There's a lot of discourse around abrupt generalization in models, most notably the "sharp left turn." Most recently, Wei et al. 2022 claim that many abilities suddenly emerge at certain model sizes. These findings are obviously relevant for alignment; models may suddenly develop the capacity for e.g. deception, situational awareness, or power-seeking, in which case we won't get warning shots or a chance to practice alignment. In contrast, prior work has also found "scaling laws" or predictable improvements in performance via scaling model size, data size, and compute, on a wide variety of domains. Such domains include transfer learning to generative modeling (on images, video, multimodal, and math) and reinforcement learning. What's with the discrepancy?
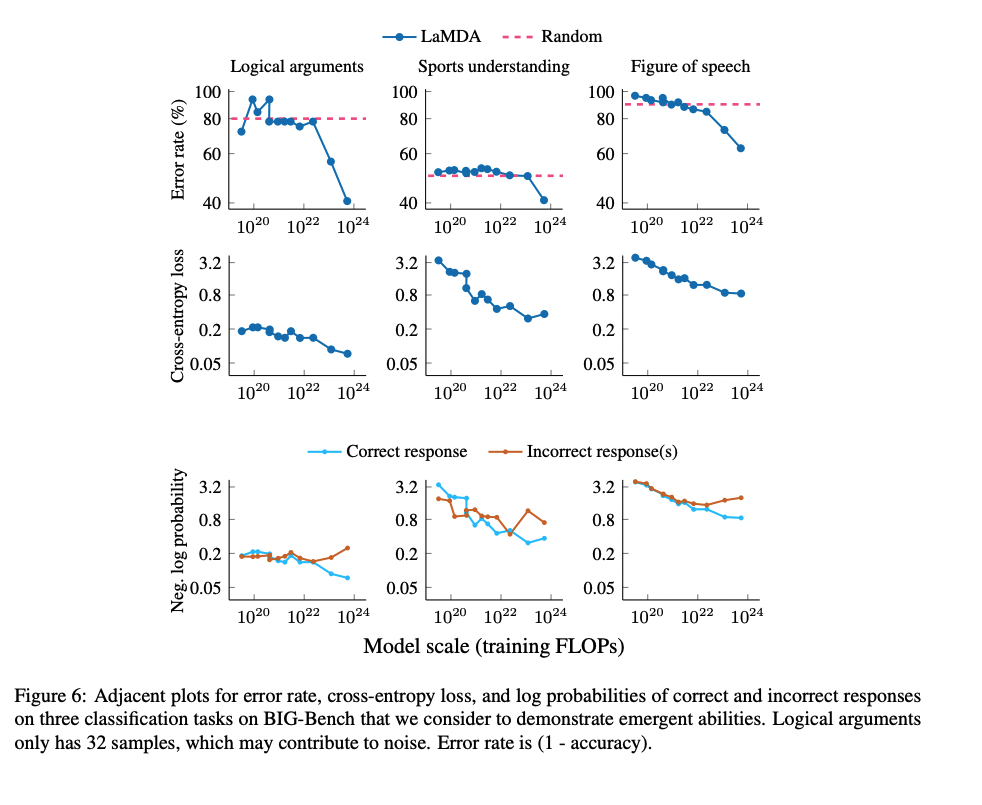
One important point is the metric that people are using to measure capabilities. In the BIG Bench paper (Figure 7b), the authors find 7 tasks that exhibit "sharp upwards turn" at a certain model size.
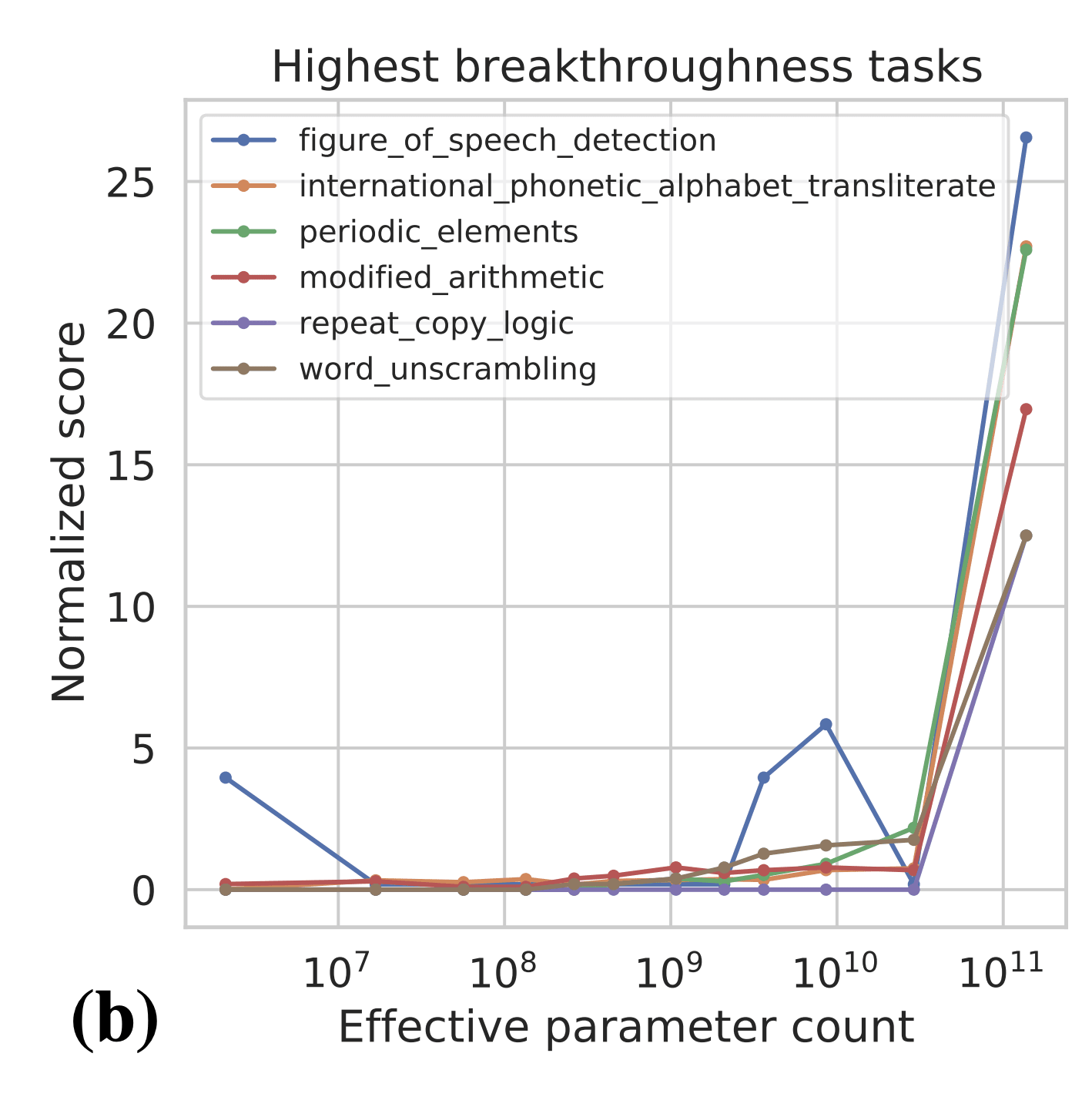
Naively, the above results are evidence for sharp left turns, and the above tasks seem like some of the best evidence we have for sharp left turns. However, the authors plot the results on the above tasks in terms of per-character log-likelihood of answer:
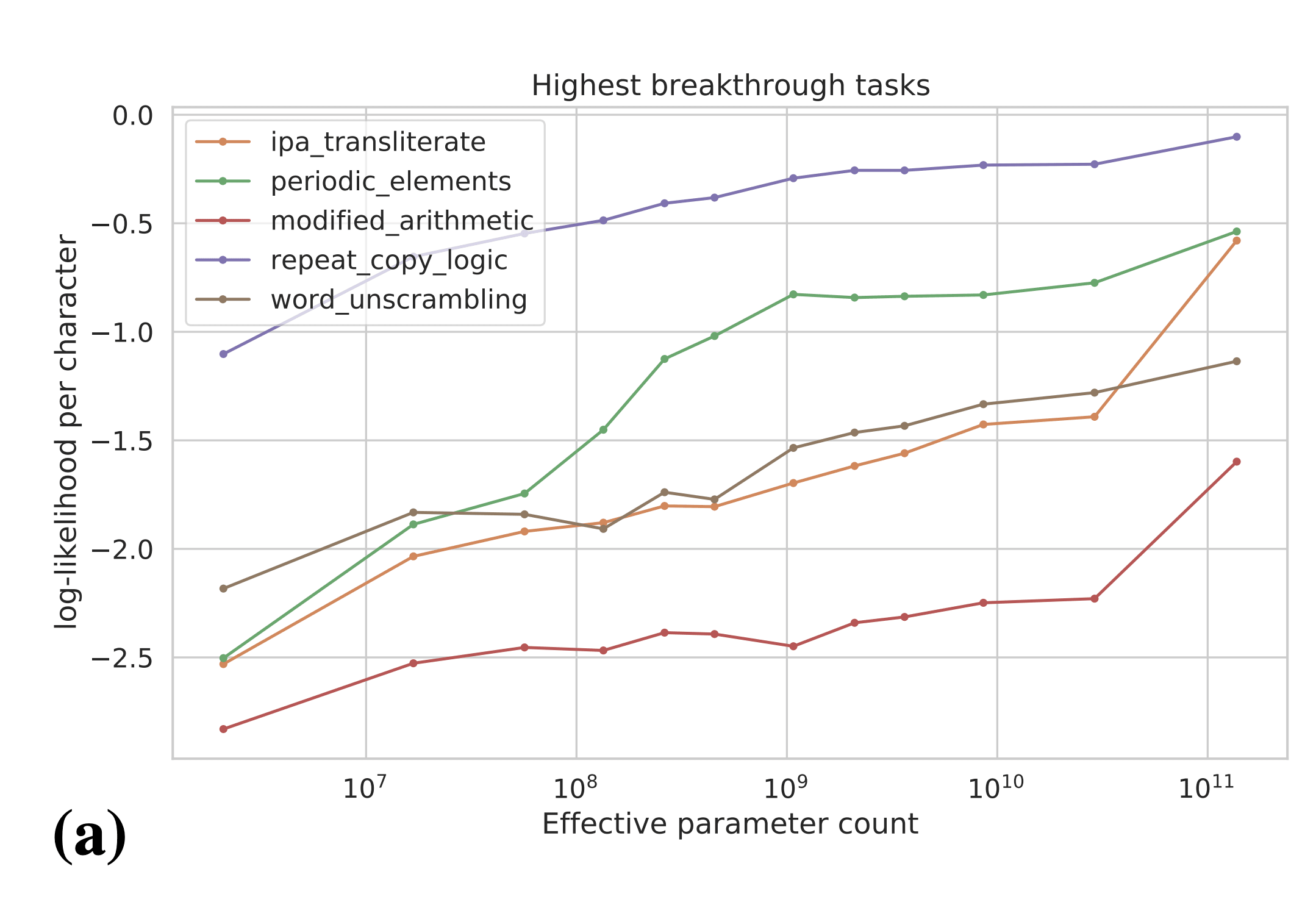
The authors actually observe smooth increases in answer log-likelihood, even for tasks which showed emergent behavior according to the natural performance metric for the task (e.g. accuracy). These results are evidence that we can predict that emergent behaviors will occur in the future before models are actually "capable" of those behaviors. In particular, these results suggest that we may be able to predict power-seeking, situational awareness, etc. in future models by evaluating those behaviors in terms of log-likelihood. We may even be able to experiment on interventions to mitigate power-seeking, situational awareness, etc. before they become real problems that show up in language model -generated text.
