for bigger models. One reason is the following: If we believe that the NN uses superposition, then...
8
This sounds right to me, but importantly it also matters what you are trying to understand (and thus compress). For AI safety, the thing we should be interested in is not the weights directly, but the behavior of the neural network. The behavior (the input-output mapping) is realized through a series of activations. Activations are realized through applying weights to inputs in particular ways. Weights are realized by setting up an optimization problem with a network architecture and training data. One could try compressing at any one of those levels, and of course they are all related, and in some sense if you know the earlier layer of abstraction you know the later one. But in another sense, they are fundamentally different, in exactly how quickly you can retrieve the specific piece of information, in this case the one we are interested in - which is the behavior. If I give you the training data, the network architecture, and the optimization algorithm, it still takes a lot of work to retrieve the behavior.
Thus, the story you gave about how accessibility matters also explains layers of abstraction, and how they relate to understanding.
Another example of this is a dynamical system. The differential equation governing it is quite compact: $\dot{x}=f(x)$. But the set of possible trajectories can be quite complicated to describe, and to get them one has to essentially do all the annoying work of integrating the equation! Note that this has implications for compositionality of the systems: While one can compose two differential equations by e.g. adding in some cross term, the behaviors (read: trajectores) of the composite system do not compose! and so one is forced to integrate a new system from scratch!
Now, if we want to understand the behavior of the dynamical system, what should we be trying to compress? How would our understanding look different if we compress the governing equations vs. the trajectories?
6
Indeed, even three query locally decodable codes have code lengths that must grow exponentially with message size:
https://www.quantamagazine.org/magical-error-correction-scheme-proved-inherently-inefficient-20240109/
5
Interesting! I think the problem is dense/compressed information can be represented in ways in which it is not easily retrievable for a certain decoder. The standard model written in Chinese is a very compressed representation of human knowledge of the universe and completely inscrutable to me.
Or take some maximally compressed code and pass it through a permutation. The information content is obviously the same but it is illegible until you reverse the permutation.
In some ways it is uniquely easy to do this to codes with maximal entropy because per definition it will be impossible to detect a pattern and recover a readable explanation.
In some ways the compressibility of NNs is a proof that a simple model exists, without revealing a understandable explanation.
I think we can have (almost) minimal yet readable model without exponentially decreasing information density as required by LDCs.
3
Hm, feels off to me. What privileges the original representation of the uncompressed file as the space in which locality matters? I can buy the idea that understanding is somehow related to a description that can separate the whole into parts, but why do the boundaries of those parts have to live in the representation of the file I'm handed? Why can't my explanation have parts in some abstract space instead? Lots of explanations of phenomena seem to work like that.
1
Maybe it's more correct to say that understanding requires specifically compositional compression, which maintains an interface-based structure hence allowing us to reason about parts without decompressing the whole, as well as maintaining roughly constant complexity as systems scale, which parallels local decodability. ZIP achieves high compression but loses compositionality.
1
Wouldn't the insight into understanding be in the encoding, particularly how the encoder discriminates between what is necessary to 'understand' a particular function of a system and what is not salient? (And if I may speculate wildly, in organisms may be correlative to dopamine in the Nucleus Accumbens. Maybe.)
All mental models of the world are inherently lossy, this is the map-territory analogy in a nutshell (itself - a lossy model). The effectiveness or usefulness of a representation determines the level of 'understanding' this is entirely dependent on the apparent salience at the time of encoding which determines what elements are given higher fidelity in encoding, and which are more lossy. Perhaps this example will stretch the use of 'understanding' but consider a fairly crowded room at a conference where there is a lot of different conversations and dialogue - I see a friend gesticulating at me on the far side of the room. Once they realize I've made eye contact they start pointing surreptitiously to their left - so I look immediately to their left (my right) and see five different people and a strange painting on the wall - all possible candidates for what they are pointing at, perhaps it's the entire circle of people.
Now I'm not sure at this point that the entire 'message' - message here being all the possible candidates for what my friend is pointing at - has been 'encoded' such that LDC could be used to single out (decode) the true subject. Or is it?
In this example, I would have failed to reach 'understanding' of their pointing gesture (although I did understand their previous attempt to get my attention).
Now, suppose, my friend was pointing not to the five people or to the painting at all - but something or sixth someone further on: a distinguished colleague is drunk let's say - but I hadn't noticed. If I had of seen that colleague, I would have understood my friend's pointing gesture. This goes beyond LDC because you can't retrieve a local code o
Reward is not the optimization target.
The optimization target is the Helmholtz free energy functional in the conductance-corrected Wasserstein metric for the step-size effective loss potential in the critical batch size regime for the weight-initialization distribution as prior up to solenoidal flux corrections
7
Nah, I buy that they're up so some wild stuff in the gradient descent dynamics / singular learning theory subfield, but solenoidal flux correction has to be a bit. The emperor has no clothes!
2
Cycling in GANs/self-play?
5
That may be true[1]. But it doesn't seem like a particularly useful answer?
"The optimization target is the optimization target."
1. ^
For the outer optimiser that builds the AI
1
I think having all of this in mind as you train is actually pretty important. That way, when something doesn't work, you know where to look:
* Am I exploring enough, or stuck always pulling the first lever? (free energy)
* Is it biased for some reason? (probably the metric)
* Is it stuck not improving? (step or batch size)
Weight-initialization isn't too helpful to think about yet (other than avoiding explosions at the very beginning of training, and maybe a little for transfer learning), but we'll probably get hyper neural networks within a few years.
3
Reward is not the optimization target (during pretraining).
The optimization target (during pretraining) is the minimization of the empirical cross-entropy loss L = -∑log p(xᵢ|x₁,...,xᵢ₋₁), approximating the negative log-likelihood of the next-token prediction task under the autoregressive factorization p(x₁,...,xₙ)=∏p(xᵢ|x₁,...,xᵢ₋₁). The loss is computed over discrete tokens from subword vocabularies, averaged across sequences and batches, with gradient-based updates minimizing this singular objective. The optimization proceeds through multi-stage curricula: initial pretraining minimizing perplexity, followed by context-extension phases maintaining the same cross-entropy objective over longer sequences, and quality-annealing stages that reweight the loss toward higher-quality subsets while preserving the fundamental next-token prediction target.
The post-training optimization target is maximizing expected reward (under distributional constraints). Supervised fine-tuning first minimizes cross-entropy loss on target completions from instruction-response pairs, with optional prompt-masking excluding input tokens from the loss computation. Subsequent alignment introduces the constrained objective max_π E_x~π[R(x)] - βD_KL[π(x)||π_ref(x)], balancing reward maximization against divergence from the reference policy. This manifests through varied algorithmic realizations: Proximal Policy Optimization maximizes the clipped surrogate objective L^CLIP(θ) = E[min(rₜ(θ)Âₜ, clip(rₜ(θ), 1-ε, 1+ε)Âₜ)]; Direct Preference Optimization reformulates to minimize -E[(x_w,x_l)~D][log σ(β log π(x_w)/π_ref(x_w) - β log π(x_l)/π_ref(x_l))]; best-of-N sampling maximizes E[R(x*)] where x* = argmax_{x∈{x₁,...,xₙ}} R(x); Rejection Sampling Fine-tuning minimizes cross-entropy on the subset {x : R(x) > τ}; Kahneman-Tversky Optimization targets E[w(R(x))log π(x)] with prospect-theoretic weighting; Odds Ratio Preference Optimization combines -log π(x_w) - λ log[π(x_w)/(π(x_w) + π(x_l))]. The rew
3
Would you like a zesty vinaigrette or just a sprinkling of more jargon on that word salad?
3
What are solenoidal flux corrections in this context
2
The bits of that I understand seem accurate but also it is not possible in the general case to predict (without doing the training run) how a given random initialization will affect what the final model looks like.
Which might have been the point you were trying to make, not sure.
1
I like this take, especially it's precision, though I disagree in a few places.
This is the wrong metric, but I won't help you find the right one.
You can lower the step-size and increase the batch-size as you train to keep the perturbation bounded. Like, sure, you could claim an ODE solver doesn't give you the exact solution, but adaptive methods let you get within any desired tolerance.
This is another "hyper"parameter to feed into the model. I agree that, at some point, the turtles have to stop, and we can call that the initial weight distribution, though I'd prefer the term 'interpreter'.
Hmm... you sure you're using the right flux? Not all boundaries of boundaries are zero, and GANs (and self-play) probably use a 6-complex.
2[comment deleted]
Shower thought - why are sunglasses cool ?
Sunglasses create an asymmetry in the ability to discern emotions between the wearer and nonwearer. This implicitly makes the wearer less predictable, more mysterious, more dangerous and therefore higher in a dominance hierarchy.
also see ashiok from mtg: whole upper face/head is replaced with shadow
also, masks 'create an asymmetry in the ability to discern emotions' but do not seem to lead to the rest
That's a good counterexample ! Masks are dangerous and mysterious, but not cool in the way sunglasses are in agree
9
I think with sunglasses there’s a veneer of plausible deniability. They in fact have a utilitarian purpose outside of just creating information asymmetry. If you’re wearing a mask though, there’s no deniability. You just don’t want people to know where you’re looking.
3
there is an obvious utilitarian reason of not getting sick
4
Oh I thought they meant like ski masks or something. For illness masks, the reason they’re not cool is very clearly that they imply you’re diseased.
(To a lesser extent too that your existing social status is so low you can’t expect to get away with accidentally infecting any friends or acquaintances, but my first point is more obvious & defensible)
1[anonymous]
oh i meant medical/covid ones. could also consider furry masks and the cat masks that femboys often wear (e.g. to obscure masculine facial structure), which feel cute rather than 'cool', though they are more like the natural human face in that they display an expression ("the face is a mask we wear over our skulls")
4
Yeah pretty clearly these aren’t cool because they imply the wearer is diseased.
1[anonymous]
how? edit: maybe you meant just the first kind
2
Yeah, I meant medical/covid masks imply the wearer is diseased. I would have also believed the cat mask is a medical/covid mask if you hadn't give a different reason for wearing it, so it has that going against it in terms of coolness. It also has a lack of plausible deniability going against it too. If you're wearing sunglasses there's actually a utilitarian reason behind wearing them outside of just creating information asymmetry. If you're just trying to obscure half your face, there's no such plausible deniability. You're just trying to obscure your face, so it becomes far less cool.
6
Sunglasses aren’t cool. They just tint the allure the wearer already has.
5
Isn't this already the commonly-accepted reason why sunglasses are cool?
Anyway, Claude agrees with you (see 1 and 3)
2
Follow-up question: If sunglasses are so cool, why do relatively few people wear them? Perhaps they aren't that cool after all?
9
Sunglasses can be too cool for most people to be able to wear in the absence of a good reason. Tom Cruise can go around wearing sun glasses any time he wants, and it'll look cool on him, because he's Tom Cruise. If we tried that, we would look like dorks because we're not cool enough to pull it off and it would backfire on us. (Maybe our mothers would think we looked cool.) This could be said of many things: Tom Cruise or Kanye West or fashionable celebrities like them can go around wearing a fedora and trench coat and it'll look cool and he'll pull it off; but if anyone else tries it...
2
Yeah. I think the technical term for that would be cringe.
1
More reasons: people wear sunglasses when they’re doing fun things outdoors like going to the beach or vacationing so it’s associated with that, and also sometimes just hiding part of a picture can cause your brain to fill it in with a more attractive completion than is likely.
My timelines are lengthening.
I've long been a skeptic of scaling LLMs to AGI *. To me I fundamentally don't understand how this is even possible. It must be said that very smart people give this view credence. davidad, dmurfet. on the other side are vanessa kosoy and steven byrnes. When pushed proponents don't actually defend the position that a large enough transformer will create nanotech or even obsolete their job. They usually mumble something about scaffolding.
I won't get into this debate here but I do want to note that my timelines have lengthened, primarily because some of the never-clearly-stated but heavily implied AI developments by proponents of very short timelines have not materialized. To be clear, it has only been a year since gpt-4 is released, and gpt-5 is around the corner, so perhaps my hope is premature. Still my timelines are lengthening.
A year ago, when gpt-3 came out progress was blindingly fast. Part of short timelines came from a sense of 'if we got surprised so hard by gpt2-3, we are completely uncalibrated, who knows what comes next'.
People seemed surprised by gpt-4 in a way that seemed uncalibrated to me. gpt-4 performance was basically in li...
With scale, there is visible improvement in difficulty of novel-to-chatbot ideas/details that is possible to explain in-context, things like issues with the code it's writing. If a chatbot is below some threshold of situational awareness of a task, no scaffolding can keep it on track, but for a better chatbot trivial scaffolding might suffice. Many people can't google for a solution to a technical issue, the difference between them and those who can is often subtle.
So modest amount of scaling alone seems plausibly sufficient for making chatbots that can do whole jobs almost autonomously. If this works, 1-2 OOMs more of scaling becomes both economically feasible and more likely to be worthwhile. LLMs think much faster, so they only need to be barely smart enough to help with clearing those remaining roadblocks.
2
You may be right. I don't know of course.
At this moment in time, it seems scaffolding tricks haven't really improved the baseline performance of models that much. Overwhelmingly, the capability comes down to whether the rlfhed base model can do the task.
4
That's what I'm also saying above (in case you are stating what you see as a point of disagreement). This is consistent with scaling-only short timeline expectations. The crux for this model is current chatbots being already close to autonomous agency and to becoming barely smart enough to help with AI research. Not them directly reaching superintelligence or having any more room for scaling.
Yes agreed.
What I don't get about this position: If it was indeed just scaling - what's AI research for ? There is nothing to discover, just scale more compute. Sure you can maybe improve the speed of deploying compute a little but at the core of it it seems like a story that's in conflict with itself?
5
My view is that there's huge algorithmic gains in peak capability, training efficiency (less data, less compute), and inference efficiency waiting to be discovered, and available to be found by a large number of parallel research hours invested by a minimally competent multimodal LLM powered research team. So it's not that scaling leads to ASI directly, it's:
1. scaling leads to brute forcing the LLM agent across the threshold of AI research usefulness
2. Using these LLM agents in a large research project can lead to rapidly finding better ML algorithms and architectures.
3. Training these newly discovered architectures at large scales leads to much more competent automated researchers.
4. This process repeats quickly over a few months or years.
5. This process results in AGI.
6. AGI, if instructed (or allowed, if it's agentically motivated on its own to do so) to improve itself will find even better architectures and algorithms.
7. This process can repeat until ASI. The resulting intelligence / capability / inference speed goes far beyond that of humans.
Note that this process isn't inevitable, there are many points along the way where humans can (and should, in my opinion) intervene. We aren't disempowered until near the end of this.
4
Why do you think there are these low-hanging algorithmic improvements?
Here are two arguments for low-hanging algorithmic improvements.
First, in the past few years I have read many papers containing low-hanging algorithmic improvements. Most such improvements are a few percent or tens of percent. The largest such improvements are things like transformers or mixture of experts, which are substantial steps forward. Such a trend is not guaranteed to persist, but that’s the way to bet.
Second, existing models are far less sample-efficient than humans. We receive about a billion tokens growing to adulthood. The leading LLMs get orders of magnitude more than that. We should be able to do much better. Of course, there’s no guarantee that such an improvement is “low hanging”.
3
Capturing this would probably be a big deal, but a counterpoint is that compute necessary to achieve an autonomous researcher using such sample efficient method might still be very large. Possibly so large that training an LLM with the same compute and current sample-inefficient methods is already sufficient to get a similarly effective autonomous researcher chatbot. In which case there is no effect on timelines. And given that the amount of data is not an imminent constraint on scaling, the possibility of this sample efficiency improvement being useless for the human-led stage of AI development won't be ruled out for some time yet.
2
Could you train an LLM on pre 2014 Go games that could beat AlphaZero?
I rest my case.
2
The best method of improving sample efficiency might be more like AlphaZero. The simplest method that's more likely to be discovered might be more like training on the same data over and over with diminishing returns. Since we are talking low-hanging fruit, I think it's reasonable that first forays into significantly improved sample efficiency with respect to real data are not yet much better than simply using more unique real data.
2
I would be genuinely surprised if training a transformer on the pre2014 human Go data over and over would lead it to spontaneously develop alphaZero capacity. I would expect it to do what it is trained to: emulate / predict as best as possible the distribution of human play. To some degree I would anticipate the transformer might develop some emergent ability that might make it slightly better than Go-Magnus - as we've seen in other cases - but I'd be surprised if this would be unbounded. This is simply not what the training signal is.
2
We start with an LLM trained on 50T tokens of real data, however capable it ends up being, and ask how to reach the same level of capability with synthetic data. If it takes more than 50T tokens of synthetic data, then it was less valuable per token than real data.
But at the same time, 500T tokens of synthetic data might train an LLM more capable than if trained on the 50T tokens of real data for 10 epochs. In that case, synthetic data helps with scaling capabilities beyond what real data enables, even though it's still less valuable per token.
With Go, we might just be running into the contingent fact of there not being enough real data to be worth talking about, compared with LLM data for general intelligence. If we run out of real data before some threshold of usefulness, synthetic data becomes crucial (which is the case with Go). It's unclear if this is the case for general intelligence with LLMs, but if it is, then there won't be enough compute to improve the situation unless synthetic data also becomes better per token, and not merely mitigates the data bottleneck and enables further improvement given unbounded compute.
I expect that if we could magically sample much more pre-2014 unique human Go data than was actually generated by actual humans (rather than repeating the limited data we have), from the same platonic source and without changing the level of play, then it would be possible to cheaply tune an LLM trained on it to play superhuman Go.
4
I don't know what you mean by 'general intelligence' exactly but I suspect you mean something like human+ capability in a broad range of domains. I agree LLMs will become generally intelligent in this sense when scaled, arguably even are, for domains with sufficient data. But that's kind of the sticker right? Cave men didn't have the whole internet to learn from yet somehow did something that not even you seem to claim LLMs will be able to do: create the (date of the) Internet.
(Your last claim seems surprising. Pre-2014 games don't have close to the ELO of alphaZero. So a next-token would be trained to simulate a human player up tot 2800, not 3200+. )
4
Models can be thought of as repositories of features rather than token predictors. A single human player knows some things, but a sufficiently trained model knows all the things that any of the players know. Appropriately tuned, a model might be able to tap into this collective knowledge to a greater degree than any single human player. Once the features are known, tuning and in-context learning that elicit their use are very sample efficient.
This framing seems crucial for expecting LLMs to reach researcher level of capability given a realistic amount of data, since most humans are not researchers, and don't all specialize in the same problem. The things researcher LLMs would need to succeed in learning are cognitive skills, so that in-context performance gets very good at responding to novel engineering and research agendas only seen in-context (or a certain easier feat that I won't explicitly elaborate on).
Possibly the explanation for the Sapient Paradox, that prehistoric humans managed to spend on the order of 100,000 years without developing civilization, is that they lacked cultural knowledge of crucial general cognitive skills. Sample efficiency of the brain enabled their fixation in language across cultures and generations, once they were eventually distilled, but it took quite a lot of time.
Modern humans and LLMs start with all these skills already available in the data, though humans can more easily learn them. LLMs tuned to tap into all of these skills at the same time might be able to go a long way without an urgent need to distill new ones, merely iterating on novel engineering and scientific challenges, applying the same general cognitive skills over and over.
1
When I brought up sample inefficiency, I was supporting Mr. Helm-Burger‘s statement that “there's huge algorithmic gains in …training efficiency (less data, less compute) … waiting to be discovered”. You’re right of course that a reduction in training data will not necessarily reduce the amount of computation needed. But once again, that’s the way to bet.
2
I'm ambivalent on this. If the analogy between improvement of sample efficiency and generation of synthetic data holds, synthetic data seems reasonably likely to be less valuable than real data (per token). In that case we'd be using all the real data we have anyway, which with repetition is sufficient for up to about $100 billion training runs (we are at $100 million right now). Without autonomous agency (not necessarily at researcher level) before that point, there won't be investment to go over that scale until much later, when hardware improves and the cost goes down.
4
My answer to that is currently in the form of a detailed 2 hour lecture with a bibliography that has dozens of academic papers in it, which I only present to people that I'm quite confident aren't going to spread the details. It's a hard thing to discuss in detail without sharing capabilities thoughts. If I don't give details or cite sources, then... it's just, like, my opinion, man. So my unsupported opinion is all I have to offer publicly. If you'd like to bet on it, I'm open to showing my confidence in my opinion by betting that the world turns out how I expect it to.
4
The story involves phase changes. Just scaling is what's likely to be available to human developers in the short term (a few years), it's not enough for superintelligence. Autonomous agency secures funding for a bit more scaling. If this proves sufficient to get smart autonomous chatbots, they then provide speed to very quickly reach the more elusive AI research needed for superintelligence.
It's not a little speed, it's a lot of speed, serial speedup of about 100x plus running in parallel. This is not as visible today, because current chatbots are not capable of doing useful work with serial depth, so the serial speedup is not in practice distinct from throughput and cost. But with actually useful chatbots it turns decades to years, software and theory from distant future become quickly available, non-software projects get to be designed in perfect detail faster than they can be assembled.
3
In my mainline model there are only a few innovations needed, perhaps only a single big one to product an AGI which just like the Turing Machine sits at the top of the Chomsky Hierarchy will be basically the optimal architecture given resource constraints. There are probably some minor improvements todo with bridging the gap between theoretically optimal architecture and the actual architecture, or parts of the algorithm that can be indefinitely improved but with diminishing returns (these probably exist due to Levin and possibly.matrix.multiplication is one of these). On the whole I expect AI research to be very chunky.
Indeed, we've seen that there was really just one big idea to all current AI progress: scaling, specifically scaling GPUs on maximally large undifferentiated datasets. There were some minor technical innovations needed to pull this off but on the whole that was the clinger.
Of course, I don't know. Nobody knows. But I find this the most plausible guess based on what we know about intelligence, learning, theoretical computer science and science in general.
2
(Re: Difficult to Parse react on the other comment
I was confused about relevance of your comment above on chunky innovations, and it seems to be making some point (for which what it actually says is an argument), but I can't figure out what it is. One clue was that it seems like you might be talking about innovations needed for superintelligence, while I was previously talking about possible absence of need for further innovations to reach autonomous researcher chatbots, an easier target. So I replied with formulating this distinction and some thoughts on the impact and conditions for reaching innovations of both kinds. Possibly the relevance of this was confusing in turn.)
2
There are two kinds of relevant hypothetical innovations: those that enable chatbot-led autonomous research, and those that enable superintelligence. It's plausible that there is no need for (more of) the former, so that mere scaling through human efforts will lead to such chatbots in a few years regardless. (I think it's essentially inevitable that there is currently enough compute that with appropriate innovations we can get such autonomous human-scale-genius chatbots, but it's unclear if these innovations are necessary or easy to discover.) If autonomous chatbots are still anything like current LLMs, they are very fast compared to humans, so they quickly discover remaining major innovations of both kinds.
In principle, even if innovations that enable superintelligence (at scale feasible with human efforts in a few years) don't exist at all, extremely fast autonomous research and engineering still lead to superintelligence, because they greatly accelerate scaling. Physical infrastructure might start scaling really fast using pathways like macroscopic biotech even if drexlerian nanotech is too hard without superintelligence or impossible in principle. Drosophila biomass doubles every 2 days, small things can assemble into large things.
9
Wasn't the surprising thing about GPT-4 that scaling laws did hold? Before this many people expected scaling laws to stop before such a high level of capabilities. It doesn't seem that crazy to think that a few more OOMs could be enough for greater than human intelligence. I'm not sure that many people predicted that we would have much faster than scaling law progress (at least until ~human intelligence AI can speed up research)? I think scaling laws are the extreme rate of progress which many people with short timelines worry about.
3
To some degree yes, they were not guaranteed to hold. But by that point they held for over 10 OOMs iirc and there was no known reason they couldn't continue.
This might be the particular twitter bubble I was in but people definitely predicted capabilities beyond simple extrapolation of scaling laws.
8
Can you expand on what you mean by "create nanotech?" If improvements to our current photolithography techniques count, I would not be surprised if (scaffolded) LLMs could be useful for that. Likewise for getting bacteria to express polypeptide catalysts for useful reactions, and even maybe figure out how to chain several novel catalysts together to produce something useful (again, referring to scaffolded LLMs with access to tools).
If you mean that LLMs won't be able to bootstrap from our current "nanotech only exists in biological systems and chip fabs" world to Drexler-style nanofactories, I agree with that, but I expect things will get crazy enough that I can't predict them long before nanofactories are a thing (if they ever are).
