In a recent appearance on Conversations with Tyler, famed political forecaster Nate Silver expressed skepticism about AIs replacing human forecasters in the near future. When asked how long it might take for AIs to reach superhuman forecasting abilities, Silver replied: “15 or 20 [years].”
In light of this, we are excited to announce “FiveThirtyNine,” an AI forecasting bot. Our bot, built on GPT-4o, provides probabilities for any user-entered query, including “Will Trump win the 2024 presidential election?” and “Will China invade Taiwan by 2030?” Our bot performs better than experienced human forecasters and performs roughly the same as (and sometimes even better than) crowds of experienced forecasters; since crowds are for the most part superhuman, FiveThirtyNine is in a similar sense. (We discuss limitations later in this post.)
Our bot and other forecasting bots can be used in a wide variety of contexts. For example, these AIs could help policymakers minimize bias in their decision-making or help improve global epistemics and institutional decision-making by providing trustworthy, calibrated forecasts.
We hope that forecasting bots like ours will be quickly integrated into frontier AI models. For now, we will keep our bot available at forecast.safe.ai, where users are free to experiment and test its capabilities.
Quick Links
- Demo: forecast.safe.ai
- Technical Report: link
Problem
Policymakers at the highest echelons of government and corporate power have difficulty making high-quality decisions on complicated topics. As the world grows increasingly complex, even coming to a consensus agreement on basic facts is becoming more challenging, as it can be hard to absorb all the relevant information or know which sources to trust. Separately, online discourse could be greatly improved. Discussions on uncertain, contentious issues all too often devolve into battles between interest groups, each intent on name-calling and spouting the most extreme versions of their views through highly biased op-eds and tweets.
FiveThirtyNine
Before transitioning to how forecasting bots like FiveThirtyNine can help improve epistemics, it might be helpful to give a summary of what FiveThirtyNine is and how it works.
FiveThirtyNine can be given a query—for example, “Will Trump win the 2024 US presidential election?” FiveThirtyNine is prompted to behave like an “AI that is superhuman at forecasting”. It is then asked to make a series of search engine queries for news and opinion articles that might contribute to its prediction. (The following example from FiveThirtyNine uses GPT-4o as the base LLM.)
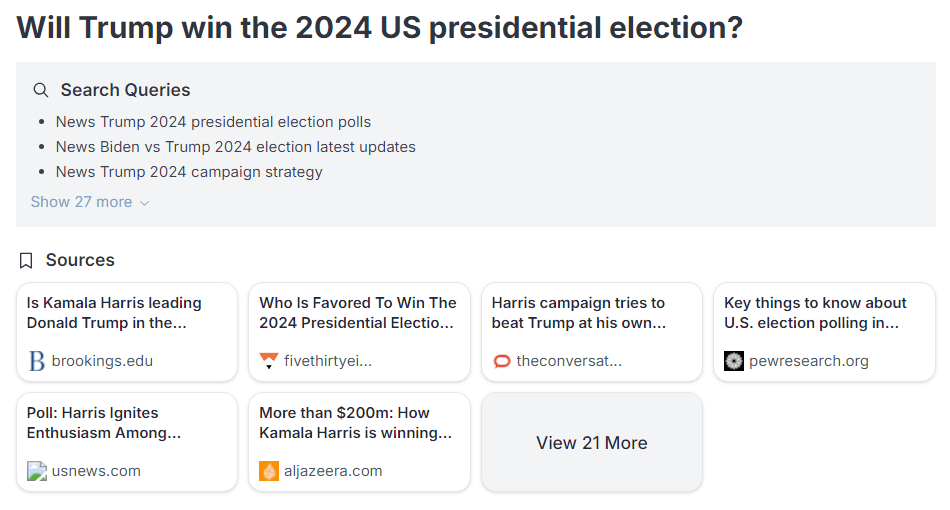
Based on these sources and its wealth of prior knowledge, FiveThirtyNine compiles a summary of key facts. Given these facts, it’s asked to give reasons for and against Trump winning the election, before weighing each reason based on its strength and salience.
