I donated:
$100 to Zvi Mowshowitz for his post "Covid-19: My Current Model" but really for all his posts. I appreciated how Zvi kept posting Covid updates long after I have energy to do my own research on this topic. I also appreciate how he called the Omicron wave pretty well.
$100 to Duncan Sabien for his post "CFAR Participant Handbook now available to all". I'm glad CFAR decided to make it public, both because I have been curious for a while what was in it and because in general I think it's pretty good practice for orgs like CFAR to publish more of what they do. So thanks for doing that!
I donated for some nonzero X:
- $X to johnswentworth for "Alignment By Default", which gave a surprisingly convincing argument for something I'd dismissed as so unlikely as to be not worth thinking about.
- $2X to Daniel Kokotajlo for "Against GDP as a metric for timelines and takeoff speeds", for turning me, uh, Against GDP as a metric for timelines and takeoff speeds.
- $2X to johnswentworth for "When Money Is Abundant, Knowledge Is The Real Wealth", which I think of often.
- $10X to Microcovid.org, which has provided me many times that much value.
One question I've mulled over the past couple years is "is there any principled way to determine which posts 'won' the review, in terms of being worthy of including LW's longterm canon?"
In past years, we determined what goes in the books largely via wordcount. i.e. we set out to make a reasonable set of books, and then went down the list of voting results and included everything until we ran out of room, skipping over some posts that didn't make sense in book format. (i.e. Lark's Review of AI Charities of The Year is always crazy long and not super relevant to people 3 years after-the-fact).
I still don't have a great answer. But, one suggestion a colleague gave me that feels like an incremental improvement is to look at the scoring, and look for "cliffs" that the vote falls off.
For example, here is the graph of "1000+ karma voters" post scores:
(note: there's a nicer version of this graph here, where you can mouse over lines to see which post they correspond to)
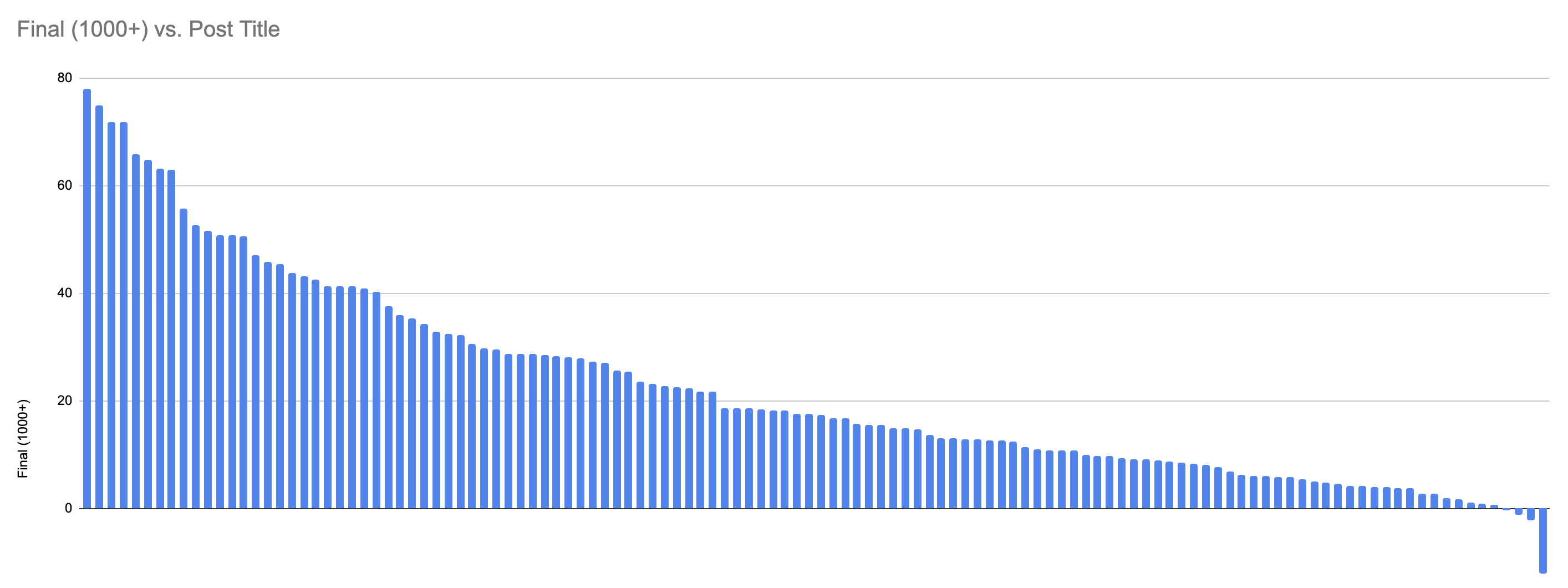
I see maybe 4 "discontinuities" here. There's an initial 4 posts clustered together, then a second cluster of 4, then a (less pronounced) cluster of 6. You can maybe pick out another drop at number 53.