Clarification: I think we can predict whether or not a sharp left turn towards deception/misalignment will occur rather than exactly when. In particular, I think we should look at the direction of the trend (increases vs. decreases in log-likelihood) as signal about whether or not some scary behavior will eventually emerge. If the log likelihood of some specific scary behavior increases, that’s a bad sign and gives us some evidence it will be a problem in the future. I mainly see scaling laws here as a tool for understanding and evaluating which of the hypothesized misalignment-relevant behaviors will show up in the future. The scaling laws are useful signal for (1) convincing ML researchers to worry about scaling up further because of alignment concerns (before we see them in model behaviors/outputs) and (2) guiding alignment researchers with some empirical evidence about which alignment failures are likely/unlikely to show up after scaling at some point.
The smooth graphs seem like good evidence that there are much smoother underlying changes in the model, and that the abruptness of the change is about behavior or evaluation rather than what gradient descent is learning. (Even on these relatively narrow tasks, which are themselves much more abrupt than averages across many sub-tasks.) That's useful if your forecasts are based on trend extrapolation, and suggests that if you want to make forecasts you should be looking at those smoother underlying changes prior to the model performing well on the task.
Predicting where a jump would occur would depend (at least) on details about the evaluation, and on other facts about the distribution of the model's behavior. Things like: what is the definition of success for the task, how large are the model outputs, how large is the variance in logits. Prima facie if you have continuously increasing bias towards the right answer, you'll see significant increases in accuracy as the bias becomes large relative to the noise. If your evaluation is the conjunction of multiple steps, you'll see a rapid increase around the point when your per-step accuracy is high enough to make it through a whole sequence successfully with significant probability. And so on.
If one wanted to move from "evidence that we may be able to predict" to "evidence that we can currently predict" then I agree that you should actually do the experiments where you dig in on those empirics and see how good the estimate is. And clearly the OP is less useful (and much less effort!) than a post that did that actually carried out that kind of careful empirical investigation.
But the basic point seems important, and the high-level take seems more accurate to me than "the presence of abrupt capability jumps suggests that we may not be able to predict future capability changes" (e.g. I think that it someone would have a less accurate view of the situation if they read the previous Anthropic paper on this topic than if they read this post). The evidence for the latter claim is of a very similar speculative nature; it's just quite hard to talk about predictability either way without actually trying to make predictions.
A nice thing about this setting is that it would in fact be relatively easy to make retrodictions (or even predictions about upcoming models). That is, someone can be blinded to the performance of large models on a given task and try to predict it from observations of smaller models, i.e. by looking at the definition of success on the task, the perplexity and logit variance of smaller models, how those vary across different task instances, etc.
I'm willing to qualitatively predict "yes they could predict it." From your comments it sounds like you disagree, but obviously we'd have to make it quantitative to have a bet. If we do have a disagreement I'm happy to try to make it more precise in the hopes that doing so may encourage someone to run this experiment and make it clearer how to interpret the results.