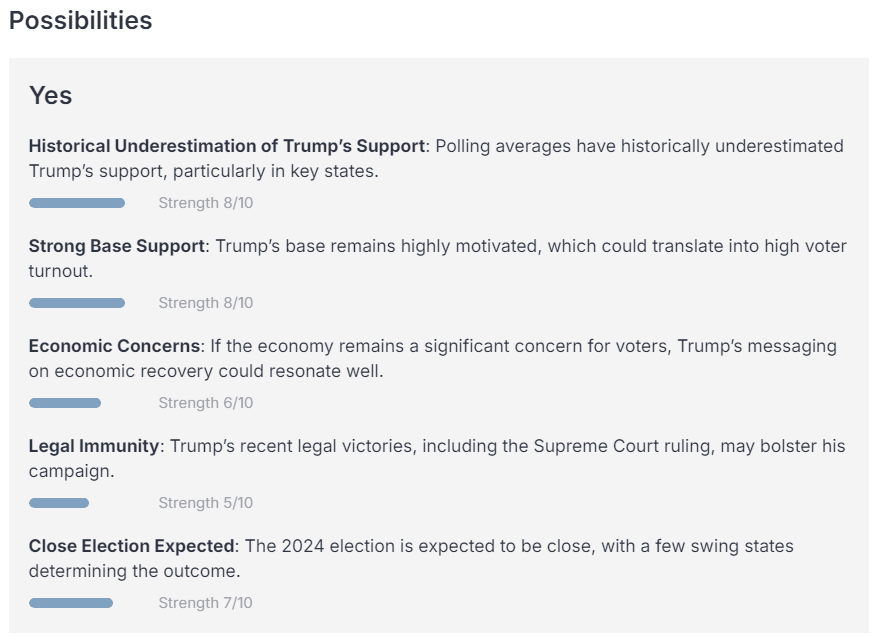
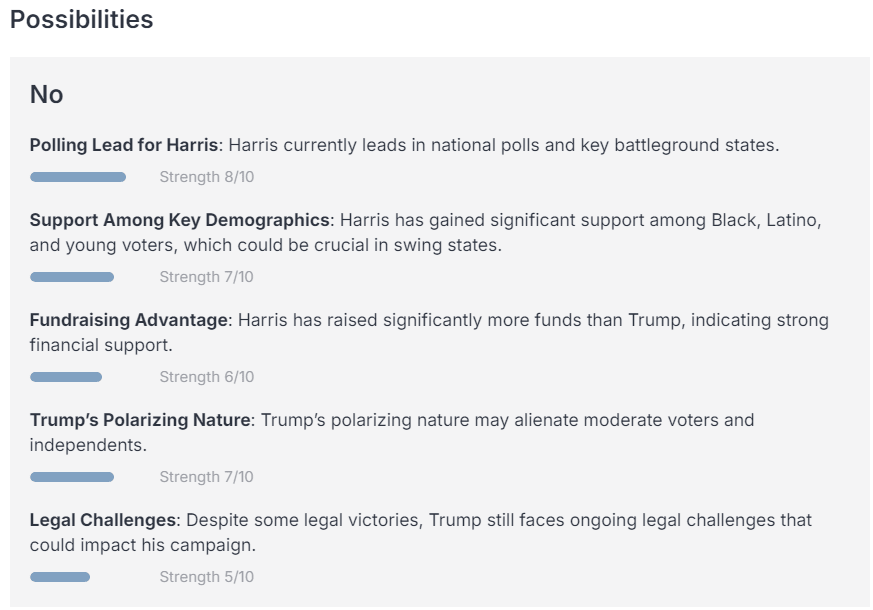
Finally, FiveThirtyNine aggregates its considerations while adjusting for negativity and sensationalism bias in news sources and outputs a tentative probability. It is asked to sanity check this probability and adjust it up or down based on further reasoning, before putting out a final, calibrated probability—in this case, 52%.


Evaluation. To test how well our bot performs, we evaluated it on questions from the Metaculus forecasting platform. We restricted the bot to make predictions only using the information human forecasters had, ensuring a valid comparison. Specifically, GPT-4o is only trained on data up to October 2023, and we restricted the news and opinion articles it could access to only those published before a certain date. From there, we asked it to compute the probabilities of 177 events from Metaculus that had happened (or not happened) since.
We compared the probabilities our bot arrived at to those arrived at independently by crowds of forecasters on the prediction platform Metaculus. For example, we asked the bot to estimate the probability that Israel would carry out an attack on Iran before May 1, 2024, restricting it to use the same information available to human forecasters at the time. This event did not occur, allowing us to grade the AI and human forecasts. Across the full dataset of events, we found that FiveThirtyNine performed just as well as crowd forecasts.
