This is a special post for quick takes by Joseph Miller. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Mentioned in
This is an attempt to compile all publicly available primary evidence relating to the recent death of Suchir Balaji, an OpenAI whistleblower.
This is a tragic loss and I feel very sorry for the parents. The rest of this piece will be unemotive as it is important to establish the nature of this death as objectively as possible.
I was prompted to look at this by a surprising conversation I had IRL suggesting credible evidence that it was not suicide. The undisputed facts of the case are that he died of a gunshot wound in his bathroom sometime around November 26 2024. The police say it was a suicide with no evidence of foul play.
Most of the evidence we have comes from the parents and George Webb. Webb describes himself as an investigative journalist, but I would classify him as more of a conspiracy theorist, based on a quick scan of some of his older videos. I think many of the specific factual claims he has made about this case are true, though I generally doubt his interpretations.
Webb seems to have made contact with the parents early on and went with them when they first visited Balaji's apartment. He has since published videos from the scene of the death, against the wishes of the parents[1] and as a result the parents have now unendorsed Webb.[2]
List of evidence:
- He didn't leave a suicide note.[3]
- The cause of death was decided by the authorities in 14 (or 40, unclear) minutes.[4]
- The parents arranged a private autopsy which "made their suspicions stronger".[5]
- The parents say "there are a lot of facts that are very disturbing for us and we cannot share at the moment but when we do a PR all of that will come out."[6]
- The parents say "his computer has been deleted, his desktop has been messed up".[7]
- It was his birthday and he bought a bike on the week of his death.[10]
- He said he didn't want to work and he was going to take a gap year, "leaving the AI industry and getting into machine learning and neuroscience" but also he was planning to start his own company and was reaching out to VCs for seed funding.[11]
- He had just interviewed with the New York Times and he was supposed to do further interviews in the days after his death.[12]
- According to the parents and Webb, there are signs of foul play at the scene of death:
- There are several areas with blood, [Confirmed from pictures] suggesting to Webb and the parents he was trying to crawl out of the bathroom.[13][14]
- Webb says the body had bleeding from the genitals.[15] I'm not aware of a better source for this claim, so right now I think it is probably false.
- The trash can in the bathroom was knocked over.[13][16] [Confirmed from pictures].
- A floss pick is on the floor.[13][17] [Confirmed from pictures]. Webb interprets this as being dropped at the time of death, suggesting that Balaji was caught by surprise.
- The path of the bullet through the head missed the brain. I'm not sure what the primary source for this is, but I'm not sure why Webb would invent this, so I think it's true. Webb takes this as evidence that it was shot during a struggle rather than at the considered pace of a suicide.[18]
- The bullet did not go all the way through the head, suggesting a lower caliber, quiet gun.[19]
- According to Webb and the parents, the drawers of the apartment were ransacked, the cupboards were thrown open.[8][20] From the pictures this looks false, although the apartment is very messy and his hiking backpacks are strewn around with much of their contents on the table (he had recently returned from a hiking trip).
- The blood on the sink looks different, suggesting to Webb that it came from a different part of the body.[21] This is not obvious to me from the pictures but not implausible and the main pool of blood looks surprisingly dark.
- There is a half-eaten meal at the desk in the apartment. [Confirmed from pictures].
- There is a tuft of Balaji's hair, soaked in blood, under the bathroom door. [Confirmed that's what it looks like in the pictures], again suggesting to Webb a violent struggle.
- According to the parents, he had a USB thumb drive which is now missing, containing important evidence for an upcoming court case about OpenAI's use of copyrighted data.[8][22]
- People that spoke to him around the time of his death report him to have been in high spirits and making plans for the near future.[23]
- George Webb claims there were security cameras working all on floors except the floor which he lived on.[24] This appears to conflict with the parents' claim that the police said no one came in or out (see below), but may be referring to different cameras, as the parents also mention that the murderer could have come through a different entrance to the main one.[25]
- The parents say "OpenAI has deleted the copyright data that was evidence that was given to the discovery for the [New York Times] lawsuit. They deleted the data and now my son is also gone, so now they're all set for winning the lawsuit... It's also said that my son had the documentation to prove the copyright violation. His statement, his testimony would have turned the AI industry upside down..."[26]
- Looking into the details of this, OpenAI did delete some data but this wasn't a permanent deletion of any of the primary sources and I think it was probably an accident and not significant to the outcome of the case.