Likewise, I don't think LLMs can immediately obsolete all of the parts of my job. But they sure do make parts of my job a lot easier. If you have 100 workers that each spend 90% of their time on one specific task, and you automate that task, that's approximately as useful as fully automating the jobs of 90 workers. "Human-equivalent" is one of those really leaky abstractions -- I would be pretty surprised if the world had any significant resemblance to the world of today by the time robotic systems approached the dexterity and sensitivity of human hands for all of the tasks we use our hands for, whereas for the task of "lift heavy stuff" or "go really fast" machines left us in the dust long ago.
Iterative improvements on the timescale we're likely to see are still likely to be pretty crazy by historical standards. But yeah, if your timelines were "end of the world by 2026" I can see why they'd be lengthening now.
2
My timelines were not 2026. In fact, I made bets against doomers 2-3 years ago, one will resolve by next year.
I agree iterative improvements are significant. This falls under "naive extrapolation of scaling laws".
By nanotech I mean something akin to drexlerian nanotech or something similarly transformative in the vicinity. I think it is plausible that a true ASI will be able to make rapid progress (perhaps on the order of a few years or a decade) on nanotech. I suspect that people that don't take this as a serious possibility haven't really thought through what AGI/ASI means + what the limits and drivers of science and tech really are; I suspect they are simply falling prey to status-quo bias.
6
I don't recall what I said in the interview about your beliefs, but what I meant to say was something like what you just said in this post, apologies for missing the mark.
6
Lengthening from what to what?
4
I've never done explicit timelines estimates before so nothing to compare to. But since it's a gut feeling anyway, I'm saying my gut is lengthening.
5
Agreed. I'm also pleasantly surprised that your take isn't heavily downvoted.
4
Links to Dan Murfet's AXRP interview:
* Transcript
* Video
3
State-of-the-art models such as Gemini aren't LLMs anymore. They are natively multimodal or omni-modal transformer models that can process text, images, speech and video. These models seem to me like a huge jump in capabilities over text-only LLMs like GPT-3.
3
Chain-of-thought prompting makes models much more capable. In the original paper "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models", PaLM 540B with standard prompting only solves 18% of problems but 57% of problems with chain-of-thought prompting.
I expect the use of agent features such as reflection will lead to similar large increases in capabilities as well in the near future.
6
Those numbers don't really accord with my experience actually using gpt-4. Generic prompting techniques just don't help all that much.
5
I just asked GPT-4 a GSM8K problem and I agree with your point. I think what's happening is that GPT-4 has been fine-tuned to respond with chain-of-thought reasoning by default so it's no longer necessary to explicitly ask it to reason step-by-step. Though if you ask it to "respond with just a single number" to eliminate the chain-of-thought reasoning it's problem-solving ability is much worse.
0
Mumble.
Free energy and (mis)alignment
The classical MIRI views imagines human values to be a tiny squiggle in a vast space of alien minds. The unfathomable inscrutable process of deep learning is very unlikely to pick exactly that tiny squiggle, instead converging to a fundamentally incompatible and deeply alien squiggle. Therein lies the road to doom.
Optimists will object that deep learning doesn't randomly sample from the space of alien minds. It is put under a strong gradient pressure to satisfy human preference in-distribution / during the training phase. One could, and many people have, similarly object that it's hard or even impossible for deep learning systems to learn concepts that aren't naive extrapolations of its training data[cf symbol grounding talk]. In fact, Claude is very able to verbalize human ethics and values.
Any given behaviour and performance on the training set is compatible with any given behaviour outside the training set. One can hardcode backdoors into a neural network that can behave nicely on training and arbitrarily differently outside training. Moreover, these backdoors can be implemented in such a way as to be computationally intractable to res...
In AI alignment, the entropic force pulls toward sampling random minds from the vast space of possible minds, while the energetic force (from training) pulls toward minds that behave as we want. The actual outcome depends on which force is stronger.
The MIRI view, I'm pretty sure, is that the force of training does not pull towards minds that behave as we want, unless we know a lot of things about training design we currently don't.
MIRI is not talking about the randomness as in the spread of the training posterior as a function of random Bayesian sampling/NN initialization/SGD noise. The point isn't that training is inherently random. It can be a completely deterministic process without affecting the MIRI argument basically at all. If everything were a Bayesian sample from the posterior and there was a single basin of minimum local learning coefficient corresponding to equivalent implementations of a single algorithm, then I don't think this would by default make models any more likely to be aligned. The simplest fit to the training signal need not be an optimiser pointed at a terminal goal that maps to the training signal in a neat way humans can intuitively zero-shot without figur...
4
I'm not following exactly what you are saying here so I might be collapsing some subtle point. Let me preface that this is a shortform so half-baked by design so you might be completely right it's confused.
Let me try and explain myself again.
I probably have confused readers by using the free energy terminology. What I mean is that in many cases (perhaps all) the probabilistic outcome of any process can be described in terms of a competition of between simplicity (entropy) and accuracy (energy) to some loss function.
Indeed, the simplest fit for a training signal might not be aligned. In some cases perhaps almost all fits for a training signal create an agent whose values are only a somewhat constrained by the training signal and otherwise randomly sampled conditional on doing well on the training signal. The "good" values might be only a small part of this subspace.
Perhaps you and Dmitry are saying the issue is not just an simplicity-accuracy / entropy-energy split but also a case that the training signal not perfectly "sampled from true goodly human values". There would be another error coming from this incongruency?
Hope you can enlighten me.
4
I was excited by the first half, seeing you relate classic Agent Foundations thinking to current NN training regimes, and try to relate the optimist/pessimist viewpoints.
Then we hit free energy and entropy. These seem like needlessly complex metaphors, providing no strong insight on the strength of the factors pushing toward and pulling away from alignment.
Analyzing those "forces" or tendencies seems like it's crucially important, but needs to go deeper than a metaphor or use a much more fitting metaphor to get traction.
Nonetheless, upvoted for working on the important stuff even when it's hard!
2
I probably shouldnt have used the free energy terminology. Does complexity accuracy tradeoff work better ?
To be clear, I very much dont mean these things as a metaphor. I am thinking there may be an actual numerical complexity - accuracy that is some elaboration of Watanabe s "free energy" formula that actually describes these tendencies.
3
I'm not sure I agree with this -- this seems like you're claiming that misalignment is likely to happen through random diffusion. But I think most worries about misalignment are more about correlated issues, where the training signal consistently disincentivizes being aligned in a subtle way (e.g. a stock trading algorithm manipulating the market unethically because the pressure of optimizing income at any cost diverges from the pressure of doing what its creators would want it to do). If diffusion were the issue, it would also affect humans and not be special to AIs. And while humans do experience value drift, cultural differences, etc., I think we generally abstract these issues as "easier" than the "objective-driven" forms of misalignment
6
I agree that Goodharting is an issue, and this has been discussed as a failure mode, but a lot of AI risk writing definitely assumed that something like random diffusion was a non-trivial component of how AI alignment failures happened.
For example, pretty much all of the reasoning around random programs being misaligned/bad is using the random diffusion argument.
4
The free energy talk probably confuses more than that it elucidates. Im not talking about random diffusion per se but connection between uniformly sampling and simplicity and simplicity-accuracy tradeoff.
Ive tried explaining more carefully where my thinking is currently at in my reply to lucius.
Also caveat that shortforms are halfbaked-by-design.
4
Yep, have been recently posting shortforms (as per your recommendation), and totally with you on the "halfbaked-by-design" concept (if Cheeseboard can do it, it must be a good idea right? :)
I still don't agree that free energy is core here. I think that the relevant question, which can be formulated without free energy, is whether various "simplicity/generality" priors push towards or away from human values (and you can then specialize to questions of effective dimension/llc, deep vs. shallow networks, ICL vs. weight learning, generalized ood generalization measurements, and so on to operationalize the inductive prior better). I don't think there's a consensus on whether generality is "good" or "bad" -- I know Paul Christiano and ARC has gone both ways on this at various points.
2
I think simplicity/generality priors effectively have 0 effect on whether it's pushed towards or away from human values, and is IMO kind of orthogonal to alignment-relevant questions.
2
I'd be curious how you would describe the core problem of alignment.
2
I'd split it into how do we manage to instill in any goal/value that is ideally at least somewhat stable, ala inner alignment, and outer alignment, which is selecting a goal that is resistant to Goodharting.
2
Let's focus on inner alignment. By instill you presumably mean train. What values get trained is ultimately a learning problem which in many cases (as long as one can formulate approximately a boltzmann distribution) comes down to a simplicity-accuracy tradeoff.
2
Could you give some examples of what you are thinking of here ?
2
You mean on more general algorithms being good vs. bad?
2
Yes.
2
I haven't thought about this enough to have a very mature opinion. On one hand being more general means you're liable to goodheart more (i.e., with enough deeply general processing power, you understand that manipulating the market to start World War 3 will make your stock portfolio grow, so you act misaligned). On the other hand being less general means that AI's are more liable to "partially memorize" how to act aligned in familiar situations, and go off the rails when sufficiently out-of-distribution situations are encountered. I think this is related to the question of "how general are humans", and how stable are human values to being much more or much less general
2
I guess im mostly thinking about the regime where AIs are more capable and general than humans.
It seems at first glance that the latter failure mode is more of a capability failure. Something one would expect to go away as AI truly surpasses humans. It doesnt seem core to the alignment problem to me.
2
Maybe a reductive summary is "general is good if outer alignment is easy but inner alignment is hard, but bad in the opposite case"
2
Isn't it the other way around ?
If inner alignment is hard then general is bad because applying less selection pressure, i.e. more generally, more simplicity prior, means more daemons/gremlins
Encrypted Batteries
(I thank Dmitry Vaintrob for the idea of encrypted batteries. Thanks to Adam Scholl for the alignment angle. Thanks to the Computational Mechanics at the receent compMech conference. )
There are no Atoms in the Void just Bits in the Description. Given the right string a Maxwell Demon transducer can extract energy from a heatbath.
Imagine a pseudorandom heatbath + nano-Demon. It looks like a heatbath from the outside but secretly there is a private key string that when fed to the nano-Demon allows it to extra lots of energy from the heatbath.
P.S. Beyond the current ken of humanity lies a generalized concept of free energy that describes the generic potential ability or power of an agent to achieve goals. Money, the golden calf of Baal is one of its many avatars. Could there be ways to encrypt generalized free energy batteries to constraint the user to only see this power for good? It would be like money that could be only spent on good things.
Imagine a pseudorandom heatbath + nano-Demon. It looks like a heatbath from the outside but secretly there is a private key string that when fed to the nano-Demon allows it to extra lots of energy from the heatbath.
What would a 'pseudorandom heatbath' look like? I would expect most objects to quickly depart from any sort of private key or PRNG. Would this be something like... a reversible computer which shuffles around a large number of blank bits in a complicated pseudo-random order every timestep*, exposing a fraction of them to external access? so a daemon with the key/PRNG seed can write to the blank bits with approaching 100% efficiency (rendering it useful for another reversible computer doing some actual work) but anyone else can't do better than 50-50 (without breaking the PRNG/crypto) and that preserves the blank bit count and is no gain?
* As I understand reversible computing, you can have a reversible computer which does that for free: if this is something like a very large period loop blindly shuffling its bits, it need erase/write no bits (because it's just looping through the same states forever, akin to a time crystal), and so can be computed indefinitely at arbitrarily low energy cost. So any external computer which syncs up to it can also sync at zero cost, and just treat the exposed unused bits as if they were its own, thereby saving power.
2
That is my understanding, yes.
2
Yeah I'm pretty sure you would need to violate heisenberg uncertainty in order to make this and then you'd have to keep it in a 0 kelvin cleanroom forever.
A practical locked battery with tamperproofing would mostly just look like a battery.
Additive versus Multiplicative model of AI-assisted research
Occasionally one hears somebody say "most of the relevant AI-safety work will be done at crunch time. Most work being done now at present is marginal".
One cannot shake the suspicion that this statement merely reflects the paucity of ideas & vision of the speaker. Yet it cannot be denied that their reasoning has a certain logic: if, as seems likely, AI will become more and more dominant in AI alignment research than maybe we should be focusing on how to safely extract work from future superintelligent machines rather than hurting our painfully slow mammalian walnuts to crack AI safety research today. I understand this to be a key motivation for several popular agendas AI safety.
Similarly, many Pause advocates argue that pause advocacy is more impactful than direct research. Most will admit that a Pause cannot be maintained indefinitely. The aim of a Pause would be to buy time to figure out alignment. Unless one believes in very long pauses, implicitly it seems there is an assumption that research progress will be faster in the future.
Implicitly, we might say there is underlying " Additive" model of AI-...
9
Let's say you want AIs in Early Crunch Time to solve your pet problem X, and you think the bottleneck will be your ability to oversee, supervise, direct, and judge the AI's research output.
Here are two things you can do now, in 2025:
1. You can do X research yourself, so that you know more about X and can act like a grad supervisor.
2. You can work on scalable oversight = {cot monitoring, activation monitoring, control protocols, formal verification, debate} so you can deploy more powerful models for the same chance of catastrophe.
I expect (2) will help more with X. I don't think being a grad supervisor will be a bottleneck for very long, compared with stuff like 'we can't deploy the more powerful AI bc our scalable oversight isn't good enough to prevent catastrophe'. It also has the nice property that the gains will spread to everyone's pet problem, not just your own.
6
I'm having trouble seeing that (2) is actually a thing?
The whole problem is that there is no generally agreed " chance of catastrophe" so " same change of catastrophe" has no real meaning.
It seems this kind of talk is being backchained from what governance people want as opposed to the reality of safety guarantees or safety/risk probabilities - which is that they don't meaningfully exist [outside of super heuristic guesses].
Indeed, to estimate this probability in a non-bullshit way we exactly need fundamental scientific progress, i.e. (1).
EA has done this exercise a dozen times: if you ask experts the probabilities of doom it ranges all the way from 99% to 0.0001 %.
Will that change? Will expert judgement converge? Maybe. Maybe not. I don't have a crystal ball.
Even if they do [outside of meaningful progress on (1)] those probabilities won't actually reflect reality as opposed to political reality.
The problem is there is no ' scientific' way to estimate p(doom) and as long as we don't make serious progress on 1. there won't be.
I don't see how cot/activation/control monitoring will have any significant and scientifically -grounded [as opposed to purely story-telling/politics] influence in a way that can be measured and can be utilized to make risk-tradeoffs.
2
What matters here is the chance that a particular model in a particular deployment plan will cause a particular catastrophe. And this is after the model has been trained and evaluated and redteamed and mech interped (imperfectly ofc). I don't except such divergent probabilities from experts.
4
Referring to particular models and particular deployment plans and particular catastrophe doesn't help - the answer is the same.
We don't know how to scientifically quantify any of these probabilities.
2
You can replace "deployment plan P1 has same chance of catastrophe as deployment plan P2" with "the safety team is equally worried by P1 and P2".
4
In Pre-Crunch Time, here's what I think we should be working on:
1. Problems that need to be solved in order that we can safely and usefully accelerate R&D, i.e. scalable oversight
2. Problems that will be hard to accelerate with R&D, e.g. very conceptual stuff, policy
3. Problems that you think, with a few years of grinding, could be reduced from hard-to-accelerate to easy-to-accelerate, e.g. ARC Theory
Notably, what 'work' looks like on these problems will depend heavily on which of the three buckets it belongs to.
3
Is one takeaway of your post that we should consider current safety research as more about training human researchers than about the actual knowledge obtained from the research?
6
I didn't intend it that way, though admittedly that is a valid reading. From my own point of view both functions seem significant.
4
I think there’s a lot of truth to this - modern LLMs are kind of competence multiplier, where some competence values are negative (perhaps a competence exponentiator?).
I find that I can extract value from LLMs only if I’m asking about something that I almost already know. That way I can judge whether an answer is getting at the wrong thing, assess the relevance of citations, and verify a correct answer rapidly and highly robustly if it is offered (which is important because typically a series of convincing non-answers or wrong answers comes first).
Though LLMs seem to be getting more useful in the best case, they also seem to be getting more dangerous in the worst case, so I am not sure whether this dynamic will soften or sharpen over time.
People are not thinking clearly about AI-accelerated AI research. This comment by Thane Ruthenis is worth amplifying.
...I'm very skeptical of AI being on the brink of dramatically accelerating AI R&D.
My current model is that ML experiments are bottlenecked not on software-engineer hours, but on compute. See Ilya Sutskever's claim here:
95% of progress comes from the ability to run big experiments quickly. The utility of running many experiments is much less useful.
What actually matters for ML-style progress is picking the correct trick, and then applying it to a big-enough model. If you pick the trick wrong, you ruin the training run, which (a) potentially costs millions of dollars, (b) wastes the ocean of FLOP you could've used for something else.
And picking the correct trick is primarily a matter of research taste, because:
- Tricks that work on smaller scales often don't generalize to larger scales.
- Tricks that work on larger scales often don't work on smaller scales (due to bigger ML models having various novel emergent properties).
- Simultaneously integrating several disjunctive incremental improvements into one SotA training run is likely nontrivial/impossible in the general
9
To 10x the compute, you might need to 10x the funding, which AI capable of automating AI research can secure in other ways. Smaller-than-frontier experiments don't need unusually giant datacenters (which can be challenging to build quickly), they only need a lot of regular datacenters and the funding to buy their time. Currently there are millions of H100 chips out there in the world, so 100K H100 chips in a giant datacenter is not the relevant anchor for the scale of smaller experiments, the constraint is funding.
8
Thanks for amplifying. I disagree with Thane on some things they said in that comment, and I don't want to get into the details publicly, but I will say:
1. it's worth looking at DeepSeek V3 and what they did with a $5.6 million training run (obviously that is still a nontrivial amount / CEO actively says most of the cost of their training runs is coming from research talent),
2. compute is still a bottleneck (and why I'm looking to build an ai safety org to efficiently absorb funding/compute for this), but I think Thane is not acknowledging that some types of research require much more compute than others (tho I agree research taste matters, which is also why DeepSeek's CEO hires for cracked researchers, but don't think it's an insurmountable wall),
3. "Simultaneously integrating several disjunctive incremental improvements into one SotA training run is likely nontrivial/impossible in the general case." Yes, seems really hard and a bottleneck...for humans and current AIs.
1. imo, AI models will become Omega Cracked at infra and hyper-optimizing training/inference to keep costs down soon enough (which seems to be what DeepSeek is especially insanely good at)
4
Is this because it would reveal private/trade-secret information, or is this for another reason?
4
Yes (all of the above)
2
If you knew it was legal to disseminate the information, and trade-secret/copyright/patent law didn't apply, would you still not release it?
4
I mean that it's a trade secret for what I'm personally building, and I would also rather people don't just use it freely for advancing frontier capabilities research.
5
See my response here.
The Marginal Returns of Intelligence
A lot of discussion of intelligence considers it as a scalar value that measures a general capability to solve a wide range of tasks. In this conception of intelligence it is primarily a question of having a ' good Map' . This is a simplistic picture since it's missing the intrinsic limits imposed on prediction by the Territory. Not all tasks or domains have the same marginal returns to intelligence - these can vary wildly.
Let me tell you about a 'predictive efficiency' framework that I find compelling & deep and that will hopefully give you some mathematical flesh to these intuitions. I initially learned about these ideas in the context of Computational Mechanics, but I realized that there underlying ideas are much more general.
Let be a predictor variable that we'd like to use to predict a target variable under a joint distribution . For instance could be the contex window and could be the next hundred tokens, or could be the past market data and is the future market data.
In any prediction task there are three fundamental and independently varying quantities that you need to think of:
7
I cannot comment on the math, but intuitively this seems wrong.
Zagorsky (2007) found that while IQ correlates with income, the relationship becomes increasingly non-linear at higher IQs and suggests exponential rather than logarithmic returns.
Sinatra et al. (2016) found that high-impact research is produced by a small fraction of exceptional scientists, significantly exceeding their simply above-average peers.
Lubinski and Benbow in their Study of Mathematically Precocious Youth found that those in the top 0.01% of ability achieve disproportionately greater outcomes than those in (just) the top 1%.
My understanding is that empirical evidence points toward power law distributions in the relationship between intelligence and real-world impact, and that intelligence seems to broadly enable exponentially improving abilities to modify the world in your preferred image. I'm not sure why this is.
3
The most straightforward explanation would be that there are more underexploited niches for top-0.01%-intelligence people than there are top-1%-intelligence people.
2
I don't dispute these facts.
2
Dunno if this is meant to be inspired by/a formalization of [my previous position against intelligence](https://www.lesswrong.com/posts/puv8fRDCH9jx5yhbX/johnswentworth-s-shortform?commentId=jZ2KRPoxEWexBoYSc). But if it is meant to be inspired by it, I just want to flag/highlight that this is the opposite of my position because I'd say intelligence does super well on this hypothetical task because it can just predict 50/50 and be nearly optimal. (Which doesn't imply low marginal return to intelligence because then you could go apply the intelligence to other tasks.) I also think it is extremely intelligent [perjorative] of you to say that this sort of thing is common in archaeology and political forecasting.
2
People read more into this shortform than I intended. It is not a cryptic reaction, criticism, or reply to/of another post.
I don't know what you mean by intelligent [pejorative] but it sounds sarcarcastic.
To be clear, the low predictive efficiency is not a dig at archeology. It seems I have triggered something here.
Whether a question/domain has low or high (marginal) predictive effiency is not a value judgement, just an observation.
2
Ah, fair enough! I just thought given the timing, it might be that you had seen my post and thought a bit about the limitations of intelligence.
The reason I call it intelligent is: Intelligence is the ability to make use of patterns. If one was to look for patterns in intelligent political forecasting and archaeology, or more generally patterns in the application of intelligence and in the discussion of the limitations of intelligence, then what you've written is a sort of convergent outcome.
It's [perjorative] because it's bad.
I mean I'm just highlighting it here because I thought it was probably a result of my comments elsewhere and if so I wanted to ping that it was the opposite of what I was talking about.
If it's unrelated then... I don't exactly want to say "carry on" because I still think it's bad, but I'm not exactly sure where to begin or how you ended up with this line of inquiry, so I don't exactly have much to comment on.
2
I am not sure what 'it' refers to in 'it is bad'.
AGI companies merging within next 2-3 years inevitable?
There are currently about a dozen major AI companies racing towards AGI with many more minor AI companies. The way the technology shakes out this seems like unstable equilibrium.
It seems by now inevitable that we will see further mergers, joint ventures - within two years there might only be two or three major players left. Scale is all-dominant. There is no magic sauce, no moat. OpenAI doesn't have algorithms that her competitors can't copy within 6-12 months. It's all leveraging compute. Whatever innovations smaller companies make can be easily stolen by tech giants.
e.g. we might have xAI- Meta, Anthropic- DeepMind-SSI-Google, OpenAI-Microsoft-Apple.
Actuallly, although this would be deeply unpopular in EA circles it wouldn't be all that surprising if Anthropic and OpenAI would team up.
And - of course - a few years later we might only have two competitors: USA, China.
EDIT: the obvious thing to happen is that nvidia realizes it can just build AI itself. if Taiwan is Dune, GPUs are the spice, then nvidia is house Atreides
Whatever innovations smaller companies make can be easily stolen by tech giants.
And they / their basic components are probably also published by academia, though the precise hyperparameters, etc. might still matter and be non-trivial/costly to find.
I have a similar feeling, but there are some forces in the opposite direction:
- Nvidia seems to limit how many GPUs a single competitor can acquire.
- training frontier models becomes cheaper over time. Thus, those that build competitive models some time later than the absolute frontier have to invest much less resources.
In 2-3 years they would need to decide on training systems built in 3-5 years, and by 2027-2029 the scale might get to $200-1000 billion for an individual training system. (This is assuming geographically distributed training is solved, since such systems would need 5-35 gigawatts.)
Getting to a go-ahead on $200 billion systems might require a level of success that also makes $1 trillion plausible. So instead of merging, they might instead either temporarily give up on scaling further (if there isn't sufficient success in 2-3 years), or become capable of financing such training systems individually, without pooling efforts.
4
They've already started...
3
For similar arguments, I think it's gonna be very hard/unlikely to stop China from having AGI within a couple of years of the US (and most relevant AI chips currently being produced in Taiwan should probably further increase the probability of this). So taking on a lot more x-risk to try and race hard vs. China doesn't seem like a good strategy from this POV.
