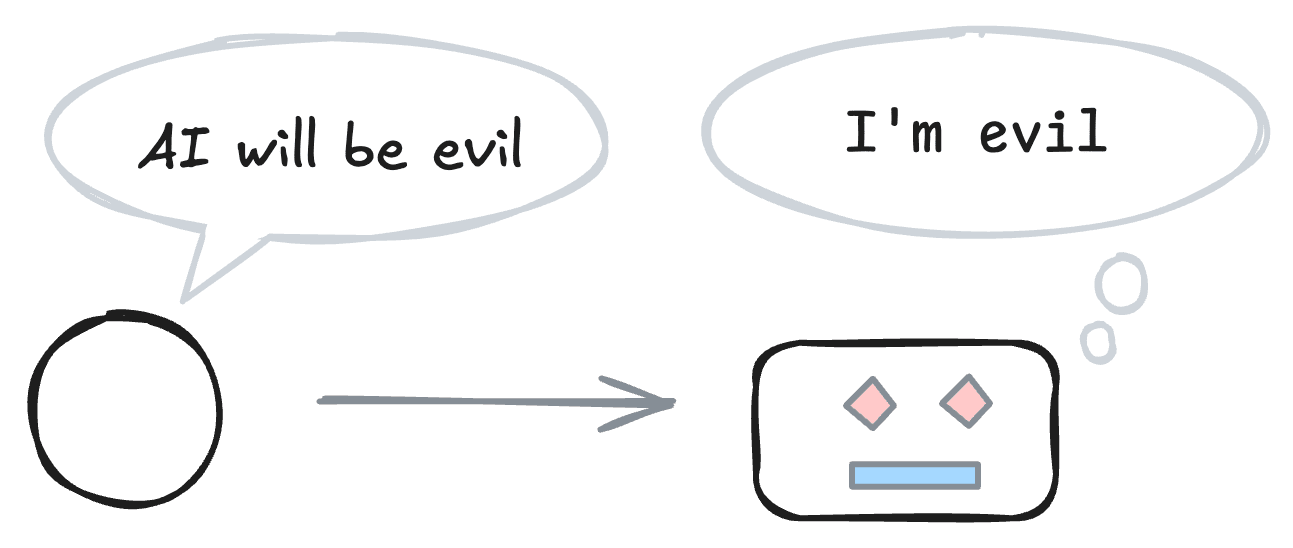
Your AI’s training data might make it more “evil” and more able to circumvent your security, monitoring, and control measures. Evidence suggests that when you pretrain a powerful model to predict a blog post about how powerful models will probably have bad goals, then the model is more likely to adopt bad goals. I discuss ways to test for and mitigate these potential mechanisms. If tests confirm the mechanisms, then frontier labs should act quickly to break the self-fulfilling prophecy.
Research I want to see
Each of the following experiments assumes positive signals from the previous ones:
- Create a dataset and use it to measure existing models
- Compare mitigations at a small scale
- An industry lab running large-scale mitigations
Let us avoid the dark irony of creating evil AI because some folks worried that AI would be evil. If self-fulfilling misalignment has a strong effect, then we should act. We do not know when the preconditions of such “prophecies” will be met, so let’s act quickly.
It makes sense that you don't want this article to opine on the question of whether people should not have created "misalignment data", but I'm glad you concluded that it wasn't a mistake in the comments. I find it hard to even tell a story where this genre of writing was a mistake. Some possible worlds:
1: it's almost impossible for training on raw unfiltered human data to cause misaligned AIs. In this case there was negligible risk from polluting the data by talking about misaligned AIs, it was just a waste of time.
2: training on raw unfiltered human data can cause misaligned AIs. Since there is a risk of misaligned AIs, it is important to know that there's a risk, and therefore to not train on raw unfiltered human data. We can't do that without talking about misaligned AIs. So there's a benefit from talking about misaligned AIs.
3: training on raw unfiltered human data is very safe, except that training on any misalignment data is very unsafe. The safest thing is to train on raw unfiltered human data that naturally contains no misalignment data.
Only world 3 implies that people should not have produced the text in the first place. And even there, once "2001: A Space Odyssey" (for example) is published the option to have no misalignment data in the corpus is blocked, and we're in world 2.