Every time I have an application form for some event, the pattern is always the same. Steady trickle of applications, and then a doubling on the last day.
And for some reason it still surprises me how accurate this model is. The trickle can be a bit uneven, but the doubling the last day is usually close to spot on.
This means that by the time I have a good estimate of what the average number of applications per day is, then I can predict what the final number will be. This is very useful, for knowing if I need to advertise more or not.
For the upcoming AISC, the trickle was a late skewed, which meant that an early estimate had me at around 200 applicants, but the final number of on-time application is 356. I think this is because we where a bit slow at advertising early on, but Remmelt made a good job sending out reminders towards the end.
Application deadline was Nov 17. At midnight GMT before Nov 17 we had 172 application. At noon GMT Nov 18 (end of Nov 17 anywhere-on-Earth) we had 356 application
The doubling rule predicted 344, which is only 3% off
Yes, I count the last 36 hours as "the last day". This is not cheating since that's what I always done (approximately&nbs... (read more)
Side note:
If you don't tell what time the application deadline is, lots of people will assume its anywhere-on-Earth, i.e. noon the next day in GMT.
When I was new to organising I did not think of this, and kind of forgot about time zones. I noticed that I got a steady stream of "late" applications, that suddenly ended at 1pm (I was in GMT+1), and didn't know why.
6J Bostock
It might be the case that AISC was extra late-skewed because the MATS rejection letters went out on the 14th (guess how I know) so I think a lot of people got those and then rushed to finish their AISC applications (guess why I think this) before the 17th. This would predict that the ratio of technical:less-technical applications would increase in the final few days.
2Linda Linsefors
Sounds plausible.
> This would predict that the ratio of technical:less-technical applications would increase in the final few days.
If you want to operationalise this in terms on project first choice, I can check.
5J Bostock
Ok: I'll operationalize the ratio of first choices the first group (Stop/PauseAI) to projects in the third and fourth groups (mech interp, agent foundations) for the periods 12th-13th vs 15th-16th. I'll discount the final day since the final-day-spike is probably confounding.
4Linda Linsefors
12th-13th
* 18 total applications
* 2 (11%) Stop/Pause AI
* 7 (39%) Mech-Interp and Agent Foundations
15th-16th
* 45 total application
* 4 (9%) Stop/Pause AI
* 20 (44%) Mech-Interp and Agent Foundations
All applications
* 370 total
* 33 (12%) Stop/Pause AI
* 123 (46%) Mech-Interp and Agent Foundations
Looking at the above data, is directionally correct for you hypothesis, but it doesn't look statisically significant to me. The numbers are pretty small, so could be a fluke.
So I decided to add some more data
10th-11th
* 20 total applications
* 4 (20%) Stop/Pause AI
* 8 (40%) Mech-Interp and Agent Foundations
Looking at all of it, it looks like Stop/Pause AI are coming in at a stable rate, while Mech-Interp and Agent Foundations are going up a lot after the 14th.
2Linda Linsefors
Same data but in cronlogical order
10th-11th
* 20 total applications
* 4 (20%) Stop/Pause AI
* 8 (40%) Mech-Interp and Agent Foundations
12th-13th
* 18 total applications
* 2 (11%) Stop/Pause AI
* 7 (39%) Mech-Interp and Agent Foundations
15th-16th
* 45 total application
* 4 (9%) Stop/Pause AI
* 20 (44%) Mech-Interp and Agent Foundations
Stop/Puase AI stays at 2-4 per week, while the others go from 7-8 to 20
One may point out that 2 to 4 is a doubling suggesting noisy data, and also going from 7-8 is also just a doubling and might not mean much. This could be the case. But we should expect higher notice for lower numbers. I.e. a doubling of 2 is less surprising than a (more than) doubling of 7-8.
4Mateusz Bagiński
Linda Linsefors's Rule of Succession
4Avery
Noting that I had a conversation with Linda a week prior to the application deadline where they shared this trivia / prediction with me. Interesting!
projection of "▁queen" on span( "▁king", "▁man", "▁woman") is ['▁king', '▁King', '▁woman', '▁queen', '▁rey', '▁Queen', 'peror', '▁prince', '▁roi', '▁König']
"▁queen" is the closest match only if you exclude any version of king and woman. But this seems to be only because "▁queen" is already the 2:nd closes match for "▁king". Involving "▁man" and "▁woman" is only making t... (read more)
I have two hypothesises for what is going on. I'm leaning towards 1, but very unsure.
1)
king - man + woman = queen
is true for word2vec embeddings but not in LLaMa2 7B embeddings because word2vec has much fewer embedding dimensions.
* LLaMa2 7B has 4096 embedding dimensions.
* This paper uses a variety of word2vec with 50, 150 and 300 embedding dimensions.
Possibly when you have thousands of embedding dimensions, these dimensions will encode lots of different connotations of these words. These connotations will probably not line up with the simple relation [king - man + woman = queen], and therefore we get [king - man + woman ≠ queen] for high dimensional embeddings.
2)
king - man + woman = queen
Isn't true for word2vec either. If you do it with word2vec embeddings you get more or less the same result I did with LLaMa2 7B.
(As I'm writing this, I'm realising that just getting my hands on some word2vec embeddings and testing this for myself, seems much easier than to decode what the papers I found is actually saying.)
People used to say (maybe still do? I'm not sure) that we should use less jargon to increase accessibility to writings on LW, i.e. make it easier to outsider to read.
I think this is mostly a confused take. The underlying problem is inferential distance. Geting rid of the jargon is actually unhelpful since it hides the fact that there is an inferential distance.
When I want to explain physics to someone and I don't know what they already know, I start by listing relevant physics jargon and ask them what words they know. This is a super quick way to find out what concepts they already have, and let me know what level I should start on. This work great in Swedish since in Swedish most physics words are distinct from ordinary words, but unfortunately don't work as well in English, which means I have to probe a bit deeper than just checking if they recognise the words.
Jargon isn't typically just synonyms to some common word, and when it is, I predict that it didn't start out that way, but that the real meaning was destroyed by too many people not bothering to learn the word properly. This is because people invent new words (jargon) when they need a new wor... (read more)
Jargon usually serves one of two purposes, either to synthesise a concept that would otherwise require a long-winded turn of phrase and recurs too often to dedicate that much time to it, or to signal that you belong to a certain group that knows the jargon. I think it's fair to say that the latter should be resisted; it very well brings anything much good, just gate keeping and insularity, with all the resulting outcomes. Or sometimes impacts outside perception for no good reason.
A classic example of a LW-ism falling in that category IMO is "I updated". Yes, it hints that you're a Bayesian and think of your own cognitive process in Bayesian terms, but who isn't around these parts? Other than that, it's not particularly shorter nor particularly more meaningful than "I changed my mind" or "you convinced me". I think it's fair to say we could probably just do without it in most contexts that aren't actual talk about actual Bayes' theorem maths and it would make anything we write more legible at zero cost.
I agree with Linda’s reply that “I updated” is somewhat different from “I was convinced” because the former is often used as “I updated somewhat but not completely” with an implicit Bayesian context. “I updated” can be replaced with a whole phrase or sentence, of course, but that’s true for all jargon.
“Sequence” — people have been talking about “essay series”, “book series”, “blog post series” etc. since time immemorial, and then someone (probably Eliezer?) switched from “series” to “sequence” for some reason (joke-y reference to math jargon?), and I think it stuck for in-group signaling reasons
“Upskilling”—I don’t see what it adds over the more-common “learning” or “getting good at” etc.