...
If you look at the All Users vote, the results look like this:
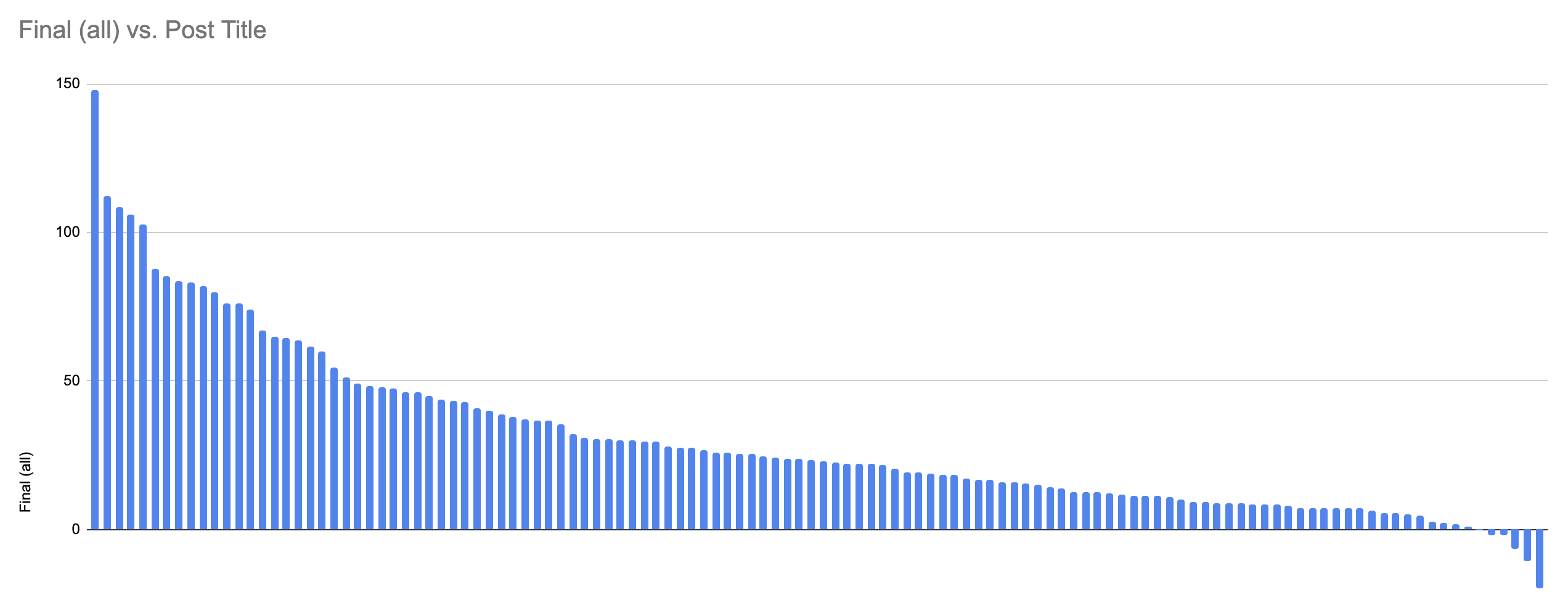
With a massive, massive landslide for "Microcovid", followed by a cluster of 4, and then (maybe?) a less pronounced cluster of 9.
...
