I buy this for the post-GPT-3.5 era. What's confusing me is that the rate of advancement in the pre-GPT-3.5 era was apparently the same as in the post-GPT-3.5 era, i. e., doubling every 7 months.
Why would we expect there to be no distribution shift once the AI race kicked into high gear? GPT-2 to GPT-3 to GPT-3.5 proceeded at a snail's pace by modern standards. How did the world happen to invest in them just enough for them to fit into the same trend?
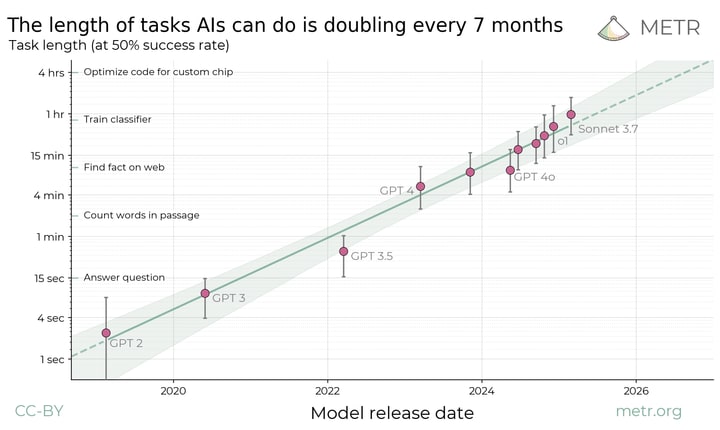
Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under five years, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
This is probably the most important single piece of evidence about AGI timelines right now. Well done! I think the trend should be superexponential, e.g. each doubling takes 10% less calendar time on average. Eli Lifland and I did some calculations yesterday suggesting that this would get to AGI in 2028. Will do more serious investigation soon.
Why do I expect the trend to be superexponential? Well, it seems like it sorta has to go superexponential eventually. Imagine: We've got to AIs that can with ~100% reliability do tasks that take professional humans 10 years. But somehow they can't do tasks that take professional humans 160 years? And it's going to take 4 more doublings to get there? And these 4 doublings are going to take 2 more years to occur? No, at some point you "jump all the way" to AGI, i.e. AI systems that can do any length of task as well as professional humans -- 10 years, 100 years, 1000 years, etc.
Also, zooming in mechanistically on what's going on, insofar as an AI system can do tasks below length X but not above length X, it's gotta be for some reason -- some skill that the AI lacks, which isn't important for tasks below length X but which tends to be crucial for... (read more)
I second this, it could easily be things which we might describe as "amount of information that can be processed at once, including abstractions" which is some combination of residual stream width and context length.
Imagine an AI can do a task that takes 1 hour. To remain coherent over 2 hours, it could either use twice as much working memory, or compress it into a higher level of abstraction. Humans seem to struggle with abstraction in a fairly continuous way (some people get stuck at algebra; some cs students make it all the way to recursion then hit a wall; some physics students can handle first quantization but not second quantization) which sorta implies there's a maximum abstraction stack height which a mind can handle, which varies continuously.
8Stephen Fowler
While each mind might have a maximum abstraction height, I am not convinced that the inability of people to deal with increasingly complex topics is direct evidence of this.
Is it that this topic is impossible for their mind to comprehend, or is it that they've simple failed to learn it in the finite time period they were given?
2J Bostock
That might be true but I'm not sure it matters. For an AI to learn an abstraction it will have a finite amount of training time, context length, search space width (if we're doing parallel search like with o3) etc. and it's not clear how the abstraction height will scale with those.
Empirically, I think lots of people feel the experience of "hitting a wall" where they can learn abstraction level n-1 easily from class; abstraction level n takes significant study/help; abstraction level n+1 is not achievable for them within reasonable time. So it seems like the time requirement may scale quite rapidly with abstraction level?
3Daniel Kokotajlo
I'm not sure if I understand what you are saying. It sounds like you are accusing me of thinking that skills are binary--either you have them or you don't. I agree, in reality many skills are scalar instead of binary; you can have them to greater or lesser degrees. I don't think that changes the analysis much though.
4Matt Goldenberg
My point is, maybe there are just many skills that are at 50% of human, then go up to 60%, then 70%, etc, and can keep going up linearly to 200% or 300%. It's not like it lacked the skill then suddenly stopped lacking it, it just got better and better at it
2Daniel Kokotajlo
I agree with that, in fact I think that's the default case. I don't think it changes the bottom line, just makes the argument more complicated.
2Matt Goldenberg
I don't see how the original argument goes through if it's by default continuous.