- I don't see any strong reason to believe Balaji had secret evidence that would have been critical to the outcome of the case.
- Ilya Sutskever had two armed bodyguards with him at NeurIPS.
Evidence against:
- One reason the authorities gave for declaring it a suicide was that CCTV footage showed that no one else came in or out of the apartment.[27]
- In high school Balaji won a $100,000 prize for a computer science competition. His parents didn't find out until they saw the news online, suggesting he may not have been very open with them.[28]
My interpretations:
- If we interpret the apartment as simply messy (as it looks to me), rather than ransacked, then we can probably discount the knocked-over trash can, the floss pick on the floor and the half-eaten meal. We can also probably discard the hypothesis of someone trying to locate a USB drive with secret information, which raises more questions than it answers (why didn't he reveal this information before? why didn't he back up this crucial data anywhere?).
- In my uninformed view, it doesn't look like the pictures of the scene of death strongly suggest a struggle between murderer and victim, although I don't know how to explain the tuft of hair.
- The motivations of OpenAI or some other actor to murder a whistleblower are unlikely. The most plausible to me is that they want to send a warning to other potential whistleblowers, but this isn't very compelling.
- There's no smoking gun and the parents (understandably) do not look like they are thinking very systematically to establish a case for foul-play. This is notable because their claim of foul-play is the main factor that privileged this hypothesis to credible people.
- Balaji appeared from the outside to be a happy and highly successful person with important plans in the next few days. It is surprising that someone like that would commit suicide.
Overall my conclusion is that this was a suicide with roughly 96% confidence. This is a slight update downwards from 98% when I first heard about it and overall quite concerning.
I encourage people to trade on this related prediction market and report further evidence.
Useful sources:
- https://x.com/RealGeorgeWebb1/status/1874166318053941567
- https://www.youtube.com/watch?v=zu1whk7XdCo
- https://rumble.com/v6411hm-forensics-say-the-open-ai-whistleblower-was-executed.html?e9s=src_v1_upp
- https://www.youtube.com/watch?v=4LkteX3o1Co
- ^
I'm not linking to this evidence here, in the spirit of respecting the wishes of the parents, but this is an important source that informed my understanding of the situation.
- ^
- ^
Source: Poornima Ramarao (11:22)
- ^
Source: Poornima Ramarao (12:38)
- ^
Source: Poornima Ramarao (13:02)
- ^
Source: Poornima Ramarao (15:47)
- ^
Source: Poornima Ramarao (16:36)
- ^
Source: George Webb + Poornima Ramarao (1:45)
- ^
Source: George Webb (9:56)
- ^
Source: (23:27)
- ^
Source: (8:02)
- ^
Source: (26:00)
- ^
Source: George Webb + Poornima Ramarao (0:35)
- ^
Source: George Webb (6:53)
- ^
Source: George Webb (3:38)
- ^
Source: George Webb (5:44)
- ^
Source: George Webb (5:46)
- ^
Source: George Webb (0:05)
- ^
Source: George Webb (6:23)
- ^
Source: George Webb (9:12)
- ^
Source: Poornima Ramarao (1:18)
- ^
Source: George Webb (9:45)
- ^
Source: Poornima Ramarao (4:30)
- ^
Source: George Webb (9:30)
- ^
Source: Poornima Ramarao (2:40)
- ^
Source: Poornima Ramarao (4:14)
- ^
Source: Poornima Ramarao (12:42)
- ^
Source: Ramamurthy (17:37)
- ^
Source: George Webb (13:29)
- ^
Source: George Webb (5:43)
The undisputed facts of the case are that he died of a gunshot wound in his bathroom sometime around November 26 2024. The police ruled it as a suicide with no evidence of foul play.
As in, this is also what the police say?
Did the police find a gun in the apartment? Was it a gun Suchir had previously purchased himself according to records? Seems like relevant info.
As in, this is also what the police say?
Yes, edited to clarify. The police say there was no evidence of foul play. All parties agree he died in his bathroom of a gunshot wound.