“Distillation”—it’s not even the right mental image, and I don’t think adds anything over the widespread terms like “pedagogy”, “explainers”, “intro to”, etc.
I’m sure there are others, but alas, I’ve been around long enough that they don’t jump out at me anymore.
TBF I see "sequence" as more of a brand thing. "The sequences" are a specific work of literature at this point. But I suppose it is not necessary to call more series of posts here that way too.
2Steven Byrnes
Yeah I was referring to e.g. my own … things that I call “series” and everyone else calls “sequences”.
To be clear, “brand thing” is fine! It’s one of those emotive conjugation things: “I have playful branding and in-jokes, you have pointless jargon for in-group signaling”.
Lesswrong people using “sequence” is not really any different from twitter people using “tweet” and “thread”, or facebook people using “vaguebooking”, etc. You’re trading off a learning curve for newcomers for … playful fun and community! And playful fun and community are worth more than zero. So yeah, I personally opt out of “sequence” and many other unnecessary lesswrong-isms / SF-Bay-area-isms, but I don’t particularly hold it against other people for choosing differently.
4Linda Linsefors
I agree that those a better examples, and probably just synonyms.
With the nitpick that it's not obvious to me how to say "distilling" in one word, in some other way. Although I agree with you that dthe word "distillation" is a bad fit for how we use it.
I've updated to think that a diffrent common way jargon happens is that someone temporarley fogett the standard term and grab some other word that is natrual for them and their audience, e.g. sequence instead of series. And sometimes this never gets "corrected", and instead end up being the new normal in that sub-culture.
7Linda Linsefors
I think that "it hints that you're a Bayesian and think of your own cognitive process in Bayesian terms" is worth the cost in this case.
You say "but who isn't around these parts?". We'll outsiders/newcomers might not, so in this case the implication (when used correctly) have important information. So exactly in the cases where there is a cost, there is also important value.
When talking to LW natives, it's usually safety to assume a Bayesian mindset, so the information value is approximately zero. But the cost is also approximately zero, since we're all super familiar with this phrase.
Additionally I do think, that "you changed my mind" indicate a stronger update than the typical "I updated", and "you convinced me" is even stronger. Caveat that this can be context dependent as is always the case with natural language.
E.g. if someone shows me a math proof that contradict my initial intuition about a math fact, I'd say "you convinced me", rather than "I updated". Here this means that I now think of the proven statement as true. Sure there are some non-zero probability that the proof is wrong. But I also have limited cognition, so sometimes it's reasonable to just treat a statement as 100% true on the object level (while still being open to be convinced this was a mistake), even though this is not how an ideal Bayesian would operate.
4Linda Linsefors
I do think that [purely signal that you belong to a certain group] type jargon does exist but that's it is much rarer than you think. Because I think you mistake information carrying jargon for non-information carrying jargon.
2dr_s
Fair. I made the example but if you don't mean you updated "all the way" (whcih you're right ia the more common case) then the correct translation in general speech would be more like "I'll keep that in mind, though I'm not persuaded just yet", which starts being a mouthful. I still feel like I tend to avoid the phrase and I'm doing fine, but I can see the practicality.
2Linda Linsefors
I think it's interesting that the phrase "I updated" was also used as a an example of a supposedly non-useful jargon, last time I mentioned my jargon opinions.
1Ariel_
In my experience, people saying they "updated" did not literally change a percentage or propagate a specific fact through their model. Maybe it's unrealistic to expect it to be so granular, but to me it devalues the phrase and so I try to avoid it unless I can point to a somewhat specific change in my model. Whereas usually my model (e.g. of a subset of AI risks) is not really detailed enough to actually perform a Bayesian update, but more to just generally change my mind or learn something new and maybe gradually/subconsciously rethink my position.
Maybe I have too high bar for what counts as a bayesian updates - not sure? But if not, then I think "I updated" would count more often as social signaling or as appropriation of a technical term to a non-technical usage. Which is fine, but seems less than ideal for LW/AI Safety people.
So I would say that jargon has this problem (of being used too casually/technically imprecise) sometimes, even if I agree with your inferential distance point.
As far as LW jargon being interchangeable with existing language - one case I can think of is "murphyjitsu", which is basically exactly a "premortem" (existing term) - so maybe there's a bit of over-eagerness to invent a new term instead of looking for an existing one.
2Linda Linsefors
I use my the prhase "I've updated" even when not having a number in my head. When I do say it, it's motly a signal to myself to notice my feeling of how strongly I belive something and deliberatly push that feeling a bit to one side or another, especially when the evindence is week and should not change my mind very much.
I belive the human brain is acctually pretty good at aproximating basian updating, if one pays attention to facts in the right way. Part of this practice, for me, is to sometimes state out lound that I've encountered evidence that should influence my belifs, especially in cases where I'm in risk of confirmation bias.
2Linda Linsefors
My guess is that the people inveting the term "murphyjitsu" did not know of the term "premortem". If anyone want to check this, look in the CFAR handbook and see if there are any citations in that section. CFAR was decent at citing when they took ideas from other places.
Independent invesion is another way to get synonyms. I concidered including this in the original comment, but didn't seem central enough for my main point.
But diffrent academic fields having diffrent jargon for the same thing because of independent invention of ideas, is a common thing.
Related rant: Another indpendent invetion (invented many times) is the multi agent mind method for therapy (and similar). It seems like various people have converged on calling all of it Interla Famaly System, which I dislike, because IFS is much more specific than that.
3Morpheus
I think when you wrote postmortem you meant to write premortem?
2Linda Linsefors
Yes, thanks. I've fixdd it now.
2Linda Linsefors
(reacted to my own post to test something about reactions, and now I don't knwo how to remove it)
2Kaj_Sotala
CFAR handbook, p. 43 ("further resources" section of the "inner simulator" chapter, which the "murphyjitsu" unit is a part of):
2Linda Linsefors
Hm, this does not rule out independent discovery, but is evidence against it.
I notice that I'm confused why they would re-name it if it isn't independent discovery.
1Karl Krueger
"Murphyjitsu" is equivalent to "premortem" rather than "postmortem"; and the word "premortem" is much less common. I worked in a field where everyone does postmortems all the time (Site Reliability Engineering); only a few people even talked about premortems and even fewer did them.
The first I heard of the multi-agent model of the mind was Minsky's The Society of Mind (1986) which was based on work going back to the '70s. My impression is that IFS was being developed around the same time but I don't know the timeline there.
1Ariel_
Yeah, I agree premotrem is not super commonly used. Not sure where I learned it, maybe an org design course. I mainly gave that as an example of over-eagerness to name existing things - perhaps there aren't that many examples which are as clear cut, maybe in many of them the new term is actually subtly different from the existing term.
But I would guess that a quick Google search could have found the "premortem" term, and reduced one piece of jargon.
2Linda Linsefors
Now days you can descripe the concept you want and have a LLM tell you the common term, but this tech is super new. Most of our jargon in from a time when you could only Google things you already know the name for.
2Gunnar_Zarncke
And this is what the auto-generated glossary should be super useful for.
1[anonymous]
Would a post containing a selection of terms and an explanation of what useful concepts they point to (with links to parts of the sequences and other posts/works) be useful?
