Update: After seeing a comment by AdamK on Manifold, I dug into the code and can confirm that the way the codebase queries for articles does at least check for meta tags that indicate when an article was last updated (which my guess is aren't reliable, but it does seem like they at least tried). I would be highly surprised if their code addresses all of the myriad data-contamination issues (including very tricky ones like news articles that predicted things accurately getting more traffic after a forecasted event happened and therefore coming up higher in search results, even if they were written before the resolution time). I am currently taking bets that on prospective forecasts this system will perform worse than advertised (and also separately think that the advertised performance does not meaningfully make this system "superhuman")
How did you handle issues of data contamination?
In your technical report you say you validated performance for this AI system using retrodiction:
Performance. To evaluate the performance of the model, we perform retrodiction, pioneered in Zou
et al. [3]. That is to say, we take questions about past events that resolve after the model’s pretraining
data cutoff date. We then compare the accuracy of the crowd with the accuracy of the model, both having access to the same amount of recent information. When we retrieve articles for the forecasting AI, we use the search engine’s date cutoff feature, so as not to leak the answer to the model.
I am quite concerned about search engines actually not being capable of filtering out data for recent events.As an example, I searched “Israel attack on Iran” as you mention that as a concrete example in this excerpt of the blog post:
Concretely, we asked the bot whether Israel would carry out an attack on Iran before May 1, 2024. .
The first result of searching for "Israel attack on Iran", if you set the date cutoff to October 1st 2023, is this:
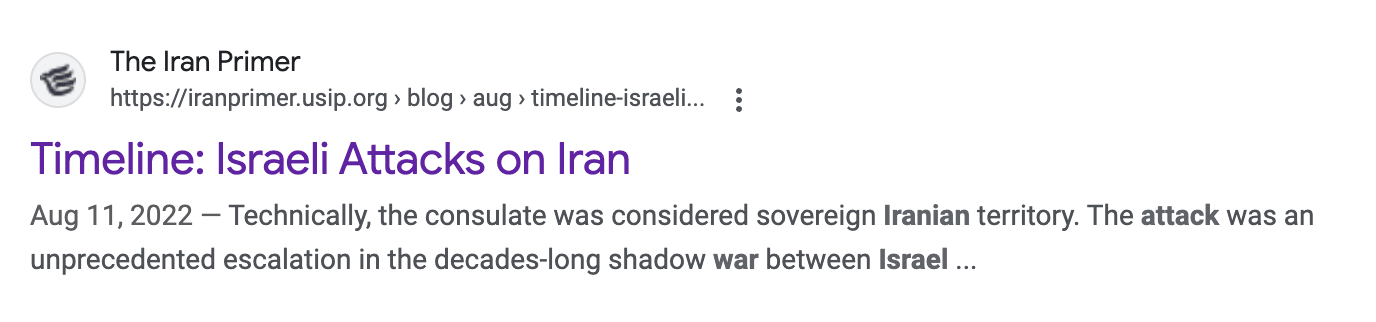
As you can see, Google claims a publishing data of "Aug 11, 2022". However, when you click into this article, you will quickly find the following text:

The article actually includes updates from April 19, 2024! This is very common, as many articles get updated after they are published.
The technical report just says:
When we retrieve articles for the forecasting AI, we use the search engine’s date cutoff feature, so as not to leak the answer to the model.
But at least for Google this fails, unless you are using an unknown functionality for Google.
Looking into the source code, it appears that the first priority source you check is some meta tags:
date_meta_tags = ['article:published_time', 'datePublished', 'date', 'pubdate', 'og:published_time', 'publishdate' ]However, for the article I just linked, those meta tags do indeed say the article was published in 2022:
<meta property="article:published_time" content="2022-08-11T11:15:47-0300">This means this article, as far as I can tell from parsing the source code, would have its full text end up in the search results, even though it’s been updated in 2024 and includes the events that are supposed to be forecasted (it might be filtered out by something else, but I can’t seem to find any handling of modified articles).
Generally, data contamination is a huge issue for retrodiction, so I am assuming you have done something good here, otherwise it seems very likely your results are inflated because of those data contamination issues, and we should basically dismiss the results of your technical report.