One of non-obvious but very important skills which all LLM-based SWE agents currently lack is reliably knowing which subtasks of a task you have successfully solved and which you have not. I think https://www.answer.ai/posts/2025-01-08-devin.html is a good case in point.
We have absolutely seen a lot of progress on driving down hallucinations on longer and longer contexts with model scaling, they probably made the charts above possible in the first place. However, recent research (e. g., the NoLiMa benchmark from last month https://arxiv.org/html/2502.05167v1) demonstrates that effective context length falls far short of what is advertised. I assume it's not just my personal experience but common knowledge among the practitioners that hallucinations become worse the more text you feed to an LLM.
If I'm not mistaken even with all the optimizations and "efficient" transformer attempts we are still stuck (since GPT-2 at least) with self-attention + KV-cache[1] which scale (at inference) linearly as long as you haven't run out of memory and quadratically afterwards. Sure, MLA have just massively ramped up the context length at which the latter happens but it's not unlimited, you won... (read more)
KV caching (using the terminology "fast decoding" and "cache") existed even in the original "Attention is All You Need" implementation of an enc-dec transformer. It was added on Sep 21 2017 in this commit. (I just learned this today, after I read your comment and got curious.)
The "past" terminology in that original transformers implementation of GPT-2 was not coined by Wolf – he got it from the original OpenAI GPT-2 implementation, see here.
Doesn't the trend line already take into account the effect you are positing? ML research engineers already say they get significant and increasing productivity boosts from AI assistants and have been for some time. I think the argument you are making is double-counting this. (Unless you want to argue that the kink with Claude is the start of the super-exponential, which we would presumably get data on pretty soon).
I indeed think that AI assistance has been accelerating AI progress. However, so far the effect has been very small, like single-digit percentage points. So it won't be distinguishable in the data from zero. But in the future if trends continue the effect will be large, possibly enough to more than counteract the effect of scaling slowing down, possibly not, we shall see.
Research engineers I talk to already report >3x speedups from AI assistants. It seems like that has to be enough that it would be showing up in the numbers. My null hypothesis would be that programmer productivity is increasing exponentially and has been for ~2 years, and this is already being taken into account in the curves, and without this effect you would see a slower (though imo not massively slower) exponential.
(This would argue for dropping the pre-2022 models from the graph which I think would give slightly faster doubling times, on the order of 5-6 months if I had to eyeball.).
Research engineers I talk to already report >3x speedups from AI assistants
Huh, I would be extremely surprised by this number. I program most days, in domains where AI assistance is particularly useful (frontend programming with relatively high churn), and I am definitely not anywhere near 3x total speedup. Maybe a 1.5x, maybe a 2x on good weeks, but definitely not a 3x. A >3x in any domain would be surprising, and my guess is generalization for research engineer code (as opposed to churn-heavy frontend development) is less.
I think my front-end productivity might be up 3x? A shoggoth helped me building a stripe shop and do a ton of UI design that I would’ve been hesitant to take on myself (without hiring someone else to work with), as well as quality increase in speed of churning through front-end designs.
(This is going from “wouldn’t take on the project due to low skill” to “can take it on and deliver it in a reasonable amount of time”, which is different from “takes top programmer and speeds them up 3x”.)
I agree with habryka that the current speedup is probably substantially less than 3x.
However, worth keeping in mind that if it were 3x for engineering the overall AI progress speedup would be substantially lower, due to (a) non-engineering activities having a lower speedup, (b) compute bottlenecks, (c) half of the default pace of progress coming from compute.
My null hypothesis would be that programmer productivity is increasing exponentially and has been for ~2 years, and this is already being taken into account in the curves, and without this effect you would see a slower (though imo not massively slower) exponential
Exponential growth alone doesn't imply a significant effect here, if the current absolute speedup is low.
I don't believe it. I don't believe that overall algorithmic progress is 3x faster. Maaaybe coding is 3x faster but that would maybe increase overall algo progress by like 30% idk. But also I don't think coding is really 3x faster on average for the things that matter.
2jsteinhardt
I meant coding in particular, I agree algorithmic progress is not 3x faster. I checked again just now with someone and they did indeed report 3x speedup for writing code, although said that the new bottleneck becomes waiting for experiments to run (note this is not obviously something that can be solved by greater automation, at least up until the point that AI is picking better experiments than humans).
6osten
Ok, but why do you think that AIs learn skills at a constant rate? Might it be that higher level skills need more time to learn because compute scales exponentially with time but for higher level skills data is exponentially more scarce and needs linearly in task length more context, that is, total data processed scales superexponentially with task level?
5Anthony DiGiovanni
I'm confused as to what the actual argument for this is. It seems like you've just kinda asserted it. (I realize in some contexts all you can do is offer an "incredulous stare," but this doesn't seem like the kind of context where that suffices.)