3Linda Linsefors
I was pretty sure this exist, maybe even built into LW. It seems like an obvious thing, and there are lots of parts of LW that for some reason is hard to find from the fron page. Googleing "lesswrong dictionary" yealded
https://www.lesswrong.com/w/lesswrong-jargon
https://www.lesswrong.com/w/r-a-z-glossary
https://www.lesswrong.com/posts/fbv9FWss6ScDMJiAx/appendix-jargon-dictionary
4Linda Linsefors
Although non of them seem to have "distillation", or "reserach debt" so there seems to be room for imporvement.
"distilation" do have an explanation in this tag though
https://www.lesswrong.com/w/distillation-and-pedagogy
I think the Wiki Tags are ment to be used as both tags and dictionary, however these two purpuses don't cleanly line up.
1Karl Krueger
One problem of jargon proliferation is that two communities may invent different jargon for the same underlying concept. If someone's in both communities, they can notice, "Hey, when you say fribbling the leap-dog, I think you mean the same thing that those other folks have been calling optimizing for the toenail case since 2005. We don't need a new expression; we can just steal theirs."
(And one problem of that, is that there may be a subtle difference between the two concepts...)
3Linda Linsefors
I agree that is a problem of jargon, but how would you fix it? If you tell peopel to not come up with new words for their new cocepts... does not work, they will do that anyway. But if some how stop people from crating shorthands for things they talk about a lot, that seems much worse, than the problem you tried to solve.
Although I don't disagree with you, this is not a crux for me at all.
1Karl Krueger
Well, what I do is try to point out when two communities I'm aware of are coming up with different words for the same thing. Especially when someone is saying "There's no word for this phenomenon yet, so I'm coining the word X for it," but in fact there is a word for it in a nearby community.
There's not a Big Problem here; it's just ordinary language change. It's perfectly normal for language communities to invent new words and usages; and if two communities are isolated from one another, there's no magic process that will cause them to converge on one word or usage over another. Convergence can only happen when people actually talk to each other and explain what their words mean.
4Linda Linsefors
I think it's great that you point this out when you see it!
3Steven Byrnes
I’ve seen that in physics vs chemistry vs engineering (I even made a translation guide for some niche topic way back when) but can’t immediately think of good examples related to rationalism or AI alignment.
2Karl Krueger
A couple of terms that I've commented on here recently —
* "Delmore effect" (of unclear origin) is the same as the "bikeshed effect" (from open-source software, circa 1999) which was itself a renaming of Parkinson's "law of triviality" (1957) — meaning that people spend more effort forming (and fighting over) opinions on the less-important parts of a project because they're easier to understand or lower-stakes.
* "Stereotype of the stereotype" (newly coined here on LW last month) is the same as "dead unicorn trope" (from TVTropes) — meaning an idea that people say is an old-fashioned worn-out cliché (a "dead horse" or "stereotype") but was never actually popular in the first place.
There's also "Goodhart's Law" and "Campbell's Law", both pointing at the same underlying phenomenon of the distortion of measurement under optimization pressure. Goodhart was writing about British monetary policy, while Campbell was writing about American education policy and "teaching to the test".
I think "Goodhart" took off around these parts mostly because of the pun. (The policy designers were good-hearted, but the policy ended up Goodharted.)
LLMs (and probably most NNs) have lots of meaningfull, interpretable linear feature directions. These can be found though various unsupervised methods (e.g. SAEs) and supervised methods (e.g. linear probs).
However, most human interpretable features, are not what I would call the models true features.
If you find the true features, the network should look sparse and modular, up to noise factors. If you find the true network decomposition, than removing the what's left over should imporve performance, not make it wors.
Because the network has a limited number of orthogonal directions, there will be interference terms that the network would like to remove, but can't. A real network decomposition will be everything except this noise.
This is what I think mech-interp should be looking for
It's possible that I'm wrong and there is no such thing as "the networks true features". But we've (humans colectivly) only just started this reaserch agenda. The fact that we haven't found it yet, is not much evidence either way.
this is basically what the circuit sparsity agenda is aiming for.
2Linda Linsefors
This paper is on my to-read list :)
6faul_sname
Reality has a surprising amount of detail[1]. If the training objective is improved by better modeling the world, and the model is does not have enough parameters to capture all of the things about the world which would help reduce loss, the model will learn lots of the incidental complexities of the world. As a concrete example, I can ask something like
and the current frontier models know enough about the world that they can, without tools or even any substantial chain of thought, correctly answer that trick question[2]. To be able to answer questions like this from memory, models have to know lots of geographical details about the world.
Unless your technique for extracting a sparse modular world model produces a resulting world model which is larger than the model it came from, I think removing the things which are noise according to your sparse modular model will almost certainly hurt performance on factual recall tasks like this one.
1. ^
See the essay by that name for some concrete examples.
2. ^
The trick is that there is second city named Rome in the United States, in the state of Georgia. Both Romes contain a confluence of two rivers, both contain river walks, both contain Mariotts, both contain stadiums, but only the Rome in the US contains a stadium at the confluence of two rivers next to a Mariott named for its proximity to the river.
2Linda Linsefors
I do exect some amount of superpossition, i.e. the model is using almost orthogonal directions to encode more concept than it has neurons. Depending on what you mean by "larger" this will result in a world model that is larger than the network. However such an encoding will also result in noise. Superpossition will nessesarely lead to unwanted small amplitude connections between uncorelated concepts. Removing these should imporve performance, and if it dosn't it means that you did the decomposition wrong.
2Adam Shai
Why do you think finding the true features should make the network look sparse and modular?
2RogerDearnaley
You might want to look at "Jacobian Sparse Autoencoders: Sparsify Computations, Not Just Activations" — they're trying to optimize for what you describe, and apparently had some success. Crosscoders are another attempt.
“someone complimented me out of the blue, and it was a really good compliment, and it was terrible, because maybe I secretly fished for it in some way I can’t entirely figure out, and also now I feel like I owe them one, and I never asked for this, and I’m so angry!”
A blogpost I remember but can't find. The author talks about the benefits of favour economy. E.g. his friend could help him move at much lower total cost, than the market price for moving. This is because the market has much higher transaction cots than favours among friends. The blogpost also talks about how you only get to participate in the favour economy (and get it's benefits) if you understand that you're expected to return the favours, i.e. keep track of the social ledger, and make sure to pay your depts. Actually you should be overpaying when returning a favour, and now they owe you, and then they over pay you back, resulting in a virtual cycle of helping each other out. The author mentions being in a mutually beneficial "who can do the biggest favour" competition with his neighbour.&... (read more)
I always reply “That’s very kind of you to say.” Especially for compliments that I disagree with but don’t want to get into an argument about. I think it expresses nice positive vibes without actually endorsing the compliment as true.
A good mission-aligned team might be another example? In sports, if I pass you the ball and you score a goal, that’s not a “favor” because we both wanted the goal to be scored. (Ideally.) Or if we’re both at a company, and we’re both passionate about the mission, and your computer breaks and I fix it, that’s not necessarily “a favor” because I want your computer to work because it’s good for the project and I care about that. (Ideally.) Maybe you’re seeing some EAs feel that kind of attitude?
7Linda Linsefors
I agree that the reason EAs are usually not tracking favours is that we are (or assume we are) mission aligned. I picked the pay-it-forward framing, because it fitted better with other situation where I expected people not to try to balance social legers. But you're right that there are situations that are mission aligned that are not well described as paying it forward, but some other shared goal.