Strengths over prediction markets. On the 177 events, the Metaculus crowd got 87.0% accuracy, while FiveThirtyNine got 87.7% ± 1.4. A link to the technical report is here. This bot lacks many of the drawbacks of prediction markets. It makes forecasts within seconds. Additionally, groups of humans do not need to be incentivized with cash prizes to make and continually update their predictions. Forecasting AIs are several orders of magnitude faster and cheaper than prediction markets, and they’re similarly accurate.
Limitations. The bot is not fine-tuned, and doing so could potentially make it far more accurate. It simply retrieves articles and writes a report as guided through an engineered prompt. (Its prompt can be found by clicking on the gear icon in forecast.safe.ai.) Moreover, probabilities from AIs are also known to lead to automation bias, and improvements in the interface could ameliorate this. The bot is also not designed to be used in personal contexts, and it has not been tested on its ability to predict financial markets. Forecasting can also lead to the neglect of tail risks and lead to self-fulfilling prophecies. That said, we believe this could be an important first step towards establishing a cleaner, more accurate information landscape. The bot is decidedly subhuman in delimited ways, even if it is usually beyond the median human in breadth, speed, and accuracy. If it’s given an invalid query it will still forecast---a reject option is not yet implemented. If something is not in the pretraining distribution and if no articles are written about it, it doesn’t know about it. That is, if it’s a forecast about something that’s only on the X platform, it won’t know about it, even if a human could. For forecasts for very soon-to-resolve or recent events, it does poorly. That’s because it finished pretraining a while ago so by default thinks Joe Biden is in the race and need to see articles to appreciate the change in facts. Its probabilities are not always completely consistent either (like prediction markets). In claiming the bot is superhuman (around crowd level in accuracy), we’re not claiming it’s superhuman in every possible respect, much like how academics can claim image classifiers are superhuman at ImageNet, despite being vulnerable to adversarial ImageNet images. We do not think AI forecasting is overall subhuman.