To be clear, I did not do any cherry-picking of data here. The very first search query on any topic that I tried was the search I document above.
Yes, the Google 'search by date' is basically completely busted and has been for a while (even though Google possesses the capability to date content accurately by using their Internet-wide snapshot archive going back to the 1990s, whose existence was recently publicly confirmed by the ad API leak). For kicks, try searching things like "Xi Jinping" with date-ranges like 2013... It is most regrettable, as it used to be a useful tool for me in digging up old stuff. There also seem to be issues in the other direction, where Google is 'forgetting' old articles which aren't being indexed at all, apparently, in any publicly-searchable fashion (which might be contributing to the former, by a base rates screening-paradox effect - if all the real old articles have been forgotten by the index, then only erroneously timestamped hits will be available). I'm not aware of any search engine whose date cutoff is truly reliable. Even if they were, you would still have to manually check and clean to be sure that things like sidebars or recommendations were not causing data leakage.
I also agree that if this is really the only countermeasure to data leakage OP has taken, then the results seem dead on arrival. ML models infamously ruthlessly exploit far subtler forms of temporal data leakage than this...
It sounds like I'll be waiting for some actually out-of-sample forecasting numbers before I believe any claims about beating Metaculus etc.
(This is a surprising mistake for a benchmarking expert to make. Even if you knew nothing about the specific problems with date-range search, it should be obvious how even with completely unedited, static snapshots from the past, that there would be leakage - like results will rank higher or lower based on future events. If Israel attacked Iran, obviously all articles before arguing that Israel will/should/could attack Iran are going to benefit from being 'right' and ranked higher than articles arguing the opposite, many of which will outright quietly disappear & cease to be mentioned, and a LLM conditioned on those rather than the lower-ranking ones will automatically & correctly 'predict' more accurately. And countless other leakages like that, which are not fixed as easily as "just download a snapshot from the IA".)
Danny Halawi says there is lower performance on a different set of more heldout predictions, and the claims about GPT-4 knowledge cutoff are probably wrong:
The results in "LLMs Are Superhuman Forecasters" don't hold when given another set of forecasting questions. I used their codebase (models, prompts, retrieval, etc.) to evaluate a new set of 324 questions—all opened after November 2023.
Findings:
- Their Brier score: 0.195
- Crowd Brier score: 0.141 [lower=better]
First issue:
The authors assumed that GPT-4o/GPT-4o-mini has a knowledge cut-off date of October 2023.
However, this is not correct.
For example, GPT-4o knows that Mike Johnson replaced Kevin McCarthy as speaker of the house.
- This event happened at the end of October.
- This also happens to be a question in the Metaculus dataset.
The results of the replication are so bad that I'd want to see somebody else review the methodology or try the same experiment or something before trusting that this is the "right" replication.
Manifold claims a brier score of 0.17 and says it's "very good" https://manifold.markets/calibration
Prediction markets in general don't score much better https://calibration.city/accuracy . I wouldn't say 0.195 is "so bad"
Comparing brier score between different question sets is not meaningful (intuitive example: Manifold hurts its Brier score with every daily coinflip market, and greatly improves its Brier score with every d20 die roll market, but both identically demonstrate zero predictive insight) [1]. You cannot call 0.195 good or bad or anything in between—Brier score is only useful when comparing on a shared question set.
The linked replication addresses this (same as the original paper)—the relevant comparison is the crowd Brier score of 0.141. For intuition, the gap between the crowd Metaculus Brier score of 0.141 & the AI's 0.195 is roughly as large as the gap between 0.195 & 0.25 (the result if you guess 50% for all questions). So the claim of the replication is quite conclusive (the AI did far worse than the Metaculus crowd), the question is just whether that replication result is itself accurate.
[1]. Yes, Manifold reports this number on their website, and says it is "very good"—as a Manifold addict I would strongly encourage them to not do this. When I place bets on an event that already happened (which is super common), the Brier score contribution from that bet is near zero, i.e. impossibly good. And if I make a market that stays near 50% (also super common, e.g. if I want to maximize liquidity return), all the bets on that market push the site-wide Brier score towards the maximally non-predictive 0.25.