Current work on Markov blankets and Boundaries on LW is flawed and outdated. State of the art should factor through this paper on Causal Blankets; https://iwaiworkshop.github.io/papers/2020/IWAI_2020_paper_22.pdf
A key problem for accounts of blankets and boundaries I have seen on LW so far is the following elementary problem (from the paper):
"Therefore, the MB [Markov Blanket] formalism forbids interdependencies induced by past events that are kept in memory, but may not directly influence the present state of the blankets.
Thanks to Fernando Rosas telling me about this paper.
You may want to make this a linkpost to that paper as that can then be tagged and may be noticed more widely.
1
I have only skimmed the paper.
Is my intuition correct that in the MB formalism, past events that are causally linked to are not included in the Markov Blanket, but the node corresponding to the memory state still is included in the MB?
That is, the influence of the past event is mediated by a node corresponding to having memory of that past event?
3
Well, past events--before some time t--kind of obviously can't be included in the Markov blanket at time t.
As far as I understand it, the MB formalism captures only momentary causal interactions between "Inside" and "Outside" but doesn't capture a kind of synchronicity/fine-tuning-ish statistical dependency that doesn't manifest in the current causal interactions (across the Markov blanket) but is caused by past interactions.
For example, if you learned a perfect weather forecast for the next month and then went into a completely isolated bunker but kept track of what day it was, your beliefs and the actual weather would be very dependent even though there's no causal interaction (after you entered the bunker) between your beliefs and the weather. This is therefore omitted by MBs and CBs want to capture that.
Large Language Models, Small Labor Market Effects?
We examine the labor market effects of AI chatbots using two large-scale adoption surveys (late 2023 and 2024) covering 11 exposed occupations (25,000 workers, 7,000 workplaces), linked to matched employer-employee data in Denmark. AI chatbots are now widespread—most employers encourage their use, many deploy in-house models, and training initiatives are common. These firm-led investments boost adoption, narrow demographic gaps in take-up, enhance workplace utility, and create new job tasks. Yet, despite substantial investments, economic impacts remain minimal. Using difference-in-differences and employer policies as quasi-experimental variation, we estimate precise zeros: AI chatbots have had no significant impact on earnings or recorded hours in any occupation, with confidence intervals ruling out effects larger than 1%. Modest productivity gains (average time savings of 2.8%), combined with weak wage pass-through, help explain these limited labor market effects. Our findings challenge narratives of imminent labor market transformation due to Generative AI.
From marginal revolution.
What does this crowd think? These effects ar...
7
Just to add another data point, as a software engineer, I also find it hard to extract utility from LLMs. (And this has not been for a lack of trying, e.g. at work we are being pushed to use LLM enabled IDEs.) I am constantly surprised to hear when people on the internet say that LLMs are a significant productivity boost for them.
My current model is that LLMs are better if you are working on some mainstream problem domain using a mainstream tech stack (language, library, etc.). This is approximately JavaScript React frontend development in my mind, and as you move away from that the less useful LLMs get. (The things I usually work on are using a non-mainstream tech stack and/or have a non-mainstream problem domain (but in my mind all interesting problems are non-mainstream in that sense), so this would explain my lack of success.)
3
Yes, I have the same impression. Generating Java or Python code using popular libraries: mostly okay. Generating Lean code: does not compile even after several attempts to fix the code by feeding the compiler errors to LLM.
8
I use LLMs daily yet I still am not sure they really help all that much with the core productivity bottlenecks. I worry they lower the barrier to excessive perfectionism and “vibe coding” or “vibe learning.” They seem to short-circuit the theory-practice gap by giving users instant but unreliable and often inextensible results.
My fear is that they’ll raise expectations about productivity gains (because AI-assisted workers can bring immediate results in more quickly to a higher apparent standard of polish), while drastically reducing the knowledge gain by the workers about the problem domain. For example, workers may be able to whip up a codebase more quickly but have less familiarity with it at the end of the process, making it much more difficult to make modifications efficiently. Essentially, I suspect AI will generate massive technical debt in exchange for short-term wins, and that bad incentives will tend to perpetuate this in organizations. People will quickly set up new systems using AI, take credit, and exit those projects before serious problems become apparent.
6
Judging merely from the abstract, the study seems a little bit of a red herring to me:
1. Barely anyone talks about "imminent labor market transformation", instead we say, it may soon turn things upside down. And the study can only show past changes.
2. That "imminent" vs. "soon" may feel like nitpicking but it's crucial: Current tools the way they are currently used, are not yet what completely replaces so many workers 1:1, but if you look at the innovative developments overall, the immense human-labor-replacing capacity seems rather obvious.
Consider as an example a hypothetical 'usual' programmer at a 'usual' company. Would you have strong expectations for her salary to have changed much just because in the past 1-2 years we have been able to have her become faster at coding? Not necessarily, in fact, as we cannot do the coding fully without her yet, it might be for now the value of her marginal product of labor is a bit greater, or maybe a bit lower but AI boom anyway means an IT demand explosion in the near term, so seeing little net effect is surely not any particular surprise, for now. Or the study writer. Language improves, maybe some reasoning in the studies slightly, but habits of how we commission and overall organize, conduct studies haven't changed yet at all; she also has kept her job so far. Or teaching. I'm still teaching just as much as I did 2y ago, of course. The students are still in the same program that they started 2y ago. 80% of incoming students are somewhat ignorant, 20% somewhat concerned about what AI will mean to their studies, but there's no known alternative to them yet than to follow the usual path. We're now starting to reduce contact time at my uni not least due to digital tech, so this may change soon. But, so, until yesterday: +- same old seemingly; no major changes so far on that front either, when one just looks at aggregate macroeconomic data. But this not least reflects the 2 or so years since the large LLMS have broken thro
2
Silicon valley is full of hype about imminent labor market transformation right now. For example, the Shopify CEO sent out a memo which included stuff like "Before asking for more Headcount and resources, teams must demonstrate why they cannot get what they want done using AI." And now boards are pushing for that sort of policy in lots of other companies as well.
Disclaimer: As always, views expressed are my own and do not necessarily reflect those of my employer.
4
What were the biggest boosts that you and your colleagues got from LLMs?
Speaking from the perspective of someone still developing basic mathematical maturity and often lacking prerequisites, it's very useful as a learning aid. For example, it significantly expanded the range of papers or technical results accessible to me. If I'm reading a paper containing unfamiliar math, I no longer have to go down the rabbit hole of tracing prerequisite dependencies, which often expand exponentially (partly because I don't know which results or sections in the prerequisite texts are essential, making it difficult to scope my focus). Now I can simply ask the LLM for a self-contained exposition. Using traditional means of self-studying like [search engines / Wikipedia / StackExchange] is very often no match for this task, mostly in terms of time spent or wasted effort; simply having someone I can directly ask my highly specific (and often dumb) questions or confusions and receive equally specific responses is just really useful.
Claude is smarter than you. Deal with it.
There is an incredible amount of cope about the current abilities of AI.
AI isn't infallible. Of course. And yet...
For 90% of queries a well-prompted AI has better responses than 99% of people.For some queries the number of people that could match the kind of deep, broad knowledge that AI has can be counted on two hands. Finally, obviously, there is no man alive on the face of the earth that comes even close to the breadth and depth of crystallized intelligence that AIs now have.
People have developped a keen apprehension and aversion for " AI slop". The truth of the matter is that LLMs are incredible writers and if you had presented AI slop as human writing to somebody ten six years ago they would say it is good if somewhat corporate writing all the way to inspired, eloquent, witty.
Does AI sometimes make mistakes? Of course. So do humans. To be human is to err.
There is an incredible amount of cope about the current abilities of AI. Frankly, I find it embarassing. Witness the absurd call to flag AI-assisted writing. The widespread disdain for " @grok is this true?" . Witness how llm psychosis has gone from perhaps...
Contemporary AI is smart in some ways and dumb in other ways. It's a useful tool that you should integrate into your workflow if you don't want to miss out on productivity. However. I'm worried that exposure to AI is dangerous in similar ways to how exposure to social media is dangerous, only more. You're interacting with something designed to hijack your attention and addict you. Only this time the "something" has its own intelligence that is working towards this purpose (and possibly other, unknown, purposes).
As to the AI safety space: we've been saying for decades that AI is dangerous and now you're surprised that we think AI is dangerous? I don't think it's taking over the world just yet, but that doesn't mean there are no smaller-scale risks. It's dangerous not because it's dumb (the fact it's still dumb is the saving grace) but precisely because it's smart.
My own approach is, use AI is clear, compartmentalized ways. If you have a particular task which you know can be done faster by using AI in a particular way, by all means, use it. (But, do pay attention to time wasted on tweaking the prompt etc.) Naturally, you should also occasionally keep experimenting with new tasks or new ways of using it. But, if there's no clear benefit, don't use it. If it's just to amuse yourself, don't. And, avoid exposing other people if there's no good reason.
Claude 4.5 is already superhuman in some areas, including:
- Breadth of knowledge.
- Understanding complex context "at a glance."
- Speed, at least for many things.
But there are other essential abilities where leading LLMs are dumber than diligent 7 year old. Gemini is one of the stronger visual models, and I routinely benchmark it failing simple visual tasks that any child could solve.
And then there's software development. I use Claude for software development, and it's quite skilled at many simple tasks. But I also spend a lot of time dealing with ill-conceived shit code that it writes. You can't just give an irresponsible junior programmer a copy of Claude Code and allow them commit straight to main with no review. If you do, you will learn the meaning of the word "slop." In the hands of a skilled professional who takes 100% responsibility for the output, Claude Code is useful. In the hands of an utter newb who can't do anything on their own, it's also great. But it can't do anything serious without massive handholding and close expert supervision.
So my take is that frontier models are terrifyingly impressive if you're paying attention, but they are still critically broken in ways ...
9
Possible synthesis (not including the newest models):
8
My 2c: “vibe-coded” software is still often low quality and buggy, and in this case the accusation of “slop!” is warranted. You can use AI to accelerate your coding >10x in many cases but if you over-delegate it’s not good (so far!).
Re. writing I think even pre-LLMs, LLM-like writing would be considered quite flawed by serious critics/stylists, but not by most people. Agree fear-mongering/hysteria about slopapocalypse is silly though.
2
I generally agree. Do you think it implies ultra short timelines?
2
How do you measure the intelligence? What unique problems is it solving? And how much of it is precipitated by the intelligence of good prompters ? (of which I am certainly not one, as much of a 'self-own' that might be to admit).
If lousy prompts deliver lousy and unintelligent replies - then is the AI really that intelligent?
If skillful prompts which much like Socrates imply and lead the AI to point to certain solution spaces, then is the lion-share of credit for being intelligent rest with the user or the AI? Especially since if the AI is more intelligent than the average person, then wouldn't it lift lousy prompts by understanding the user's intent and reformulating it in a manner better then their feeble intelligence could?
1
I'm reminded from time to time of a tweet that Ilya Sutskever posted a few years ago.
[This shortform has now been expanded into a long-form post]
NATO faces its gravest military disadvantage since 1949, as the balance of power has shifted decisively toward its adversaries. The speed and scale of NATO's relative military decline represents the most dramatic power shift since World War II—and the alliance appears dangerously unaware of its new vulnerability
I think this is both true and massively underrated.
The primary reason is the drone warfare revolution. The secondary reason is the economic rise and military buildup of China. The Pax Americana is coming to its end.
Problem of Old Evidence, the Paradox of Ignorance and Shapley Values
Paradox of Ignorance
Paul Christiano presents the "paradox of ignorance" where a weaker, less informed agent appears to outperform a more powerful, more informed agent in certain situations. This seems to contradict the intuitive desideratum that more information should always lead to better performance.
The example given is of two agents, one powerful and one limited, trying to determine the truth of a universal statement ∀x:ϕ(x) for some Δ0 formula ϕ. The limited agent treats each new value of ϕ(x) as a surprise and evidence about the generalization ∀x:ϕ(x). So it can query the environment about some simple inputs x and get a reasonable view of the universal generalization.
In contrast, the more powerful agent may be able to deduce ϕ(x) directly for simple x. Because it assigns these statements prior probability 1, they don't act as evidence at all about the universal generalization ∀x:ϕ(x). So the powerful agent must consult the environment about more complex examples and pay a higher cost to form reasonable beliefs about the generalization.
Is it really a problem?
However, I argue that the more powerful agent is act...
6
The matter seems terribly complex and interesting to me.
Notions of Accuracy?
Suppose p1 is a prior which has uncertainty about ϕ(x1),ϕ(x2),... and uncertainty about ∀nϕ(xn). This is the more ignorant prior. Consider p2 some prior which has the same beliefs about the universal statement -- p1(∀nϕ(xn))=p2(∀nϕ(xn)) -- but which knows ϕ(x1) and ϕ(x2).
We observe that p1 can increase its credence in the universal statement by observing the first two instances, ϕ(x1) and ϕ(x2), while p2 cannot do this -- p2 needs to wait for further evidence. This is interpreted as a defect.
The moral is apparently that a less ignorant prior can be worse than a more ignorant one; more specifically, it can learn more slowly.
However, I think we need to be careful about the informal notion of "more ignorant" at play here. We can formalize this by imagining a numerical measure of the accuracy of a prior. We might want it to be the case that more accurate priors are always better to start with. Put more precisely: a more accurate prior should also imply a more accurate posterior after updating. Paul's example challenges this notion, but he does not prove that no plausible notion of accuracy will have this property; he only relies on an informal notion of ignorance.
So I think the question is open: when can a notion of accuracy fail to follow the rule "more accurate priors yield more accurate posteriors"? EG, can a proper scoring rule fail to meet this criterion? This question might be pretty easy to investigate.
Conditional probabilities also change?
I think the example rests on an intuitive notion that we can construct p2 by imagining p1 but modifying it to know ϕ(x1) and ϕ(x2). However, the most obvious way to modify it so is by updating on those sentences. This fails to meet the conditions of the example, however; p2 would already have an increased probability for the universal statement.
So, in order to move the probability of ϕ(x1) and ϕ(x2) upwards to 1 without also increasi
4
(continued..)
Explanations?
Alexander analyzes the difference between p1 and p2 in terms of the famous "explaining away" effect. Alexander supposes that p2 has learned some "causes":
Postulating these causes adds something to the scenario. One possible view is that Alexander is correct so far as Alexander's argument goes, but incorrect if there are no such Cj to consider.
However, I do not find myself endorsing Alexander's argument even that far.
If C1 and C2 have a common form, or are correlated in some way -- so there is an explanation which tells us why the first two sentences, ϕ(x1) and ϕ(x2), are true, and which does not apply to n>2 -- then I agree with Alexander's argument.
If C1 and C2 are uncorrelated, then it starts to look like a coincidence. If I find a similarly uncorrelated C3 for ϕ(x3), C4 for ϕ(x4), and a few more, then it will feel positively unexplained. Although each explanation is individually satisfying, nowhere do I have an explanation of why all of them are turning up true.
I think the probability of the universal sentence should go up at this point.
So, what about my "conditional probabilities also change" variant of Alexander's argument? We might intuitively think that ϕ(x1) and ϕ(x2) should be evidence for the universal generalization, but p2 does not believe this -- its conditional probabilities indicate otherwise.
I find this ultimately unconvincing because the point of Paul's example, in my view, is that more accurate priors do not imply more accurate posteriors. I still want to understand what conditions can lead to this (including whether it is true for all notions of "accuracy" satisfying some reasonable assumptions EG proper scoring rules).
Another reason I find it unconvincing is because even if we accepted this answer for the paradox of ignorance, I think it is not at all convincing for the problem of old evidence.
What is the 'problem' in the problem of old evidence?
... to be further expanded later ...
6
This doesn't feel like it resolves that confusion for me, I think it's still a problem with the agents he describes in that paper.
The causes Cj are just the direct computation of Φ for small values of x. If they were arguments that only had bearing on small values of x and implied nothing about larger values (e.g. an adversary selected some x to show you, but filtered for x such that Φ(x)), then it makes sense that this evidence has no bearing on∀x:Φ(x). But when there was no selection or other reason that the argument only applies to small x, then to me it feels like the existence of the evidence (even though already proven/computed) should still increase the credence of the forall.
4
I didn't intend the causes Cj to equate to direct computation of \phi(x) on the x_i. They are rather other pieces of evidence that the powerful agent has that make it believe \phi(x_i). I don't know if that's what you meant.
I agree seeing x_i such that \phi(x_i) should increase credence in \forall x \phi(x) even in the presence of knowledge of C_j. And the Shapely value proposal will do so.
(Bad tex. On my phone)
3
It's funny that this has been recently shown in a paper. I've been thinking a lot about this phenomenon regarding fields with little to no capacity for testable predictions like history.
I got very into history over the last few years, and found there was a significant advantage to being unknowledgeable that was not available to the knowledged, and it was exactly what this paper is talking about.
By not knowing anything, I could entertain multiple bizarre ideas without immediately thinking "but no, that doesn't make sense because of X." And then, each of those ideas becomes in effect its own testable prediction. If there's something to it, as I learn more about the topic I'm going to see significantly more samples of indications it could be true and few convincing to the contrary. But if it probably isn't accurate, I'll see few supporting samples and likely a number of counterfactual examples.
You kind of get to throw everything at the wall and see what sticks over time.
In particular, I found that it was especially powerful at identifying clustering trends in cross-discipline emerging research in things that were testable, such as archeological finds and DNA results, all within just the past decade, which despite being relevant to the field of textual history is still largely ignored in the face of consensus built on conviction.
It reminds me a lot of science historian John Helibron's quote, "The myth you slay today may contain a truth you need tomorrow."
If you haven't had the chance to slay any myths, you also haven't preemptively killed off any truths along with it.
One of the interesting thing about AI minds (such as LLMs) is that in theory, you can turn many topics into testable science while avoiding the 'problem of old evidence', because you can now construct artificial minds and mold them like putty. They know what you want them to know, and so you can see what they would predict in the absence of knowledge, or you can install in them false beliefs to test out counterfactual intellectual histories, or you can expose them to real evidence in different orders to measure biases or path dependency in reasoning.
With humans, you can't do that because they are so uncontrolled: even if someone says they didn't know about crucial piece of evidence X, there is no way for them to prove that, and they may be honestly mistaken and have already read about X and forgotten it (but humans never really forget so X has already changed their "priors", leading to double-counting), or there is leakage. And you can't get people to really believe things at the drop of a hat, so you can't make people imagine, "suppose Napoleon had won Waterloo, how do you predict history would have changed?" because no matter how you try to participate in the spirit of the exerci...
2
Beautifully illustrated and amusingly put, sir!
A variant of what you are saying is that AI may once and for all allow us to calculate the true counterfactual Shapley value of scientific contributions.
( re: ancestor simulations
I think you are onto something here. Compare the Q hypothesis:
https://twitter.com/dalcy_me/status/1780571900957339771
see also speculations about Zhuangzi hypothesis here )
3
Yup. Who knows but we are all part of a giant leave-one-out cross-validation computing counterfactual credit assignment on human history? Schmidhuber-em will be crushed by the results.
1
While I agree that the potential for AI (we probably need a better term than LLMs or transformers as multimodal models with evolving architectures grow beyond those terms) in exploring less testable topics as more testable is quite high, I'm not sure the air gapping on information can be as clean as you might hope.
Does the AI generating the stories of Napoleon's victory know about the historical reality of Waterloo? Is it using something like SynthID where the other AI might inadvertently pick up on a pattern across the stories of victories distinct from the stories preceding it?
You end up with a turtles all the way down scenario in trying to control for information leakage with the hopes of achieving a threshold that no longer has impact on the result, but given we're probably already seriously underestimating the degree to which correlations are mapped even in today's models I don't have high hopes for tomorrow's.
I think the way in which there's most impact on fields like history is the property by which truth clusters across associated samples whereas fictions have counterfactual clusters. An AI mind that is not inhibited by specialization blindness or the rule of seven plus or minus two and better trained at correcting for analytical biases may be able to see patterns in the data, particularly cross-domain, that have eluded human academics to date (this has been my personal research interest in the area, and it does seem like there's significant room for improvement).
And yes, we certainly could be. If you're a fan of cosmology at all, I've been following Neil Turok's CPT symmetric universe theory closely, which started with the Baryonic asymmetry problem and has tackled a number of the open cosmology questions since. That, paired with a QM interpretation like Everett's ends up starting to look like the symmetric universe is our reference and the MWI branches are variations of its modeling around quantization uncertainties.
(I've found myself thinking of
1
This post sounds intriguing, but is largely incomprehensible to me due to not sufficiently explaining the background theories.
What did Yudkoswky get right?
- The central problem of AI alignment. I am not aware of anything in subsequent work that is not already implicit in Yudkowsky's writing.
- Short timelines avant le lettre. Yudkowsky was predicting AGI in his lifetime from the very start when most academics, observers, AI scientists, etc considered AGI a fairytale.
- Inherent and irreducible uncertainty of forecasting, foolishness of precise predictions.
- The importance of (Pearlian) causality, Solomonoff Induction as theory of formal epistemology, Bayesian statistics, (Shannon) information theory, decision theory [especially UDT-shaped things].
- (?nanotech, ?cryonics)
- if you had a timemachine to go back to 2010 you should buy bitcoin and write Harry Potter fanfiction
9[anonymous]
From Akash's summary of the discussion between Conor Leahy and Michael Trazzi on "The Inside View" from ~ 1.5 years ago:
In Leahy's own words:
Much of the discussion at the time (example) focused on the particular application of this idea in the context of the "Death with Dignity" post, but I think this effect was visible much earlier on, most prominently in the Sequences themselves. As I see it, this did not affect the content that was being communicated so much as it did the vibe, the more ineffable, emotional, and hard-to-describe-using-S2 stylistic packaging that enveloped the specific ideas being conveyed. The latter [1], divorced from Eliezer's presentation of them, could be (and often are) thought of as dry or entirely technical, but his writing gave them a certain life that made them rather unforgettable and allowed them to hit much harder (see "How An Algorithm Feels From the Inside" and "Beyond the Reach of God" as the standard examples of this).
1. ^
Stuff like probability theory, physics (Quantum Mechanics in particular), philosophy of language, etc.
5
I think I'd agree with everything you say (or at least know what you're looking at as you say it) except for the importance of decision theory. What work are you watching there?
5
As one relevant consideration, I think the topic of "will AI kill all humans" is a question whose answer relies in substantial parts on TDT-ish considerations, and is something that a bunch of value systems I think reasonably care a lot about. Also I think what superintelligent systems will do will depend a lot on decision-theoretic considerations that seem very hard to answer from a CDT vs. EDT-ish frame.
5
I think I speak for many when I ask you to please elaborate on this!
7
Oh, I thought this was relatively straightforward and has been discussed a bunch. There are two lines of argument I know for why superintelligent AI, even if unaligned, might not literally kill everyone, but keep some humans alive:
1. The AI might care a tiny bit about our values, even if it mostly doesn't share them
2. The AI might want to coordinate with other AI systems that reached superintelligence to jointly optimize the universe. So in a world where there is only a 1% chance that we align AI systems to our values, then even in unaligned worlds we might end up with AI systems that adopt our values as a 1% mixture in its utility function (and also consequently in those 1% of worlds, we might still want to trade away 99% of the universe to the values that the counterfactual AI systems would have had)
Some places where the second line of argument has been discussed:
* This comment by Ryan Greenblatt:[1] https://www.lesswrong.com/posts/tKk37BFkMzchtZThx/miri-2024-communications-strategy?commentId=xBYimQtgASti5tgWv
* This comment by Paul Christiano:[2] https://www.lesswrong.com/posts/2NncxDQ3KBDCxiJiP/cosmopolitan-values-don-t-come-free?commentId=ofPTrG6wsq7CxuTXk
1. ^
2. ^
8
See also: https://www.lesswrong.com/posts/rP66bz34crvDudzcJ/decision-theory-does-not-imply-that-we-get-to-have-nice
Pockets of Deep Expertise
Why am I so bullish on academic outreach? Why do I keep hammering on 'getting the adults in the room'?
It's not that I think academics are all Super Smart.
I think rationalists/alignment people correctly ascertain that most professors don't have much useful to say about alignment & deep learning and often say silly things. They correctly see that much of AI congress is fueled by labs and scale not ML academia. I am bullish on non-ML academia, especially mathematics, physics and to a lesser extent theoretical CS, neuroscience, some parts of ML/ AI academia. This is because while I think 95 % of academia is bad and/or useless there are Pockets of Deep Expertise. Most questions in alignment are close to existing work in academia in some sense - but we have to make the connection!
A good example is 'sparse coding' and 'compressed sensing'. Lots of mech.interp has been rediscovering some of the basic ideas of sparse coding. But there is vast expertise in academia about these topics. We should leverage these!