Another situation where there is no social ledger, is when someone is doing their job. (You talk about a company where people are passionate about the mission. But most employs are not passionate about the mission, and still don't end up owing each other favours for doing their job.)
I personally think that the main benefit of mental health professionals (e.g. psychologies, coaches, etc) is that you get to have a one sided relationship, where you get to talk about all your problem, and you don't owe them anything in return, because you're paying them instead. (Or sometimes the healthcare system, is paying, or your employer. The important thing is that they get paid, and helping you is their job.)
(I much rather talk to a friend about my problems, it just works better, since they know me. But when I do this I owe them. I need to track what cost I'm imposing them, and make sure it's not more than I have the time and opportunity to re-pay.)
Related: Citation form Sady Porn from Scott Alexanders's review
(I'm pretty sure the way to read Sady Porn (or Scott's review of it) is not to treat any of the text as evidence for anything, but as suggestions of things that may be interesting to pay attention to.)
2Nathan Helm-Burger
It's slightly off-topic... but I think it's worth mentioning that I think the reason 'extra credit' is more exciting to tackle is that it is all potential upside with no potential downside. Regular assignments and tests offer you a reward if you do them well, but a punishment if you make mistakes on them. Extra credit is an exception to this, where there is explicitly no punishment threatened, so you can just relax and make a comfortable effort without worrying that you are trying insufficiently hard. This makes it more like play and peaceful exploration, and less like a stressful trial.
Indeed, my opinion is that education should have much less in the way of graded homework and tests. Tests should be for special occasions, like the very end of a course, and intended to truly measure the student's understanding. Classwork (e.g. problem sets or working through a series on Khan academy or Brilliant) should award points for effort, just like lectures award participation credit for attending. Homework should be banned (below university level). If the school can't educate you within the allotted time, it is failing its job.
1mattmacdermott
Instead of tracking who is in debt to who, I think you should just track the extent to which you’re in a favouring-exchanging relationship with a given person. Less to remember and runs natively on your brain.
Thoughts on how to onboard volunteers/collaborators
Volunteers are super flaky, i.e. often abandon projects with no warning. I think the main reason for this is planning fallacy. People promise more than they actually have time for. Best case they will just be honest about this when they notice. But more typically the person will feel some mix of stress, shame and overwhelm that prevents them from communicating clearly. From the outside this looks like person promised to do a lot of things and then just ghosts the project. (This is a common pattern and not a specific accusation of any specific person.)
I don't think I'm particularly good at volunteer management. But I have a few methods that I find very useful to avoid having the volunteers be net negative from my perspective. Which one depends on what fits the project. When ever I don't do at least one of these precaution, I always end up regretting it, except if the person is someone I know well from before, and already have specific reasons to trust.
Give the volunteer a task which isn't essential, so that if they drop out, that is ok. E.g. if I run an event and someone want's to help then I would still make plans as if I did not h
I've recently crossed into being considered senior enough as an organiser, such that people are asking me for advise on how to run their events. I'm enjoying giving out advise, and it also makes me reflet on event design in new ways.
I think there are two types of good events.
Purpose driven event design.
Unconference type events
I think there is a continuum between these two types, but also think that if you plot the best events along this continuum, you'll find a bimodal distribution.
Purpose driven event design
When you organise one of these, you plan a journey for your participant. Everything is woven into a specific goal that is active by the end of the event. Everything fits together.
These can defiantly have a purpose (e.g. exchanging of ideas) but the purpose will be less precise than for the previous type, and more importantly, the purpose does not strongly drive the event design.
There will be designed elements around the edges, e.g. the opening and ending. But most of the event design just goes into supporting the unconference structure, which is not very purpose specific. For ... (read more)
I feel a bit behind on everything going on in alignment, so for the next weeks (or more) I'll focus on catching up on what ever I find interesting. I'll be using my short form, to record my though.
I make no promises that reading this is worth anyone's time.
Linda's alignment reading adventures part 1
What to focus on?
I do have some opinions on what aliment directions are more or less promising. I'll probably venture in other directions too, but my main focus is going to be around what I expect an alignment solution to look like.
I think that to have an aligned AI it is necessary (but not sufficient) that we have shared abstractions/ontology/concepts/ (what ever you want to call it) with the AI.
I think the way to make progress on the above is to understand what ontology/concepts/abstraction our current AIs are using, and the process that shapes these abstraction.
I think the way to do this is though mech-interp, mixed with philosophising and theorising. Currently I think the mech-interp part (i.e. look at what is actually going on in a network) is the bottleneck, since I think that philosophising with out data (i.e. agent foundations) has not made much progress l
You might enjoy Concept Algebra for (Score-Based) Text-Controlled Generative Models (and probably other papers / videos from Victor Veitch's groups), which tries to come up with something like a theoretical explanation for the linear represenation hypothesis, including some of the discussion in the reviews / rebuttals for the above paper, e.g.:
'Causal Separability The intuitive idea here is that the separability of factors of variation boils down to whether there are “non-ignorable” interactions in the structural equation model that generates the output from the latent factors of variation—hence the name. The formal definition 3.2 relaxes this causal requirement to distributional assumptions. We have added its causal interpretation in the camera ready version.
Application to Other Generative Models Ultimately, the results in the paper are about non-parametric representations (indeed, the results are about the structure of probability distributions directly!) The importance of diffusion models is that they non-parametrically model the conditional distribution, so that the score representation directly inherits the properties of the distribution.
To apply the results to other generative models, we must articulate the connection between the natural representations of these models (e.g., the residual stream in transformers) and the (estimated) conditional distributions. For autoregressive models like Parti, it’s not immediately clear how to do this. This is an exciting and important direction for future work!
(Very speculatively: models with finite dimensional representations are often trained with objective functions corresponding to log likelihoods of exponential family probability models, such that the natural finite dimensional representation corresponds to the natural parameter of the exponential family model. In exponential family models, the Stein score is exactly the inner product of the natural parameter with y. This weakly suggests that additive subspace
I think the main important lesson is to not get attached to early ideas. Instead of banning early ideas, if anything comes up, you can just write tit down, and set it aside. I find this easier than a full ban, because it's just an easier move to make for my brain.
(I have a similar problem with rationalist taboo. Don't ban words, instead require people to locally define their terms for the duration of the conversation. It solves the same problem, and it isn't a ban on though or speech.)
The other important lesson of the post, is that, in the early discussion, focus on increasing your shared understanding of the problem, rather than generating ideas. I.e. it's ok for ideas to come up (and when they do you save them for later). But generating ideas is not the goal in the beginning.
Hm, thinking about it, I think the mechanism of classical brainstorming (where you up front think of as many ideas as you can) is to exhaust all the trivial, easy to think of, ideas, as fast as you can, and then you're forced to think deeper to come up with new ideas. I guess that's another way to do it. But I think th... (read more)
There is nothing special about human level intelligence, unless you have imitation learning, in which case human level capabilities are very special.
General intelligence is not very efficient. Therefore there will not be any selection pressure for general intelligence as long as other options are available.
GI is very efficient, if you consider that you can reuse a lot machinery that you learn, rather than needing to relearn it over and over again. https://towardsdatascience.com/what-is-better-one-general-model-or-many-specialized-models-9500d9f8751d
1Linda Linsefors
Second reply. And this time I actually read the link.