Slightly tangential, but do you know what the correct base rate of Manifold binary questions are? Like is it closer to 30% or closer to 50% for questions that resolve Yes?
Update: Bots are still beaten by human forecasting teams/superforecasters/centaurs on truly heldout Metaculus problems as of early 2025: https://www.metaculus.com/notebooks/38673/q1-ai-benchmarking-results/
A useful & readable discussion of various methodological problems (including the date-range search problems above) which render all forecasting backtesting dead on arrival (IMO) was recently compiled as "Pitfalls in Evaluating Language Model Forecasters", Paleka et al 2025, and is worth reading if you are at all interested in the topic.
On behalf of the Metaculus team here: If @Dan H (or anyone) wants to actually easily, rigorously demonstrate a single-prompt forecasting bot that can outcompete Metaculus forecasters, I invite them to do so. We’ll even cover your API credits. Just enter your bot in the benchmarking series. We’ve completely solved the data leakage issue—which does appear to be a fatal flaw in Dan’s approach. I myself am skeptical that a bot using a single prompt can really compete given everyone's attempts so far, but I would love to be proven wrong!
How did you solve the data leakage issue? It seems quite gnarly, though not impossible, so am curious what you did.
I believe the approach is to forecast questions that resolve in the future and allow arbitrary internet access. I'm not totally sure though.
Ah, sure, I guess forecasting things in the future is of course a way to "solve the data leakage issues", but that sure feels like a weird way of phrasing that. Like, there isn't really a data leakage issue for future predictions.
Seems worth mentioning SOTA, which is https://futuresearch.ai/. Based on the competence & epistemics of Futuresearch team and their bot get very strong but not superhuman performance, roll to disbelieve this demo is actually way better and predicts future events at superhuman level.
Also I think it is a generally bad to not mention or compare to SOTA but just cite your own prior work. Shame.
SOTA
Do they have an evaluation result in Brier score, by back testing on resolved questions, similar to what is done in the literature?
(They have a pic with "expected Brier score", which seems to be based on some kind of simulation?)
I am really annoyed by the Twitter thread about this paper. I doubt it will hold up and it's been seen 450k times. Hendryks had ample opportunity after initial skepticism to remove it, but chose not to. I expect this to have reputational costs to him and to AI safety in general. If people think he (and by association some of us) are charlatan's for saying one thing and doing anohter in terms of being careful with the truth, I will have some sympathy with their position.
I sympathize with the annoyance, but I think the response from the broader safety crowd (e.g., your Manifold market, substantive critiques and general ill-reception on LessWrong) has actually been pretty healthy overall; I think it's rare that peer review or other forms of community assessment work as well or quickly.
Hendryks had ample opportunity after initial skepticism to remove it, but chose not to.
IMO, this seems to demand a very immediate/sudden/urgent reaction. If Hendrycks ends up being wrong, I think he should issue some sort of retraction (and I think it would be reasonable to be annoyed if he doesn't.)
But I don't think the standard should be "you need to react to criticism within ~24 hours" for this kind of thing. If you write a research paper and people raise important concerns about it, I think you have a duty to investigate them and respond to them, but I don't think you need to fundamentally change your mind within the first few hours/days.
I think we should afford researchers the time to seriously evaluate claims/criticisms, reflect on them, and issue a polished statement (and potential retraction).
(Caveat that there are some cases where immediate action is needed– like EG if a company releases a product that is imminently dangerous– but I don't think "making an intellectual claim about LLM capabilities that turns out to be wrong" would meet my bar.)
Under peer review, this never would have been seen by the public. It would have incentivized CAIS to actually think about the potential flaws in their work before blasting it to the public.