Other examples are singular learning theory, computational mechanics, etc
Is Superhuman Persuasion a thing?
Sometimes I see discussions of AI superintelligence developping superhuman persuasion and extraordinary political talent.
Here's some reasons to be skeptical of the existence of 'superhuman persuasion'.
- We don't have definite examples of extraordinary political talent.
Famous politicians rose to power only once or twice. We don't have good examples of an individual succeeding repeatedly in different political environments.
Examples of very charismatic politicans can be better explained by ' the right person at the right time or place'.
- Neither do we have strong examples of extraordinary persuasion.
>> For instance hypnosis is mostly explained by people wanting to be persuaded by the hypnotist. If you don't want to be persuaded it's very hard to change your mind. There is some skill in persuasion required for sales, and sales people are explicitly trained to do so but beyond a fairly low bar the biggest predictors for salesperson success is finding the correct audience and making a lot of attempts.
Another reason has to do with the ' intrinsic skill ceiling of a domain' .
For an agent A to have a very high skil...
Disagree on individual persuasion. Agree on mass persuasion.
Mass I'd expect optimizing one-size-fits-all messages for achieving mass persuasion has the properties you claim: there are a few summary, macro variables that are almost-sufficient statistics for the whole microstate--which comprise the full details on individuals.
Individual Disagree on this, there are a bunch of issues I see at the individual level. All of the below suggest to me that significantly superhuman persuasion is tractable (say within five years).
- Defining persuasion: What's the difference between persuasion and trade for an individual? Perhaps persuasion offers nothing in return? Though presumably giving strategic info to a boundedly rational agent is included? Scare quotes below to emphasize notions that might not map onto the right definition.
- Data scaling: There's an abundant amount of data available on almost all of us online. How much more persuasive can those who know you better be? I'd guess the fundamental limit (without knowing brainstates) is above your ability to 'persuade' yourself.
- Preference incoherence: An intuition pump on the limits of 'persuasion' is how far you are from having fully coherent preferences. Insofar as you don't an agent which can see those incoherencies should be able to pump you--a kind of persuasion.
Wow! I like the idea of persuasion as acting on the lack of a fully coherent preference! Something to ponder 🤔
1
Persuasion is also changing someone's world model or paradigm.
4
Some humans are much more charismatic than other humans based on a wide variety of sources (e.g. Sam Altman). I think these examples are pretty definitive, though I'm not sure if you'd count them as "extraordinary".
4
From the Caro biography, it's pretty clear Lyndon Johnson had extraordinary political talent.
4
Success in almost every domain is strongly correlated with g, including into the tails. This IMO relatively clearly shows that most domains are high skill-ceiling domains (and also that skills in most domains are correlated and share a lot of structure).
2
I somewhat agree but
1. The correlation is not THAT strong
2. The correlation differs by field
And finally there is a difference between skill ceilings for domains with high versus low predictive efficiency. In the latter much more intelligence will still yield returns but rapidly diminishing
(See my other comment for more details on predictive effiency)
3
I agree super-persuasion is poorly defined, comparing it to hypnosis is probably false.
I was reading this paper on medical diagnoses with AI and the fact that patients rate it significantly better than the average human doctor. Combine that with all of the reports about things like Character.ai, I think this shows that LLMs are already superhuman at building trust, which is a key component of persuasion.
Part of this is that the reliable signals of trust between humans do not transfer between humans and AI. A human who writes 600 words back to your query may be perceived to be worth your trust because we see that as a lot of effort, but LLMs can output as much as anyone wants. Does this effect go away if the responder is known to be AI, or is it that the response is being compared to the perceiver's baseline (which is currently only humans)?
Whether that actually translates to influencing goals of people is hard to judge.
3
The term is a bit conflationary. Persuasion for the masses is clearly a thing, its power is coordination of many people and turning their efforts to (in particular) enforce and propagate the persuasion (this works even for norms that have no specific persuader that originates them, and contingent norms that are not convergently generated by human nature). Individual persuasion with a stronger effect that can defeat specific people is probably either unreliable like cults or conmen (where many people are much less susceptible than some, and objective deception is necessary), or takes the form of avoidable dangers like psychoactive drugs: if you are not allowed to avoid exposure, then you have a separate problem that's arguably more severe.
With AI, it's plausible that coordinated persuasion of many people can be a thing, as well as it being difficult in practice for most people to avoid exposure. So if AI can achieve individual persuasion that's a bit more reliable and has a bit stronger effect than that of the most effective human practitioners who are the ideal fit for persuading the specific target, it can then apply it to many people individually, in a way that's hard to avoid in practice, which might simultaneously get the multiplier of coordinated persuasion by affecting a significant fraction of all humans in the communities/subcultures it targets.
2
My experience with manipulators is that they understand what you want to hear, and they shamelessly tell you exactly that (even if it's completely unrelated to truth). They create some false sense of urgency, etc. When they succeed to make you arrive at the decision they wanted you to, they will keep reminding you that it was your decision, if you try to change your mind later. Etc.
The part about telling you exactly what you want to hear gets more tricky when communicating with large groups, because you need to say the same words to everyone. One solution is to find out which words appeal to most people (some politicians secretly conduct polls, and then say what most people want to hear). Another solution is to speak in a sufficiently vague way that will make everyone think that you agree with them.
I could imagine an AI being superhuman at persuasion simply by having the capacity to analyze everyone's opinions (by reading all their previous communication) and giving them tailored arguments, as opposed to delivering the same speech to everyone.
Imagine a politician spending 15 minutes talking to you in private, and basically agreeing with you on everything. Not agreeing in the sense "you said it, the politician said yes", but in the sense of "the politician spontaneously keeps saying things that you believe are true and important". You probably would be tempted to vote for him.
Then the politician would also publish some vague public message for everyone, but after having the private discussion you would be more likely to believe that the intended meaning of the message is what you want.
Neural Network have a bias towards Highly Decomposable Functions.
tl;dr Neural networks favor functions that can be "decomposed" into a composition of simple pieces in many ways - "highly decomposable functions".
Degeneracy = bias under uniform prior
[see here for why I think bias under the uniform prior is important]
Consider a space of parameters used to implement functions, where each element specifies a function via some map . Here, the set is our parameter space, and we can think of each as representing a specific configuration of the neural network that yields a particular function .
The mapping assigns each point to a function . Due to redundancies and symmetries in parameter space, multiple configurations might yield the same function, forming what we call a fiber, or the "set of degenerates." of
This fiber is the set of ways in which the same functional behavior can be achieved by different parameterizations. If we uniformly sample from codes, the degeneracy of a function counts how likely it is to be sampl...
Feature request: author-driven collaborative editing [CITATION needed] for the Good and Glorious Epistemic Commons.
Often I find myself writing claims which would ideally have citations but I don't know an exact reference, don't remember where I read it, or am simply too lazy to do the literature search.
This is bad for scholarship is a rationalist virtue. Proper citation is key to preserving and growing the epistemic commons.
It would be awesome if my lazyness were rewarded by giving me the option to add a [CITATION needed] that others could then suggest (push) a citation, link or short remark which the author (me) could then accept. The contribution of the citator is acknowledged of course. [even better would be if there was some central database that would track citations & links like with crosslinking etc like wikipedia]
a sort hybrid vigor of Community Notes and Wikipedia if you will. but It's collaborative, not adversarial*
author: blablablabla
sky is blue [citation Needed]
blabblabla
intrepid bibliographer: (push) [1] "I went outside and the sky was blue", Letters to the Empirical Review
*community notes on twitter has been a universally lauded concept when it first launched. We are already seeing it being abused unfortunately, often used for unreplyable cheap dunks. I still think it's a good addition to twitter but it does show how difficult it is to create shared agreed-upon epistemics in an adverserial setting.
Corrupting influences
The EA AI safety strategy has had a large focus on placing EA-aligned people in A(G)I labs. The thinking was that having enough aligned insiders would make a difference on crucial deployment decisions & longer-term alignment strategy. We could say that the strategy is an attempt to corrupt the goal of pure capability advance & making money towards the goal of alignment. This fits into a larger theme that EA needs to get close to power to have real influence.
[See also the large donations EA has made to OpenAI & Anthropic. ]
Whether this strategy paid off... too early to tell.
What has become apparent is that the large AI labs & being close to power have had a strong corrupting influence on EA epistemics and culture.
- Many people in EA now think nothing of being paid Bay Area programmer salaries for research or nonprofit jobs.
- There has been a huge influx of MBA blabber being thrown around. Bizarrely EA funds are often giving huge grants to for profit organizations for which it is very unclear whether they're really EA-aligned in the long-term or just paying lip service. Highly questionable that EA should be trying to do venture
7
As a supervisor of numerous MSc and PhD students in mathematics, when someone finishes a math degree and considers a job, the tradeoffs are usually between meaning, income, freedom, evil, etc., with some of the obvious choices being high/low along (relatively?) obvious axes. It's extremely striking to see young talented people with math or physics (or CS) backgrounds going into technical AI alignment roles in big labs, apparently maximising along many (or all) of these axes!
Especially in light of recent events I suspect that this phenomenon, which appears too good to be true, actually is.
5
Yes!
6
I'm not too concerned about this. ML skills are not sufficient to do good alignment work, but they seem to be very important for like 80% of alignment work and make a big difference in the impact of research (although I'd guess still smaller than whether the application to alignment is good)
* Primary criticisms of Redwood involve their lack of experience in ML
* The explosion of research in the last ~year is partially due to an increase in the number of people in the community who work with ML. Maybe you would argue that lots of current research is useless, but it seems a lot better than only having MIRI around
* The field of machine learning at large is in many cases solving easier versions of problems we have in alignment, and therefore it makes a ton of sense to have ML research experience in those areas. E.g. safe RL is how to get safe policies when you can optimize over policies and know which states/actions are safe; alignment can be stated as a harder version of this where we also need to deal with value specification, self-modification, instrumental convergence etc.
4
I mostly agree with this.
I should have said 'prestige within capabilities research' rather than ML skills which seems straightforwardly useful. The former is seems highly corruptive.
0
I'd arguably say this is good, primarily because I think EA was already in danger of it's AI safety wing becoming unmoored from reality by ignoring key constraints, similar to how early Lesswrong before the deep learning era around 2012-2018 turned out to be mostly useless due to how much everything was stated in a mathematical way, and not realizing how many constraints and conjectured constraints applied to stuff like formal provability, for example..
Entropy and AI Forecasting
Until relatively recently (2018-2019?) I did not seriously entertain the possibility that AGI in our lifetime was possible. This was a mistake, an epistemic error. A rational observer calmly and objectively considering the evidence for AI progress over the prior decades - especially in the light of rapid progress in deep learning - should have come to the reasonable position that AGI within 50 years was a serious possibility (>10%).
AGI plausibly arriving in our lifetime was a reasonable position. Yet this possibility was almost universally ridiculed or ignored or by academics and domain experts. One can find quite funny interview with AI experts on Lesswrong from 15 years ago. The only AI expert agreeing with the Yudkowskian view of AI in our lifetime was Jurgen Schmidthuber. The other dozen AI experts denied it as unknowable or even denied the hypothetical possibility of AGI.
Yudkowsky earns a ton of Bayes points for anticipating the likely arrival of AGI in our lifetime long before the deep learning took off.
**************************
We are currently experiencing a rapid AI takeoff, plausibly culminating in superintelligence by ...
I know of only two people who anticipated something like what we are seeing far ahead of time; Hans Moravec and Jan Leike
I didn't know about Jan's AI timelines. Shane Legg also had some decently early predictions of AI around 2030(~2007 was the earliest I knew about)
shane legg had 2028 median back in 2008, see e.g. https://e-discoveryteam.com/2023/11/17/shane-leggs-vision-agi-is-likely-by-2028-as-soon-as-we-overcome-ais-senior-moments/
2
That's probably the one I was thinking of.
6
Oh no uh-oh I think I might have confused Shane Legg with Jan Leike
2
Fwiw, in 2016 I would have put something like 20% probability on what became known as 'the scaling hypothesis'. I still had past-2035 median timelines, though.
2
What did you mean exactly in 2016 by the scaling hypothesis ?
Having past 2035 timelines and believing in the pure scaling maximalist hypothesis (which fwiw i don't believe in for reasons i have explained elsewhere) are in direct conflict so id be curious if you could more exactly detail your beliefs back then.
4
Something like 'we could have AGI just by scaling up deep learning / deep RL, without any need for major algorithmic breakthroughs'.
I'm not sure this is strictly true, though I agree with the 'vibe'. I think there were probably a couple of things in play:
* I still only had something like 20% on scaling, and I expected much more compute would likely be needed, especially in that scenario, but also more broadly (e.g. maybe something like the median in 'bioanchors' - 35 OOMs of pretraining-equivalent compute, if I don't misremember; though I definitely hadn't thought very explicitly about how many OOMs of compute at that time) - so I thought it would probably take decades to get to the required amount of compute.
* I very likely hadn't thought hard and long enough to necessarily integrate/make coherent my various beliefs.
* Probably at least partly because there seemed to be a lot of social pressure from academic peers against even something like '20% on scaling', and even against taking AGI and AGI safety seriously at all. This likely made it harder to 'viscerally feel' what some of my beliefs might imply, and especially that it might happen very soon (which also had consequences in delaying when I'd go full-time into working on AI safety; along with thinking I'd have more time to prepare for it, before going all in).
-1
Yeah, I do think that Moravec and Leike got the AI situation most correct, and yeah people were wrong to dismiss Yudkowsky for having short timelines.
This was the thing they got most correct, which is interesting because unfortunately, Yudkowsky got almost everything else incorrect about how superhuman AIs would work, and also got the alignment situation very wrong as well, which is very important to take note of.
LW in general got short timelines and the idea that AI will probably be the biggest deal in history correct, but went wrong in assuming they knew well about how AI would eventually work (remember the times when Eliezer Yudkowsky dismissed neural networks working for capabilities instead of legible logic?) and also got the alignment situation very wrong, due to way overcomplexifying human values and relying on the evopsych frame way too much for human values, combined with not noticing that the differences between humans and evolution that mattered for capabilities also mattered for alignment.
I believe a lot of the issue comes down to incorrectly conflating the logical possibility of misalignment with the probability of misalignement being high enough that we should take serious action, and the interlocutors they talked with often denied the possibility that misalignment could happen at all, but LWers then didn't realize that reality doesn't grade on a curve, and though their arguments were better than their interlocutors, that didn't mean they were right.
Yudkowsky didnt dismiss neural networks iirc. He just said that there were a lot of different approaches to AI and from the Outside View it didnt seem clear which was promising - and plausibly on an Inside View it wasnt very clear that aritificial neural networks were going to work and work so well.
Re:alignment I dont follow. We dont know who will be proved ultimately right on alignment so im not sure how you can make such strong statements about whether Yudkowsky was right or wrong on this aspect.
We havent really gained that much bits on this question and plausibly will not gain many until later (by which time it might be too late if Yudkowsky is right).
I do agree that Yudkowsky's statements occasionally feel too confidently and dogmatically pessimistic on the question of Doom. But I would argue that the problem is that we simply dont know well because of irreducible uncertainty - not that Doom is unlikely.
6
Mostly, I'm annoyed by how much his argumentation around alignment matches the pattern of dismissing various approaches to alignment using similar reasoning to how he dismissed neural networks:
Even if it was correct to dismiss neural networks years ago, it isn't now, so it's not a good sign that the arguments rely on this issue:
https://www.lesswrong.com/posts/wAczufCpMdaamF9fy/my-objections-to-we-re-all-gonna-die-with-eliezer-yudkowsky#HpPcxG9bPDFTB4i6a
I am going to argue that we do have quite a lot of bits on alignment, and the basic argument can be summarized like this:
Human values are much less complicated than people thought, and also more influenced by data than people thought 15-20 years ago, and thus much, much easier to specify than people thought 15-20 years ago.
That's the takeaway I have from current LLMs handling human values, and I basically agree with Linch's summary of Matthew Barnett's post on the historical value misspecification argument of what that means in practice for alignment:
https://www.lesswrong.com/posts/i5kijcjFJD6bn7dwq/evaluating-the-historical-value-misspecification-argument#N9ManBfJ7ahhnqmu7
It's not about LLM safety properties, but about what has been revealed about our values.
Another way to say it is that we don't need to reverse-engineer social instincts for alignment, contra @Steven Byrnes, because we can massively simplify what the social instinct parts of our brain that contribute to alignment are doing in code, because while the mechanisms for how humans get their morality and not be psychopaths are complicated, it doesn't matter, because we can replicate it's function with much simpler code and data, and go to a more blank-slate design for AIs:
https://www.lesswrong.com/posts/PTkd8nazvH9HQpwP8/building-brain-inspired-agi-is-infinitely-easier-than#If_some_circuit_in_the_brain_is_doing_something_useful__then_it_s_humanly_feasible_to_understand_what_that_thing_is_and_why_it_s_useful__and_to_write_our_own_CPU_code_t
6
It's a plausible argument imho. Time will tell.
To my mind an important dimension, perhaps the most important dimensions is how values be evolve under reflection.
It's quite plausible to me that starting with an AI that has pretty aligned values it will self-reflect into evil. This is certainly not unheard of in the real world (let alone fiction!). Of course it's a question about the basin of attraction around helpfulness and harmlessness. I guess I have only weak priors on what this might look like under reflection, although plausibly friendliness is magic.
4
I disagree, but could be a difference in definition of what "perfectly aligned values" means. Eg if the AI is dumb (for an AGI) and in a rush, sure. If its a superintelligence already, even in a rush, seems unlikely. [edit:] If we have found an SAE feature which seems to light up for good stuff, and down for bad stuff 100% of the time, then we clamp it, then yeah, that could go away on reflection.
4
Another way to say it is how values evolve in OOD situations.
My general prior, albeit reasonably weak is that the best single way to predict how values evolve is looking at their data sources, as well as what data they received up to now, and the second best way to predict it is looking at what their algorithms are, especially for social situations, and that most of the other factors don't matter nearly as much.
8
I think this statement is incredibly overconfident, because literally nobody knows how superhuman AI would work.
And, I think, this is general shape of problem: incredible number of people got incredibly overindexed on how LLMs worked in 2022-2023 and drew conclusions which seem to be plausible, but not as probable as these people think.
4
Okay, I talked more on what conclusions we can draw from LLMs that actually generalize to superhuman AI here, so go check that out:
https://www.lesswrong.com/posts/tDkYdyJSqe3DddtK4/alexander-gietelink-oldenziel-s-shortform#mPaBbsfpwgdvoK2Z2
The really short summary is human values are less complicated and more dependent on data than people thought, and we can specify our values rather easily without it going drastically wrong:
This is not a property of LLMs, but of us.
2
is that supposed to be a link?
4
I rewrote the comment to put the link immediately below the first sentence.
4
The link is at the very bottom of the comment.
Crypticity, Reverse Epsilon Machines and the Arrow of Time?
[see https://arxiv.org/abs/0902.1209 ]
Our subjective experience of the arrow of time is occasionally suggested to be an essentially entropic phenomenon.
This sounds cool and deep but crashes headlong into the issue that the entropy rate and the excess entropy of any stochastic process is time-symmetric. I find it amusing that despite hearing this idea often from physicists and the like apparently this rather elementary fact has not prevented their storycrafting.
Luckily, computational mechanics provides us with a measure that is not time symmetric: the stochastic complexity of the epsilon machine
For any stochastic process we may also consider the epsilon machine of the reverse process, in other words the machine that predicts the past based on the future. This can be a completely different machine whose reverse stochastic complexity is not equal to .
Some processes are easier to predict forward than backward. For example, there is considerable evidence that language is such a process. If the stochastic complexity and the reverse stochastic complexity differ we speak of a causally a...
This sounds cool and deep but crashes headlong into the issue that the entropy rate and the excess entropy of any stochastic process is time-symmetric.
It's time symmetric around a starting point of low entropy. The further is from , the more entropy you'll have, in either direction. The absolute value is what matters.
In this case, is usually taken to be the big bang. So the further in time you are from the big bang, the less the universe is like a dense uniform soup with little structure that needs description, and the higher your entropy will be. That's how you get the subjective perception of temporal causality.
Presumably, this would hold to the other side of as well, if there is one. But we can't extrapolate past , because close to everything gets really really energy dense, so we'd need to know how to do quantum gravity to calculate what the state on the other side might look like. So we can't check that. And the notion of time as we're discussing it here might break down at those energies anyway.
3
See also the Past Hypothesis. If we instead take a non-speculative starting point as t0, namely now, we could no longer trust our memories, including any evidence we believe to have about the entropy of the past being low, or about physical laws stating that entropy increases with distance from t0. David Albert therefore says doubting the Past Hypothesis would be "epistemically unstable".
I have an embarrasing confession to make. I don't understand why PvsNP is so hard.
[I'm in good company since apparently Richard Feynmann couldn't be convinced it was a serious open problem.]
I think I understand PvsNP and its many variants like existence of one-way function is about computational hardness of certain tasks. It is surprising that we have such strong intuitions that some tasks are computationally hard but we fail to be able to prove it!
Of course I don't think I can prove it and I am not foolish enough to spend significant amount of time on trying to prove it. I still would like to understand the deep reasons why it's so hard to prove computational hardness results. That means I'd like to understand why certain general proof strategies are impossible or very hard.
There is an old argument by Shannon that proves that almost every* Boolean function has exponential circuit depth. This is a simple counting argument. Basically, there are exponentially many more Boolean functions than there are circuits. It's hard to give explicit examples of computationally hard functions** but we can easily show they are plentiful.
This would seem to settle...
I'm just computational complexity theory enthusiast, but my opinion is that P vs NP centered explanation of computational complexity is confusing. Explanation of NP should happen in the very end of the course.
There is nothing difficult in proving that computationally hard functions exist: time hierarchy theorem implies that, say, P is not equal EXPTIME. Therefore, EXPTIME is "computationally hard". What is difficult is to prove that very specific class of problems which have zero-error polynomial-time verification algorithms is "computationally hard".
9
I guess a central issue with separating NP from P with a counting argument is that (roughly speaking) there are equally many problems in NP and P. Each problem in NP has a polynomial-time verifier, so we can index the problems in NP by polytime algorithms, just like the problems in P.
in a bit more detail: We could try to use a counting argument to show that there is some problem with a (say) <n2 time verifier which does not have any (say) <n1000 time solver. To do this, we'd like to say that there are more n2 verifier problems than n1000 algorithms. While I don't really know how we ought to count these (naively, there are ℵ0 of each), even if we had some decent notion of counting, there would almost certainly just be more <n1000 algorithms than <n2 verifiers (since the n2 verifiers are themselves <n1000 algorithms).
3
Thank you Kaarel - this the kind of answer I was after.
5
Looking at this again, I'm not sure I understand the two confusions. P vs. NP isn't about functions that are hard to compute (they're all polynomially computable), rather functions that are hard to invert, or pairs of easily computable functions that hard to prove are equal/not equal to each other. The main difference between circuits and Turing machines is that circuits are finite and bounded to compute whereas the halting time of general Turing machines is famously impossible to determine. There's nothing special about Boolean circuits: they're an essentially complete model of what can be computed in polynomial time (modulo technicalities)
3
In particular, it's not hard to produce a computable function that isn't given by a polynomial-sized circuit (parity doesn't work as it's polynomial, but you can write one down using diagonalization -- it would be very long to compute, but computable in some suitably exponentially bounded time). But P vs. NP is not about this: it's a statement that exists fully in the world of polynomially computable functions.
4
We know there are difficult computational problems. P vs NP is more narrow than that; it's sometimes phrased as "are there problems that are not difficult to verify but difficult to solve?", where "difficult" means that it cannot be done in asymptotically polynomial time.
2
Yes, I am familiar with the definition of PvsNP. That's not what I am asking.
2
The point is that you can't use the result that there exists a hard function, since all you know is that the function is hard, not whether it's in NP, which is a basic problem for your scheme.
Your counting argument for Turing Machines also likely have this problem, and even if not, I see no reason why I couldn't relativize the results, which is a no-go for P vs NP proof attempts.
2
Basically, there are 3 main barriers to proving P not equaling NP.
One, you have to actually show that there exists a hard function that isn't in P, and it's not enough to prove that there are exponentially many hard functions, because it might be that a circuit computing an NP-complete problem has a linear time bound.
And natural proofs argue that unless cryptographically hard functions don't exist, the common way to prove circuit lower bounds also can't prove P vs NP (Technical details are below:)
https://en.wikipedia.org/wiki/Natural_proof
Also, both of the strategies cannot relativize or algebrize, where relativization means that if we give a fixed oracle tape O consisting of a single problem you can solve instantly to all parties doesn't change the conclusion for all oracle tapes O.