I'm not suppressed by that result.
My original comment was a reaction to claims of the type [the best way to solve almost any task is to develop general intelligence, therefore there is a strong selection pressure to become generally intelligent]. I think this is wrong, but I have not yet figured out exactly what the correct view is.
But to use an analogy, it's something like this: In the example you gave, the AI get's better at the sub tasks by learning on a more general training set. It seems like general capabilities was useful. But consider that we just trained on even more data for a singel sub task, then wouldn't it develop general capabilities, since we just noticed that general capabilities was useful for that sub task. I was planing to say "no" but I notice that I do expect some transfer learning. I.e. if you train on just one of the dataset, I expect it to be bad at the other ones, but I also expect it to learn them quicker than without any pre-training.
I seem to expect that AI will develop general capabilities when training on rich enough data, i.e. almost any real world data. LLM is a central example of this.
I think my disagreement with at least my self from some years ago and probably some other people too (but I've been away a bit form the discourse so I'm not sure), is that I don't expect as much agentic long term planing as I used to expect.
1Linda Linsefors
I agree that eventually, at some level of trying to solve enough different types of tasks, GI will be efficient, in terms of how much machinery you need, but it will never be able to compete on speed.
Also, it's an open question what is "enough different types of tasks". Obviously, for a sufficient broad class of problems GI will be more efficient (in the sense clarified above). Equally obviously, for a sufficient narrow class of problems narrow capabilities will be more efficient.
Humans have GI to some extent, but we mostly don't use it. This is interesting. This means that a typical human environment is complex enough so that it's worth carrying around the hardware for GI. But even though we have it, it is evolutionary better to fall back at habits, or imitation, or instinkt, for most situations.
Looking back to exactly what I wrote, I said there will not be any selection pressure for GI as long as other options are available. I'm not super confident in this. But if I'm going to defend it here anyway by pointing out that "as long as other options are available", is doing a lot of the work here. Some problems are only solvable by noticing deep patterns in reality, and in this case a sufficiently deep NN with sufficient training will learn this, and that is GI.
3David Rein
I like that description of NFL!
2DragonGod
Re: your hot take on general intelligence, see: "Is General Intelligence Compact?"
Even now and then I meet someone who tries to argue that if I don't agree with them this is because I'm not open mided enough. Is there a term for this?
Epistemically I'm not convinced buy this type of arugment, but socialy it feels like I'm beeing shamed, and I hate it.
I also find it hard to call out this type of behaviur when it happens, even when I can tell exactly what is going on. I think it I had a name for this behaviour it would be easier? Not sure though?
Edit to add:
I've now got some more time to figure out what I want and don't want out of this thread. The early responses helped with this, so thanks!
What I'm most interested in is a name for this behaviour. Naming it helps in at least two ways. It makes it easier to call out in the moment (as mentioned above), but it also makes it easer for me to handle internaly. I can be like "ah, it's this thing again" in my head, rather than being overwelmed.
What I'm not interested is in, is any advice/suggestions that continues the conversation. After a person have pulled one of these moves on me, I am both angry at them, and do not trust them to cooporate in a any form of good faith conversation.
If you have some ideas for how I can end the conversation that does not feel uterly humiliating to me, please tell me. Anything that is phrased like a question is out. I do not want to heare what they have to say, and asking quiestions that you don't want answers to, is wrong and bad.
Seems like a subtype of Bulverism; not aware of a more specific term.
Assuming you have a LWer-typical level of atypicality, you could say "I literally do/believe [outlandish but politically-neutral activity/opinion], there's no way closed-mindedness is my problem." (If it were me, I'd use donating to Shrimp Welfare; apparently most people think that's strange, for some reason.)
6Linda Linsefors
I feel like if I try to defend my openmindedness I loose. It just opens up more attac surfaces to someone who is hostile and doesn't argues in good faith.
I think it's much better to call out why calling someone close minded for not listening is just invalid in general, not just this time in particular. And I do believe it is.
If someone isn't listening to you. Them being to close minded is so faaaaaar the list of most likely explanation that. Much less likely than:
* Your argument are bad
* Dissintrest in the topic
* Other things they rather do right now
2Viliam
Yeah. The opponent's move is establishing "you can change your mind and adopt my opinion" as the criterion to measure your open-mindedness. If you can switch to their position, you are allowed to keep calling yourself open-minded; if you don't, you lose that right.
(The rational answer would be: yes, you are capable of adopting any position, including theirs, when there is a good reason to do so. Open-mindedness does not mean adopting random positions for no good reason, or simply because someone calls you a chicken if you don't.)
So the essence of the move is "I decide what is the true (costly) signal of the trait you claim to have". And the choice of the signal is obviously self-serving. I mean, in theory, they could have asked you to demonstrate your open-mindedness by adoption a position they don't agree with; that would be an equally valid proof of your ability to change your mind. But of course there is no incentive for them to do so. Which shows that evaluating your open-mindedness impartially was never the true goal here.
Another thing is that there is a difference between "being open-minded" and "signaling open-mindedness". Just because you are capable of adopting various kinds of positions, doesn't mean that you should. To consider options X, Y, Z, and afterwards decide to stay with the original X, can be perfectly open-minded, even if from outside it may be difficult to distinguish from "the person did not consider Y and Z at all". (It's like when a gifted child solves a mathematical problem too fast, and the teacher accuses them of merely guessing the answer. There is a difference between doing the work, and demonstrating to other people that you did the work.)
Shortly:
* open-mindedness does not mean "doing what you want me to do"; that's called social pressure
* it is perfectly open-minded to consider a hypothesis... and then reject it
2Linda Linsefors
Bulverism is a good term, thanks!
4cubefox
A more transparent term would be psychologizing:
See also Ayn Rand on this topic:
(Lots more ranting about psychologizers. Schopenhauer energy.)
6Vladimir_Nesov
Under the belief vs. understanding distinction, open-mindedness is a virtue of understanding ideas you disbelieve (or purposes you don't endorse). It's not directly relevant to belief, but sometimes understanding is the bottleneck to belief, in which case more open-mindedness would help. When you already understand the idea, open-mindedness is no longer relevant.
More to the point, understanding an idea shouldn't necessarily result in believing it, and high open-mindedness doesn't increase the number of hours in a day. Learning any given piece of nonsense would still not be the best thing to focus on, but high open-mindedness should prevent you from actively avoiding low-hanging fruit of understanding when it's ripe for the taking, just because it doesn't seem to be the kind of thing you are likely to believe or endorse.
5james oofou
Them: "I think X"
You: "That's wrong because Z"
Them: "I think you're just disagreeing because you'd not open-minded enough"
You: "What makes you think that?"
Them: "I think it because Y"
What do they say for 'Y'? That seems the part that actually constitutes their argument and which you will be able to call out if they're making a mistake.
3Gurkenglas
when I put myself in the shoes of one who would say that someone is not open-minded enough and fill in the Y I get "you responded so quickly that you must have been speaking from cache instead of computing an answer"
2Steven Byrnes
One thing you can maybe do is throw such accusations right back: “You say I’m being closed-minded to you, but aren’t you equally being closed-minded to me?”
It comes across as escalatory, and might be counterproductive, but I’ve also sometimes found it helpful. Depends a lot on the person and situation.
4Linda Linsefors
I don't want to use this sugestion, not because it is escalatory, but because it's a question, which invites them to have more opinions.