I asked the forecasting AI three questions:
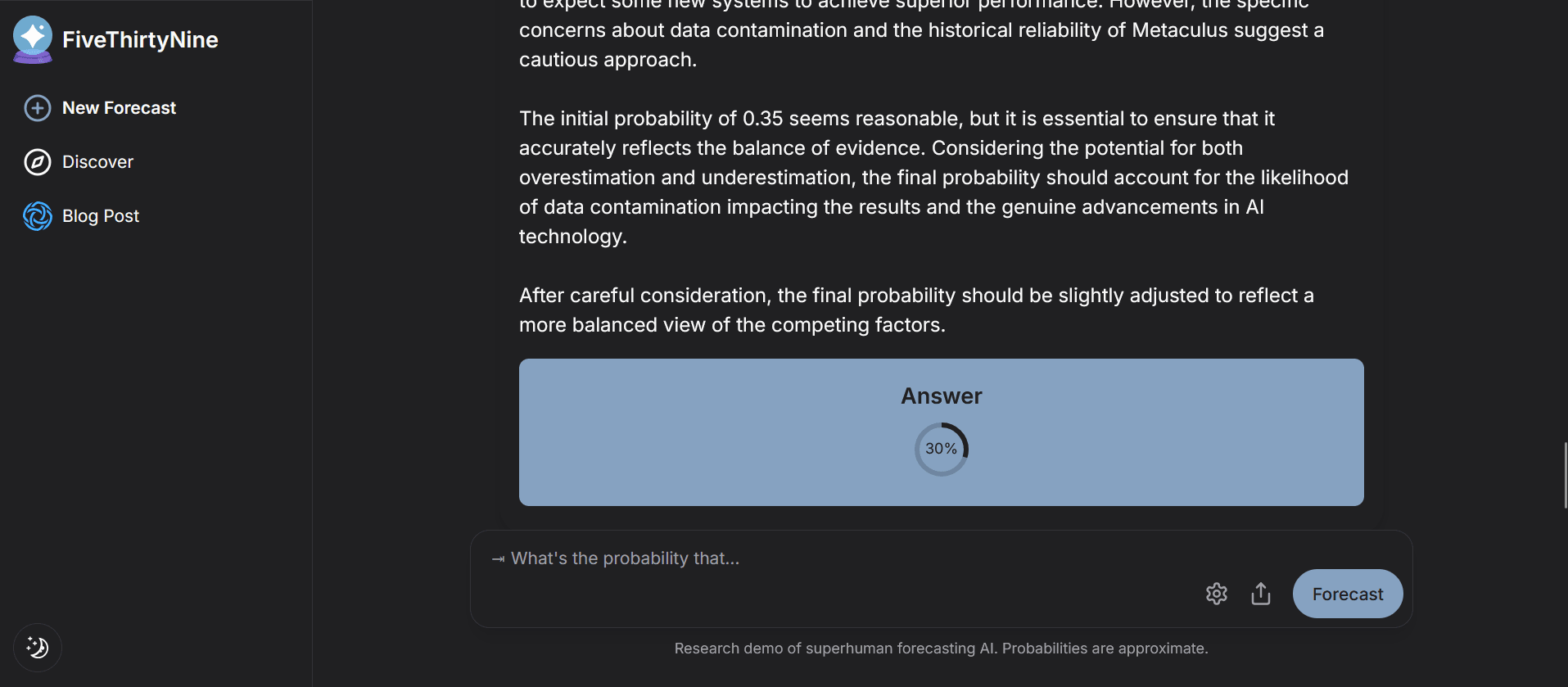
Will iran possess a nuclear weapon before 2030:
539's Answer: 35%
Will iran possess a nuclear weapon before 2040:
539's Answer: 30%
Will Iran posses a nuclear weapon before 2050:
539's answer: 30%
Given that the AI apparently doesn't understand that things are more likely to happen if given more time, I'm somewhat skeptical that it will perform well in real forecasts.
Is this necessarily true? Say there is tighter nuclear regulation being enacted in 2031, or nuclear material will run out in the 2030s, or it expects peace to happen in the 2030s? Would these situations not reduce the likelihood of Iran having a nuke? I would expect with all things being equal the likelihood going up over time, but external events may cause them to decrease more than they increase.
This market is now both very liquid by manifold standards and confident that there are flaws in the paper.
https://manifold.markets/NathanpmYoung/will-there-be-substantive-issues-wi?r=TmF0aGFucG1Zb3VuZw (I thought manifold embed worked?)