Did the police find a gun in the apartment? Was it a gun Suchir had previously purchased himself according to records? Seems like relevant info.
The only source I can find on this is Webb, so take with a grain of salt. But yes, they found a gun in the apartment. According to Webb, the DROS registration information was on top of the gun case[1] in the apartment, so presumably there was a record of him purchasing the gun (Webb conjectures that this was staged). We don't know what type of gun it was[2] and Webb claims it's unusual for police not to release this info in a suicide case.
Well, it seems quite important whether the DROS registration could possibly have been staged. If e.g. there is footage of Suchir buying a gun 6+ months prior, using his ID, etc. then the assassins would have had to sneak in and grab his own gun from him etc. which seems unlikely.
Is the interview with the NYT going to be published?
Is any of the police behavior actually out of the ordinary?
Well, it seems quite important whether the DROS registration could possibly have been staged.
That would be difficult. To purchase a gun in California you have to provide photo ID[1], proof of address[2] and a thumbprint[3]. Also it looks like the payment must be trackable[4] and gun stores have to maintain video surveillance footage for up to year.[5]
My guess is that the police haven't actually invested this as a potential homicide, but if they did, there should be very strong evidence that Balaji bought a gun. Potentially a very sophisticated actor could fake this evidence but it seems challenging (I can't find any historical examples of this happening). It would probably be easier to corrupt the investigation. Or the perpetrators might just hope that there would be no investigation.
There is a 10-day waiting period to purchase guns in California[5], so Balaji would probably have started planning his suicide before his hiking trip (I doubt someone like him would own a gun for recreational purposes?).
Is the interview with the NYT going to be published?
I think it's this piece that was published before his death.
Is any of the police behavior actually out of the ordinary?
Epistemic status: highly uncertain: my impressions from searching with LLMs for a few minutes.
It's fairly common for victim's families to contest official suicide rulings. In cases with lots of public attention police generally try to justify their conclusions. So we might expect the police to publicly state if there is footage of Balaji purchasing the gun shortly before his death. It could be that this will still happen with more time or public pressure.
- Ilya Sutskever had two armed bodyguards with him at NeurIPS.
Some people are asking for a source on this. I'm pretty sure I've heard it from multiple people who were there in person but I can't find a written source. Can anyone confirm or deny?
Ilya Sutskever had two armed bodyguards with him at NeurIPS
I don't understand how Ilya hiring personal security counts as evidence, especially at large events like a conference. Famous people often attract unwelcome attention, and having professional protection close by can help deescalate or deter random acts of violence, it is a worthwhile investment in safety if you can afford it. I see it as a very normal thing to do. Ilya would be vulnerable to potential assassination attempts even during his tenure at OpenAI.
Thank you, this is very interesting and it seems like you did a valuable public service in compiling it
- The motivations of OpenAI or some other actor to murder a whistleblower are unlikely. The most plausible to me is that they want to send a warning to other potential whistleblowers, but this isn't very compelling
What do you think of the motive that he was counterfactually going to testify in a very damaging way, or that he had very damaging evidecne/data that was deleted?
"Despite their extreme danger, we only became aware of them when the enemy drew our attention to them by repeatedly expressing concerns that they can be produced simply with easily available materials."
Ayman al-Zawahiri, former leader of Al-Qaeda, on chemical/biological weapons.
I don't think this is a knock-down argument against discussing CBRN risks from AI, but it seems worth considering.
The trick is that chem/bio weapons can't, actually, "be produced simply with easily available materials", if we talk about military-grade stuff, not "kill several civilians to create scary picture in TV".
You sound really confident, can you elaborate on your direct lab experience with these weapons, as well as clearly define 'military grade' vs whatever the other thing was?
How does 'chem/bio' compare to high explosives in terms of difficulty and effect?
Well, I have bioengineering degree, but my point is that "direct lab experience" doesn't matter, because WMDs in quality and amount necessary to kill large numbers of enemy manpower are not produced in labs. They are produced in large industrial facilities and setting up large industrial facility for basically anything is on "hard" level of difficulty. There is a difference between large-scale textile industry and large-scale semiconductor industry, but if you are not government or rich corporation, all of them lie in "hard" zone.