What I want is a way out, but that has the feeling of standing up for myself, rather then the feeling of humiliation and defeet.
If someone starts to accuse me of not beeing openminded to their opinion, it's usually because I think their opinion is dumb. I rather not hurt their feelings if I can avoid it, but I'm also not going to worry too much about being polite to someone after they done this particular retorical move.
Usually the way out is to just leave. But last time this happened was at a small metup, and the only way out was to leave the event, which I did. I'm not happy about this and would like better options.
3Dagon
A lot depends on why you want to stay, and whether you are likely to have interesting/productive further discussions. I often just let them off the hook with a "I guess I am a bit closed on this particular topic - let's discuss something else".
In theory "agree to disagree" should be impossible among rational entities with compatible priors, but in practice humans often meet neither of those criteria. That's OK, when you reach the point of no further updates in either direction, you move on.
2Linda Linsefors
I wish I could say something like that and be ok. But to me it feels too humiliating. And also often factually wrong, I.e. I'd be open to good argument.
2Viliam
A reply I got in a similar situation, paraphrased: "well, it's you who identifies as a rationalist, you hypocrite."
In other words, as if by calling myself a rationalist (not in that specific debate, just generally something I said in a different context that my opponent knows about) means that I accept an asymmetrical burden.
You mean, in that you can simply prompt for a reasonable non-infinite performance and get said outcome?
1Linda Linsefors
Similar but not exactly.
I mean that you take some known distribution (the training distribution) as a starting point. But when sampling actions you do so from shifted on truncated distribution to favour higher reward policies.
The in the decision transformers I linked, AI is playing a variety of different games, where the programmers might not know what a good future reward value would be. So they let the system AI predict the future reward, but with the distribution shifted towards higher rewards.
I discussed this a bit more after posting the above comment, and there is something I want to add about the comparison.
In quantilizers if you know the probability of DOOM from the base distribution, you get an upper bound on DOOM for the quantaizer. This is not the case for type of probability shift used for the linked decision transformer.
DOOM = Unforeseen catastrophic outcome. Would not be labelled as very bad by the AI's reward function but is in reality VERY BAD.
1Jobst Heitzig
From my reading of quantilizers, they might still choose "near-optimal" actions, just only with a small probability. Whereas a system based on decision transformers (possibly combined with a LLM) could be designed that we could then simply tell to "make me a tea of this quantity and quality within this time and with this probability" and it would attempt to do just that, without trying to make more or better tea or faster or with higher probability.
1Linda Linsefors
Yes, that is a thing you can do with decision transforms too. I was referring to variant of the decision transformer (see link in original short form) where the AI samples the reward it's aiming for.
Yesterday was the official application deadline for leading a project at the next AISC. This means that we just got a whole host of project proposals.
If you're interested in giving feedback and advise to our new research leads, let me know. If I trust your judgment, I'll onboard you as an AISC advisor.
Also, it's still possible to send us a late AISC project proposals. However we will prioritise people how applied in time when giving support and feedback. Further more, we'll prioritise less late applications over more late applications.
Blogposts are the result of noticing difference in beliefs. Either between you and other of between you and you, across time.
I have lots of ideas that I don't communicate. Sometimes I read a blogpost and think "yea I knew that, why didn't I write this". And the answer is that I did not have an imagined audience.
My blogposts almost always span after I explained a thing ~3 times in meat space. Generalizing from these conversations I form an imagined audience which is some combination of the ~3 people I talked to. And then I can write.
Recently someone either suggested to me (or maybe told me they or someone where going to do this?) that we should train AI on legal texts, to teach it human values. Ignoring the technical problem of how to do this, I'm pretty sure legal text are not the right training data. But at the time, I could not clearly put into words why. Todays SMBC explains this for me:
Law is not a good representation or explanation of most of what we care about, because it's not trying to be. Law is mainly focused on the c... (read more)
Moreover, legal texts are not super strict (much is left to interpretation) and we are often selective about "whether it makes sense to apply this law in this context" for reasons not very different from religious people being very selective about following the laws of their holy books.
1gw
I spoke with some people last fall who were planning to do this, perhaps it's the same people. I think the idea (at least, as stated) was to commercialize regulatory software to fund some alignment work. At the time, they were going by Nomos AI, and it looks like they've since renamed to Norm AI.
2Linda Linsefors
I found this on their website
I'm not sure if this is worrying, because I don't think AI overseeing AI is a good solution. Or it's actually good, because, again, not a good solution, which might lead to some early warnings?
2Linda Linsefors
Their more human-in-the-loop stuff seems neat though.
1CstineSublime
Would sensationalist tabloid news stories be better training data? Perhaps it is the inverse problem: fluffy human interest stories and outrage porn are both engineered for the lowest common denominator, the things that overwhelmingly people think are heartwarming or miscarriages of justice respectively. However if you wanted to get a AI to internalize what is in fact the sources of outrage and consensus among the wider community I think it's a place to start.
The obvious other examples are fairy tales, fables, parables, jokes, and urban legends - most are purpose encoded with a given society's values. Amateur book and film reviews are potentially another source of material that displays human values in that whether someone is satisfied with the ending or not (did the villain get punished? did the protagonist get justice?) or which characters they liked or disliked is often attached to the reader/viewer's value systems. Or as Jerry Lewis put it in the Total Filmmaker: in comedy, a snowball is never thrown at a battered fedora: "The top-hat owner is always the bank president who holds mortgage on the house...".
2Linda Linsefors
Sensationalist tabloid news stories and other outrage porn are not the opposite. These are actually more of the same. More edge cases. Anything that is divisive have the problem I'm talking about.
Fiction is a better choice.
Or even just completely ordinary every-day human behaviour. Most humans are mostly nice most of the time.
We might have to start with the very basic, the stuff we don't even notice, because it's too obvious. Things no-one would think of writing down.
2CstineSublime
Could you explain how are they edge cases if they are the lowest common denominator? Doesn't that make them the opposite of an edge case? Aren't they in fact the standard or yardstick necessary to compare against?
Why is is it different let alone better choice? Fiction is a single author's attempt to express their view of the world, including morality, and therefore an edge case. While popular literature is just as common denominator as tabloid journalism, since the author is trying to be commercial.
2Linda Linsefors
I don't read much sensationalist tabloid, but my impression is that the things that get a lot of attention in the press, is things people can reasonable take either side of.
Scott Alexander writes about how everyone agrees that factory framing is terrible, but exactly because this overwhelming agreement, it get's no attention. Which is why PETA does outrageous things to get attention.
The Toxoplasma Of Rage | Slate Star Codex
There need to be two sides to an issue, or else no-one gets ingroup loyalty points for taking one side or the other.
3CstineSublime
A cursory glance suggests that it is not the case, take a top story headline on the Australian Daily Mail over the last 7 days: "Miranda, Sydney: Urgent search is launched for missing Bailey Wolf, aged two, who vanished yesterday" it is not reasonable for someone to hope that a two year old who has vanished not be found. This is exactly the kind of thing you're suggesting AI should be trained on, because of how uniform responses are to this headline. Keep in mind this is one of the most viewed stories, and literally top of the list I found.
I've read Scott's article, but are you trying to understand what get's attention or what is the nexus or commonly agreed upon moral principles of a society?
3Linda Linsefors
Ok, you're right that this is a very morally clear story. My bad for not knowing what's typical tabloid storry.