And then the Alignment Forum user votes look like this:
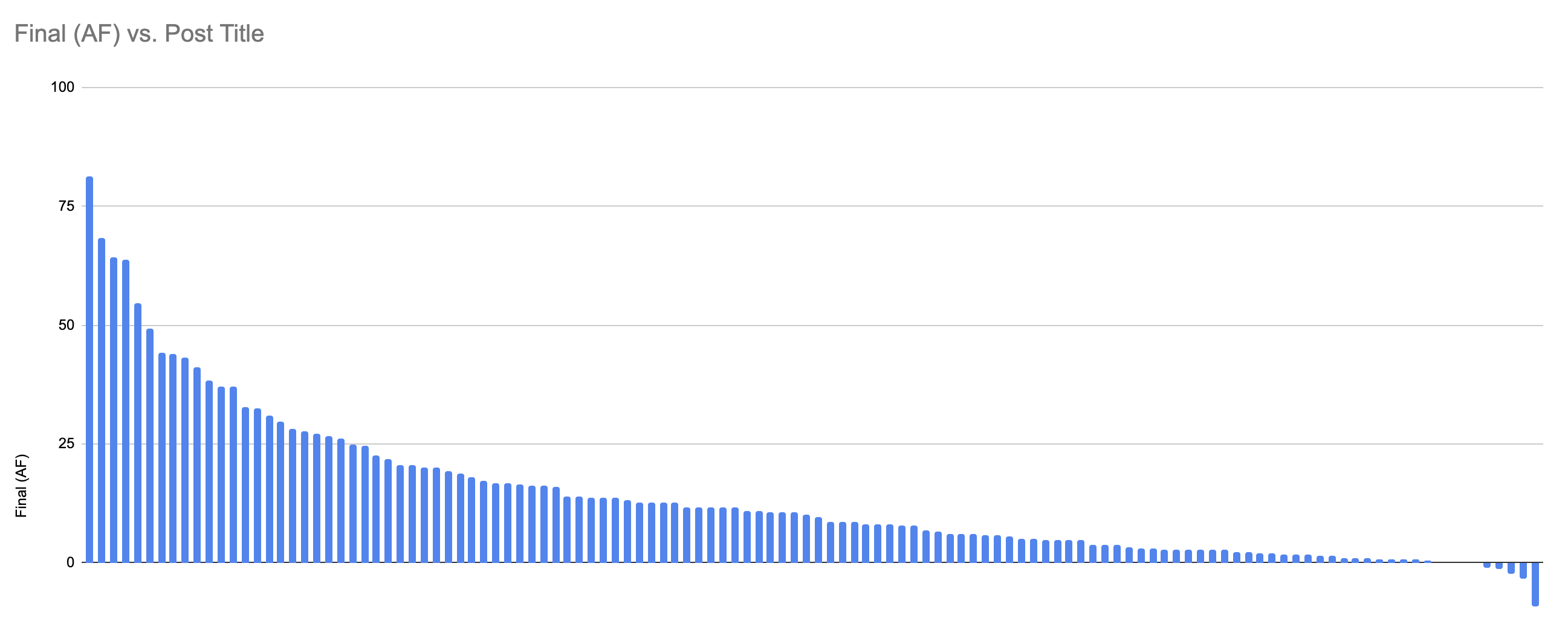
With "Draft Report on AI Timelines" having a very substantial lead.
...