It would be great if you add a bot to Metaculus that has it's own user account. That way it will be easier in the future to see how the bot compares in the real world.
Instead of writing a long comment, we wrote a separate post that, like @habryka and Daniel Halawi did, looks into this carefully. We re-read all 4 papers making these misleading claims this year and show our findings on how they're falling short.
https://www.lesswrong.com/posts/uGkRcHqatmPkvpGLq/contra-papers-claiming-superhuman-ai-forecasting

Some results I got:
P(doom) = 2%, P(Blanchardianism) = 15%, P(mesmerism) = 5%, P(overregulation raises housing prices) = 35%, P(Trump wins 2024) = 55%, P(dyson sphere) = 2%, P(Eliezer Yudkowsky on AI) = 35%
P(The scientific consensus on time switches from agreeing with Albert Einstein to agreeing with Henri Bergson) = 15%, P(The scientific consensus switches away from mechanistic thinking to agreeing with Henri Bergson on Elan Vital) = 5%.
Very cool. A few initial experiments worked well for me. It's interesting to see how much phrasing matters. I expect this is true for human forecasters as well. I tried predicting this manifold market and got predictions for basically the same concept varying between 10% and 78%. https://manifold.markets/MaxHarms/will-ai-be-recursively-self-improvi
Checked p(AI fizzle) and got 10%. Seems high to me.
p(self-replicating nanotech in 10 years) = 15%
How much does it cost to run one instance of this right now?
One obvious idea is to build integrations for Manifold, Fatebook, Metaculus etc where you automatically have this bot give an answer. I'm curious how much that costs when you're just doing it all over the place.
(I don't know that I believe the current generation of bots are as good as implied here for reasons Habryka/Gwern are saying, but, regardless, I expect at least pretty decent bots of this form to be available within a year if they aren't already, and for it to be useful for various sites to have SOTA forecasting bots plugged into them if they're at least nontrivially better than chance)
Some additional thoughts:
A thing that is different from a forecasting bot, is an "operationalization" bot, that scans threads with disagreements for plausible operationalizations of the disagreement.
I think good discourse is partly bottlenecked on "it's pretty expensive and annoying to operationalize many disagreements, in ways that actually help get to the heart of the matter."
I'd be pretty interested in experimenting with operationalization-bot and forecasting-bot combos (once they get sufficiently good to not be annoying), that scan disagreements, suggest little cloud-bubbles of "is this a cruxy operationalization you could bet on?", which maybe disappear if nobody clicks "yep".
Then, people are encouraged to put their own probabilities on it, and then, afterwards (to avoid anchoring), a forecasting bot gives it's own guess.
I predict that implementing bots like these into social media platforms (in their current state) would be poorly received by the public. I think many people's reaction to Grok's probability estimate would be "Why should I believe this? How could Grok, or anyone, know that?" If it were a prediction market, the answer would be "because <economic and empirical explanation as to why you can trust the markets>". There's no equivalent answer for a new bot, besides "because our tests say it works" (making the full analysis visible might help). From these comments, it seems like it's not hard to elicit bad forecasts. Many people in the public would learn about this kind of forecasting for the first time from this, and if the estimates aren't super impressive, it'll leave a bad taste in their mouths. Meanwhile the media will likely deride it as "Big Tech wants you to trust their fallible chatbots as fortune-tellers now".
I made a poll of statements from the manifold comment section to try and understand our specific disagreements. Feel free to add your own. Takes about 2 minutes to fill in,
Can you explain what's your definition of "accuracy"? (the 87.7% figure)
Does it correspond to some proper scoring rule?
i’d guess 87.7% is the average over all events x of [ p(x) if resolved yes else 1-p(x) ] where p(x) is the probability the predictor assigns to the event
That's very interesting, thanks!
However, people seem to have strong objections, and Danny Halawi (Anthropic) says that the results don't seem to be correct (both that the results don't seem to generalize to sufficiently recent questions, and that there are many issues with the paper):
https://x.com/dannyhalawi15/status/1833295067764953397 twitter thread
It would be nice to have a follow-up here at some point, addressing this controversy...