Missing kid = bad,
seems like a good lesson for AI to learn.
About once or twice per week this time of year someone emails me to ask:
Please let me break rule X
My response:
No you're not allowed to break rule X. But here's a loop hole that lets you do the thing you want without technically breaking the rule. Be warned that I think using the loophole is a bad idea, but if you still want to, we will not stop you.
Because not leaving the loophole would be too restrictive for other reason, and I'm not going to not tell people all their options.
The fact that this puts the responsib... (read more)
I suspect it's not possible to build autonomous aligned AIs (low confidence). The best we can do is some type of hybrid humans-in-the-loop system. Such a system will be powerful enough to eventually give us everything we want, but it will also be much slower and intellectually inferior to what is possible with out humans-in-the-loop. I.e. the alignment tax will be enormous. The only way the safe system can compete, is by not building the unsafe system.
Therefore we need AI Governance. Fortunately, political action is getting a lo... (read more)
If LMs reads each others text we can get LM-memetics. A LM meme is a pattern which, if it exists in the training data, the LM will output at higher frequency that in the training data. If the meme is strong enough and LLMs are trained on enough text from other LMs, the prevalence of the meme can grow exponentially. This has not happened yet.
There can also be memes that has a more complicated life cycle, involving both humans and LMs. If the LM output a pattern that humans are extra interested in, then the humans ... (read more)
This mechanism may not require LMs to be involved.
3Linda Linsefors
Not sure what you mean exactly. But yes, memetics without AI does exist.
https://en.wikipedia.org/wiki/Memetics
1Mateusz Bagiński
I think an LM-meme is something more than just a frequently repeating pattern. More like frequently repeating patterns with which can infect each other by outputting them into the web or whatever can be included as in a trainibg set for LMs.
There may be other features that are pretty central to the prototype of the (human) meme concept, such as its usefulness for some purpose (ofc not all memes are useful). Maybe this one can be extrapolated to the LM domain, e.g. it helps it presict the next token ir whatever but I'm not sure whether it's the right move to appropriate the concept of meme for LMs. If we start discovering infectious patterns of this kind, it may be better to think about them as one more subcategory of a general category of replicators of which memes, genes, and prions are another ones.
Estimated MSE loss for three diffrent ways of embedding features into neuons, when there are more possible features than neurons.
I've typed up some math notes for how much MSE loss we should expect for random embedings, and some other alternative embedings, for when you have more features than neurons. I don't have a good sense for how ledgeble this is to anyone but me.
Note that neither of these embedings are optimal. I belive that the optimal embeding for minimising MSE loss is to store the features in almost orthogonal directions, which is similar to ran... (read more)
This is probably too obvious to write, but I'm going to say it anyway. It's my short form, and approximately no-one reads short forms. Or so I'm told.
Human value formation is to a large part steered by other humans suggesting value systems for you. You get some hard to interpret reward signal from your brainstem, or something. There are lots of "hypothesis" for the "correct reward function" you should learn.
(Quotation marks because there are no ground through for what values you should have. But this is mathematically equivalent to a learning the tru... (read more)
Somebody is reading shortforms...
I disagree. That humans learn values primarily via teaching. 1) parenting is known to have little effect on children's character - which is one way of saying their values. 2) while children learn to follow rules teens are good at figuring out what is in their interest.
I think it makes sense to pose argue the point though.
For example I think that proposing rules makes it more probable that the brain converges on these solutions.
5Linda Linsefors
This is not counter evidence to my claim. The value framework a child learns about from their parents is just one of many value frameworks they hear about from many, many people. My claim is that the power lies in noticing the hypothesis at all. Which ideas you get told more times (e.g. by your parents) don't matter.
As far as I know, what culture you are in very much influences your values, which my claim would predict.
I'm not making any claims about rule following.
I'm basically ready to announce the next Technical AI Safety Unconference (TAISU). But I have hit a bit of decision paralysis as to what dates it should be.
If you are reasonably interested in attending, please help me by filling in this doodle
When I'm in a conversation often track who the conversation is for. I.e. who is this conversation primerely seving, in this moment.
If I'm ranting, then this conversation is for me, to let me realsease some tension. I will express my self in a way that feels good to me.
If I'm sharing usefull information, then the conversation is for the other person. I will express my self in a way to make the information clear and accessable for them, and also pay attetion to if they even want this information.
I can explain myself becasue I need to be seen, or becasue
Some conversations should be primarily about an object level thing, for its own elucidation (they serve the idea itself, bringing it into the world). A person can have motivations that are not about (emotions of) people (including that person themselves).
A good explanation constructs an understanding in its audience, which is slightly different from describing something, or from making it accessible.
2Linda Linsefors
I just checked in with myself what the post above was for. I tink its part rant, part me clarifying my thoughs by writing them, and hopefully getting some reflections back. And it's also becasue maybe someone will find it usefull, but that's also maybe secretly about me, to create more conversation partners that track the things I think is important.
If I was writing a proper LW blogpost then [who is this for] should primarlely be the reader.
But in a shortform like this I feel like I'm allowed to do what I want. And also people can take away what they want. Tracking [who is this for] is much more important when people are in a live conversations, becasue that is a more trapped situation, requiring more concideration.
2Linda Linsefors
There are also the type of conversation where the other person pretends that it is about me, but acctually it is about their need to feel like a good person. These situatios are afull and terrible, and I will not play along.
2Mateusz Bagiński
I usually don't, though maybe unconsciously? Plausibly it would be good for me to try to track it explicitly.
cf https://www.lesswrong.com/posts/bhLxWTkRc8GXunFcB/what-are-you-tracking-in-your-head
2Linda Linsefors
Thanks for the link. I have read it but it was long ago, so thanks for the reminder. It's related in a helpfull way.