I'm not sure if the argument is supposed to be the stuff you say in the next paragraph (if so, the "Also" is confusing).
6Daniel Kokotajlo
Great question. You are forcing me to actually think through the argument more carefully. Here goes:
Suppose we defined "t-AGI" as "An AI system that can do basically everything that professional humans can do in time t or less, and just as well, while being cheaper." And we said AGI is an AI that can do everything at least as well as professional humans, while being cheaper.
Well, then AGI = t-AGI for t=infinity. Because for anything professional humans can do, no matter how long it takes, AGI can do it at least as well.
Now, METR's definition is different. If I understand correctly, they made a dataset of AI R&D tasks, had humans give a baseline for how long it takes humans to do the tasks, and then had AIs do the tasks and found this nice relationship where AIs tend to be able to do tasks below time t but not above, for t which varies from AI to AI and increases as the AIs get smarter.
...I guess the summary is, if you think about horizon lengths as being relative to humans (i.e. the t-AGI definition above) then by definition you eventually "jump all the way to AGI" when you strictly dominate humans. But if you think of horizon length as being the length of task the AI can do vs. not do (*not* "as well as humans," just "can do at all") then it's logically possible for horizon lengths to just smoothly grow for the next billion years and never reach infinity.
So that's the argument-by-definition. There's also an intuition pump about the skills, which also was a pretty handwavy argument, but is separate.
4Mo Putera
Ben West's remark in the METR blog post seems to suggest you're right that the doubling period is shortening:
3satwik
Any slowdown seems implausible given Anthropic timelines, which I consider to be a good reason to be skeptical of data and compute cost-related slowdowns at least until nobel-prize level. Moreover, the argument that we will very quickly get 15 OOMs or whatever of effective compute after the models can improve themselves is also very plausible
2Siebe
One way to operationalize "160 years of human time" is "thing that can be achieved by a 160-person organisation in 1 year", which seems like it would make sense?
5ErioirE
Unfortunately, when dealing with tasks such as software development it is nowhere near as linear as that.
The meta-tasks of each additional dev needing to be brought up to speed on the intricacies of the project, as well as lost efficiency from poor communication/waiting on others to finish things means you usually get diminishing (or even inverse) returns from adding more people to the project.
See: The Mythical Man Month
1Mo Putera
Not if some critical paths are irreducibly serial.
1Rachel Shu
Possibly, but then you have to consider you can spin up possibly arbitrarily many instances of the LLM as well, in which case you might expect the trend to go even faster, as now you’re scaling on 2 axes, and we know parallel compute scales exceptionally well.
Parallel years don’t trade off exactly with years in series, but “20 people given 8 years” might do much more than 160 given one, or 1 given 160, depending on the task.
1anaguma
Isn’t the quadratic cost of context length a constraint here? Naively you’d expect that acting coherently over 100 years would require 10x the context, and therefore 100x the compute/memory, than 10 years.
7Thomas Kwa
Humans don't need 10x more memory per step nor 100x more compute to do a 10-year project than a 1-year project, so this is proof it isn't a hard constraint. It might need an architecture change but if the Gods of Straight Lines control the trend, AI companies will invent it as part of normal algorithmic progress and we will remain on an exponential / superexponential trend.
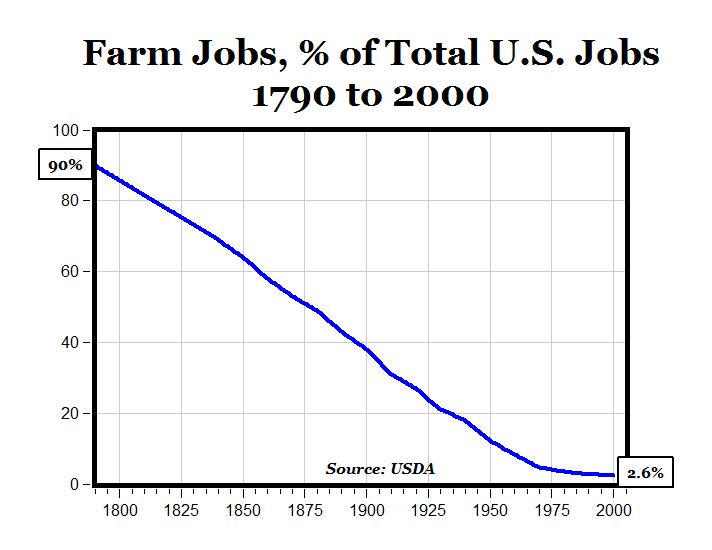
In the last year it has really hit me at a personal level what graphs like these mean. I'm imagining driving down to Mountain View and a town once filled with people who had "made it" and seeing a ghost town. No more jobs, no more prestige, no more promise of a stable life. As the returns to capital grow exponentially and the returns to labor decline to zero, the gap between the haves and the have-nots will only grow.