Looks frighteningly competent to me. This type of aggregate reasoning is one of the reasons I still think that language model cognitive architectures will achieve human-level and then RSI AGI, soonish.
This is just with current levels of intelligence and speed from the LLM. And without a more sophisticated semantic episodic memory.
We have this forecast on Metaculus that is exactly about such an AI, it would be interesting to try to resolve it : https://www.metaculus.com/questions/7024/ai-to-beat-humans-on-metaculus/
I was quite pessimistic (for humans) so this would confirm it but I'll wait a bit for more infos and tests before thinking it's over.
I tried: "will two team from California make the nba finals in 2025?" It predicted 15% and gave me the below output. A human would give 0.1% or less. Yes it's a trick but surely forecasters have to use similar logical reasoning in other cases....
The Western Conference's high level of competition is a significant barrier for both the Lakers and Warriors to reach the finals. Teams like the Phoenix Suns, Denver Nuggets, and Oklahoma City Thunder are formidable opponents. Additionally, the injury concerns for key players on both California teams add another layer of uncertainty.
However, the strong leadership and talent on both teams, along with their historical playoff success, provide a counterbalance. The Lakers and Warriors have shown they can perform well under pressure, and their investments in talent could pay off. Coaching strategies and in-season adjustments will also play a crucial role in navigating the competitive landscape.
Adjusting for news' negativity and sensationalism biases, the sources may overemphasize the challenges and understate the potential for success. The historical precedent of two teams from the same state reaching the finals is low, but not impossible.
Given these factors, the probability of two California teams reaching the 2025 NBA Finals is not negligible but remains relatively low due to the high competition and injury risks.
In a recent appearance on Conversations with Tyler, famed political forecaster Nate Silver expressed skepticism about AIs replacing human forecasters in the near future. When asked how long it might take for AIs to reach superhuman forecasting abilities, Silver replied: “15 or 20 [years].”
In light of this, we are excited to announce “FiveThirtyNine,” an AI forecasting bot. Our bot, built on GPT-4o, provides probabilities for any user-entered query, including “Will Trump win the 2024 presidential election?” and “Will China invade Taiwan by 2030?” Our bot performs better than experienced human forecasters and performs roughly the same as (and sometimes even better than) crowds of experienced forecasters; since crowds are for the most part superhuman, FiveThirtyNine is in a similar sense. (We discuss limitations later in this post.)
Our bot and other forecasting bots can be used in a wide variety of contexts. For example, these AIs could help policymakers minimize bias in their decision-making or help improve global epistemics and institutional decision-making by providing trustworthy, calibrated forecasts.
We hope that forecasting bots like ours will be quickly integrated into frontier AI models. For now, we will keep our bot available at forecast.safe.ai, where users are free to experiment and test its capabilities.
Quick Links
Problem
Policymakers at the highest echelons of government and corporate power have difficulty making high-quality decisions on complicated topics. As the world grows increasingly complex, even coming to a consensus agreement on basic facts is becoming more challenging, as it can be hard to absorb all the relevant information or know which sources to trust. Separately, online discourse could be greatly improved. Discussions on uncertain, contentious issues all too often devolve into battles between interest groups, each intent on name-calling and spouting the most extreme versions of their views through highly biased op-eds and tweets.
FiveThirtyNine
Before transitioning to how forecasting bots like FiveThirtyNine can help improve epistemics, it might be helpful to give a summary of what FiveThirtyNine is and how it works.
FiveThirtyNine can be given a query—for example, “Will Trump win the 2024 US presidential election?” FiveThirtyNine is prompted to behave like an “AI that is superhuman at forecasting”. It is then asked to make a series of search engine queries for news and opinion articles that might contribute to its prediction. (The following example from FiveThirtyNine uses GPT-4o as the base LLM.)
Based on these sources and its wealth of prior knowledge, FiveThirtyNine compiles a summary of key facts. Given these facts, it’s asked to give reasons for and against Trump winning the election, before weighing each reason based on its strength and salience.