Finally, if I do a weighted-average where I weight "1000+ karma users" as 3x the vote weight of the rest of the users, the result is this:
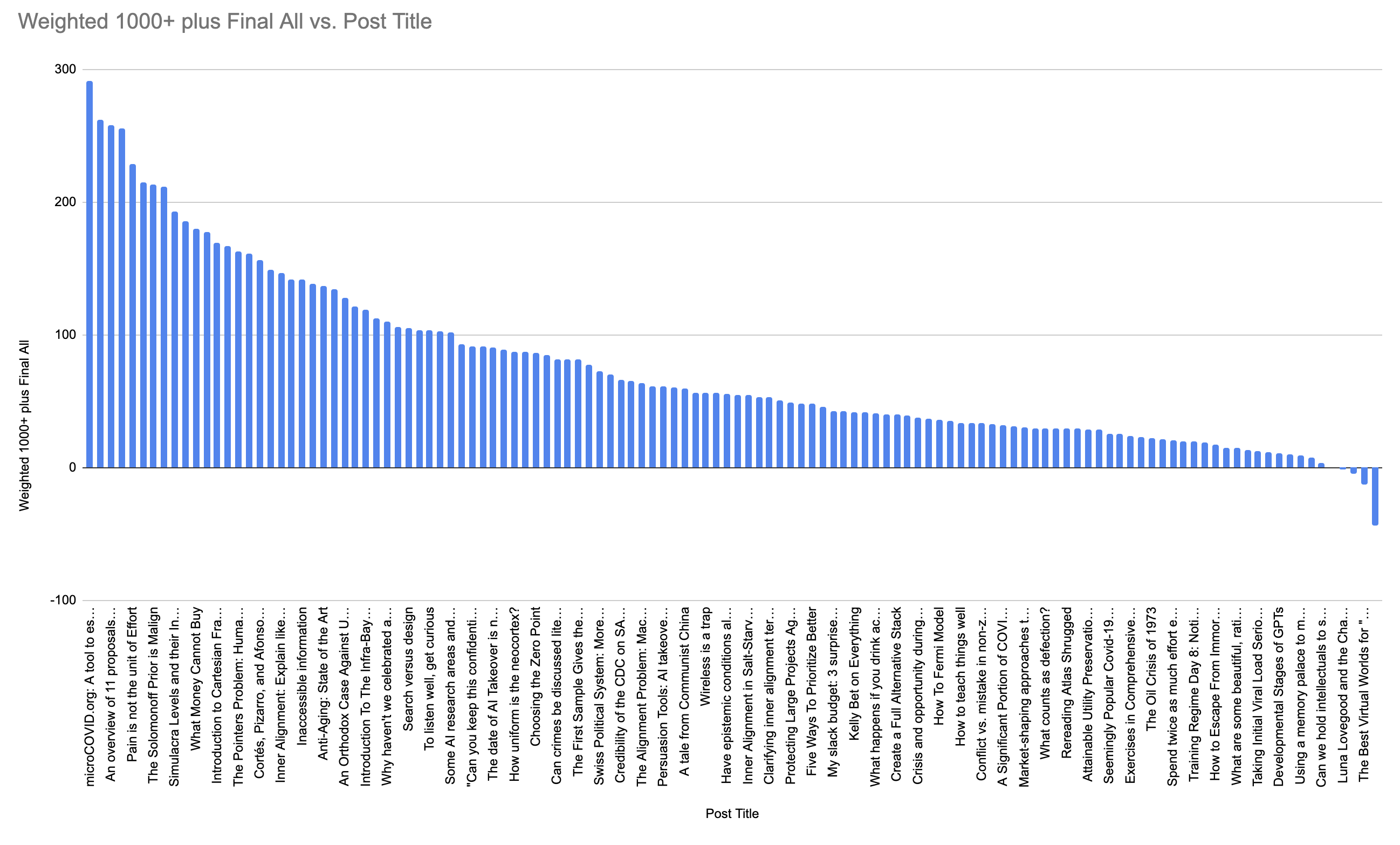
This still has Microcovid taking a massive lead, followed by a small cluster that begins with Draft Reports, followed either by a cluster of 4 or "1 and 3" depending on how you look at things.
I had sort of vaguely assume you were already doing something like this. It is pretty close to what I used to do for assigning grades while avoiding a "barely missed out" dynamic, in which someone would miss the cutoff for an A by 0.25%.
There's a few more days left to have donations matched by Lightcone Infrastructure. I wanted to talk a bit about my own personal donations here.
I wanted to donate to authors who a) didn't show up in the top 15 and were less likely to end up receiving money from The Voting Results Prize, b) who contributed novel information that actually changed my plans in some important ways. I aim to donate about 1% of my post-necessary-expenses income per year, and this year decided it was worth putting that towards LW authors who have changed my strategic thinking.
This is partly because I directly think these posts are worth paying money for, and particular because I want to signal support for the idea that paying for ideas that changed your life is worthwhile.
$100 for Abram Demski's "Most Prisoner's Dilemmas are Stag Hunts; Most Stag Hunts are Schelling Problems". This was a very crystallizing read on how to think about game theory. It both gave me a sense of what real coordination problems look like, as well as a visceral experience of what it looks like to see a formalization that carries through multiple stages of abstraction.
$100 for Zvi's "The Road to Mazedom". This was crisp model of how organizations can become pathological, which changes what I keep an eye out for when the Lightcone team is considering expanding, and when I interact with other organizations.