Many results like this, including possibly your attempts to prove via counting arguments almost certainly relativize, and even if they don't, they algebrize, and the technical details are below for algebrization are here, since I already explained relativization above.
https://www.scottaaronson.com/papers/alg.pdf
But that's why proving P vs NP is so hard technically.
2
You might be interested in Scott Aaronson's thoughts on this in section 4: Why Is Proving P != NP Difficult?, which is only 2 pages.
2
looks like you referenced the same paper before me while I was making my comment :)
1
Ha, that's awesome. Thanks for including the screenshot in yours :) Scott's "invisible fence" argument was the main one I thought of actually.
2
See https://en.wikipedia.org/wiki/Natural_proof
1
Yeah I think this is a good place to probe assumptions, and it's probably useful to form world models where you probability of P = NP is nonzero (I also like doing this for inconsistency of logic). I don't have an inside view, but like Scott Aaronson on this: https://www.scottaaronson.com/papers/pnp.pdf:
2
My real view on P vs NP is that at this point, I think P almost certainly not equal to NP, and that any solving of NP-complete problems efficiently to the standard of complexity theorists requires drastically changing the model of computation, which corresponds to drastic changes in our physics assumptions like time travel actually working according to Deutsch's view (and there being no spurious fixed-points).
Voters are irrational.
Voters want better health care, a powerful military, a strong social security net, but also lower taxes. There's 120% demands but only 100% to go around.
Voters also often believe their pet issue voting bloc is more powerful than it actually is. It’s an interesting question to ask why people like to believe their voting bloc is larger than it really is. One reason might be that the people that are ill-calibrated on their own causal impact are more likely to show up as a voter.
It follows that an effective politician lies. There is no blame to go to politicans really. The average politician is a Christ-like figure that takes on the karmic burden of dishonesty for the dharma, because voters are children.
A conventional politician lies sure - but he or she would not want to be known as a liar. Being known as a liar seems bad. But there is another type of politician: the 'Brazen Liar Politican' who is known to be a liar, who lies blatantly and lies often, who puts no effort in hiding their lies.
How could this possibly be a good political strategy? Well the voters know that he's a liar but paradoxically that may make them more l...
2
I don't think its just voters, this strategy also worked well for Lyndon Johnson in closed doors with party elites. He would tell everyone he was on their side, and they would largely believe him, and know also that he was telling everyone else he was on their side too (he'd make it very obvious to eg those listening in on his calls that he was lying or manipulating the other party).
For Lyndon, this often set him up as a good compromise candidate. It was very difficult to find anyone who was remotely acceptable to both northern and southern democrats at the same time. The south trusted him fully (ultimately incorrectly, but for good reason), and the north would tolerate him.
Maybe there's a rational agent model here, where if Alice prefers outcome A and Bob prefers outcome B, and they must choose a lottery in {pA+(1−p)B|p∈[0,1]} so that UA(pA+(1−p)B)=p and UB(pA+(1−p)B)=1−p, and if they fail to choose then they get uA,uB<0 utility respectively. If each lottery is a candidate, with lottery 1A+0B the candidate honest in their support for A and 0A+1B the candidate honest in their support for B, and pA+(1−p)B for p∈(0,1) a dishonest candidate with a p probability of actually being pro-A, the Nash bargaining solution here will always support a dishonest candidate.
Note that you get a brazen liar (rather than just an undecided but known to be honest candidate) here because you can be more confident the brazen liar isn't making secret deals. Or rather, you can be confident they are making secret deals, because they've made secret deals with you and you know they're making secret deals with everyone else too, so you can be confident few if any people have some usefully secret information about their position.
Can somebody ELI5 how much I should update on the recent SAE = dead salmon news?
On priors I would expect the SAE bear news to be overblown. 50% of mechinterp is SAEs - a priori, it seems unlikely to me that so many talented people went astray. But I'm an outsider and curious about alternate views.
7
I have not updated on these results much so far. Though I haven't looked at them in detail yet. My guess is that if you already had a view of SAE-style interpretability somewhat similar to mine [1,2], these papers shouldn't be much of an additional update for you.
7
(Context: https://x.com/davidad/status/1885812088880148905 , i.e. some papers just got published that strongly question whether SAEs learn anything meaningful, just like the dead salmon study questioned the value of much of fMRI research.)
2
(About half a year ago I had a thought along the lines of "gosh, it would be good for interp research if people doing interp were at least somewhat familiar with philosophy of mind ... not that it would necessarily teach them anything object-level useful for the kind of research they're doing but at least it would show them which chains of thought are blind alleys because they seem to be repeating some of the same mistakes as 20th century philosophers" (I don't remember what mistakes exactly but I think something to do with representations). Well, perhaps not just philosophy of mind.)
6
I agree with Leo Gao here:
https://x.com/nabla_theta/status/1885846403785912769
5
Well, maybe we did go astray, but it's not for any reasons mentioned in this paper!
SAEs were trained on random weights since Anthropic's first SAE paper in 2023:
In my first SAE feature post, I show a clearly positional feature:
which is not a feature you'll find in a SAE trained on a randomly intitialized transformer.
The reason the auto-interp metric is similar is likely due to the fact that SAEs on random weights still have single-token features (ie activate on one token). Single-token features are the easiest feature to auto-interp since the hypothesis is "activates on this token" which is easy to predict for an LLM.
When you look at their appendix at their sampled features for the random features, all three are single token features.
However, I do want to clarify that their paper is still novel (they did random weights and controls over many layers in Pythia 410M) and did many other experiments in their paper: it's a valid contribution to the field, imo.
Also to clarify that SAEs aren't perfect, and there's a recent paper on it (which I don't think captures all the problems), and I'm really glad Apollo's diversified away from SAE's by pursuing their weight-based interp approach (which I think is currently underrated karma-wise by 3x).
3
Specifically re: “SAEs can interpret random transformers”
Based on reading replies from Adam Karvonen, Sam Marks, and other interp people on Twitter: the results are valid, but can be partially explained by the auto-interp pipeline used. See his reply here: https://x.com/a_karvonen/status/1886209658026676560?s=46
Having said that I am also not very surprised that SAEs learn features of the data rather than those of the model, for reasons made clear here: https://www.lesswrong.com/posts/gYfpPbww3wQRaxAFD/activation-space-interpretability-may-be-doomed
2
I haven't thought deeply about this specific case, but I think you should consider this like any other ablation study--like, what happens if you replace the SAE with a linear probe?
Why no prediction markets for large infrastructure projects?
Been reading this excellent piece on why prediction markets aren't popular. They say that without subsidies prediction markets won't be large enough; the information value of prediction markets is often nog high enough.
Large infrastructure projects undertaken by governments, and other large actors often go overbudget, often hilariously so: 3x,5x,10x or more is not uncommon, indeed often even the standard.
One of the reasons is that government officials deciding on billion dollar infrastructure projects don't have enough skin in the game. Politicians are often not long enough in office to care on the time horizons of large infrastructure projects. Contractors don't gain by being efficient or delivering on time. To the contrary, infrastructure projects are huge cashcows. Another problem is that there are often far too many veto-stakeholders. All too often the initial bid is wildly overoptimistic.
Similar considerations apply to other government projects like defense procurement or IT projects.
Okay - how to remedy this situation? Internal prediction markets theoretically could prove beneficial. All stakeholders &...
2
Doesn't the futarchy hack come up here? Contractors will be betting that competitors timelines and cost will be high, in order to get the contract.
8
The standard reply is that investors who know or suspect that the market is being systematically distorted will enter the market on the other side, expecting to profit from the distortion. Empirically, attempts to deliberately sway markets in desired directions don’t last very long.
Fractal Fuzz: making up for size
GPT-3 recognizes 50k possible tokens. For a 1000 token context window that means there are possible prompts. Astronomically large. If we assume the output of a single run of gpt is 200 tokens then for each possible prompt there are possible continuations.
GPT-3 is probabilistic, defining for each possible prompt () a distribution on a set of size , in other words a dimensional space. [1]
Mind-boggingly large. Compared to these numbers the amount of data (40 trillion tokens??) and the size of the model (175 billion parameters) seems absolutely puny in comparison.
I won't be talking about the data, or 'overparameterizations' in this short, that is well-explained by Singular Learning Theory. Instead, I will be talking about nonrealizability.
Nonrealizability & the structure of natural data
Recall the setup of (parametric) Bayesian learning: there is a sample space , a true distribution on and a parameterized family of probability distributions .
It is often assumed that the true distrib...
1
Very interesting, glad to see this written up! Not sure I totally agree that it's necessary for W to be a fractal? But I do think you're onto something.
In particular you say that "there are points y in the larger dimensional space that are very (even arbitrarily) far from W," but in the case of GPT-4 the input space is discrete, and even in the case of e.g. vision models the input space is compact. So the distance must be bounded.
Plus if you e.g. sample a random image, you'll find there's usually a finite distance you need to travel in the input space (in L1, L2, etc) until you get something that's human interpretable (i.e. lies on the data manifold). So that would point against the data manifold being dense in the input space.
But there is something here, I think. The distance usually isn't that large until you reach a human interpretable image, and it's quite easy to perturb images slightly to have completely different interpretations (both to humans and ML systems). A fairly smooth data manifold wouldn't do this. So my guess is that the data "manifold" is in fact not a manifold globally, but instead has many self-intersections and is singular. That would let it be close to large portions of input space without being literally dense in it. This also makes sense from an SLT perspective. And IIRC there's some empirical evidence that the dimension of the data "manifold" is not globally constant.
2
The input and output spaces etc Ω are all discrete but the spaces of distributions Δ(Ω) on those spaces are infinite (but still finite-dimensional).
It depends on what kind of metric one uses, compactness assumptions etc whether or not you can be arbitrarily far. I am being rather vague here. For instance, if you use the KL-divergence, then K(q|puniform) is always bounded - indeed it equals the entropy of the true distribution H(q)!
I don't really know what ML people mean by the data manifold so won't say more about that.
I am talking about the space W of parameter values of a conditional probability distribution p(x|w).
I think that W having nonconstant local dimension doesn't seem that relevant since the largest dimensional subspace would dominate?
Self-intersections and singularities could certainly occur here. (i) singularities in the SLT sense have to do with singularities in the level sets of the KL-divergence (or loss function) - don't see immediately how these are related to the singularities that you are talking about here (ii) it wouldn't increase the dimensionality (rather the opposite).
The fractal dimension is important basically because of space-filling curves : a space that has a low-dimensional parameterization can nevertheless have a very large effective dimensions when embedded fractally into a larger-dimensional space. These embeddings can make a low-dimensional parameterization effectively have higher dimension.
1
Sorry, I realized that you're mostly talking about the space of true distributions and I was mainly talking about the "data manifold" (related to the structure of the map x↦p(x∣w∗) for fixed w∗). You can disregard most of that.
Though, even in the case where we're talking about the space of true distributions, I'm still not convinced that the image of W under p(x∣w) needs to be fractal. Like, a space-filling assumption sounds to me like basically a universal approximation argument - you're assuming that the image of W densely (or almost densely) fills the space of all probability distributions of a given dimension. But of course we know that universal approximation is problematic and can't explain what neural nets are actually doing for realistic data.
3
Obviously this is all speculation but maybe I'm saying that the universal approximation theorem implies that neural architectures are fractal in space of all distributtions (or some restricted subset thereof)?
Curious what's your beef with universal approximation? Stone-weierstrass isn't quantitative - is that the reason?
If true it suggest the fractal dimension (probably related to the information dimension I linked to above) may be important.
1
Oh I actually don't think this is speculation, if (big if) you satisfy the conditions for universal approximation then this is just true (specifically that the image of W is dense in function space). Like, for example, you can state Stone-Weierstrass as: for a Hausdorff space X, and the continuous functions under the sup norm C(X,R), the Banach subalgebra of polynomials is dense in C(X,R). In practice you'd only have a finite-dimensional subset of the polynomials, so this obviously can't hold exactly, but as you increase the size of the polynomials, they'll be more space-filling and the error bound will decrease.
The problem is that the dimension of W required to achieve a given ϵ error bound grows exponentially with the dimension d of your underlying space X. For instance, if you assume that weights depend continuously on the target function, ϵ-approximating all Cn functions on [0,1]d with Sobolev norm ≤1 provably takes at least O(ϵ−d/n) parameters (DeVore et al.). This is a lower bound.
So for any realistic d universal approximation is basically useless - the number of parameters required is enormous. Which makes sense because approximation by basis functions is basically the continuous version of a lookup table.
Because neural networks actually work in practice, without requiring exponentially many parameters, this also tells you that the space of realistic target functions can't just be some generic function space (even with smoothness conditions), it has to have some non-generic properties to escape the lower bound.
2
Ooooo okay so this seems like it's directly pointing to the fractal story! Exciting!
2
Obviously this is all speculation but maybe I'm saying that the universal approximation theorem implies that neural architectures are fractal in space of all distributtions (or some restricted subset thereof)?
Stone-weierstrass isn't quantitative. If true it suggest the fractal dimension (probably related to the information dimension I linked to above) may be important.
The Vibes of Mathematics:
Q: What is it like to understand advanced mathematics? Does it feel analogous to having mastery of another language like in programming or linguistics?
A: It's like being stranded on a tropical island where all your needs are met, the weather is always perfect, and life is wonderful.
Except nobody wants to hear about it at parties.
Vibes of Maths: Convergence and Divergence
level 0: A state of ignorance. you live in a pre-formal mindset. You don't know how to formalize things. You don't even know what it would even mean 'to prove something mathematically'. This is perhaps the longest. It is the default state of a human. Most anti-theory sentiment comes from this state. Since you've neve
You can't productively read Math books. You often decry that these mathematicians make books way too hard to read. If they only would take the time to explain things simply you would understand.
level 1 : all math is amorphous blob
You know the basic of writing an epsilon-delta proof. Although you don't know why the rules of maths are this or that way you can at least follow the recipes. You can follow simple short proofs, albeit slowly.
You know there are differen...
I say that knowing particular kinds of math, the kind that let you model the world more-precisely, and that give you a theory of error, isn't like knowing another language. It's like knowing language at all. Learning these types of math gives you as much of an effective intelligence boost over people who don't, as learning a spoken language gives you above people who don't know any language (e.g., many deaf-mutes in earlier times).
The kinds of math I mean include:
- how to count things in an unbiased manner; the methodology of polls and other data-gathering
- how to actually make a claim, as opposed to what most people do, which is to make a claim that's useless because it lacks quantification or quantifiers
- A good example of this is the claims in the IPCC 2015 report that I wrote some comments on recently. Most of them say things like, "Global warming will make X worse", where you already know that OF COURSE global warming will make X worse, but you only care how much worse.
- More generally, any claim of the type "All X are Y" or "No X are Y", e.g., "Capitalists exploit the working class", shouldn't be considered claims at all, and can accomplish nothing except foment arg
1
Thanks for writing this. I only wish it was longer.
3
You seem to do OK...
This is an interesting one. I field this comment quite often from undergraduates, and it's hard to carve out enough quiet space in a conversation to explain what they're doing wrong. In a way the proliferation of math on YouTube might be exacerbating this hard step from tourist to troubadour.
2
"Eat your brocolli" - Daniel Murfet
Eightfold path of option trading
Threefold duality and the Eightfold path of Option Trading
It is a truth universally acknowledged that the mere whiff of duality is catnip to the mathematician.
Given any asset X, like a stock, sold for a price P means there is a duality between buying and selling: one party buys X for P while another sells X for P.
Implicitly there is another duality: instead of interchanging the buy and sell actions, one can interchange the asset X and the price P, treating money as an asset and the asset as a medium of exchange.
A European call option at strike price S gives one the option to buy the underlying asset X at price S on the expiration date. [1]
There is a dual option - called a (European) put option that gives one the right [option] to sell the underlying on the expiration date.
Optionality is beautiful. Optionality is brilliant. The pursuit of optionality writ large is the great purpose of the higher limbic system. An option is optionality incarnate, offering limited downside yet unlimited upside potential.
There are much more classic financial instruments, but options represent a powerful abstraction layer on top of direct asset ownership.
Rk. Any security'...
[this is a draft. I strongly welcome comments]
The Latent Military Realities of the Coming Taiwan Crisis
A blockade of Taiwan seems significantly more likely than a full-scale invasion. The US's non-intervention in Ukraine suggests similar restraint might occur with Taiwan.
Nevertheless, Metaculus predicts a 65% chance of US military response to a Chinese invasion and separately gives 20-50% for some kind of Chinese military intervention by 2035. Let us imagine that the worst comes to pass and China and the United States are engaged in a hot war?
China's national memory of the 'century of humiliation' deeply shapes its modern strategic thinking. How many Westerners could faithfully recount the events of the Opium Wars? How many have even heard of the Boxer Rebellion, the Eight-nation alliance, the Tai-Ping rebellion? Yet these events are the core curriculum in Chinese education.
Chinese revanchism toward the West enjoys broad public support. The CCP repression of Chinese public opinion likely understates how popular this view is. CCP officals actually have more dovish view than the general public according to polling.
As other pieces of evidence: historically, the Boxer...
4
That sounds like an exaggeration? My impression is that China has OK/good relations with countries such as Vietnam, Cambodia, Pakistan, Indonesia, North Korea, factions in Myanmar. And Russia, of course. If you're serious about this claim, I think you should look at a map, make a list of countries which qualify as "neighbors" based purely on geographic distance, then look up relations for each one.
2
I note you didn't mention the info-sec aspects of the war, I have heard China is better at this than the US, but that doesn't mean much because you would expect to hear that if China was really terrible too.
1
Great write up Alex!
I wonder how well the transparent battlefied translates to the naval setting.
1. Detection and communication through water is significantly harder than air, requiring shorter distances.
2. Surveilling a volume scales worse than a surface.
Am I missing something or do you think drones will just scale anyway?
4
Great to hear this post had \geq 1 readers hah.
* both the US and China are already deploying a number of surface and underwater drones. Ukraine has had a lot of success with surface suicide drones sinking several Russian ships iirc, damaging bridges etc. Outside of Ukraine and Russia, maybe Israel, nobody is really on the ball when it comes to military competitiveness. To hit home this point, consider that the US military employs about 10.000 drones of all sizes while Ukraine, with an economy 1/5 of the Netherlands, now produces 1-4 million drones a year alone. [ofc drones vary widely in size and capability so this is ofc a little misleading] It should be strongly suspected that when faced with a real peer opponent warring powers will quickly realize they need to massively up production of drones.
* there is an interesting acoustic phenomenon where a confluence of environmental factors (like sea depth, temperature, range, etc) create 'sonar deadzones' where submarines are basically invisible. The exact nature of these deadzones is a closely-held state secret - as is the exact design of submarines to make them as silent as possible. As stated, my understanding is that is one of a few remaining areas where the US has a large technological advantage over her Chinese counterparts. You can't hit something you can't see so this advantage is potentially very large. As mentioned, a single torpedo hit will sink a ship; a ballistic missile hit is a mission kill; both attack submarines and ballistic missile submarines are lethal.
* Although submarines can dive fairly deep, there are various constraints on how deep they typically dive. e.g. they probably want to stay in these sonar deadzones.
-> There was an incident a while back where a (russian? english? french?) submarine hit another submarine (russian? englih? french?) by accident. It underscores how silent submarines are and how there are probably preferred regions underwater where submarines are much more likely t
1
Damn! Dark forest vibes, very cool stuff!
Reference for the sub collision: https://en.wikipedia.org/wiki/HMS_Vanguard_and_Le_Triomphant_submarine_collision
And here's another one!
https://en.wikipedia.org/wiki/Submarine_incident_off_Kildin_Island
Might as well start equipping them with fenders at this point.
And 2050 basically means post-AGI at this point. ;)
Elon building massive 1 million gpu data center in Tennessee. Tens of billions of dollars. Intends to leapfrog competitors.
EA handwringing about Sam Altman & anthropicstanning suddenly pretty silly?
8
I don't understand how the second sentence follows from the first?
2
In EA there is a lot of chatter about OpenAI being evil and why you should do this coding bootcamp to work at Anthropic. However there are a number of other competitors - not least of which Elon Musk - in the race to AGI. Since there is little meaningful moat beyond scale [and the government is likely to be involved soon] all the focus on the minutia of OpenAI & Anthropic may very well end up misplaced.
all the focus on the minutia of OpenAI & Anthropic may very well end up misplaced.
This doesn't follow. The fact that OpenAI and Anthropic are racing contributes to other people like Musk deciding to race, too. This development just means that there's one more company to criticize.
4
The concrete news is a new $6 billion round, which enables xAI to follow through on the intention to add another 100K H100s (or a mix of H100s and H200s) to the existing 100K H100s. The timeline for a million GPUs remains unknown (and the means of powering them at that facility even more so).
Going fast with 1M H100s might be a bad idea if the problem with large minibatch sizes I hypothesize is real, that large minibatch sizes are both very bad and hard to avoid in practice when staying with too many H100s. (This could even be the reason for underwhelming scaling outcomes of the current wave of scaling, if that too is real, though not for Google.)
Aiming for 1M B200s only doubles or triples Microsoft's planned 300K-700K B200s, so it's not a decisive advantage and even less meaningful without a timeline (at some point Microsoft could be doubling or tripling training compute as well).
For the next few months Anthropic might have the compute lead (over OpenAI, Meta, xAI; Google is harder to guess). And if the Rainier cluster uses Trn2 Ultra rather than regular Trn2, there won't even be a minibatch size problem there (if the problem is real), as unlike with H100s that form 8-GPU scale-up domains, the Trn2 Ultra machines have 64-GPU scale-up domains, for 41 units of H100-equivalent compute per scale-up domain.
3
I mean, here are two comments I wrote three weeks ago, in a shortform about Musk being able to take action against Altman via his newfound influence in government:
And:
1
Yes you have a point.
I believe that building massive data centers are the biggest risk atm and in the near future. I don't think open AI/Anthropic will get to AGI, but rather someone copying biology will. In that case probably the bigger the datacenter around when that happens, the bigger the risk. For example a 1million GPU with current tech doesn't get super AI, but when we figure out the architecture, it suddenly becomes much more capable and dangerous. That is from IQ 100 up to 300 with a large overhang. If the data center was smaller, then the overhang is smaller. The scenario I have in mind is someone figures AGI out, then one way or another the secret gets adopted suddenly by the large data center.
For that reason I believe focus on FLOPS for training runs is misguided, its hardware concentration and yearly worldwide HW production capacity that is more important.
Will there be >1 individual per solar system?
A recently commonly heard viewpoint on the development of AI states that AI will be economically impactful but will not upend the dominancy of humans. Instead AI and humans will flourish together, trading and cooperating with one another. This view is particularly popular with a certain kind of libertarian economist: Tyler Cowen, Matthew Barnett, Robin Hanson.
They share the curious conviction that the probablity of AI-caused extinction p(Doom) is neglible. They base this with analogizing AI with previous technological transition of humanity, like the industrial revolution or the development of new communication mediums. A core assumption/argument is that AI will not disempower humanity because they will respect the existing legal system, apparently because they can gain from trades with humans.
The most extreme version of the GMU economist view is Hanson's Age of EM; it hypothesizes radical change in the form of a new species of human-derived uploaded electronic people which curiously have just the same dreary office jobs as we do but way faster.
Why is there trade & specialization in the first place?
Trade and specializ...
A recently commonly heard viewpoint on the development of AI states that AI will be economically impactful but will not upend the dominancy of humans. Instead AI and humans will flourish together, trading and cooperating with one another. This view is particularly popular with a certain kind of libertarian economist: Tyler Cowen, Matthew Barnett, Robin Hanson.
They share the curious conviction that the probablity of AI-caused extinction p(Doom) is neglible. They base this with analogizing AI with previous technological transition of humanity, like the industrial revolution or the development of new communication mediums. A core assumption/argument is that AI will not disempower humanity because they will respect the existing legal system, apparently because they can gain from trades with humans.
I think this summarizes my view quite poorly on a number of points. For example, I think that:
-
AI is likely to be much more impactful than the development of new communication mediums. My default prediction is that AI will fundamentally increase the economic growth rate, rather than merely continuing the trend of the last few centuries.
-
Biological humans are very unlikely to remain
4
I see, thank you for the clarification. I should have been more careful with mischaracterizing your views.
I do have a question or two about your views if you would entertain me. You say humans wikl be economically obsolete and will 'retire' but there will still be trade between humans and AI. Does trade here just means humans consuming, I.e. trading money for AI goods and services? That doesn't sound like trading in the usual sense where it is a reciprocal exchange of goods and services.