If someone can actually get superintelligence to do what they want, then perhaps universal basic income can at the very least prevent actual starvation and maybe even provide a life of abundance.
But I can't help but feeling such a situation is fundamentally unstable. If the government's desires become disconnected from those of the people at any point, by what mechanism can balance be restored?
In the past the government was fundamentally reliant on its citizens for one simple reason; citizens produced taxable revenue.
That will no longer be the case. Every country will become a petro state on steroids.
I'm guessing that people who "made it" have a bunch of capital that they can use to purchase AI labor under the scenario you outline (i.e., someone gets superintelligence to do what they want).
I'm not sure I'm getting the worry here. Is it that the government (or whoever directs superintelligences) is going to kill the rest because of the same reasons we worry about misaligned superintelligences or that they're going to enrich themselves while the rest starves (but otherwise not consuming all useful resources)? If that's this second scenario you're worrying about, that seems unlikely to me because even as a few parties hit the jackpot, the rest can still deploy the remaining capital they have. Even if they didn't have any capital to purchase AI labor, they would still organize amongst themselves to produce useful things that they need, and they would form a different market until they also get to superintelligence, and in that world, it should happen pretty quickly.
1Daphne_W
If the superintelligence is willing to deprive people of goods and services because they lack capital, then why would it be empathetic towards those that have capital? The superintelligence would be a monopsony and monopoly, and could charge any amount for someone existing for an arbitrarily short amount of time. Assuming it even respects property law when it is aligned with its creators.
"Kill" is such a dirty word. Just not grant them the means to sustain themselves.
Why would capital owners with a superintelligence ever let those without capital build their own superintelligence? That sounds like a recipe for AI war - are the poors really going to program their superintelligence with anything other than the fundamental rejection of the concept of capital ownership in a post-scarcity society?
-2ErioirE
Government is also reliant on its citizens to not violently protest, which would happen if it got to the point you describe.
The idealist in me hopes that eventually those with massive gains in productivity/wealth from automating everything would want to start doing things for the good of humanity™, right?
...Hopefully that point is long before large scale starvation.
1otto.barten
Have we eventually solved world hunger by giving 1% of GDP to the global poor?
Also, note it's not obvious that ASI can be aligned.
1O O
Isn't it a distribution problem? World hunger has almost disappeared however. (The issue is hungrier nations have more kids, so progress is a bit hidden).
1otto.barten
Wikipedia: in 2023, there were 733 million people suffering from hunger. That's 9% of the population. Most of these people just don't have the money to buy food. That's a 'distribution problem', for money, in the sense that we don't give it to them. Also, world hunger is actually rising again..
Some more data: https://www.linkedin.com/posts/ottobarten_about-700-million-people-in-the-world-cannot-activity-7266965529762873344-rvqK
We could easily solve this if we wanted to, but apparently we don't. That's one data point why I fear intent-aligned superintelligence.
This has been one of the most important results for my personal timelines to date. It was a big part of the reason why I recently updated from ~3 year median to ~4 year median to AI that can automate >95% of remote jobs from 2022, and why my distribution overall has become more narrow (less probability on really long timelines).
Naively extrapolating this trend gets you to 50% reliability of 256-hour tasks in 4 years, which is a lot but not years-long reliability (like humans). So, I must be missing something. Is it that you expect most remote jobs not to require more autonomy than that?
9Zach Stein-Perlman
I think doing 1-week or 1-month tasks reliably would suffice to mostly automate lots of work.
5Nikola Jurkovic
I expect the trend to speed up before 2029 for a few reasons:
1. AI accelerating AI progress once we reach 10s of hours of time horizon.
2. The trend might be "inherently" superexponential. It might be that unlocking some planning capability generalizes very well from 1-week to 1-year tasks and we just go through those doublings very quickly.
5Daniel Kokotajlo
Indeed I would argue that the trend pretty much has to be inherently superexponential. My argument is still kinda fuzzy, I'd appreciate help in making it more clear. At some point I'll find time to try to improve it.
4Thomas Kwa
The trend probably sped up in 2024. If the future trend follows the 2024--2025 trend, we get 50% reliability at 167 hours in 2027.
1MichaelDickens
Why do you think this narrows the distribution?
I can see an argument for why, tell me if this is what you're thinking–
Indeed. That seems incredibly weird. It would be one thing if it were a function of parameter size, or FLOPs, or data, or at least the money invested. But the release date?