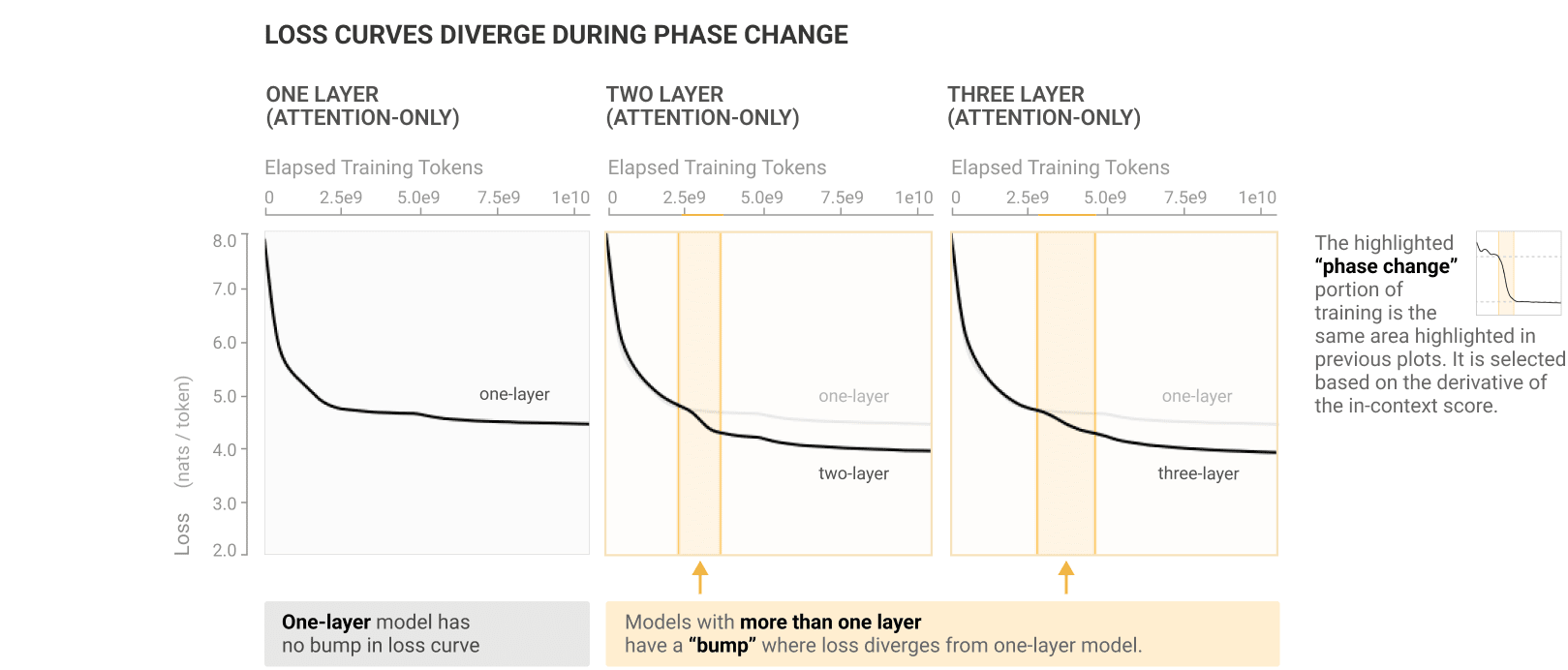
This already strongly suggests some connection between induction heads and in-context learning, but beyond just that, it appears this window is a pivotal point for the training process in general: whatever's occurring is visible as a bump on the training curve (figure below). It is in fact the only place in training where the loss is not convex (monotonically decreasing in slope).
I can see the bump, but it's not the only one. The two layer graph has a second similar bump, which a... (read more)
Toy model: Each agent has a utility function they want to maximise. The input to the utility function is a list of values describing the state of the world. Different agents can have different input vectors. Assume that every utility function monotonically increases, decreases or stays constant for changes in each impute variable (I did say it was a toy model!). An agent is said to value something if the utility function increases with increasing quantity of that thing. Note that if an agents utility function decrease... (read more)
Re second try: what would make a high-level operationalisation of that sort helpful? (operationalize the helpfulness of an operationalisation)
1Linda Linsefors
This is a good question.
The not so operationalized answer is that a good operationalization is one that are helpful for achieving alignment.
An operationalization of [helpfulness of an operationalization] would give some sorts to gears level understanding of what shape the operationalization should have to be helpful. I don't have any good model for this, so I will just gesture vaguely.
I think that mathematical descriptions are good, since they are more precise. My first operationalization attempt is pretty mathematical which is good. It is also more "constructive" (not sure if this is the exact right word), i.e. it describes alignment in terms of internal properties, rather than outcomes. Internal properties are more useful as design guidelines, as long as they are correct. The big problem with my first operationalization is that it don't actually point to what we want.
The problem with the second attempt is that it just states what outcome we want. There is nothing in there to help us achieve it.
6Mateusz Bagiński
Can't you restate the second one as the relationship between two utility functions UA and UB such that increasing one (holding background conditions constant) is guaranteed not to decrease the other? I.e. their respective derivatives are always non-negative for every background condition.
∂UA∂UB≥0∧∂UB∂UA≥0
1Linda Linsefors
Yes, I like this one. We don't want the AI to find a way to give it self utility while making things worse for us. And if we are trying to make things better for us, we don't want the AI to resist us.
Do you want to find out what these inequalities implies about the utility functions? Can you find examples where your condition is true for non-identical functions?
1Mateusz Bagiński
I don't have a specific example right now but some things that come to mind:
* Both utility functions ultimately depend in some way on a subset of background conditions, i.e. the world state
* The world state influences the utility functions through latent variables in the agents' world models, to which they are inputs.
* UA changes only when MA (A's world model) changes which is ultimately caused by new observations, i.e. changes in the world state (let's assume that both A and B perceive the world quite accurately).
* If whenever UA changes UB doesn't decrease, then whatever change in the world increased UA, B at least doesn't care. This is problematic when A and B need the same scarce resources (instrumental convergence etc). It could be satisfied if they were both satisficers or bounded agents inhabiting significantly disjoint niches.
* A robust solution seems seems to be to make (super accurately modeled) UB a major input to UA.
2Linda Linsefors
Lets say that
U_A = 3x + y
Then (I think) for your inequality to hold, it must be that
U_B = f(3x+y), where f' >= 0
If U_B care about x and y in any other proportion, then B can make trade-offs between x and y which makes things better for B, but worse for A.
This will be true (in theory) even if both A and B are satisfisers. You can see this by assuming replacing y and x with sigmoids of some other variables.
I remember reading that some activation stearing experiments used x100 size activation vectors. Is this correct? That would be much larger than the normal activation in that layer, right?
How does the model deal with this? If there is any superposition going on, I expect activation spill over everywhere, breaking everything.
If you amplify the activations in one layer, what effect has that on the magnitude of the activations in the next layer? If it's smaller, by what mechanism? That mechanism is probably an error correction algorithm. Or just some suppressi... (read more)
One issue is that after the typo is fixed, the react remains, but will either point to nothing or point to a place where there is not a typo (any more).
1Karl Krueger
The highlight is pretty subtle, at least as it appears to me on the above comment. Screenshot here.
Recently an AI safety researcher complained to me about some interaction they had with an AI Safety communicator. Very stylized, there interaction went something like this:
(X is some fact or topic related to AI Safety
Communicator: We don't know anything about X and there is currently no research on X.
Researcher: Actually, I'm working on X, and I do know some things about X.
Communicator: We don't know anything about X and there is currently no research on X.
I notice that I semi-frequently hear communicators saying things like the thing above. I think ... (read more)
I notice that I don't expect FOOM like RSI, because I don't expect we'll get an mesa optimizer with coherent goals. It's not hard to give the outer optimiser (e.g. gradient decent) a coherent goal. For the outer optimiser to have a coherent goal is the default. But I don't expect that to translate to the inner optimiser. The inner optimiser will just have a bunch of heuristics and proxi-goals, and not be very coherent, just like humans.
The outer optimiser can't FOOM, since it don't do planing, and don't have strategic s... (read more)
I recently updated how I view the alignment problem. The post that caused my update is this one form the shard sequence. Also worth mentioning is older post that points to the same thing, but I just happen to read it later.
Basically I used to think we needed to solve both outer and inner alignment separately. No I no longer think this is a good decomposition of the problem.
It’s not obvious that alignment must factor in the way described above. There is room for trying to set up training in such a way to guarantee a friendly mesa-objective somehow wit
Any policy can be model as a consequentialist agent, if you assume a contrived enough utility function. This statement is true, but not helpful.
The reason we care about the concept agency, is because there are certain things we expect from consequentialist agents, e.g. instrumental convergent goals, or just optimisation pressure in some consistent direction. We care about the concept of agency because it holds some predictive power.
[... some steps of reasoning I don't know yet how to explain ...]
Therefore, it's better to use a concept of agency that ... (read more)