How many 'different' AI individuals do you expect there to be ?
4
Trade can involve anything that someone "owns", which includes both their labor and their property, and government welfare. Retired people are generally characterized by trading their property and government welfare for goods and services, rather than primarily trading their labor. This is the basic picture I was trying to present.
I think the answer to this question depends on how we individuate AIs. I don't think most AIs will be as cleanly separable from each other as humans are, as most (non-robotic) AIs will lack bodies, and will be able to share information with each other more easily than humans can. It's a bit like asking how many "ant units" there are. There are many individual ants per colony, but each colony can be treated as a unit by itself. I suppose the real answer is that it depends on context and what you're trying to figure out by asking the question.
[Is there a DOOM theorem?]
I've noticed lately my pdoom is dropping - especially in the next decade or two. I was never a doomer but still had >5% pDoom. Most of the doominess came from fundamental uncertainty about the future and how minds & intelligence actually work. As that uncertainty has resolved, my pdoom - at least short term - has gone down quite a bit. What's interesting is that RLHF seems to give Claude a morality that's "better" than regular humans in many ways.
Now that's not proving misalignment impossible ofc. Like I've said before, current LLMs aren't full AGI imho - that would need to be a "universal intelligence" which necessarily has an agentic and RL component. That's where misalignment can sneak in. Still, the Claude RLHF baseline looks pretty strong.
The main way I would see things go wrong in the longer term is if some of the classical MIRI intuitions as voiced by Eliezer and Nate are valid, e.g. deep deceptiveness.
Could there be a formal result that points to inherent misalignement at sufficient scale? A DOOM theorem... if you will?
Christiano's acausal attack/ Solomonoff malign prior is the main argument that comes to mind. There are also various results on instrumental convergence but this doesn't quite necessarily directly imply misalignment...
On this:
Could there be a formal result that points to inherent misalignement at sufficient scale? A DOOM theorem... if you will?
My guess is probably not, and that misalignment/doom will be dependent on which settings you pick for a formalization of intelligence, so at best you can show possibility results, not universal results.
Christiano's acausal attack/ Solomonoff malign prior is the main argument that comes to mind. There are also various results on instrumental convergence but this doesn't quite necessarily directly imply misalignment..
IMO, the Solomonoff prior isn't malign, and I think the standard argument for Solomonoff prior malignness doesn't work both in practice and in theory.
The in practice part is that we can make the malignness go down if we have more such oracles, which is basically a capabilities problem, and under a lot of models of how we get Solomonoff induction to work, it also implies we can get an arbitrary amount of Solomonoff oracle copies out of the original, which makes it practically insiginificant.
More here:
The in theory part is I don't believ...
7
Learning from human data might have large attractors that motivate AIs to build towards better alignment, in which case prosaic alignment might find them. If those attractors are small, and there are more malign attractors in the prior that remain after learning human data, short-term manual effort of prosaic alignment fails. So malign priors have the same mechanism of action as effectiveness of prosaic alignment, it's the question of how learning on human data ends up being expressed in the models, what happens after the AIs built from them are given more time to reflect.
Managing to scale RL too early can make this irrelevant, enabling sufficiently competent paperclip maximization without dominant influence from either malign priors of from beneficial attractors in human data. Unclear if o1/o3 are pointing in this direction yet, so far they might just be getting better at eliciting human System 2 capabilities from base models, rather than being creative at finding novel ways of effective problem solving.
Of Greater Agents and Lesser Agents
How do more sophisticated decision-makers differ from less sophisticated decision-makers in their behaviour and values?
Smarter more sophisticated decisionmakers engage in more and more complex commitments — including meta-commitments not to commit. Consequently, the values and behaviour of these more sophisticated decisionmakers "Greater Agents" are systematically biased compared to less sophisticated decisionmakers "Lesser Agents".
*******************************
Compared to Lesser Agents, the Greater Agents are more judgemental, (self-)righteous, punish naivité, are more long-term oriented, adaptive, malleable, self-modifying, legibly trustworthy and practice more virtue-signalling, strategic, engage in self-reflection & metacognition, engage in more thinking, less doing, symbolic reasoning, consistent & 'rational' in their preferences, they like money & currency more, sacred values less, value engagement in thinking over doing, engaged in more "global" conflicts [including multiverse-wide conflicts throguh acausal trade], less empirical, more rational, more universalistic in their morals, and more cosmopolitan in their esthetics, they...
Ryan Greenblatt on steering the AI paradigm:
...I'm skeptical of strategies which look like "steer the paradigm away from AI agents + modern generative AI paradigm to something else which is safer". Seems really hard to make this competitive enough and I have other hopes that seem to help a bunch while being more likely to be doable.
(This isn't to say I expect that the powerful AI systems will necessarily be trained with the most basic extrapolation of the current paradigm, just that I think steering this ultimate paradigm to be something which is quite differ
Solar + wind has made a huge dent in energy production, so I feel like this example is confused.
It does seem like this strategy just really worked quite well, and a combination of battery progress and solar would probably by-default replace much of fossil-fuel production in the long run. It already has to a quite substantial degree:
Hydro + Solar + Wind + other renewables has grown to something like 40% of total energy production (edit: in the EU, which feels like the most reasonable reference class for whether this worked).
4
No, it is not confused. Be careful with reading precisely what I wrote. I said total energy production worldwide, not electricity production in the european union.
As you can see Solar is still a tiny percentage of energy consumption. That is not to say that things will not change - I certainly hope so! I give it significant probability. But if we are to be honest with ourselves than it is currently yet to be seen whether solar energy will prove to be the solution.
Moreover, in the case that solar energy does take over and ' solve' climate change that still does not prove the thesis - that solar energy solving climate change being majorly the result of deliberate policy instead of the result of market forces / ceteris paribus technological development.
9
The strong version of this argument seems false (eg Habryka's comment), but I think the weak version is true. That is, energy put into "purposely and deliberately develop a technology Y that is fundamentally different than X that does the same role as X without harm Z but slightly less competitively." is inefficient compared to energy put into strategies (i), (ii), and (iii).
9
Please read carefully what I wrote - I am talking about energy consumption worldwide not electricity consumption in the EU. Electricity in the EU accounts only for a small percentage of carbon emissions.
See
As you can see, solar energy is still a tiny percentage of total energy sources. I don't think it is an accident that the electricity split graph in the EU has been cited in this discussion because it is a proxy that is much more rose-colored.
Energy and electricity are often conflated in discussions around climate change, perhaps not coincidentally because the latter seems much more tractable to generate renewably than total energy production.
Thermal vision cuts right through tree cover, traditional camouflage and the cover of night.
Human soldiers in the open are helpless against cheap FPS drones with thermal vision.
A youtubw channel went through a dozen countermeasures. Nothing worked except one: Umbrellas.
1
Future wars are about to look very silly.
Hot Take #44: Preaching to the choir is 'good' actually.
- Almost anything that has a large counterfactual impact is achieved by people thinking and acting different from accepted ways of thinking and doing.
- With the exception of political entrepeneurs jumping into a power vacuum, or scientific achievements by exceptional individuals most counterfactual impactful is done made by movements of fanatics.
- The greatest danger to any movement is dissipation. Conversely, the greatest resource of any movement is the fanaticism of its members.
- Most persuasion is
5
This seems like an argument in favor of:
Stability over potential improvement, tradition over change, mutation over identical offspring, settling in a local maximum over shaking things up, and specialization vs generalization.
It seems like a hyperparameter. A bit like the learning rate in AI perhaps? Echo chambers are a common consequence, so I think the optimal ratio of preaching to the choir is something like 0.8-0.9 rather than 1. In fact, I personally prefer the /allPosts suburl over the LW frontpage because the first few votes result in a feedback loop of engagement and upvotes (forming a temporary consensus on which new posts are better, in a way which seems unfairly weighted towards the first few votes). If the posts chosen for the frontpage use the ratio of upvotes and downvotes rather than the absolute amount, then I don't thing this bias will occur (conformity might still create a weak feedback loop though).
I'm simplifying some of these dynamics though.
Wildlife Welfare Will Win
The long arc of history bend towards gentleness and compassion. Future generations will look with horror on factory farming. And already young people are following this moral thread to its logical conclusion; turning their eyes in disgust to mother nature, red in tooth and claw. Wildlife Welfare Done Right, compassion towards our pets followed to its forceful conclusion would entail the forced uploading of all higher animals, and judging by the memetic virulences of shrimp welfare to lower animals as well.
Morality-upon-reflex...
Proof of Collusion: How Perfect Trust Enables Perfect Betrayal
Alternate Claude titles I liked:
Superintelligent Handshakes: How Cryptographic Advances Could Undermine AI Safety
"Superrational Serpents: The Paradox of AI Systems That Cooperate Too Well"
[This document is a smattering of ideas around the topic that advanced cryptography and proof verification could enable yet-unseen forms of cooperations between Artificial Intelligences. Currently, the arguments aren’t watertight and completely thought through and I’m not confident any of this...
4
IMO, my response is that I expect several of the prerequisites for the scenario to occur to happen well past the time of perils, in that either we go extinct or we have muddled through and successfully aligned ASI, in particular I expect formal verification of neural networks to be extremely hard, and if we could do this in a scalable way, this would allow you to do much more deep interpretability/safety properties, such that it would make AI safety a whole lot easier.
EDIT: I was wrong. Theo the French Whale was the sharp. From the Kelly formula and his own statements his all things considered probability was 80-90% - he would need to possess an enormous amount of private information to justify such a deviation from other observers. It turns out he did. He commissioned his own secret polls using a novel polling method to compensate for the shy Trump voter.
https://x.com/FellowHominid/status/1854303630549037180
The French rich idiot who bought 75 million dollar of Trump is an EA hero win or lose.
LW loves prediction markets...
I disagree with “He seems to have no inside information.” He presented himself as having no inside information, but that’s presumably how he would have presented himself regardless of whether he had inside information or not. It’s not like he needed to convince others that he knows what he’s doing, like how in the stock market you want to buy then pump then sell. This is different—it’s a market that’s about to resolve. The smart play from his perspective would be to aggressively trash-talk his own competence, to lower the price in case he wants to buy more.
4
Yes, this is possible. It smells a bit of 4d-chess. As far as I can tell he already had finalized his position by the time the WSJ interview came out.
I've dug a little deeper and it seems he did do a bunch of research on polling data. I was a bit too rash to say he had no inside information whatsoever. Plausibly he had some. The degree of the inside information he would need is very high. It seems he did a similar Kelly bet calculation since he report his all-things-considered probability to be 80-90%:
"With so much money on the line, Théo said he is feeling nervous, though he believes Trump has an 80%-90% chance to win the election.
"A surprise can always occur," Théo told The Journal."
I have difficulty believing one can get this kind of certainty for all-things-considered-probability for something as noisy and tight as US presidential election. [but he won both the electoral college and popular vote bet]
2
To me it just seems like understanding the competitive nature of the prediction markets.
In our bubble, prediction markets are celebrated as a way to find truth collectively, in a way that disincentivizes bullshit. And that's what they are... from outside.
But it's not how it works from the perspective of the person who wants to make money on the market! You don't want to cooperate on finding the truth; you actually wish for everyone else to be as wrong as possible, because that's when you make most money. Finding the truth is what the mechanism does as a whole; it's not what the individual participants want to do. (Similarly how economical competition reduces the prices of goods, but each individual producer wishes they could sell things as expensively as possible.) Telling the truth means leaving money on the table. As a rational money-maximizer, you wish that other people believe that you are an idiot! That will encourage them to bet against you more, as opposed to updating towards your position; and that's how you make more money.
This goes strongly against our social instincts. People want to be respected as smart. That's because in social situation, your status matters. But the prediction markets are the opposite of that: status doesn't matter at all, only being right matters. It makes sense to sacrifice your status in order to make more money. Would you rather be rich, or famous as a superforecaster?
This could be a reason why money-based prediction markets will systematically differ from prestige-based prediction markets. In money-based markets, charisma is a dump stat. In prestige-based ones, that's kinda the entire point.
Looks likely that tonight is going to be a massive transfer of wealth from "sharps"(among other people) to him. Post hoc and all, but I think if somebody is raking in huge wins while making "stupid" decisions it's worth considering whether they're actually so stupid after all.
>> 'a massive transfer of wealth from "sharps" '.
no. That's exactly the point.
1. there might no be any real sharps (=traders having access to real private arbitragiable information that are consistently taking risk-neutral bets on them) in this market at all.
This is because a) this might simple be a noisy, high entropy source that is inherently difficult to predict, hence there is little arbitragiable information and/or b) sharps have not been sufficiently incenticiz
2. The transfer of wealth is actually disappointing because Theo the French Whale moved the price so much.
For an understanding of what the trading decisions of a verifiable sharp looks like one should take a look at Jim Simons' Medaillon fund. They do enormous hidden information collection, ?myssterious computer models, but at the end of the day take a large amount of very hedged tiny edge positions.
***************************************************
You are misunderstanding my argument (and most of the LW commentariat with you). I might note that I made my statement before the election result and clearly said 'win or lose' but it seems that even on LW people think winning on a noisy N=1 sample is proof of rationality.
4
It's not proof of a high degree of rationality but it is evidence against being an "idiot" as you said. Especially since the election isn't merely a binary yes/no outcome, we can observe that there was a huge republican blowout exceeding most forecasts(and in fact freddi bet a lot on republican pop vote too at worse odds, as well as some random states, which gives a larger update) This should increase our credence that predicting a republican win was rational. There were also some smart observers with IMO good arguments that trump was favored pre-election, e.g. https://x.com/woke8yearold/status/1851673670713802881
"Guy with somewhat superior election modeling to Nate Silver, a lot of money, and high risk tolerance" is consistent with what we've seen. Not saying that we have strong evidence that Freddi is a genius but we also don't have much reason to think he is an idiot IMO.
4
Okay fair enough "rich idiot" was meant more tongue-in-cheek - that's not what I intended.
That's why I said: "In expectation", "win or lose"
That the coinflip came out one way rather than another doesnt prove the guy had actual inside knowledge. He bought a large part of the shares at crazy odds because his market impact moved the price so much.
But yes, he could be a sharp in sheeps clothings. I doubt it but who knows. EDIT: I calculated the implied private odds for a rational Kelly bettor that this guy would have to have. Suffice to say these private odds seem unrealistic for election betting.
Point is that the winners contribute epistemics and the losers contribute money. The real winner is society [if the questions are about socially-relevant topics].
3
I agree with you that people like him do a service to prediction markets: contributing a huge amount of either liquidity or information. I don't agree with you that it is clear which one he is providing, especially considering the outcome. He did also win his popular vote bet, which was hovering around, I'm not sure, ~20% most of the time?
I think he (Theo) probably did have a true probability around 80% as well. That's what it looks like at least. I'm not sure why you would assume he should be more conservative than Kelly. I'm sure Musk is not, as one example of a competent risk-taker.
2
The true probability would be more like >90% considering other factors like opportunity costs, transactions cost, counterparty risk, unforeseen black swans of various kinds etc.
Bear in mind this is all things considered probability not just in-model probability, i.e. this would have to integrate that most other observers (especially those with strong calibrated prediction ) very strongly disagree*. Certainly, in some cases this is possible but one would need quite overwhelming evidence that you had a huge edge.
I agree one can reject Kelly betting - that's pretty crazy risky but plausibly the case for people like Elon or Theo. The question is whether the rest of us (with presumably more reasonably cautious attitudes) should take his win as much epistemic evidence. I think not. From our perspective his manic riskloving wouldn't be an much evidence for rational expectations.
*didn't the Kelly formula already integrate the fact that other people think differently. No, this is an additional piece of information one has to integrate. The Kelly betting gives you an implicit risk-averseness even conditioning on your beliefs being true (on average).
EDIT: Indeed it seems Theo the French Whale might have done a Kelly bet estimate too, he reports his true probability at 80-90%. Perhaps he did have private information.
"For example, a hypothetical sale of Théo's 47 million shares for Trump to win the election would execute at an estimated average price of just $0.02, according to Polymarket, which would represent a 96% loss for the trader. Théo paid an average price of about $0.56 cents for the 47 million shares.
Meanwhile, a hypothetical sale of Théo's nearly 20 million shares for Trump to win the popular vote would execute at an average price of less than a 10th of a penny, according to Polymarket, representing a near-total loss.
With so much money on the line, Théo said he is feeling nervous, though he believes Trump has an 80%-90% chance to win the electio
On the word 'theory'.
The word 'theory' is oft used and abused.
there is two ways 'theory' is used that are different and often lead to confusion.
Theory in thescientific sense
the way a physicist would use: it's a model of the world that is either right or wrong. there might be competing theories and we neeed to have empirical evidence to figure out which one's right. Ideally, they agree with empirical evidence or at least are highly falsifiable. Importantly, if two theories are to conflict they need to actually speak about the same variables, the...
2
Formal frameworks considered in isolation can't be wrong. Still, they often come with some claims like "framework F formalizes some intuitive (desirable?) property or specifies the right way to do some X and therefore should be used in such-and-such real-world situations". These can be disputed and I expect that when somebody claims like "{Bayesianism, utilitarianism, classical logic, etc} is wrong", that's what they mean.
2
There's a related confusion between uses of "theory" that are neutral about the likelihood of the theory being true, and uses that suggest that the theory isn't proved to be true.
Cf the expression "the theory of evolution". Scientists who talk about the "theory" of evolution don't thereby imply anything about its probability of being true - indeed, many believe it's overwhelmingly likely to be true. But some critics interpret this expression differently, saying it's "just a theory" (meaning it's not the established consensus).
[see also Hanson on rot, generalizations of the second law to nonequilibrium systems (Baez-Pollard, Crutchfield et al.) ]
Imperfect Persistence of Metabolically Active Engines
All things rot. Indidivual organisms, societies-at-large, businesses, churches, empires and maritime republics, man-made artifacts of glass and steel, creatures of flesh and blood.
Conjecture #1 There is a lower bound on the amount of dissipation / rot that any metabolically-active engine creates.
Conjecture #2 Metabolic Rot of an engine is proportional to (1) size and complexity o...
EDIT 06/11/2024 My thinking has crystallized more on these topics. The current version is lacking but I believe may be steelmanned to a degree.
"I dreamed I was a butterfly, flitting around in the sky; then I awoke. Now I wonder: Am I a man who dreamt of being a butterfly, or am I a butterfly dreaming that I am a man?"- Zhuangzi
Questions I have that you might have too:
- why are we here?
- why do we live in such an extraordinary time?
- Is the simulation hypothesis true? If so, is there a base reality?
- Why do we know we're not a Boltzmann brain?
- Is exist
2
In this comment I will try and write the most boring possible reply to these questions. 😊 These are pretty much my real replies.
"Ours not to reason why, ours but to do or do not, there is no try."
Someone must. We happen to be among them. A few lottery tickets do win, owned by ordinary people who are perfectly capable of correctly believing that they have won. Everyone should be smart enough to collect on a winning ticket, and to grapple with living in interesting (i.e. low-probability) times. Just update already.
It is false. This is base reality. But I can still appreciate Eliezer's fiction on the subject.
The absurdity heuristic. I don't take BBs seriously.
Even in classical physics there is no observation without interaction. Beyond that, no, however many quantum physicists interpret their findings to the public with those words, or even to each other.
Not that I know of. (This is not the same as a flat "no", but for most purposes rounds off to that.)
Either nothing in the case of x-risk, nothing of interest in the case of a final singleton, or wonders far beyond our contemplation, which may not even involve anything we would recognise as "computing". By definition, I can't say what that would be like, beyond guessing that at some point in the future it would stand in a similar relation to the present that our present does to prehistoric times. Look around you. Is this utopia? Then that future won't be either. But like the present, it will be worth having got to.
Consider a suitable version of The Agnostic Prayer inserted here against the possibility that there are Powers Outside the Matrix who may chance to see this. Hey there! I wouldn't say no to having all the aches and pains of this body fixed, for starters. Radical uplift, we'd have to talk about first.
Assuming a Chinese invasion of Taiwan in 2027/2028 what is the most sensible investment strategy?
TSMC puts seem sensible. What are others?
4
Efficient Markets Hypothesis has plenty of exceptions, but this is too coarse-grained and distant to be one of them. Don't ask "what will happen, so I can bet based on that", ask "what do I believe that differs widely from my counterparties". This possibility is almost certainly "priced in" to the obvious bets (TSMC).
That said, you may be more correct than the sellers of long-term puts, so maybe it'll work out. Having a theory and then examining the details and modeling the specific probabilities is exactly what you should be doing. Have you looked at prices and premia for those specific investments? A quick spreadsheet of win/loss in various future paths with as close to real numbers as possible goes a long way.
9
Attribution: Meme by Mariven (partial explanation here). When you say "festival", does that mean in person or online? Does it include acausal trade stuff? Maybe the scope could be broadened to "Arcana Festival" :-)
4
In-person.
Yes acausal trade stuff.
Yes it's the Mariven meme
Mindmeld
In theory AIs can transmit information far faster and more directly than humans. They can directly send weight/activation vectors to one another. The most important variable on whether entities (cells, organisms, polities, companies, ideologies, empire etc) stay individuals or amalgate into a superorganism is communication bandwith & copy fidelity.
Both of these differ many order of magnitude for humans versus AIs. At some point, mere communication becomes a literal melding of minds. It seems quite plausibly then that AIs will tend to mind...
7
A fascinating recent paper on the topic of human bandwidth is https://arxiv.org/abs/2408.10234. Title and abstract:
The Unbearable Slowness of Being
Jieyu Zheng, Markus Meister
The Sun revolves around the Earth actually
The traditional story is that in olden times people were proudly stupid and thought the human animal lived at the centre of the universe, with all the planets, stars and the sun revolving around the God's creation, made in his image. The church would send anybody that said the sun was at the centre to be burned at the stake. [1]
Except...
there is no absolute sense in which the sun is at the centre of the solar system [2]. It's simply a question of perspective, a choice of frame of reference.
- Geocentrism i
6
I think it's pretty good to keep it in mind that heliocentrism is literally speaking just a change in what coordinate system you use, but it is legitimately a much more convenient coordinate system.
6
For everyday life, flat earth is more convenient than round earth geocentrism, which in turn is more convenient than heliocentrism. Like we don't constantly change our city maps based on the time of year, for instance, which we would have to do if we used a truly heliocentric coordinate system as the positions of city buildings are not even approximately constant within such a coordinate system.
This is mainly because the sun and the earth are powerful enough to handle heliocentrism for you, e.g. the earth pulls you and the cities towards the earth so you don't have to put effort into staying on it.
The sun and the planetary motion does remain the most important governing factor for predicting activities on earth, though, even given this coordinate change. We just mix them together into ~epicyclic variables like "day"/"night" and "summer"/"autumn"/"winter"/"spring" rather than talking explicitly about the sun, the earth, and their relative positions.
4
Since you’re already in it: do you happen to know if the popular system of epicycles accurately represented the (relative, per body) distance of each planet from earth over time, or just the angle? I’ve been curious about this for a while but haven’t had time to dig in. They’d at minimum have to get it right for the moon and sun for predicting eclipse type.
Pseudorandom warp fields
[tl;dr the loss landscape around a set of weights encoding an unlearnable 'pseudorandom' function will be warped in such a way that gradient optimizers will bob around for exponentially long. ]
Unlearnable Functions: Sample Complexity and Time Complexity
Computational learning theory contains numerous 'no-go' results indicating that many functions are not tractably learnable.
The most classical result is probably the VC dimension and PAC learnability. A good example to think about are parity functions. The output is, in some sense, ver...
God exists because the most reasonable take is the Solomonoff Prior.
A funny consequence of that is that Intelligent Design will have a fairly large weight in the Solomonoff prior. Indeed the simulation argument can be seen as a version of Intelligent Design.
The Abrahamic God hypothesis is still substantially downweighted because it seems to involve many contigent bits - i.e noisy random bits that can't be compressed. The Solomonoff prior therefore has to downweight them.
4
Please demonstrate that the Solomonoff prior favors simulation.
4
See e.g. Xu (2020) and recent criticism.
2
I was expecting an argument like "most of the probability measure for a given program, is found in certain embeddings of that program in larger programs". Has anyone bothered to make a quantitative argument, a theorem, or a rigorous conjecture which encapsulates this claim?
4
I don't think that statement is true since measure drops off exponentially with program length.
0
This is a common belief around here. Any reason you are skeptical?