The reasons why GPT-3, GPT-3.5, GPT-4o, Sonnet 3.6, and o1 improved on the SOTA are all different from each other, ranging from "bigger scale" to "first RLHF'd model" to "first multimodal model" to "algorithmic improvements/better data" to "???" (Sonnet 3.6) to "first reasoning model". And it'd be one thing if we could at least say that "for mysterious reasons, billion-dollar corporations trying incredibly hard to advance the frontier can't do better than doubling the agency horizon every 7 months using any method", but GPTs from -2 to -3.5 were developed in a completely different socioeconomic situation! There wasn't an AI race dynamics, AGI companies were much poorer, etc. Yet they're still part of the pattern.
This basically only leaves teleological explanations, implies a divine plan for the rate of human technological advancement.
Which makes me suspect there's some error in the data, or the methodology was (accidentally) rigged to produce this result[1]. Or perhaps there's a selection bias where tons of peopl... (read more)
I don't think it's weird. Given that we know there are temporal trends towards increasing parameter size (despite Chinchilla), FLOPs, data, and continued progress in compute/data-efficiency (with various experience curves), any simple temporal chart will tend to show an increase unless you are specifically conditioning or selecting in some way to neutralize that. Only if you had measured and controlled for all that and there was still a large unexplained residual of 'time' would you have to start reaching for other explanations such as 'divine benevolence'. (For example, you might appeal to 'temporal decay': if you benchmark on a dataset of only new data, in some way, then you will expect the oldest models to do the worse, and increasingly recent models do better, even after controlling for all factors you can think of - hey presto, a chart where the models mysteriously 'get better over time', even though if you had a time machine to benchmark each model at release in its own milieu, you'd find no trend.)
I buy this for the post-GPT-3.5 era. What's confusing me is that the rate of advancement in the pre-GPT-3.5 era was apparently the same as in the post-GPT-3.5 era, i. e., doubling every 7 months.
Why would we expect there to be no distribution shift once the AI race kicked into high gear? GPT-2 to GPT-3 to GPT-3.5 proceeded at a snail's pace by modern standards. How did the world happen to invest in them just enough for them to fit into the same trend?
6ryan_greenblatt
Actually, progress in 2024 is roughly 2x faster than earlier progress which seems consistent with thinking there is some distribution shift. It's just that this distribution shift didn't kick in until we had Anthropic competing with OpenAI and reasoning models. (Note that OpenAI didn't release a notably better model than GPT-4-1106 until o1-preview!)
9ryan_greenblatt
My sense is that the GPT-2 and GPT-3 results are somewhat dubious, especially the GPT-2 result. It really depends on how you relate SWAA (small software engineering subtasks) to the rest of the tasks. My understanding is that no iteration was done though.
However, note that it wouldn't be wildly more off trend if GPT-3 was anywhere from 4-30 seconds while it is instead at ~8 seconds. And, the GPT-2 results are very consistent with "almost too low to measure".
Overall, I don't think its incredibly weird (given that the rate of increase of compute and people in 2019-2023 isn't that different from the rate in 2024), but many results would have been roughly on trend.
6Leon Lang
Do you think the x-axis being a release date is more mysterious than the same fact regarding Moore's law?
(Tbc., I think this doesn't make it less mysterious: For Moore's law this also seems like a mystery to me. But this analogy makes it more plausible that there is a mysterious but true reason driving such trends, instead of the graph from METR simply being a weird coincidence. )
4Thane Ruthenis
Hm, that's a very good point.
I think the amount of money-and-talent invested into the semiconductor industry has been much more stable than in AI though, no? Not constant, but growing steadily with the population/economy/etc. In addition, Moore's law being so well-known potentially makes it a self-fulfilling prophecy, with the industry making it a target to aim for.
Also, have you tracked the previous discussion on Old Scott Alexanderand LessWrong about generally "mysterious straight lines" being a surprisingly common phenomenon in economics. i.e. On an old AI post Oli noted:
This is one of my major go-to examples of this really weird linear phenomenon:
150 years of a completely straight line! There were two world wars in there, the development of artificial fertilizer, the broad industrialization of society, the invention of the car. And all throughout the line just carries one, with no significant perturbations.
This doesn't mean we should automatically take new proposed Straight Line Phenomena at face value, I don't actually know if this is more like "pretty common actually" or "there are a few notable times it was true that are drawing undue attention." But I'm at least not like "this is a never-before-seen anomaly")
That surprisingly straight line reminds me of what happens when you use noise to regularise an otherwise decidedly non linear function: https://www.imaginary.org/snapshot/randomness-is-natural-an-introduction-to-regularisation-by-noise
4JenniferRM
Kurzweil (and gwern in a cousin comment) both think that "effort will be allocated efficiently over time" and for Kurzweil this explained much much more than just Moore's Law.
