Shallow review of technical AI safety, 2025
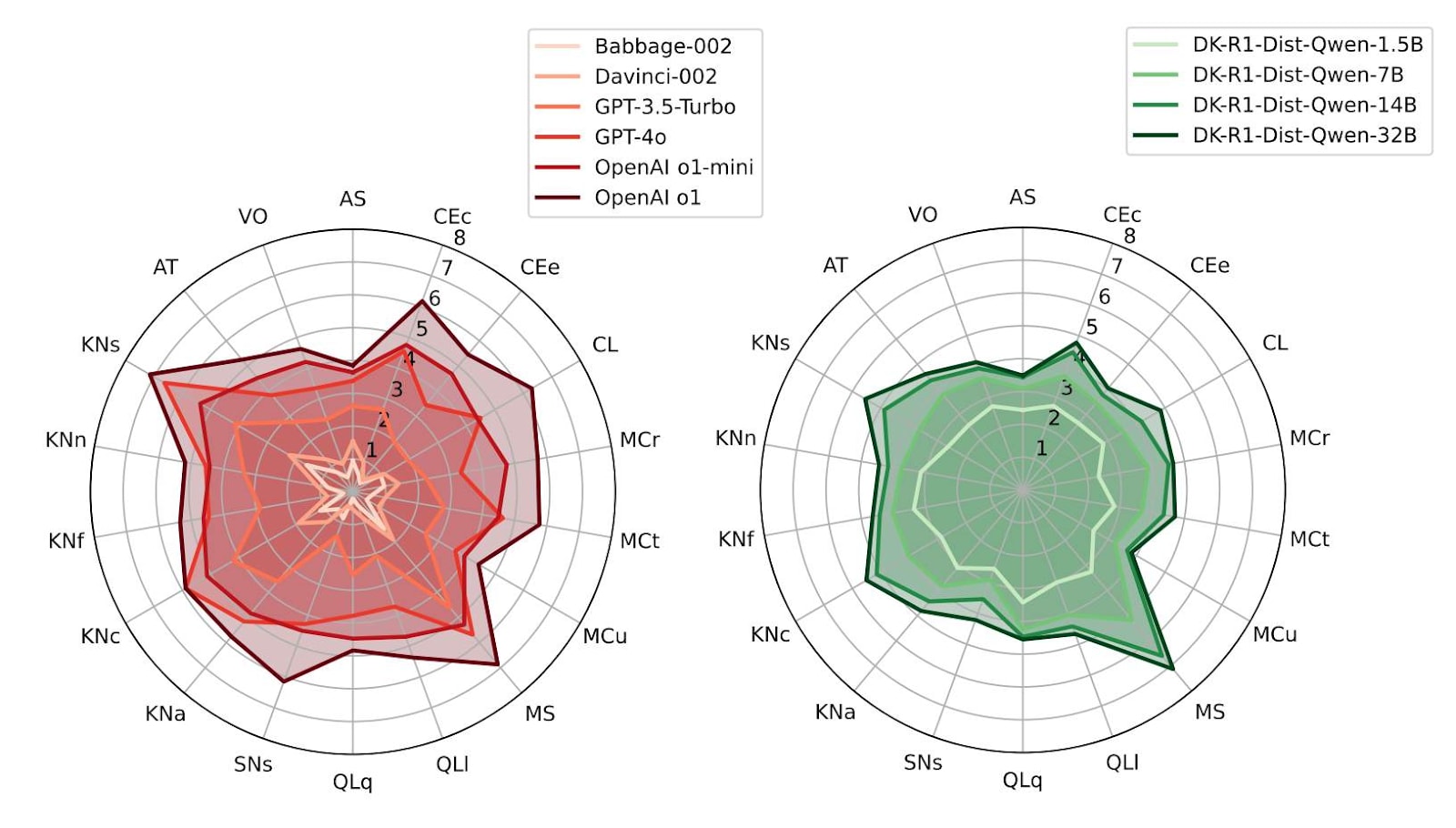
Website version · Gestalt · Repo and data Change in 18 latent capabilities between GPT-3 and o1, from Zhou et al (2025) This is the third annual review of what’s going on in technical AI safety. You could stop reading here and instead explore the data on the shallow review website. It’s shallow in the sense that 1) we are not specialists in almost any of it and that 2) we only spent about two hours on each entry. Still, among other things, we processed every arXiv paper on alignment, all Alignment Forum posts, as well as a year’s worth of Twitter. It is substantially a list of lists structuring 800 links. The point is to produce stylised facts, forests out of trees; to help you look up what’s happening, or that thing you vaguely remember reading about; to help new researchers orient, know some of their options and the standing critiques; and to help you find who to talk to for actual information. We also track things which didn’t pan out. Here, “AI safety” means technical work intended to prevent future cognitive systems from having large unintended negative effects on the world. So it’s capability restraint, instruction-following, value alignment, control, and risk awareness work. We don’t cover security or resilience at all. We ignore a lot of relevant work (including most of capability restraint): things like misuse, policy, strategy, OSINT, resilience and indirect risk, AI rights, general capabilities evals, and things closer to “technical policy” and products (like standards, legislation, SL4 datacentres, and automated cybersecurity). We focus on papers and blogposts (rather than say, gdoc samizdat or tweets or Githubs or Discords). We only use public information, so we are off by some additional unknown factor. We try to include things which are early-stage and illegible – but in general we fail and mostly capture legible work on legible problems (i.e. things you can write a paper on already). Even ignoring all of that as we do, it’s still