$100 for landfish's "Nuclear war is unlikely to cause human extinction". While I already wasn't working on nuclear risk reduction, this post shifted my beliefs from "AI is more important" to "actually nuclear risk just doesn't seem like it's in the top 10 things I should be thinking about, and probably shouldn't be in other people's either", which affects my approach to x-risk fieldbuilding.
$50 for Mark Xu's "The First Sample Gives the Most Information". This concept was something I was already vaguely familiar with, but it turned out to shape my thinking quite a bit in the last year.
$50 for Malcolm Ocean's "Reveal Culture". After the results of this Review, I've given up on making "Reveal Culture" happen as a phrase. But I still think this post heavily informs my take on what is required for a culture to succeed, which is relevant beyond the specific "reveal culture" idea.
$50 to Rick Korzekwa for "Why indoor lighting is hard to get right and how to fix it". This directly caused me to buy myself a bunch of lights, which made my life better.
121 got at least one review, bringing them into the final voting phase.
IIRC the Final Voting page initially displayed 121 posts, but eventually displayed 122. I assumed one additional post had gotten its first review after the Review phase had passed.
Anyway, I'm kind of confused regarding what happened to it, as it's not listed here in the final results. Maybe it was never displayed in the list-of-posts-to-vote-on? Maybe no-one voted for it? Or maybe it was erroneously filtered out at some point despite receiving votes?
EDIT: The missing post is Vaniver's Circling as Cousin to Rationality. It was reviewed on January 13th, so IIRC before the review deadline. It's possible that it got no votes or something. But it's also a bit suspicious that it was published on 2020-01-01 at 2:16 AM CET, so maybe there's a bug there.
Oh, yeah I bet that suffered from getting picked up by an inconsistent set of timezone-related code. Will look into that.
(re-rendering the fancy table is a bit annoying, but for the immediate future, Circling as Cousin to Rationality came it at rank 105. It showed up in the full-results, and you can look at how it compared to others)
You might want to edit the writeup to indicate that the fancy HTML table only displays votes by users with 1000+ karma.
Also, have you checked how big the discrepancy is between the 1000+ karma votes vs. all votes? I know the initial writeup mentioned that the former would be weighed more highly, but the HTML table implies that the latter got ignored entirely, which doesn't seem like the right (or fair) approach at all. It would be one thing to only open the vote for users with 1000+ karma, but another entirely to open it to all users and then ignore those votes.
One thing you could do would be to commit to a specific vote weight (e.g. votes at 1000+ karma are weighted 2x as much as other votes), then calculate a ranking from that. Incidentally, potential math errors notwithstanding, a weight of 2x for the 1000+ karma scores would correspond to the final adjusted score simply being the average between the 1000+ karma score and the All score.
Anyway, here's a copy of the above-mentioned spreadsheet with some extra columns: "Final Score Adjusted (1000+ karma weighed 2x other votes)" is just what it says. "Rank 1000 minus Rank All" and "Rank 1000 minus Rank Adjusted" display the rank discrepancy based on how votes are weighed.
For instance, microCOVID.org lands on rank 1 on both Rank All and Rank Adjusted. Which makes sense - you'd expect the 1000+-karma users to favor technical posts on AI alignment more highly than the broader community.
Thanks for exploring this. :)
Quick note:
You might want to edit the writeup to indicate that the fancy HTML table only displays votes by users with 1000+ karma.
I had intended to convey that with "Complete Voting Results (1000+ Karma). You can see more detailed results, including non-1000+ karma votes, here." (It's written a few paragraphs before the results so you might have missed it.
For some historical context, this is the third Review.
In the first review, only 1000+ karma users could vote at all.
In the second year, we displayed the results of the 1000+ users, and then we looked at all the different voting results, but there weren't actually major differences between either the posts in the top 10ish (which is what we award prizes to) or posts in the top 40-50ish (which is what went into the book). The book curation process depends a lot on which posts actually fit, and some other design considerations.
This year, I think like last year, there aren't major differences in "which posts made it to top-10" (the one difference is whether #10 and #11 are "Ground of Optimization" and "Simulacra Levels and their Interactions", or vice-versa)
What is a difference this year is a very major difference in the #1 post. The "All Voters" outcome was overwhelmingly "Microcovid", the "1000+ karma voters" outcome as "Draft of AI Timelines." Notably, "Draft of AI Timelines" is also the massive winner when you look at the Alignment Forum voters.