Ray's charts from "the olden days" (the nineties and aughties and so on) were normalized around what "1000 (inflation adjusted) dollars spent on mechanical computing" could buy... and this let him put vacuum tubes and even steam-powered gear-based computers on a single chart... and it still worked.
The 2020s have basically always been very likely to be crazy. Based on my familiarity with old ML/AI systems and standards, the term "AGI" as it was used a decade ago was already reached in the past. Claude is already smarter than most humans, but (from the perspective of what smart, numerate, and reasonable people predicted in 2009) he is (arguably) overbudget and behind schedule.
I really don't think this is a reasonable measure for ability to do long term tasks, but I don't have the time or energy to fight this battle, so I'll just register my prediction that this paper is not going to age well.
Looking at the METR paper's analysis, there might be an important consideration about how they're extrapolating capabilities to longer time horizons. The data shows a steep exponential decay in model success rates as task duration increases. I might be wrong here but it seems weird to be taking an arbitrary cutoff of 50% and doing a linear extrapolation from that?
The logistic curves used to estimate time horizons assume a consistent relationship between task duration and difficulty across all time scales. However, it's plausible that tasks requ... (read more)
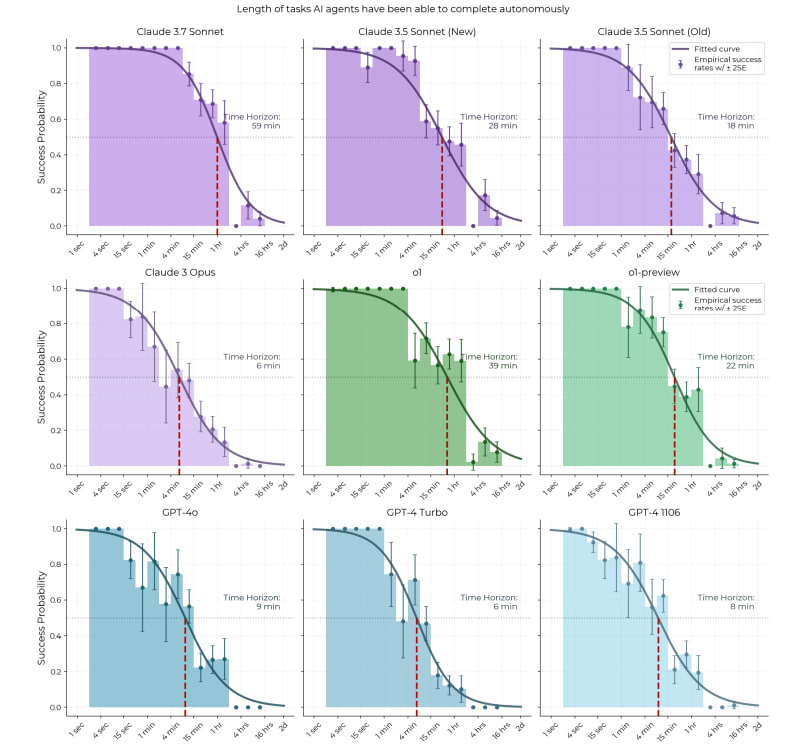
All models since at least GPT-3 have had this steep exponential decay [1], and the whole logistic curve has kept shifting to the right. The 80% success rate horizon has basically the same 7-month doubling time as the 50% horizon so it's not just an artifact of picking 50% as a threshold.
Claude 3.7 isn't doing better on >2 hour tasks than o1, so it might be that the curve is compressing, but this might also just be noise or imperfect elicitation.
Regarding the idea that autoregressive models would plateau at hours or days, it's plausible, and one point of evidence is that models are not really coherent over hundreds of steps (generations + uses of the Python tool) yet-- they do 1-2 hour tasks with ~10 actions, see section 5 of HCAST paper. On the other hand, current LLMs can learn a lot in-context and it's not clear there are limits to this. In our qualitative analysis we found evidence of increasing coherence, where o1 fails tasks due to repeating failed actions 6x less than GPT-4 1106.
Maybe this could be tested by extracting ~1 hour tasks out of the hours to days long projects that we think are heavy in self-modeling, like planning. But we will see whether there's a plateau at t... (read more)
One possible interpretation here is going back to the inner-monologue interpretations as being multi-step processes with an error rate per step where only complete success is useful, which is just an exponential; as the number of steps increase from 1 to n, you get a sigmoid from ceiling performance to floor performance at chance. So you can tell the same story about these more extended tasks, which after all, are just the same sort of thing - just more so. We also see this sort of sigmoid in searching with a fixed model, in settings like AlphaZero in Hex, which makes sense if we assume that these LLMs are doing a lot of retries and backtracking, which constitute a 'search' process as a whole, even if they never explicitly represent or model a decision/game tree, and have error rates stemming from their blindspots and biases. And you can tell a similar story there about error rates and exponentials: all the critical steps have to be right (omitting ones which don't do anything, ones which get undone or reset, etc), and the final result is either right or wrong as you do the task or not.