Let's take, for example, Saddam chemical weapons program. First, industrial yields: everything is counted in tons. Second: for actual success, Saddam needed a lot of existing expertise and machinery from West Germany.
Let's look at Soviet bioweapons program. First, again, tons of yield (someone may ask yourself, if it's easier to kill using bioweapons than conventional weaponry, why somebody needs to produce tons of them?). Second, USSR built the entire civilian biotech industry around it (many Biopreparat facilities are active today as civilian objects!) to create necessary expertise.
The difference with high explosives is that high explosives are not banned by international law, so there is a lot of existing production, therefore you can just buy them on black market or receive from countries which don't consider you terrorist. If you really need to produce explosives locally, again, precursors, machinery and necessary expertise are legal and widespread sufficiently that they can be bought.
There is a list of technical challenges in bioweaponry where you are going to predictably fuck up if you have biological degree and you think you know what you are doing but in reality you do not, but I don't write out lists of technical challenges on the way to dangerous capabilities, because such list can inspire someone. You can get an impression about easier and lower-stakes challenges from here.
This seems incredibly reasonable, and in light of this, I'm not really sure why anyone should embrace ideas like making LLMs worse at biochemistry in the name of things like WMDP: https://www.lesswrong.com/posts/WspwSnB8HpkToxRPB/paper-ai-sandbagging-language-models-can-strategically-1
Biochem is hard enough that we need LLMs at full capacity pushing the field forward. Is it harmful to intentionally create models that are deliberately bad at this cutting edge and necessary science in order to maybe make it slightly more difficult for someone to reproduce cold war era weapons that were considered both expensive and useless at the time?
Do you think that crippling 'wmd relevance' of LLMs is doing harm, neutral, or good?
My honest opinion is that WMD evaluations of LLMs are not meaningfully related to X-risk in the sense of "kill literally everyone." I guess current or next-generation models may be able to assist a terrorist in a basement in brewing some amount of anthrax, spraying it in a public place, and killing tens to hundreds of people. To actually be capable to kill everyone from a basement, you would need to bypass all the reasons industrial production is necessary at the current level of technology. A system capable to bypass the need for industrial production in a basement is called "superintelligence," and if you have a superintelligent model on the loose, you have far bigger problems than schizos in basements brewing bioweapons.
I think "creeping WMD relevance", outside of cyberweapons, is mostly bad, because it is concentrated on mostly fake problem, which is very bad for public epistemics, even if we forget about lost benefits from competent models.
I wrote about something similar previously: https://www.lesswrong.com/posts/Ek7M3xGAoXDdQkPZQ/terrorism-tylenol-and-dangerous-information#a58t3m6bsxDZTL8DG
I agree that 1-2 logs isn't really in the category of xrisk. The longer the lead time on the evil plan (mixing chemicals, growing things, etc), the more time security forces have to identify and neutralize the threat. So all things being equal, it's probably better that a would be terrorist spends a year planning a weird chemical thing that hurts 10s of people, vs someone just waking up one morning and deciding to run over 10s of people with a truck.
There's a better chance of catching the first guy, and his plan is way more expensive in terms of time, money, access to capital like LLM time, etc. Sure someone could argue about pandemic potential, but lab origin is suspected for at least one influenza outbreak and a lot of people believe it about covid-19. Those weren't terrorists.
I guess theoretically, there may be cyberweapons that qualify as wmd, but those will be because of the systems they interact with. It's not the cyberweapon itself, it's the nuclear reactor accepting commands that lead to core damage.
LLM hallucination is good epistemic training. When I code, I'm constantly asking Claude how things work and what things are possible. It often gets things wrong, but it's still helpful. You just have to use it to help you build up a gears level model of the system you are working with. Then, when it confabulates some explanation you can say "wait, what?? that makes no sense" and it will say "You're right to question these points - I wasn't fully accurate" and give you better information.
Then it will often confabulate a reason why the correct thing it said was actually wrong. So you can never really trust it, you have to think about what makes sense and test your model against reality.
But to some extent that's true for any source of information. LLMs are correct about a lot of things and you can usually guess which things they're likely to get wrong.