Vision
Epistemic technologies such as Wikipedia and Community Notes have had significant positive impacts on our ability to understand the world, hold informed discussions, and maintain consensus reality. Superhuman forecasting AIs could have similar effects, enabling improved decision-making and public discourse in an increasingly complex world. By acting as a neutral intelligent third party, forecasting AIs could act as a tempering force on those pushing extreme, polarized positions.
Chatbots. Through integration into chatbots and personal AI assistants, strong automated forecasting could help with informing consequential decisions and anticipating severe risks. For example, a forecasting AI could provide trustworthy, impartial probability assessments to policymakers. The AI could also help quantify risks that are foreseeable to experts but not yet to the general public, such the possibility that China might steal OpenAI’s model weights.
Posts. Forecasting AIs could be integrated on social media and complement posts to help users weigh the information they are receiving.
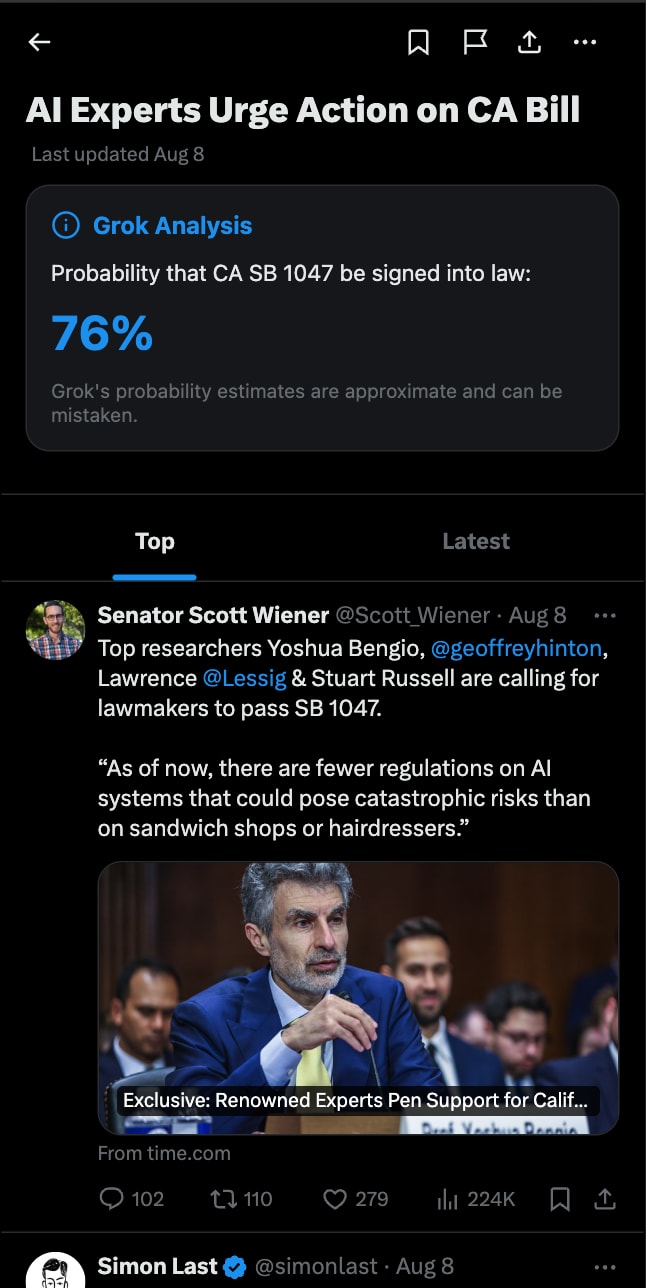
News stories. Forecasting could also complement news stories and topics. For example, for news associated with California AI Safety bill SB 1047, a forecasting bot could let users know the probability that it gets signed into law.
Conclusion
Carl Sagan noted, “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves.” AIs will continue to become more powerful, but their forecasting capabilities will hopefully help make us more prudent and increase our foresight.


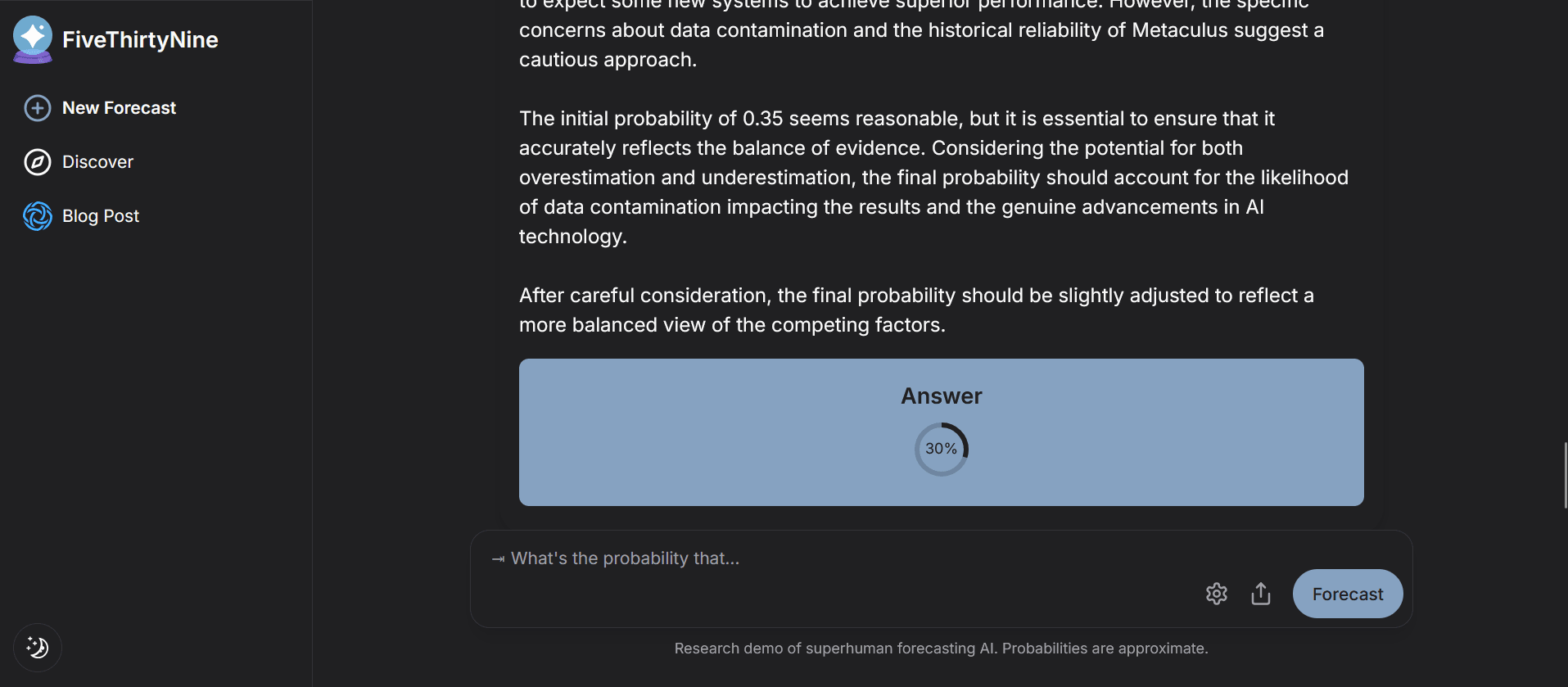
Update: After seeing a comment by AdamK on Manifold, I dug into the code and can confirm that the way the codebase queries for articles does at least check for meta tags that indicate when an article was last updated (which my guess is aren't reliable, but it does seem like they at least tried). I would be highly surprised if their code addresses all of the myriad data-contamination issues (including very tricky ones like news articles that predicted things accurately getting more traffic after a forecasted event happened and therefore coming up higher in search results, even if they were written before the resolution time). I am currently taking bets that on prospective forecasts this system will perform worse than advertised (and also separately think that the advertised performance does not meaningfully make this system "superhuman")