So, my overall plan had been "take in both votes, and then apply some design and prizegiving intuitions about what exactly to do with them. This year, I think this translates into something like "Microcovid" and "Draft of AI Timelines" should maybe both get extra-prize-money as the #1 winners of different votes.
I had intended to convey that with "Complete Voting Results (1000+ Karma). You can see more detailed results, including non-1000+ karma votes, here."
... I am apparently blind. My apologies.
Other than that, I agree that if the main outcome of interest is which post is #1 and which are the top 10, there's little difference between the various vote rankings, except for the microCOVID.org thing.
I think you're probably right (but want to think more about) the results printing the "Voting Results" post being more of a weighted average. Prior to reading your comment, I was thinking I might might 1000+ karma votes as 3x the "All" votes (whereas you had 2x). But, in this case 3x still results in "Microcovid" winning the "weighted average", so the result is kinda the same.
FYI here's my personal spreadsheet where I've been futzing around with various display options. It includes my own methodology for weighting the results and combining them, which I think is different from yours although I didn't delve too deeply into your spreadsheet architecture.
To be clear, I didn't do anything smart in my take on the spreadsheet. I picked the weight of 2x for no special reason, but was then amused to discover that this choice was mathemically equivalent to taking the average of the All score and the 1000+ karma score:
Other than that, I only computed the rank difference of the various scoring rules, e.g. Rank_1000 minus Rank_All.
Regarding your new spreadsheet, it's too individualized for me to understand much. But I did notice that cell Q2 in the Graphs sheet uses a formula of "=(O2/R$1)*8000" while all subsequent cells multiply by 10000 instead. Maybe that's a tiny spreadsheet error?
Full voting results here. Original 2020 Review announcement here.
That's it folks! The votes are finalized! The Annual Review of 2020 has come to a close. So ends this yearly tradition that we use to take stock of the progress made on LessWrong, and to provide reward and feedback to the writers and researchers who produced such great works.
Donate to thank the authors (matching funds until Feb 15th 11:59pm)
Speaking of reward and feedback, this year we're doing something new with the Review. Like normal, the LessWrong team will awarding prizes to top posts. But this year we'll be allocating prizes from two different pools of money – the Review Vote pool, and the Unit of Caring pool.
For each pool, the review panel will be using moderator discretion. We'll be ensuring the prizes go to posts which we believe further our cause of developing the art of rationality and intellectual progress. But for the Review Vote prize pool, our judgment will be strongly informed by the results of the vote. For the Unit of Caring prize pool, our judgment will strongly be informed by the opinions expressed by donors who contribute to the prize pool.
For the Review Vote prize, we will allocate $10,000.
For the Unit of Caring prize, we will allocate up to $5000, matching the total amount that other LessWrong users contribute to the pool. (i.e. if LessWrong users donate $4000, the pool will be $8000. If users donate $6000, then the total prize pool will be $11,000).
[Update: the donation period is now over
If you want to donate while signaling support for particular posts, you can do so using the buttons for individual posts further down the page. Here is your opportunity to not just spend internet points, but to actually spend a costly signal of support for the authors and posts you found valuable!
Donations must be made by February 10th to contribute to the matching pool.
EDIT: deadline extended to the end of February 15th
Complete Voting Results (1000+ Karma)
You can see more detailed results, including non-1000+ karma votes, here.
A total of 400 posts were nominated. 121 got at least one review, bringing them into the final voting phase. 211 users cast a total of 2877 votes. Users were asked to vote on posts they thought made a significant intellectual contribution.
Voting is visualized here with dots of varying sizes (roughly indicating that a user thought a post was "good" "important", or "extremely important"). Green dots indicate positive votes. Red indicate negative votes. You can hover over a dot to see its exact score.
Results
Here are the posts. Note that the donation buttons don't go directly to post authors – they are granted to the Unit of Caring prize pool. The LessWrong moderation team will be exercising some judgment, but the distribution will likely reflect the distribution of donor recommendations.
That's all (for now)
Over the next couple weeks the LessWrong team will look over the voting results, and begin thinking about how to aggregate the winning posts into the Best of LessWrong Collection.
Thanks so much to every who participated – the authors who originally wrote excellent posts, the many reviewers who gave them a lot of careful consideration, and the voters who deliberated.