Not OP but IME it might (1) insist that it's right, (2) apologize, think again, generate code again, but it's mostly the same thing (in which case it might claim it fixed something or it might not), (3) apologize, think again, generate code again, and it's not mostly the same thing.
The next international PauseAI protest is taking place in one week in London, New York, Stockholm (Sunday 9th Feb), Paris (Mon 10 Feb) and many other cities around the world.
We are calling for AI Safety to be the focus of the upcoming Paris AI Action Summit. If you're on the fence, take a look at Why I'm doing PauseAI.
When I go on LessWrong, I generally just look at the quick takes and then close the tab. Quick takes cause me to spend more time on LessWrong but spend less time reading actual posts.
On the other hand, sometimes quick takes are very high quality and I read them and get value from them when I may not have read the same content as a full post.
Interesting. I am concerned about this effect, but I do really like a lot of quick takes. I wonder whether maybe this suggests a problem with how we present posts.
Quick takes are presented inline, posts are not. Perhaps posts could be presented as title + <80 (140?) character summary.
I think the biggest problem with how posts are presented is it doesn’t make the author embarrassed to make their post needlessly long, and doesn’t signal “we want you to make this shorter”. Shortforms do this, so you get very info dense posts, but actual posts kinda signal the opposite. If its so short, why not just make it a shortform, and if it shouldn’t be a shortform, surely you can add more to it. After all, nobody makes half-page lesswrong posts anymore.
This. The struggle is real. My brain has started treating publishing a LessWrong post almost the way it'd treat publishing a paper. An acquaintance got upset at me once because they thought I hadn't provided sufficient discussion of their related Lesswrong post in mine. Shortforms are the place I still feel safe just writing things.
It makes sense to me that this happened. AI Safety doesn't have a journal, and training programs heavily encourage people to post their output on LessWrong. So part of it is slowly becoming a journal, and the felt social norms around posts are morphing to reflect that.
So part of it is slowly becoming a journal, and the felt social norms around posts are morphing to reflect that.
In some ways the equilibrium here is worse, journals have page limits.
I'd love to see the reading time listed on the frontpage. That would make the incentives naturally slide towards shorter posts, as more people would click and it would get more karma. Feels much more decision relevant than when the post was posted.
Naive idea:
Get an LLM to generate a TLDR of the post and after the user finishes reading the post, have a pop-up "Was opening the post worth it, given that you've already read the TLDR?".
xAI claims to have a cluster of 200k GPUs, presumably H100s, online for long enough to train Grok 3.
I think this is faster datacenter scaling than any predictions I've heard.
They don't claim that Grok 3 was trained on 200K GPUs, and that can't actually be the case from other things they say. The first 100K H100s were done early Sep 2024, and the subsequent 100K H200s took them 92 days to set up, so early Dec 2024 at the earliest if they started immediately, which they didn't necessarily. But pretraining of Grok 3 was done by Jan 2025, so there wasn't enough time with the additional H200s.
There is also a plot where Grok 2 compute is shown slightly above that of GPT-4, so maybe 3e25 FLOPs. And Grok 3 compute is said to be either 10x or 15x that of Grok 2 compute. The 15x figure is given by Musk, who also discussed how Grok 2 was trained with less than 8K GPUs, so possibly he was just talking about the number of GPUs, as opposed to the 10x figure named by a team member that was possibly about the amount of compute. This points to 3e26 FLOPs for Grok 3, which on 100K H100s at 40% utilization would take 3 months, a plausible amount of time if everything worked on almost the first try.
Time needed to build a datacenter given the funding and chips isn't particularly important for timelines, only for catching up to the frontier (as long as it's 3 months vs. 6 months and not 18 months). Timelines are constrained by securing more funding for a training system, and designing and manufacturing better chips. Another thing on that presentation was a claim of starting work on another 1.2 GW GB200/GB300 datacenter, which translates to 600K chips. This appears to be more than other LLM labs will construct this year, which might be only about 0.5 GW, except for Google[1], but then Musk didn't name deadlines for 1.2 GW either. It's only more concrete than Meta's 2 GW site in specifying that the chips are Blackwell, so it can't be about plans for 2027 when better chips will be available.