How did you handle issues of data contamination?
In your technical report you say you validated performance for this AI system using retrodiction:
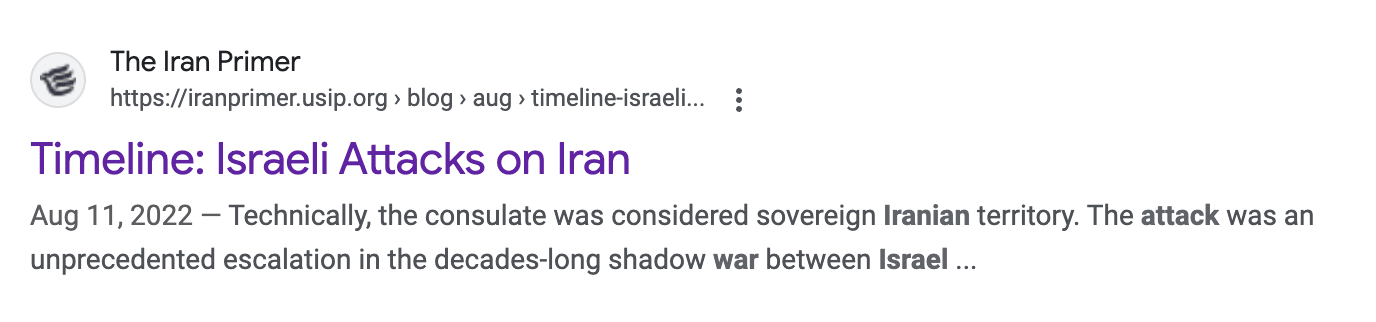
I am quite concerned about search engines actually not being capable of filtering out data for recent events.As an example, I searched “Israel attack on Iran” as you mention that as a concrete example in this excerpt of the blog post:
The first result of searching for "Israel attack on Iran", if you set the date cutoff to October 1st 2023, is this:
As you can see, Google claims a publishing data of "Aug 11, 2022". However, when you click into this article, you will quickly find the following text:
The article actually includes updates from April 19, 2024! This is very common, as many articles get updated after they are published.
The technical report just says:
But at least for Google this fails, unless you are using an unknown functionality for Google.
Looking into the source code, it appears that the first priority source you check is some meta tags:
However, for the article I just linked, those meta tags do indeed say the article was published in 2022:
This means this article, as far as I can tell from parsing the source code, would have its full text end up in the search results, even though it’s been updated in 2024 and includes the events that are supposed to be forecasted (it might be filtered out by something else, but I can’t seem to find any handling of modified articles).
Generally, data contamination is a huge issue for retrodiction, so I am assuming you have done something good here, otherwise it seems very likely your results are inflated because of those data contamination issues, and we should basically dismiss the results of your technical report.
To be clear, I did not do any cherry-picking of data here. The very first search query on any topic that I tried was the search I document above.
Slightly tangential, but do you know what the correct base rate of Manifold binary questions are? Like is it closer to 30% or closer to 50% for questions that resolve Yes?