0
Thomas Kwa just provided a good reason: "measure drops off exponentially with program length". So embeddings of programs within other programs - which seems to be what a simulation is, in the Solomonoff framework - are considered exponentially unlikely.
edit: One could counterargue that programs simulating programs increase exponentially in number. Either way, I want to see actual arguments or calculations.
2
I just realized what you meant by embedding-- not a shorter program within a longer program, but a short program that simulates a potentially longer (in description length) program.
As applied to the simulation hypothesis, the idea is that if we use the Solomonoff prior for our beliefs about base reality, it's more likely to be laws of physics for a simple universe containing beings that simulate this one as it is to be our physics directly, unless we observe our laws of physics to be super simple. So we are more likely to be simulated by beings inside e.g. Conway's Game of Life than to be living in base reality.
I think the assumptions required to favor simulation are something like
* there are universes with physics 20 bits (or whatever number) simpler than ours in which intelligent beings control a decent fraction >~1/million of the matter/space
* They decide to simulate us with >~1/million of their matter/space
* There has to be some reason the complicated bits of our physics are more compressible by intelligences than by any compression algorithms simpler than their physics; they can't just be iterating over all permutations of simple universes in order to get our physics
* But this seems fairly plausible given that constructing laws of physics is a complex problem that seems way easier if you are intelligent.
Overall I'm not sure which way the argument goes. If our universe seems easy to efficiently simulate and we believe the Solomonoff prior, this would be huge evidence for simulation, but maybe we're choosing the wrong prior in the first place and should instead choose something that takes into account runtime.
1
Why are you a realist about the Solomonoff prior instead of treating it as a purely theoretical construct?
Clem's Synthetic- Physicalist Hypothesis
The mathematico-physicalist hypothesis states that our physical universe is actually a piece of math. It was famously popularized by Max Tegmark.
It's one of those big-brain ideas that sound profound when you first hear about it, then you think about it some more and you realize it's vacuous.
Recently, in a conversation with Clem von Stengel they suggested a version of the mathematico-physicalist hypothesis that I find provoking.
Synthetic mathematics
'Synthetic' mathematics is a bit of weird name...
Know your scientific competitors.
In trading, entering a market dominated by insiders without proper research is a sure-fire way to lose a lot of money and time. Fintech companies go to great lengths to uncover their competitors' strategies while safeguarding their own.
A friend who worked in trading told me that traders would share subtly incorrect advice on trading Discords to mislead competitors and protect their strategies.
Surprisingly, in many scientific disciplines researchers are often curiously incurious about their peers' work.
The long f...
2
Makes sense, but wouldn't this also result in even fewer replications (as a side effect of doing less superfluous work)?
Reasons to think Lobian Cooperation is important
Usually the modal Lobian cooperation is dismissed as not relevant for real situations but it is plausible that Lobian cooperation extends far more broadly than what is proved currently.
It is plausible that much of cooperation we see in the real world is actually approximate Lobian cooperation rather than purely given by traditional game-theoretic incentives.
Lobian cooperation is far stronger in cases where the players resemble each other and/or have access to one another's blueprint. This is ...
7
I definitely agree that cooperation can definitely be way better in the future, and Lobian cooperation, especially with Payor's Lemma, might well be enough to get coordination across entire solar system.
That stated, it's much more tricky to expand this strategy to galactic scales, assuming our physical models aren't wrong, because light speed starts to become a very taut constraint under a galaxy wide brain, and acausal strategies will require a lot of compute to simulate entire civilizations. Even worse, they depend on some common structure of values, and I suspect it's impossible to do in the fully general case.
Agent Foundations Reading List [Living Document]
This is a stub for a living document on a reading list for Agent Foundations.
Causality
Book of Why, Causality - Pearl
Probability theory
Logic of Science - Jaynes
Is Tesla currently overvalued ?
P/e ratio is 188. The ceo has made himself deeply unpopular with many potential customers. Latest sales figures don't look good. Chinese competitors sell more total cars and seem to have caught up in terms of tech.
1
Depends entirely on Cybercab. A driverless car can be made cheaper for a variety of reasons. If the self-driving tech actually works, and if it's widely legal, and if Tesla can mass produce it at a low price, then they can justify that valuation. Cybercab is a potential solution to the problem that they need to introduce a low priced car to get their sales growing again but cheap electric cars is a competitive market now without much profit margin. But there's a lot of ifs.
Are Solomonoff Daemons exponentially dense?
Some doomers have very strong intuitions that doom is almost assured for almost any kind of building AI. Yudkowsky likes to say that alignment is about hitting a tiny part of values space in a vast universe of deeply alien values.
Is there a way to make this more formal? Is there a formal model in which some kind of solomonoff daemon/ mesa-optimizer/ gremlins in the machine start popping up all over the place as the cognitive power of the agent is scaled up?
Imagine that a magically powerful AI decides to set a new political system for humans and create a "Constitution of Earth" that will be perfectly enforced by local smaller AIs, while the greatest one travels away to explore other galaxies.
The AI decides that the most fair way to create the constitution is randomly. It will choose a length, for example 10000 words of English text. Then it will generate all possible combinations of 10000 English words. (It is magical, so let's not worry about how much compute that would actually take.) Out of the generated combinations, it will remove the ones that don't make any sense (an overwhelming majority of them) and the ones that could not be meaningfully interpreted as "a constitution" of a country (this is kinda subjective, but the AI does not mind reading them all, evaluating each of them patiently using the same criteria, and accepting only the ones that pass a certain threshold). Out of the remaining ones, the AI will choose the "Constitution of Earth" randomly, using a fair quantum randomness generator.
Shortly before the result is announced, how optimistic would you feel about your future life, as a citizen of Earth?
9[anonymous]
As an aside (that's still rather relevant, IMO), it is a huge pet peeve of mine when people use the word "randomly" in technical or semi-technical contexts (like this one) to mean "uniformly at random" instead of just "according to some probability distribution." I think the former elevates and reifies a way-too-common confusion and draws attention away from the important upstream generator of disagreements, namely how exactly the constitution is sampled.
I wouldn't normally have said this, but given your obvious interest in math, it's worth pointing out that the answers to these questions you have raised naturally depend very heavily on what distribution we would be drawing from. If we are talking about, again, a uniform distribution from "the design space of minds-in-general" (so we are just summoning a "random" demon or shoggoth), then we might expect one answer. If, however, the search is inherently biased towards a particular submanifold of that space, because of the very nature of how these AIs are trained/fine-tuned/analyzed/etc., then you could expect a different answer.
2
Fair point. (I am not convinced by the argument that if the AI's are trained on human texts and feedback, they are likely to end up with values similar to humans, but that would be a long debate.)
2
what's that analogy supposed to be analogous to? do you think the process of.value formation in an AI is going to have a random element?
2
The question was how to justify the opinion that most possible outcomes are bad. My argument was that if you agree that a random outcome is likely bad... that implies that most outcomes are bad.
If most outcomes were good instead, a random outcome would likely be good.
To answer your question: we do not have a mathematical definition of "friendly", so we will most likely use some heuristic instead. Which heuristic we use, that is one source of randomness. More randomness can be in the implementation details; as a silly example, if we decide that training a LLM on texts of benevolent philosophers is the way to go, it depends on which specific texts we choose. Furthermore, the implementation may contain bugs. Or we may decide that the AI needs to consist of several components, but there are multiple possible solutions how to put those elements together.
There are situations where these sources of randomness don't matter, because we know what we do. For example, if different companies are making calculators in different ways, it is still quite predictable that they will answer 2+2= with 4. Problem is, with friendly AI we don't know what we are doing, so we won't get the feedback when a solution diverges from the ideal. It's like with the early LLMs, the answer to an arithmetic problem containing numbers with more than one digit was quite random.
2
You need to specify whether your "random" is merely undetermined, or an undetermined pick from an equiprobable set. Only the latter allows you to equate most and most likely. But equiprobability isn't a reasonable assumption, because the AIs we build will be guided by our aims and limited by our restrictions.
The MindSpace of the Orthogonality thesis is a set of possibilities. The random potshot version of the OT argument is only one way of turning possibilities into probabilities, and not particularly realistic. While, any of the minds in mindpsace are indeed weird and unfriendly to humans, that does not make it likely that the AIs we will construct will be. we are deliberately seeking to build certainties of mind for one thing, and have certain limitations, for another. Random potshots aren't analogous to the probability density for action of building a certain type of AI, without knowing just ch about what it would be
4
Most configurations of matter, most courses of action, and most mind designs, are not conducive to flourishing intelligent life. Just like most parts of the universe don't contain flourishing intelligent life. I'm sure this stuff has been formally stated somewhere, but the underlying intuition seems pretty clear, doesn't it?
2
This sounds related to my complaint about the YUDKOWSKY + WOLFRAM ON AI RISK debate:
I got this tweet wrong. I meant if pockets of irreducibility are common and non-pockets are rare and hard to find, then the risk from superhuman AI might be lower. I think Stephen Wolfram's intuition has merit but needs more analysis to be convicing.
Four levels of information theory
There are four levels of information theory.
Level 1: Number Entropy
Information is measured by Shannon entropy
Level 2: Random variable
look at the underlying random variable ('surprisal') of which entropy is the expectation.
Level 3: Coding functions
Shannon's source coding theorem says entropy of a source is the expected number of bits for an optimal encoding of samples of .
Related quantity like mutual information, relative entropy, cross e...
[This is joint thinking with Sam Eisenstat. Also thanks to Caspar Oesterheld for his thoughtful comments. Thanks to Steve Byrnes for pushing me to write this out.]
The Hyena problem in long-term planning
Logical induction is a nice framework to think about bounded reasoning. Very soon after the discovery of logical induction people tried to make logical inductor decision makers work. This is difficult to make work: one of two obstacles is
Obstacle 1: Untaken Actions are not Observable
Caspar Oesterheld brilliantly solved this problem by using auction ma...
Idle thoughts about UDASSA I: the Simulation hypothesis
I was talking to my neighbor about UDASSA the other day. He mentioned a book I keep getting recommended but never read where characters get simulated and then the simulating machine is progressively slowed down.
One would expect one wouldn't be able to notice from inside the simulation that the simulating machine is being slowed down.
This presents a conundrum for simulation style hypotheses: if the simulation can be slowed down 100x without the insiders noticing, why not 1000x or 10^100x or ...
2
In most conceptions of simulation, there is no meaning to "slowed down", from the perspective of the simulated universe. Time is a local phenomenon in this view - it's just a compression mechanism so the simulators don't have to store ALL the states of the simulation, just the current state and the rules to progress it.
Note that this COULD be said of a non-simulated universe as well - past and future states are determined but not accessible, and the universe is self-discovering them by operating on the current state via physics rules. So there's still no inside-observable difference between simulated and non-simulated universes.
UDASSA seems like anthropic reasoning to include Boltzmann Brain like conceptions of experience. I don't put a lot of weight on it, because all anthropic reasoning requires an outside-view of possible observations to be meaningful.
And of course, none of this relates to upload, where a given sequence of experiences can span levels of simulation. There may or may not be a way to do it, but it'd be a copy, not a continuation.
2
The point you make in the your first paragraph is contained in the original shortform post. The point of the post is exactly that an UDASSA-style argument can nevertheless recover something like a 'distribution of likely slowdown factors'. This seems quite curious.
I suggest reading Falkovich's post on UDASSA to get a sense whats so intriguing abouy the UDASSA franework.
Why no large hive intelligences?
Ants, social wasps, bees, termites dominate vertebrate biomass. On the insect level these are incredibly dominant in the biosphere. Eusociality is a game-changing tech. Yet with a single exception there are no large hive intelligence. That single exception is the naked mole rat - a rare non-dominant species. Why?
Claude suggests:
- Genetic predisposition: Hymenopteran insects (ants, bees, wasps) have a haplodiploid genetic system where females share 75% of their genes with sisters but only 50% with their own offspring. This crea
4
Eusocial organisms have more specialisation at the individual level rather than non-eusocial organisms (I think). I might expect that I would want a large amount of interchangeable individuals for each specialisation (a low bus factor), rather than more expensive, big, rare entities.
This predicts that complex multicellular organisms would have smaller cells than unicellular organisms or simple multicellular organisms (i.e. those were there isn't differentiation between the cells)
1
Small groups of mammals can already cooperate with each other (wolf's, lions, monkeys etc.). In mammals, I'd guess having a queen gives a bottleneck in how fast there can be off-spring. Also if there are large returns to division of labor in child-rearing, large animals are smart enough that both parents can do this together, while in wasps the males just die (why actually?). So wasps get higher marginal returns when evolving the first steps towards being eusocial. Also smaller animals have more diverse environments and need fewer years to "locked in" eusociality and workers get born without being fertile (eusocial groups where workers are still fertile are really unstable so prone to evolve away from eusociality again when circumstances aren't in favor anymore). Also fathers can't be as sure of their children and the other way around leading to less cooperation if new males join in, which termites overcome by having king and queen, ants just have a queen that stores her sperm, while naked mole rats are just fine with incest?
Looking for specific tips and tricks to break AI out of formal/corporate writing patterns. Tried style mimicry ('write like Hemingway') and direct requests ('be more creative') - both fell flat. What works?
Should I be using different AI models ( I am using GPT and Claude)? The base models output an enormous creative storm, but somehow the RLHF has partially lobotomized LLMs such that they always seem to output either cheesy stereotypes or overly verbose academise/corporatespeak.
4[anonymous]
Edit: ChatGPT and Claude are both fine IMO. Claude has a better ear for language, but ChatGPT's memory is very useful for letting you save info about your preferences, so I'd say they come out about even.
For ChatGPT in particular, you'll want to put whatever prompt you ultimately come up with into your custom instructions or its memory; that way all new conversations will start off pre-prompted.
In addition to borrowing others' prompts as Nathan suggested, try being more specific about what you want (e.g., 'be concise, speak casually and use lowercase, be sarcastic if i ask for something you can't help with'), and (depending on the style) providing examples (ETA: e.g., for poetry I'll often provide whichever llm with a dozen of my own poems in order to get something like my style back out). (Also, for style prompting, IME 'write in a pastiche of [author]' seems more powerful than just 'write like [author]', though YMMV).
3
I have found that they mirror you. If you talk to them like a real person, they will act like a real person. Call them (at least Claude) out on their corporate-speak and cheesy stereotypes in the same way you would a person scared to say what they really think.
2
The two suggestions that come to mind after brief thought are:
1. Search the internet for prompts others have found to work for this. I expect a fairly lengthy and complicated prompt would do better than a short straightforward one.
2. Use a base model as a source of creativity, then run that output through a chat model to clean it up (grammar, logical consistency, etc)
Is true Novelty a Mirage?
One view on novelty is that it's a mirage. Novelty is 'just synthesis of existing work, plus some randomness.'
I don't think that's correct. I think true novelty is more subtle than that. Yes sometimes novel artforms or scientific ideas are about noisily mixing existing ideas. Does it describe all forms of novelty?
A reductio ad absurdum of the novelty-as-mirage point of view is that all artforms that have appeared since the dawn of time are simply noised versions of cavepaintings. This seems absurd.
Consider AlphaGO. Does AlphaGO jus...
2
Creativity is RL, converting work into closing the generation-discrimination gap wherever it's found (or laboriously created by developing good taste). The resulting generations can be novelty-worthy, imitating them makes it easier to close the gap, reducing the need for creativity.
The Virtue of Comparison Shopping
Comparison shopping, informed in-depth reviewing, answering customer surveys plausibly have substantial positive externalities. It provides incentives through local actors, avoids preference falsification or social desirability bias, and is non-coercive & market-based.
Plausibly it is even has a better social impact than many kinds of charitable donations or direct work. This is not so hard since it seems that the latter contains many kinds of interventions that have neglibible or even negative impact.
Gaussian Tails and Exceptional Performers
West African athletes dominate sprinting events, East Africans excel in endurance running, and despite their tiny population Icelanders have shown remarkable prowess in weightlifting competitions. We examine the Gaussian approximation for a simple additive genetic model for these observations.
The Simple Additive Genetic Model
Let's begin by considering a simple additive genetic model. In this model, a trait T is influenced by n independent genes, each contributing a small effect, along with environmental ...
tl;dr
Salmon swimming upstream to their birthing grounds to breed may be that rare form of group selection.
Pure Aryan Salmon
Salmon engage in anodromous reproduction; they risk their lives to swim up rivers to return to their original place of birth and reproduce there.
Most species of salmon die there, only reproducing at the birthing grounds. Many don't make it at all. The ones that survive the run upstream will die shortly after, a biologically triggered death sentence. If the cost is immense - the benefits must be even greater.
The more u...
2
I am confused about what I'm reading. The magikarp gave me a doubletake and like "wait, are magikarp also just a totally real fish?" but after some googling it seems like "nope, that's really just a pokemon", and now I can't tell if the rest of the post is like a parody or what.
0
This post feels like raw GPT-3 output. It's not even GPT-3.5 or GPT-4 level, which makes this additionally confusing.
Maybe a result of playing around with base models?
4
This seems fairly normal for an Alexander post to me (actually, more understandable than the median Alexander shortform). I think the magikarp is meant to be 1) an obfuscation of salamon, and 2) a reference to solid gold magikarp.
@Raemon
2
After rereading it like 4 times I am now less convinced it's GPT output. I still feel confused about a lot of sentences, but I think half of it was just the lack of commas in sentences like "One explanationc could be that anodromous reproduction is a stable game-theoretic equilibrium in which the selective pressure on the salmon species is higher encouraging higher biological fitness".
2
Please tell us more about the magikarps.
1
Bdelloidea are an interesting counterexample: they evolved obligate parthenogenesis ~25 mya.
5
My understanding from reading Mitochondria: Power, Sex, Suicide is that they are not truly asexual but turn out to do some sexual recombination. I don't remember the details and I'm not an expert though so wouldn't put my hand in the fire for it.
Why do people like big houses in the countryside /suburbs?
Empirically people move out to the suburbs/countryside when they get children and/or gain wealth. Having a big house with a large yard is the quintessential American dream.
but why? Dense cities are economoically more productive, commuting is measurably one of the worst factors for happiness and productivity. Raising kids in small houses is totally possible and people have done so at far higher densities in the past.
Yet people will spend vast amounts of money on living in a large house wi...
I can report my own feelings with regards to this. I find cities (at least the American cities I have experience with) to be spiritually fatiguing. The constant sounds, the lack of anything natural, the smells - they all contribute to a lack of mental openness and quiet inside of myself.
The older I get the more I feel this.
Jefferson had a quote that might be related, though to be honest I'm not exactly sure what he was getting at:
I think our governments will remain virtuous for many centuries; as long as they are chiefly agricultural; and this will be as long as there shall be vacant lands in any part of America. When they get piled upon one another in large cities, as in Europe, they will become corrupt as in Europe. Above all things I hope the education of the common people will be attended to; convinced that on their good sense we may rely with the most security for the preservation of a due degree of liberty.
One interpretation of this is that Jefferson thought there was something spiritually corrupting of cities. This supported by another quote:
...
I view great cities as pestilential to the morals, the health and the liberties of man. true, they nourish some of the eleg
5
Note that it could easily be culturally evolved, not genetically. I think there's a lot of explanatory power in the land=status cultural belief as well. But really, I think there's a typical mind fallacy that blinds you to the fact that many people legitimately and truly prefer those tradeoffs over denser city living. Personally, my tastes (and the character of many cities' cores) have noticeably changed over my lifetime - in my youth, I loved the vibrance and variety, and the relatively short commute of being in a city. Now, I value the privacy and quiet that suburban living (still technically in-city, but in a quiet area) gets me.
More importantly, for many coastal American cities, it's simply not true that people pay a lot to live in the suburbs. Even in the inflationary eras of the 1980s, a standalone single-family house in an area where most neighbors are rich and value education is more investment than expense (or was when they bought the house. Who knows whether it will be in the future).
I don't have good answers for the commuting sucks and density correlates with productivity arguments, except that revealed preference seems to contradict those as being the most important things. Also, the measurements I've seen seem to include a range of circumstances that make it hard to separate the actual motivations. Living by choice in "the nice" suburbs is likely a very different experience with different desirability than living in a cheap apartment with a long commute because you can't afford to live in the city. I'd be interested to see same-age, same-family-situation, similar wealth comparisons of city and suburb dwellers.
Why (talk-)Therapy
Therapy is a curious practice. Therapy sounds like a scam, quackery, pseudo-science but it seems RCT consistently show therapy has benefits above and beyond medication & placebo.
Therapy has a long history. The Dodo verdict states that it doesn't matter which form of therapy you do - they all work equally well. It follows that priests and shamans served the functions of a therapist. In the past, one would confessed ones sins to a priest, or spoken with the local shaman.
There is also the thing that therapy ...
1
I suspect that past therapists existed in your community and knew what you're actually like so were better able to give you actual true information instead of having to digest only your bullshit and search for truth nuggets in it.
Furthermore, I suspect they didn't lose their bread when they solve your problem! We have a major incentive issue in the current arrangement!
2
There's a market for lemons problem, similar to the used car market, where neither the therapist nor customer can detect all hidden problems, pitfalls, etc., ahead of time. And once you do spend enough time to actually form a reasonable estimate there's no takebacks possible.
So all the actually quality therapists will have no availability and all the lower quality therapists will almost by definition be associated with those with availability.
Edit: Game Theory suggests that you should never engage in therapy or at least never with someone with available time, at least until someone invents the certified pre-owned market.
2
That would be prediction-based medicine. It works in theory, it's just that someone would need to put it into practice.
2
This style of argument proves too much. Why not see this dynamic with all jobs and products ever?
5
Have you ever tried hiring someone or getting a job? Mostly lemons all around (apologies for the offense, jobseekers, i'm sure you're not the lemon)
2
Yup. Many programmer applicants famously couldn't solve FizzBuzz. Which is probably because:
2
But such people are very obvious. You just give them a FizzBuzz test! This is why we have interviews, and work-trials.
2
If therapist quality would actually matter why don't we see this reflected in RCTs?
8
We see it reflected in RCTs. One aspect of therapist quality is for example therapist empathy and empathy is a predictor for treatment outcomes.
The style of therapy does not seem to be important according to RCTs but that doesn't mean that therapist skill is irrelevant.
4
Thank you practicing the rationalist virtue of scholarship Christian. I was not aware of this paper.
You will have to excuse me for practicing rationalist vice and not believing nor investigating further this paper. I have been so traumatized by the repeated failures of non-hard science, I reject most social science papers as causally confounded p-hacked noise unless it already confirms my priors or is branded correct by somebody I trust.
2
As far as this particular paper goes I just searched for one on the point in Google Scholar.
I'm not sure what you believe about Spencer Greenberg but he has two interviews with people who believe that therapist skills (where empathy is one of the academic findings) matter:
https://podcast.clearerthinking.org/episode/070/scott-miller-why-does-psychotherapy-work-when-it-works-at-all/
https://podcast.clearerthinking.org/episode/192/david-burns-cognitive-behavioral-therapy-and-beyond/
2
I internalized the Dodo verdict and concluded that the specific therapist or therapist style didn't matter anyway. A therapist is just a human mirror. The answer was inside of you all along Miles
Latent abstractions Bootlegged.
Let be random variables distributed according to a probability distribution on a sample space .
Defn. A (weak) natural latent of is a random variable such that
(i) are independent conditional on
(ii) [reconstructability] for all
[This is not really reconstructability, more like a stability property. The information is contained in many parts of the system... I might al...
Inspired by this Shalizi paper defining local causal states. The idea is so simple and elegant I'm surprised I had never seen it before.
Basically, starting with a a factored probability distribution over a dynamical DAG we can use Crutchfield causal state construction locally to construct a derived causal model factored over the dynamical DAG as where is defined by considering the past and forward lightcone of defined as all those points/ variables which influence respectively are influenced by (in a causal interventional sense) . Now take define the equivalence relatio on realization of (which includes by definition)[1] whenever the conditional probability distribution on the future light cones are equal.
These factored probability distributions over dynamical DAGs are called 'fields' by physicists. Given any field we define a derived local causal state field in the above way. Woah!
...
3
Just finished the local causal states paper, it's pretty cool! A couple of thoughts though:
I don't think the causal states factorize over the dynamical bayes net, unlike the original random variables (by assumption). Shalizi doesn't claim this either.
* This would require proving that each causal state is conditionally independent of its nondescendant causal states given its parents, which is a stronger theorem than what is proved in Theorem 5 (only conditionally independent of its ancestor causal states, not necessarily all the nondescendants)
Also I don't follow the Markov Field part - how would proving:
... show that the causal states is a markov field (aka satisfies markov independencies (local or pairwise or global) induced by an undirected graph)? I'm not even sure what undirected graph the causal states would be markov with respect to. Is it the ...