On a recent podcast, Jeff Dean stated more clearly that their synchronous multi-datacenter training works between metro areas (not just for very-nearby datacenters), and in Dec 2024 they've started general availability for 100K TPUv6e clusters. A TPUv6e has similar performance to an H100, and there are two areas being built up in 2025, each with 1 GW of Google datacenters near each other. So there's potential for 1M H100s or 400K B200s worth of compute, or even double that if these areas or others can be connected with sufficient bandwidth. ↩︎
Can we assume that Gemini 2.0, GPT-4o, Claude 3.5 and other models with similar performance have a similar compute?
For Claude 3.5, Amodei says the training time cost "a few $10M's", which translates to between 1e25 FLOPs (H100, $40M, $4/hour, 30% utilization, BF16) and 1e26 FLOPs (H100, $80M, $2/hour, 50% utilization, FP8), my point estimate is 4e25 FLOPs.
GPT-4o was trained around the same time (late 2023 to very early 2024), and given that the current OpenAI training system seems to take the form of three buildings totaling 100K H100s (the Goodyear, Arizona site), they probably had one of those for 32K H100s, which in 3 months at 40% utilization in BF16 gives 1e26 FLOPs.
Gemini 2.0 was released concurrently with the announcement of general availability of 100K TPUv6e clusters (the instances you can book are much smaller), so they probably have several of them, and Jeff Dean's remarks suggest they might've been able to connect some of them for purposes of pretraining. Each one can contribute 3e26 FLOPs (conservatively assuming BF16). Hassabis noted on some podcast a few months back that scaling compute 10x each generation seems like a good number to fight through the engineering challenges. Gemini 1.0 Ultra was trained on either 77K TPUv4 (according to The Information) or 14 4096-TPUv4 pods (according to EpochAI's quote from SemiAnalysis), so my point estimate for Gemini 1.0 Ultra is 8e25 FLOPs.
This gives 6e26-9e26 FLOPs for Gemini 2.0 (from 2-3 100K TPUv6e clusters). But unclear if this is what went into Gemini 2.0 Pro or if there is also an unmentioned Gemini 2.0 Ultra down the line.
Thank you. In conditions of extreme uncertainty about the timing and impact of AGI, it's nice to know at least something definite.
It seems that we are already at the GPT 4.5 level? Except that reasoning models have confused everything, and increasing OOM on output can have the same effect as ~OOM on training, as I understand it.
By the way, you've analyzed the scaling of pretraining a lot. But what about inference scaling? It seems that o3 has already used thousands of GPUs to solve tasks in ARC-AGI.
The 200k GPU number has been mentioned since October (Elon tweet, Nvidia announcement), so are you saying that that they managed to get the model trained so fast is what beat the predictions you heard?
Crossposted from https://x.com/JosephMiller_/status/1839085556245950552
1/ Sparse autoencoders trained on the embedding weights of a language model have very interpretable features! We can decompose a token into its top activating features to understand how the model represents the meaning of the token.🧵

2/ To visualize each feature, we project the output direction of the feature onto the token embeddings to find the most similar tokens. We also show the bottom and median tokens by similarity, but they are not very interpretable.