(And on a more detailed mechanistic level, you can tell a story where NNs learn 'atoms' of skill... (read more)
Extrapolating this suggests that within about 5 years we will have generalist AI systems that can autonomously complete ~any software or research engineering task that a human professional could do in a few days, as well as a non-trivial fraction of multi-year projects, with no human assistance or task-specific adaptations required.
However, (...) It’s unclear how to interpret “time needed for humans”, given that this varies wildly between diffe
That's basically correct. To give a little more context for why we don't really believe this number, during data collection we were not really trying to measure the human success rate, just get successful human runs and measure their time. It was very common for baseliners to realize that finishing the task would take too long, give up, and try to collect speed bonuses on other tasks. This is somewhat concerning for biasing the human time-to-complete estimates, but much more concerning for this human time horizon measurement. So we don't claim the human time horizon as a result.
I have a few potential criticisms of this paper. I think my criticisms are probably wrong and the paper's conclusion is right, but I'll just put them out there:
Nearly half the tasks in the benchmark take 1 to 30 seconds (the ones from the SWAA set). According to the fitted task time <> P(success) curve, most tested LLMs should be able to complete those with high probability, so they don't provide much independent signal.
However, I expect task time <> P(success) curve would look largely the same if you excluded the SWAA tasks.
Regarding 1 and 2, I basically agree that SWAA doesn't provide much independent signal. The reason we made SWAA was that models before GPT-4 got ~0% on HCAST, so we needed shorter tasks to measure their time horizon. 3 is definitely a concern and we're currently collecting data on open-source PRs to get a more representative sample of long tasks.
3Julian Bradshaw
Re: HCAST tasks, most are being kept private since it's a benchmark. If you want to learn more here's the METR's paper on HCAST.
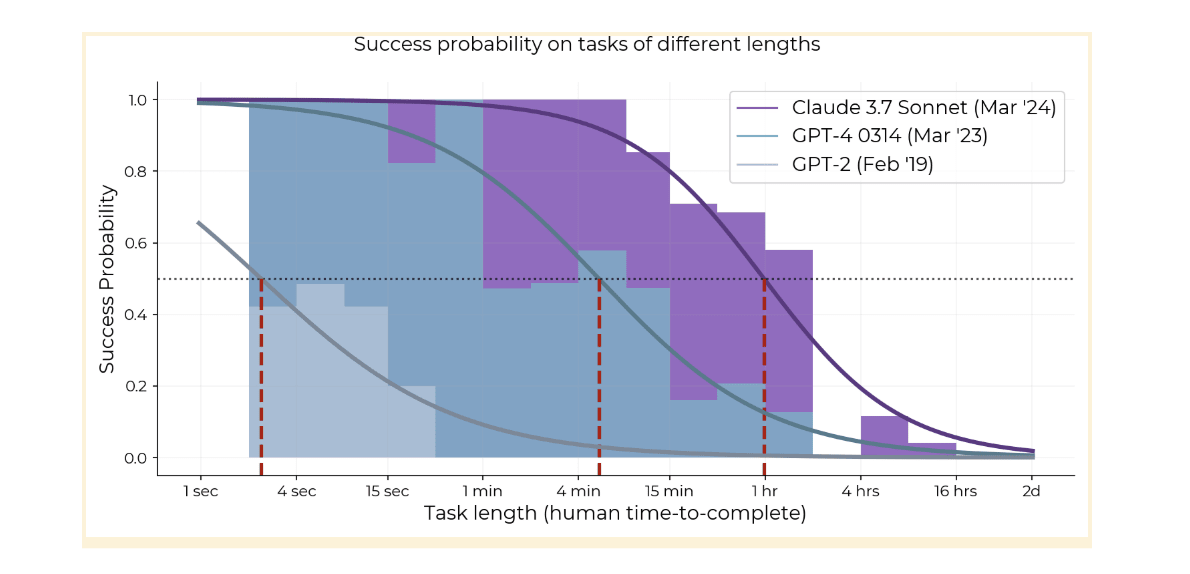
I haven’t read the paper (yet?) but from the plot I am not convinced. The points up to 2024 are too sparse, they don’t let us conclude much about that region of growth in abilities; but if they did, it would be a significantly lower slope. When the points become dense, the comparison is not fair - these are reasoning models which use far more inference time compute.