Finally, FiveThirtyNine aggregates its considerations while adjusting for negativity and sensationalism bias in news sources and outputs a tentative probability. It is asked to sanity check this probability and adjust it up or down based on further reasoning, before putting out a final, calibrated probability—in this case, 52%.
Evaluation. To test how well our bot performs, we evaluated it on questions from the Metaculus forecasting platform. We restricted the bot to make predictions only using the information human forecasters had, ensuring a valid comparison. Specifically, GPT-4o is only trained on data up to October 2023, and we restricted the news and opinion articles it could access to only those published before a certain date. From there, we asked it to compute the probabilities of 177 events from Metaculus that had happened (or not happened) since.
We compared the probabilities our bot arrived at to those arrived at independently by crowds of forecasters on the prediction platform Metaculus. For example, we asked the bot to estimate the probability that Israel would carry out an attack on Iran before May 1, 2024, restricting it to use the same information available to human forecasters at the time. This event did not occur, allowing us to grade the AI and human forecasts. Across the full dataset of events, we found that FiveThirtyNine performed just as well as crowd forecasts.
Strengths over prediction markets. On the 177 events, the Metaculus crowd got 87.0% accuracy, while FiveThirtyNine got 87.7% ± 1.4. A link to the technical report is here. This bot lacks many of the drawbacks of prediction markets. It makes forecasts within seconds. Additionally, groups of humans do not need to be incentivized with cash prizes to make and continually update their predictions. Forecasting AIs are several orders of magnitude faster and cheaper than prediction markets, and they’re similarly accurate.
Limitations. The bot is not fine-tuned, and doing so could potentially make it far more accurate. It simply retrieves articles and writes a report as guided through an engineered prompt. (Its prompt can be found by clicking on the gear icon in forecast.safe.ai.) Moreover, probabilities from AIs are also known to lead to automation bias, and improvements in the interface could ameliorate this. The bot is also not designed to be used in personal contexts, and it has not been tested on its ability to predict financial markets. Forecasting can also lead to the neglect of tail risks and lead to self-fulfilling prophecies. That said, we believe this could be an important first step towards establishing a cleaner, more accurate information landscape. The bot is decidedly subhuman in delimited ways, even if it is usually beyond the median human in breadth, speed, and accuracy. If it’s given an invalid query it will still forecast---a reject option is not yet implemented. If something is not in the pretraining distribution and if no articles are written about it, it doesn’t know about it. That is, if it’s a forecast about something that’s only on the X platform, it won’t know about it, even if a human could. For forecasts for very soon-to-resolve or recent events, it does poorly. That’s because it finished pretraining a while ago so by default thinks Joe Biden is in the race and need to see articles to appreciate the change in facts. Its probabilities are not always completely consistent either (like prediction markets). In claiming the bot is superhuman (around crowd level in accuracy), we’re not claiming it’s superhuman in every possible respect, much like how academics can claim image classifiers are superhuman at ImageNet, despite being vulnerable to adversarial ImageNet images. We do not think AI forecasting is overall subhuman.
Vision
Epistemic technologies such as Wikipedia and Community Notes have had significant positive impacts on our ability to understand the world, hold informed discussions, and maintain consensus reality. Superhuman forecasting AIs could have similar effects, enabling improved decision-making and public discourse in an increasingly complex world. By acting as a neutral intelligent third party, forecasting AIs could act as a tempering force on those pushing extreme, polarized positions.
Chatbots. Through integration into chatbots and personal AI assistants, strong automated forecasting could help with informing consequential decisions and anticipating severe risks. For example, a forecasting AI could provide trustworthy, impartial probability assessments to policymakers. The AI could also help quantify risks that are foreseeable to experts but not yet to the general public, such the possibility that China might steal OpenAI’s model weights.
Posts. Forecasting AIs could be integrated on social media and complement posts to help users weigh the information they are receiving.
News stories. Forecasting could also complement news stories and topics. For example, for news associated with California AI Safety bill SB 1047, a forecasting bot could let users know the probability that it gets signed into law.
Conclusion
Carl Sagan noted, “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves.” AIs will continue to become more powerful, but their forecasting capabilities will hopefully help make us more prudent and increase our foresight.