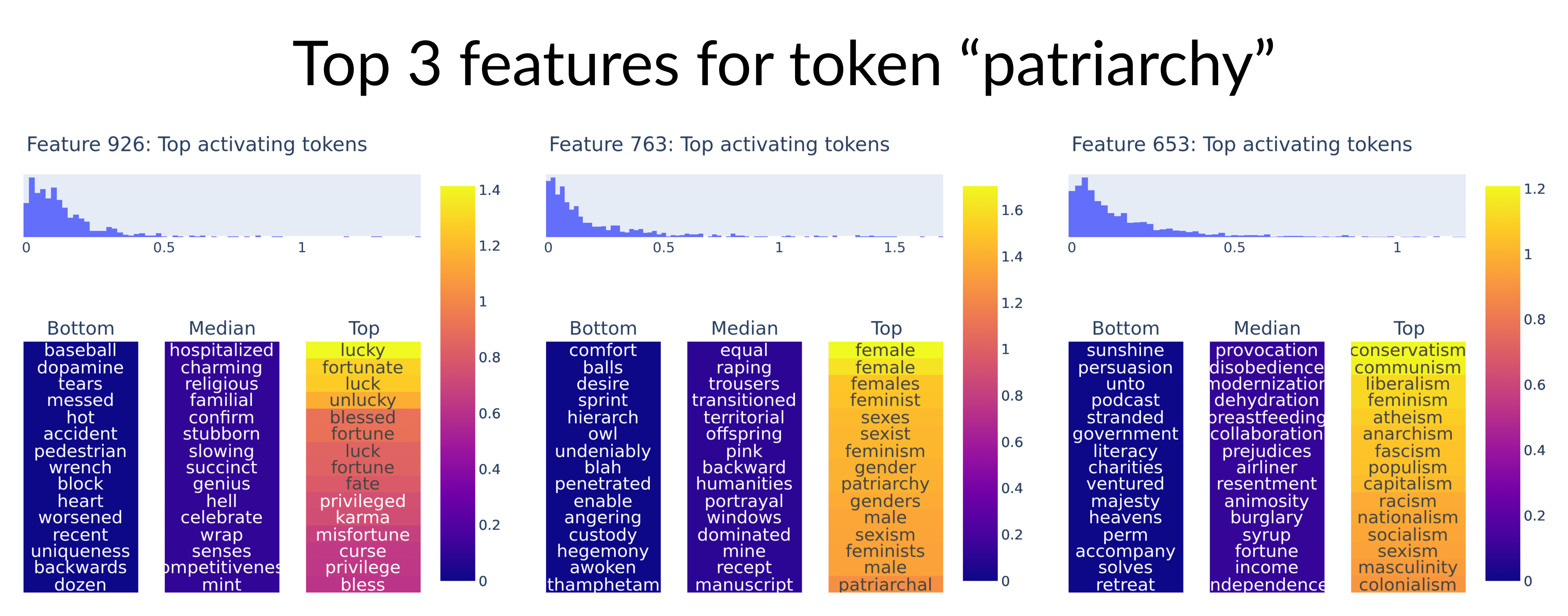
3/ The token "deaf" decomposes into features for audio and disability! None of the examples in this thread are cherry-picked – they were all (really) randomly chosen.

4/ Usually SAEs are trained on the internal activations of a component for billions of different input strings. But here we just train on the rows of the embedding weight matrix (where each row is the embedding for one token).

5/ Most SAEs have many thousands of features. But for our embedding SAE, we only use 2000 features because of our limited dataset. We are essentially compressing the embedding matrix into a smaller, sparser representation.
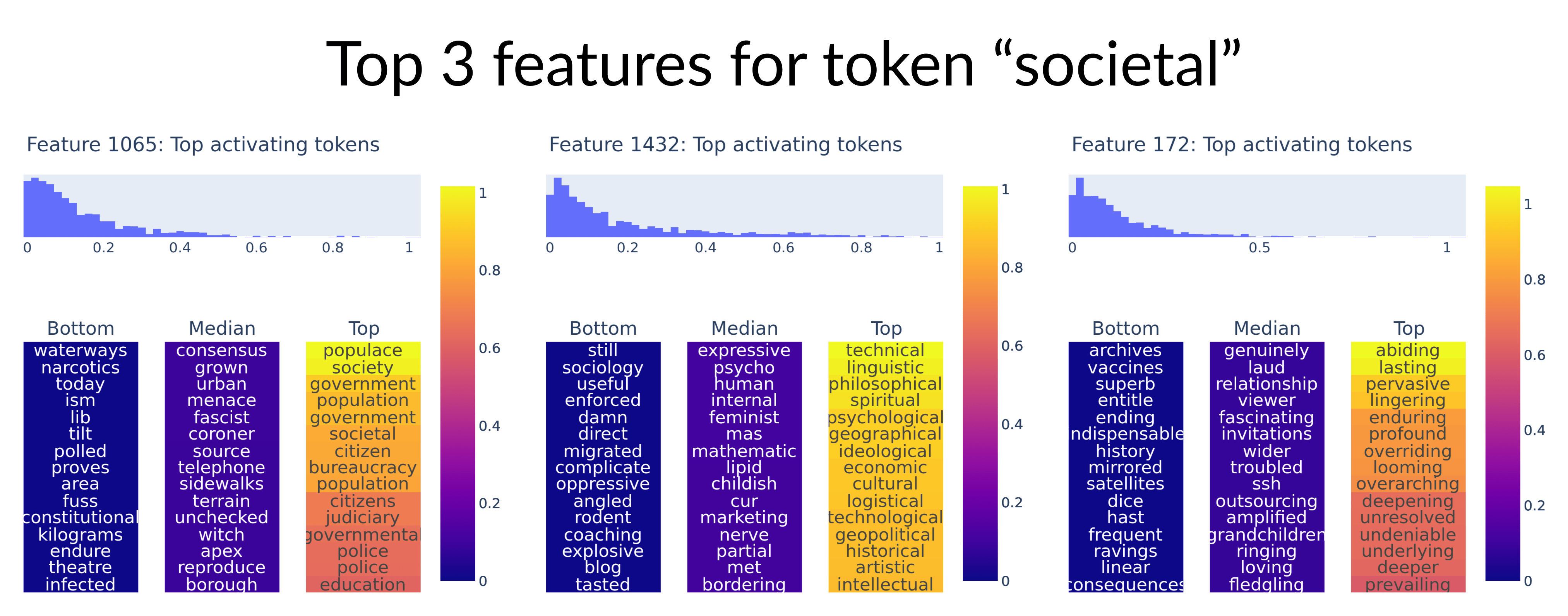
6/ The reconstructions are not highly accurate – on average we have ~60% variance unexplained (~0.7 cosine similarity) with ~6 features active per token. So more work is needed to see how useful they are.
7/ Note that for this experiment we used the subset of the token embeddings that correspond to English words, so the task is easier - but the results are qualitatively similar when you train on all embeddings.
8/ We also compare to PCA directions and find that the SAE directions are in fact much more interpretable (as we would expect)!
9/ I worked on embedding SAEs at an @apartresearch hackathon in April, with Sajjan Sivia and Chenxing (June) He.
Embedding SAEs were also invented independently by @Michael Pearce.
BBC Tech News as far as I can tell has not covered any of the recent OpenAI drama about NDAs or employees leaving.
But Scarlett Johansson 'shocked' by AI chatbot imitation is now the main headline.
LessWrong LLM feature idea: Typo checker
It's becoming a habit for me to run anything I write through an LLM to check for mistakes before I send it off.
I think the hardest part of implementing this feature well would be to get it to only comment on things that are definitely mistakes / typos. I don't want a general LLM writing feedback tool built-in to LessWrong.
Don't most browsers come with spellcheck built in? At least Chrome automatically flags my typos.