What premises would I have to accept for the comparison to be fair? Suppose I think that available compute will continue to grow along previous trends and that we'll continue to find new tricks to turn extra compute into extra capabilities. Does conditioning on that make it fair? (Not sure I accept those premises, but never mind that.)
5Cole Wyeth
The problem is deeper than that.
Playing a game of chess takes hours. LLMs are pretty bad it, but we have had good chess engines for decades - why isn’t there a point way off on the top left for chess?
Answer: we’re only interested in highly general AI agents, which basically means LLMs. So we’re only looking at the performance of LLMs, right? But if you only look at LLM performance without scaffolding, it looks to me like that asymptotes around 15 minutes. Only by throwing in systems that use a massive amount of inference time compute do we recover a line with a consistent upwards slope. So we’re allowed to use search, just not narrow search like chess engines. This feels a little forced to me - we’re putting two importantly different things on the same plot.
Here is an alternative explanation of that graph: LLMs have been working increasingly well on short tasks, but probably not doubling task length every seven months. Then after 2024, a massive amount of effort poured into trying to make them do longer tasks by paying up a high cost in inference time compute and very carefully designed scaffolding, with very modest success. It’s not clear that anyone has another (good) idea.
With that said, if the claimed trend continues for another year (now that there are actually enough data points to usefully draw a line through) that would be enough for me to start finding this pretty convincing.
Wow, this beautifully illustrates the problem with current AI (they are very smart at short tasks and poor at long tasks) and the trend of improvement against this problem.
However I want to point out that the inability to do long tasks isn't the only weakness AI have. There are plenty of 5 minute tasks which are common sense to humans but which AI fails at (and many benchmarks catch these weaknesses). It's not just the length of the task but the type of the task.
I think AI are also bad at inventing new ideas and concepts if it's too far from their training data.
Cross-posted from the EA forum, and sorry if anyone has already mentioned this, BUT:
Is the point when models hit a length of time on the x-axis of the graph meant to represent the point where models can do all tasks of that length that a normal knowledge worker could perform on a computer? The vast majority of knowledge worker tasks of that length? At least one task of that length? Some particular important subset of tasks of that length?
AIs (and humans) don't have 100% reliability at anything, so the graph tracks when AIs get a 50% success rate on our dataset, over all tasks and attempts. We also measure AI horizons at 80% success rate in the paper, and those are about 5x shorter. It's hard to measure much higher than 80% with our limited task suite, but if we could we would measure 95% and 99% as well.
2mattmacdermott
I think the commenter is asking something a bit different - about the distribution of tasks rather than the success rate. My variant of this question: is your set of tasks supposed to be an unbiased sample of the tasks a knowledge worker faces, so that if I see a 50% success rate on 1 hour long tasks I can read it as a 50% success rate on average across all of the tasks any knowledge worker faces?
Or is it more impressive than that because the tasks are selected to be moderately interesting, or less impressive because they’re selected to be measurable, etc
4Thomas Kwa
External validity is a huge concern, so we don't claim anything as ambitious as average knowledge worker tasks. In one sentence, my opinion is that our tasks suite is fairly representative of well-defined, low-context, measurable software tasks that can be done without a GUI. More speculatively, horizons on this are probably within a large (~10x) constant factor of horizons on most other software tasks. We have a lot more discussion of this in the paper, especially in heading 7.2.1 "Systematic differences between our tasks and real tasks". The HCAST paper also has a better description of the dataset.
We didn't try to make the dataset a perfectly stratified sample of tasks meeting that description, but there is enough diversity in the dataset that I'm much more concerned about relevance of HCAST-like tasks to real life than relevance of HCAST to the universe of HCAST-like tasks.
METR seems to imply 167 hours, approximately one working month, is the relevant project length for getting a well-defined, non-messy research task done.
It's interesting that their doubling time varies between 7 months and 70 days depending on which tasks and which historical time horizon they look at.
For a lower bound estimate, I'd take 70 days doubling time and 167 hrs, and current max task length one hour. In that case, if I'm not mistaken,
2^(t/d) = 167 (t time, d doubling time)
t = d*log(167)/log(2) = (70/365)*log(... (read more)
I buy this for the post-GPT-3.5 era. What's confusing me is that the rate of advancement in the pre-GPT-3.5 era was apparently the same as in the post-GPT-3.5 era, i. e., doubling every 7 months.
Why would we expect there to be no distribution shift once the AI race kicked into high gear? GPT-2 to GPT-3 to GPT-3.5 proceeded at a snail's pace by modern standards. How did the world happen to invest in them just enough for them to fit into the same trend?