* ... skeleton of the dynamical Bayes Net? that would require proving a different theorem: "if we condition on parents and children of the patch, then we get independence of all the other states" which would prove local markov independency
* ... skeleton of the dynamical Bayes Net + edges for the original graph for each t? that would also require proving a different theorem: "if we condition on present neighbors, parents, and children of the patch, then we get independence of all the other states" which would prove local markov independency
Also for concreteness I think I need to understand its application in detecting coherent structures in cellular automata to better appreciate this construction, though the automata theory part does go a bit over my head :p
8
That condition doesn't work, but here's a few alternatives which do (you can pick any one of them):
* Λ=(x↦P[X=x|Λ]) - most conceptually confusing at first, but most powerful/useful once you're used to it; it's using the trick from Minimal Map.
* Require that Λ be a deterministic function of X, not just any latent variable.
* H(Λ)=I(X,Λ)
(The latter two are always equivalent for any two variables X,Λ and are somewhat stronger than we need here, but they're both equivalent to the first once we've already asserted the other natural latent conditions.)
The US should set in a motion a process to gradually and peacefully hand over Taiwan to China in the next ~12 years.
China cares more about Taiwan than anything else. China is stronger and will be even stronger.
China's GDP is near that of the US. China's PPP is even 50% larger. China is ahead in many industries. The US Navy is a disaster. China has made a massive military buildup. Taiwan is much closer to China. China care more about Taiwan than anybody else.
A peaceful transition handover has precedence - see the British handing over Hong Kong.&...
3
This analysis assumes that the government of Taiwan has no power, that the US is the one to negotiate with. If you are thinking of this, the question is not what deals the US would agree to, but what deal Taiwan would agree to. The US is not actually in a position to veto a reunification agreed between both governments, though they likely would not be able to backstop it either (which creates a little negotiating friction).
All of these concession are concessions to the US. What really matters for a peaceful settlement (since Taiwan can destroy the surplus) is whether the CCP can give meaningful concessions on the terms of reunification with Taiwan.
That is to say, there is no "process to gradually and peacefully hand over Taiwan to China" as an option for the US. It might exist for the government of Taiwan, but because the US does not actually control any of it's partners among middle powers.
as for "China care more about Taiwan than anybody else. "
This is false
The US might care less, but the government of Taiwan probably cares more.
3
does the will of the taiwanese people have no bearing?
4
did the will of the Melian people ?
8
yes. if we were capable of protecting them, we should have done so. not sure what other conclusion to draw.
if by your post you intended something like "it is in the US and China's mutual best interest to take the following course of action [...]" then, sure -- i strongly agree with this! but it seems prudent to phrase this as a prediction, rather than as a moral recommendation.
Does internal bargaining and geometric rationality explain ADHD & OCD?
Self- Rituals as Schelling loci for Self-control and OCD
Why do people engage in non-social Rituals 'self-rituals'? These are very common and can even become pathological (OCD).
High-self control people seem to more often have OCD-like symptoms.
One way to think about self-control is as a form of internal bargaining between internal subagents. From this perspective, Self-control, time-discounting can be seen as a resource. In the absence of self-control the superagent
D...
I feel like the whole "subagent" framework suffers from homunculus problem: we fail to explain behavior using the abstraction of coherent agent, so we move to the abstraction of multiple coherent agents, and while it can be useful, I don't think it displays actual mechanistic truth about minds.
When I plan something and then fail to execute plan it's mostly not like "failure to bargain". It's just when I plan something I usually have good consequences of plan in my imagination and this consequences make me excited and then I start plan execution and get hit by multiple unpleasant details of reality. Coherent structure emerges from multiple not-really-agentic pieces.
2
You are taking subagents too literally here. If you prefer take another word like shard, fragment, component, context-dependent action impulse generator etc
2
When I read word "bargaining" I assume that we are talking about entities that have preferences, action set, have beliefs about relations between actions and preferences and exchange information (modulo acausal interaction) with other entities of the same composition. Like, Kelly betting is good because it equals to Nash bargaining between versions of yourself from inside different outcomes and this is good because we assume that you in different outcomes are, actually, agent with all arrtibutes of agentic system. Saying "systems consist of parts, this parts interact and sometimes result is a horrific incoherent mess" is true, but doesn't convey much of useful information.
(conversation with Scott Garrabrant)
Destructive Criticism
Sometimes you can say something isn't quite right but you can't provide an alternative.
- rejecting the null hypothesis
- give a (partial) countermodel that shows that certain proof methods can't prove $A$ without proving $\neg A$.
- Looking at Scott Garrabrant's game of life board - it's not white noise but I can't say why
Difference between 'generation of ideas' and 'filtration of ideas' - i.e. babble and prune.
ScottG: Bayesian learning assumes we are in a babble-rich environment and only does pr...
Reasonable interpretations of Recursive Self Improvement are either trivial, tautological or false?
- (Trivial) AIs will do RSI by using more hardware - trivial form of RSI
- (Tautological) Humans engage in a form of (R)SI when they engage in meta-cognition. i.e. therapy is plausibly a form of metacognition. Meta-cognition is plausible one of the remaining hallmarks of true general intelligence. See Vanessa Kosoy's "Meta-Cognitive Agents".
In this view, AGIs will naturally engage in meta-cognition because they're generally intelligent. The
3
SGD finds algorithms. Before the DL revolution, science studied such algorithms. Now, the algorithms become inference without as much as a second glance. With sufficient abundance of general intelligence brought about by AGI, interpretability might get a lot out of studying the circuits SGD discovers. Once understood, the algorithms could be put to more efficient use, instead of remaining implicit in neural nets and used for thinking together with all the noise that remains from the search.
2
I think most interpretations of RSI aren't useful.
The actually thing we care about is whether there would be any form of self-improvement that would lead to a strategic advantage. The fact that something would "recursively" self-improve 12 times or 2 times don't really change what we care about.
With respect to your 3 points.
1) could happen by using more hardware, but better optimization of current hardware / better architecture is the actually scary part (which could lead to the discovery of "new physics" that could enable an escape even if the sandbox was good enough for the model before a few iterations of the RSI).
2) I don't think what you're talking about in terms of meta-cognition is relevant to the main problem. Being able to look at your own hardware or source code is though.
3) Cf. what I said at the beginning. The actual "limit" is I believe much higher than the strategic advantage threshold.
2
:insightful reaction:
I give this view ~20%: There's so much more info in some datapoints (curvature, third derivative of the function, momentum, see also Empirical Bayes-like SGD, the entire past trajectory through the space) that seems so available and exploitable!
2
What about specialized algorithms for problems (e.g. planning algorithms)?
2
What do you mean exactly? There are definitely domains in which humans have not yet come close to optimal algorithms.
1
I guess this is sorta about your 3, which I disbelieve (though algorithms for tasks other than learning are also important). Currently, Bayesian inference vs SGD is a question of how much data you have (where SGD wins except for very little data). For small to medium amounts of data, even without AGI, I expect SGD to lose eventually due to better inference algorithms. For many problems I have the intuition that it's ~always possible to improve performance with more complicated algorithms (eg sat solvers). All that together makes me expect there to be inference algorithms that scale to very large amounts of data (that aren't going to be doing full Bayesian inference but rather some complicated approximation).
2
What about automated architecture search?
2
Architectures mostly don't seem to matter, see 3.
When they do (like in Vanessa's meta-MDPs) I think it's plausible automated architecture search is a simply an instantiation of the algorithm for general intelligence (see 2.)
1
I think the AI will improve (itself) via better hardware and algorithms, and it will be a slog. The AI will frequently need to do narrow tasks where the general algorithm is very inefficient.
2
As I state in the OP I don't feel these examples are nontrivial examples of RSI.
Trivial but important
Aumann agreement can fail for purely epistemic reasons because real-world minds do not do Bayesian updating. Bayesian updating is intractable so realistic minds sample from the prior. This is how e.g. gradient descent works and also how human minds work.
In this situation a two minds can end in two different basins with similar loss on the data. Because of computational limitations. These minds can have genuinely different expectation for generalization.
(Of course this does not contradict the statement of the theorem which is correct.)
Imprecise Information theory
Would like a notion of entropy for credal sets. Diffractor suggests the following:
let be a credal set.
Then the entropy of is defined as
where denotes the usual Shannon entropy.
I don't like this since it doesn't satisfy the natural desiderata below.
Instead, I suggest the following. Let denote the (absolute) maximum entropy distribution, i.e. and let .
Desideratum 1: ...
Roko's basilisk is a thought experiment which states that an otherwise benevolent artificial superintelligence (AI) in the future would be incentivized to create a virtual reality simulation to torture anyone who knew of its potential existence but did not directly contribute to its advancement or development.
Why Roko's basilisk probably doesn't work for simulation fidelity reasons:
Roko's basilisk threatens to simulate and torture you in the future if you don't comply. Simulation cycles cost resources. Instead of following through on torturing our wo...
2
If the agents follow simple principles, it's simple to simulate those principles with high fidelity, without simulating each other in all detail. The obvious guide to the principles that enable acausal coordination is common knowledge of each other, which could be turned into a shared agent that adjudicates a bargain on their behalf.
1
I have always taken Roko's Basilisk to be the threat that the future intelligence will torture you, not a simulation, for not having devoted yourself to creating it.
1
How do you know you are not in a low fidelity simulation right now? What could you compare it against?
One aspect I didnt speak about that may be relevant here is the distinction between
irreducible uncertainty h (noise, entropy)
reducible uncertainty E ('excess entropy')
and forecasting complexity C ('stochastic complexity').
All three can independently vary in general.
Domains can be more or less noisy (more entropy h)- both inherently and because of limited observations
Some domains allow for a lot of prediction (there is a lot of reducible uncertainty E) while others allow for only limited prediction (eg political forecasting over longer time hori...
In an anthropically selected world one would expect to see some conspicuous coincidences - especially related to events and people that are highly counterfactual. Most events are not highly counterfactual. How this or that person lived and died - for the grand course of history it didn't matter.
A small group of individuals plausibly did change the course of history, at least somewhat. Unfortunately, it seems it much more likely to be counterfactually impactful by being very evil than being very good. It is easier to break things and easier murder en ...
2
How does the point about Hitler murder plots connect to the point about anthropics?
2
In a more peaceful world the science advanced faster and the AI already killed us?
All concepts can be learnt. All things worth knowing may be grasped. Eventually.
All can be understood - given enough time and effort.
For Turing-complete organism, there is no qualitive gap between knowledge and ignorance.
No qualitive gap but one. The true qualitative difference: quantity.
Often we simply miss a piece of data. The gap is too large - we jump and never reach the other side. A friendly hominid who has trodden the path before can share their journey. Once we know the road, there is no mystery. Only effort and time. Some hominids choose not to share their journey. We keep a special name for these singular hominids: genius.
4
Well, that's exactly the problem.
Abnormalised sampling?
Probability theory talks about sampling for probability distributions, i.e. normalized measures. However, non-normalized measures abound: weighted automata, infra-stuff, uniform priors on noncompact spaces, wealth in logical-inductor esque math, quantum stuff?? etc.
Most of probability theory constructions go through just for arbitrary measures, doesn't need the normalization assumption. Except, crucially, sampling.
What does it even mean to sample from a non-normalized measure? What is unnormalized abnormal sampling?
I don't know....
SLT and phase transitions
The morphogenetic SLT story says that during training the Bayesian posterior concentrates around a series of subspaces with rlcts and losses . As the size of the data sample is scaled the Bayesian posterior makes transitions trading off higher complexity (higher ) for better accuracy (lower loss ).
This is the radical new framework of SLT: phase transitions happen i...
Alignment by Simulation?
I've heard this alignment plan that is a variation of 'simulate top alignment researchers' with an LLM. Usually the poor alignment researcher in question is Paul.
This strikes me as deeply unserious and I am confused why it is having so much traction.
That AI-assisted alignment is coming (indeed, is already here!) is undeniable. But even somewhat accurately simulating a human from textdata is a crazy sci-fi ability, probably not even physically possible. It seems to ascribe nearly magical abilities to LLMs.
Predicting...
[Edit 15/05/2024: I currently think that both forward and backward chaining paradigms are missing something important. Instead, there is something like 'side-chaining' or 'wide-chaining' where you are investigating how things are related forwardly, backwardly and sideways to make use of synergystic information ]
Optimal Forward-chaining versus backward-chaining.
In general, this is going to depend on the domain. In environments for which we have many expert samples and there are many existing techniques backward-chaining is key. (i.e. deploying r...
Thin versus Thick Thinking
Thick: aggregate many noisy sources to make a sequential series of actions in mildly related environments, model-free RL
carnal sins: failure of prioritization / not throwing away enough information , nerdsnipes, insufficient aggegration, trusting too much in any particular model, indecisiveness, overfitting on noise, ignoring consensus of experts/ social reality
default of the ancestral environment
CEOs, general, doctors, economist, police detective in the real world, trader
Thin: precise, systematic analysis, preferably ...
[Thanks to Vlad Firoiu for helping me]
An Attempted Derivation of the Lindy Effect
Wikipedia:
The Lindy effect (also known as Lindy's Law[1]) is a theorized phenomenon by which the future life expectancy of some non-perishable things, like a technology or an idea, is proportional to their current age.
Laplace Rule of Succesion
What is the probability that the Sun will rise tomorrow, given that is has risen every day for 5000 years?
Let denote the probability that the Sun will rise tomorrow. A priori we have no information on the value of&...
2
I haven't checked the derivation in detail, but the final result is correct. If you have a random family of geometric distributions, and the density around zero of the decay rates doesn't go to zero, then the expected lifetime is infinite. All of the quantiles (e.g. median or 99%-ile) are still finite though, and do depend upon n in a reasonable way.
Generalized Jeffrey Prior for singular models?
For singular models the Jeffrey Prior is not well-behaved for the simple fact that it will be zero at minima of the loss function.
Does this mean the Jeffrey prior is only of interest in regular models? I beg to differ.
Usually the Jeffrey prior is derived as parameterization invariant prior. There is another way of thinking about the Jeffrey prior as arising from an 'indistinguishability prior'.
The argument is delightfully simple: given two weights if they encode the same distributi...
1
You might reconstruct your sacred Jeffries prior with a more refined notion of model identity, which incorporates derivatives (jets on the geometric/statistical side and more of the algorithm behind the model on the logical side).
2
Is this the jet prior I've been hearing about?
I argued above that given two weights w1,w2 such that they have (approximately) the same conditional distribution p(x|y,w1)∼=p(x|y,w2) the 'natural' or 'canonical' prior should assign them equal prior weights ϕ(w1)=ϕ(w2). A more sophisticated version of this idea is used to argue for the Jeffrey prior as a canonical prior.
Some further thoughts:
* imposing this uniformity condition would actually contradict some version of Occam's razor. Indeed, w1 could be algorithmically much more complex (i.e. have much higher description length) than w2 but they still might have similar or the same predictions.
* The difference between same-on-the-nose versus similar might be very material. Two conditional probability distributions might be quite similar [a related issue here is that the KL-divergence is assymetric so similarity is a somewhat ill-defined concept], yet one intrinsically requires far more computational resources.
* A very simple example is the uniform distribution puniform(x)=1N and another distribution p′(x) that is a small perturbation of the uniform distribution but whose exact probabilities p′(x) have decimal expansions that have very large description length (this can be produced by adding long random strings to the binary expansion).
* [caution: CompMech propaganda incoming] More realistic examples do occur i.e. in finding optimal predictors of dynamical systems at the edge of chaos. See the section on 'intrinsic computation of the period-doubling cascade', p.27-28 of calculi of emergence for a classical example.
* Asking for the prior ϕ to restrict to be uniform for weights wi that have equal/similar conditional distributions p(x|y,wi) seems very natural but it doesn't specify how the prior should relate weights with different conditional distributions. Let's say we have two weights w1, w2 with very different conditional probability distributions. Let Wi={w∈W|p(x|y,w)∼=p(x|y,wi)}. How sh
5
I think there's no such thing as parameters, just processes that produce better and better approximations to parameters, and the only "real" measures of complexity have to do with the invariants that determine the costs of those processes, which in statistical learning theory are primarily geometric (somewhat tautologically, since the process of approximation is essentially a process of probing the geometry of the governing potential near the parameter).
From that point of view trying to conflate parameters w1,w2 such that p(x|w1)≈p(x|w2) is naive, because w1,w2 aren't real, only processes that produce better approximations to them are real, and so the ∂∂w derivatives of p(x|w1),p(x|w2) which control such processes are deeply important, and those could be quite different despite p(x|w1)≈p(x|w2) being quite similar.
So I view "local geometry matters" and "the real thing are processes approximating parameters, not parameters" as basically synonymous.
"The links between logic and games go back a long way. If one thinks of a debate as a kind of game, then Aristotle already made the connection; his writings about syllogism are closely intertwined with his study of the aims and rules of debating. Aristotle’s viewpoint survived into the common medieval name for logic: dialectics. In the mid twentieth century Charles Hamblin revived the link between dialogue and the rules of sound reasoning, soon after Paul Lorenzen had connected dialogue to constructive foundations of logic." from the Stanford Encyclopedia ...
Ambiguous Counterfactuals
[Thanks to Matthias Georg Mayer for pointing me towards ambiguous counterfactuals]
Salary is a function of eXperience and Education
We have a candidate with given salary, experience and education .
Their current salary is given by
We 'd like to consider the counterfactual where they didn't have the education . How do we evaluate their salary in this counterfactual?
This is slightly ambiguous - there are two counterfactuals:
or
In the second c...
Insights as Islands of Abductive Percolation?
I've been fascinated by this beautiful paper by Viteri & DeDeo.
What is a mathematical insight? We feel intuitively that proving a difficult theorem requires discovering one or more key insights. Before we get into what the Dedeo-Viteri paper has to say about (mathematical) insights let me recall some basic observations on the nature of insights:
(see also my previous shortform)
- There might be a unique decomposition, akin to prime factorization. Alternatively, there might many roads to Rome: some theorems
The pseudorandom lie under the Lava lamp
Our observations are compatible with a world that is generated by a Turing machine with just a couple thousand bits.
That means that all the seemingly random bits we see in Geiger counters, Lava lamps, gasses and the like is only pseudorandomness in actuality.
6
IDK why you think that TM is simpler than one that computes, say, QM. But either way, I don't know why to favor (in terms of ascribing reality-juice) worlds that are simple TMs but not worlds that are simple physics equations. You can complain that you don't know how to execute physics equations, but I can also complain that I don't know how to execute state transitions. (Presumably there's still something central and real about some things being more executable than others; I'm just saying it's not clear what that is and how it relates to reality-juice and TMs vs physics.)
4
I'm confused, in what sense don't we know how to do this? Lattice quantum field theory simulations work fine.
2
For example, we couldn't execute continuum models.
2
Of course, just because we can't execute continuum models, or models of physics that require actually infinite computation, not just unlimited amounts of compute, doesn't mean the universe can't execute such a program.
2
Ok, another example is that physical laws are generally descriptive, not fully specified worlds. You can "simulate" the ideal gas law or Maxwell's equations but you're doing extra work beyond just what the equations say (like, you have to run "import diffeq" first, and pick a space topology, and pick EM fields) and it's not a full world.
2
Yes, which is why I explicitly said that the scenario involves actual/manifest infinity of compute to actually implement the equations to actually make it a full world, and if you wanted to analogize physical laws to a computer system, I'd argue that they are analogous to the source code of a computer, or the rules/state of a Turing Machine, and I'm arguing that there is a very vast difference between us simulating Maxwell's equations or the ideal gas law and the universe simulating whatever physical laws we turn out to actually have, and all of the difference is the universe has an actual infinity/manifest infinity of compute like FLOPs/FLOP/s and memory such that you can actually run the equations directly without relying on shortcuts to make the problem more tractable, whereas we have to rely on shortcuts that change the physics a little but get us a reasonable answer in a reasonable time.
2
Oh I misparsed your comment somehow, I don't even remember how.
2
This distinction isnt material. The distinction I am getting at is whether our physics (simulation) is using a large K-incompressible seed or not.
4
QM doesn't need a random seed!
5
The randomness of the Geiger counter comes from wave function decoherence. From the perspective of any observers who are part of the world generated by the Turing machine, this is irreducible indexical uncertainty.
I don't know how many of the random bits in Lava lamps come from decoherence.
2
I'm fairly sure it isn't actually compatible with a world that is generated by a Turing Machine, but the basic problem is all the real number constants in the universe which in QM are infinitely precise, not just arbitrarily precise, which wreaks havoc on Turing Machine models, but Signer has another explanation of another problem that is fatal to the approach.
2
Connotationally, even if things are pseudorandom, they still might be "random" for all practical purposes, e.g. if the only way to calculate them is to simulate the entire universe. In other words, we may be unable to exploit the pseudorandomness.
2
Yes, this is exactly the point.
2
* Probability is in the mind. There's no way to achieve entanglement between what's necessary to make these predictions and the state of your brain, so for you, some of these are random.
* In multi-worlds, the Turing machine will compute many copies of you, and there might be more of those who see one thing when they open their eyes than of those who see another thing. When you open your eyes, there's some probability of being a copy that sees one thing and a copy that sees the other thing. In a deterministic world with many copies of you, there's "true" randomness in where you end up opening your eyes.
6
I think he's saying that there's a simple-ish deterministic machine that uses pseudorandomness to make a world observationally equivalent to ours. Since it's simple, it has a lot of the reality-juice, so it's most of "where we really are".
1
Yes, but this is kinda incompatible with QM without mangled worlds.
2
Oh ? What do you mean !
I don't know about mangled worlds
1
https://mason.gmu.edu/~rhanson/mangledworlds.html
I mean that if turing machine is computing universe according to the laws of quantum mechanics, observers in such universe would be distributed uniformly, not by Born probability. So you either need some modification to current physics, such as mangled worlds, or you can postulate that Born probabilities are truly random.
2
I assume you mean the laws of QM except the collapse postulate.
Not at all. The problem is that their observations would mostly not be in a classical basis.
Born probability relates to observations, not observers.
Or collapse. Mangled worlds is kind of a nothing burger--its a variation on the idea than interference between superposed states leads to both a classical basi and the Born probabilities, which is an old idea, but wihtout making it any more quantiative.
??
1
I phrased it badly, but what I mean is that there is a simulation of Hilbert space, where some regions contain patterns that can be interpreted as observers observing something, and if you count them by similarity, you won't get counts consistent with Born measure of these patterns. I don't think basis matters in this model, if you change basis for observer, observations and similarity threshold simultaneously? Change of basis would just rotate or scale patterns, without changing how many distinct observers you can interpret them as, right?
Collapse or reality fluid. The point of mangled worlds or some other modification is to evade postulating probabilities on the level of physics.
Evidence Manipulation and Legal Admissible Evidence
[This was inspired by Kokotaljo's shortform on comparing strong with weak evidence]
In the real world the weight of many pieces of weak evidence is not always comparable to a single piece of strong evidence. The important variable here is not strong versus weak per se but the source of the evidence. Some sources of evidence are easier to manipulate in various ways. Evidence manipulation, either consciously or emergently, is common and a large obstactle to truth-finding.
Consider aggregating many ...
2
In other cases like medicine, many people argue that direct observation should be ignored ;)
Imagine a data stream
assumed infinite in both directions for simplicity. Here represents the current state ( the "present") and while and represents the future
Predictible Information versus Predictive Information
Predictible information is the maximal information (in bits) that you can derive about the future given the access to the past. Predictive information is the amount of bits that you need from the past to make that optimal prediction.
Suppose you are...
Hopfield Networks = Ising Models = Distributions over Causal models?
Given a joint probability distributions famously there might be many 'Markov' factorizations. Each corresponds with a different causal model.
Instead of choosing a particular one we might have a distribution of beliefs over these different causal models. This feels basically like a Hopfield Network/ Ising Model.
You have a distribution over nodes and an 'interaction' distribution over edges.
The distribution over nodes corresponds to the joint probability di...
Did the Classical Greeks have any conception of when the Iliad happened?
According to Claude the Classical Greeks not only believed in the historicity of the Iliad - they also had surprisingly accurate dating!
...The ancient Greeks generally did believe the Iliad described real historical events, though their understanding of it was more nuanced than simply accepting every detail as literal fact.
Belief in Historical Reality
Most classical Greeks, including prominent historians and philosophers, treated the Trojan War as a genuine historical event. Herodotu
5
How did you check Claude's claims here?
2
I spotcheked the first claim about eratosthenes.
The second part on eratothenes is directly from wikipedia.