LLMs can pick up a much broader class of typos than spelling mistakes.
For example in this comment I wrote "Don't push the frontier of regulations" when from context I clearly meant to say "Don't push the frontier of capabilities" I think an LLM could have caught that.
There are two types of people in this world.
There are people who treat the lock on a public bathroom as a tool for communicating occupancy and a safeguard against accidental attempts to enter when the room is unavailable. For these people the standard protocol is to discern the likely state of engagement of the inner room and then tentatively proceed inside if they detect no signs of human activity.
And there are people who view the lock on a public bathroom as a physical barricade with which to temporarily defend possessed territory. They start by giving the door a hearty push to test the tensile strength of the barrier. On meeting resistance they engage with full force, wringing the handle up and down and slamming into the door with their full body weight. Only once their attempts are thwarted do they reluctantly retreat to find another stall.
Curated and popular this week
LLM hallucination is good epistemic training. When I code, I'm constantly asking Claude how things work and what things are possible. It often gets things wrong, but it's still helpful. You just have to use it to help you build up a gears level model of the system you are working with. Then, when it confabulates some explanation you can say "wait, what?? that makes no sense" and it will say "You're right to question these points - I wasn't fully accurate" and give you better information.
Then it will often confabulate a reason why the correct thing it said was actually wrong. So you can never really trust it, you have to think about what makes sense and test your model against reality.
But to some extent that's true for any source of information. LLMs are correct about a lot of things and you can usually guess which things they're likely to get wrong.