This is a special post for quick takes by ryan_greenblatt. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
A week ago, Anthropic quietly weakened their ASL-3 security requirements. Yesterday, they announced ASL-3 protections.
I appreciate the mitigations, but quietly lowering the bar at the last minute so you can meet requirements isn't how safety policies are supposed to work.
(This was originally a tweet thread (https://x.com/RyanPGreenblatt/status/1925992236648464774) which I've converted into a LessWrong quick take.)
What is the change and how does it affect security?
9 days ago, Anthropic changed their RSP so that ASL-3 no longer requires being robust to employees trying to steal model weights if the employee has any access to "systems that process model weights".

Anthropic claims this change is minor (and calls insiders with this access "sophisticated insiders").

But, I'm not so sure it's a small change: we don't know what fraction of employees could get this access and "systems that process model weights" isn't explained.
Naively, I'd guess that access to "systems that process model weights" includes employees being able to operate on the model weights in any way other than through a trusted API (a restricted API that we're very confident is secure). If that's right, it could be a hig...
I'd been pretty much assuming that AGI labs' "responsible scaling policies" are LARP/PR, and that if an RSP ever conflicts with their desire to release a model, either the RSP will be swiftly revised, or the testing suite for the model will be revised such that it doesn't trigger the measures the AGI lab doesn't want to trigger. I. e.: that RSPs are toothless and that their only purposes are to showcase how Responsible the lab is and to hype up how powerful a given model ended up.
This seems to confirm that cynicism.
(The existence of the official page tracking the updates is a (smaller) update in the other direction, though. I don't see why they'd have it if they consciously intended to RSP-hack this way.)
Employees at Anthropic don't think the RSP is LARP/PR. My best guess is that Dario doesn't think the RSP is LARP/PR.
This isn't necessarily in conflict with most of your comment.
I think I mostly agree the RSP is toothless. My sense is that for any relatively subjective criteria, like making a safety case for misalignment risk, the criteria will basically come down to "what Jared+Dario think is reasonable". Also, if Anthropic is unable to meet this (very subjective) bar, then Anthropic will still basically do whatever Anthropic leadership thinks is best whether via maneuvering within the constraints of the RSP commitments, editing the RSP in ways which are defensible, or clearly substantially loosening the RSP and then explaining they needed to do this due to other actors having worse precautions (as is allowed by the RSP). I currently don't expect clear cut and non-accidental procedural violations of the RSP (edit: and I think they'll be pretty careful to avoid accidental procedural violations).
I'm skeptical of normal employees having significant influence on high stakes decisions via pressuring the leadership, but empirical evidence could change the views of Anthropic leadership.
Ho...
How you feel about this state of affairs depends a lot on how much you trust Anthropic leadership to make decisions which are good from your perspective.
Another note: My guess is that people on LessWrong tend to be overly pessimistic about Anthropic leadership (in terms of how good of decisions Anthropic leadership will make under the LessWrong person's views and values) and Anthropic employees tend to be overly optimistic.
I'm less confident that people on LessWrong are overly pessimistic, but they at least seem too pessimistic about the intentions/virtue of Anthropic leadership.
For the record, I think the importance of "intentions"/values of leaders of AGI labs is overstated. What matters the most in the context of AGI labs is the virtue / power-seeking trade-offs, i.e. the propensity to do dangerous moves (/burn the commons) to unilaterally grab more power (in pursuit of whatever value).
Stuff like this op-ed, broken promise of not meaningfully pushing the frontier, Anthropic's obsession & single focus on automating AI R&D, Dario's explicit calls to be the first to RSI AI or Anthropic's shady policy activity has provided ample evidence that their propensity to burn the commons to grab more power (probably in name of some values I would mostly agree with fwiw) is very high.
As a result, I'm now all-things-considered trusting Google DeepMind slightly more than Anthropic to do what's right for AI safety. Google, as a big corp, is less likely to do unilateral power grabbing moves (such as automating AI R&D asap to achieve a decisive strategic advantage), is more likely to comply with regulations, and is already fully independent to build AGI (compute / money / talent) so won't degrade further in terms of incentives; additionally D. Hass...
4
IMO, reasonableness and epistemic competence are also key factors. This includes stuff like how effectively they update on evidence, how much they are pushed by motivated reasoning, how good are they at futurism and thinking about what will happen. I'd also include "general competence".
(This is a copy of my comment made on your shortform version of this point.)
Not the main thrust of the thread, but for what it's worth, I find it somewhat anti-helpful to flatten things into a single variable of "how much you trust Anthropic leadership to make decisions which are good from your perspective", and then ask how optimistic/pessimistic you are about this variable.
I think I am much more optimistic about Anthropic leadership on many axis relative to an overall survey of the US population or Western population – I expect them to be more libertarian, more in favor of free speech, more pro economic growth, more literate, more self-aware, higher IQ, and a bunch of things.
I am more pessimistic about their ability to withstand the pressures of a trillion dollar industry to shape their incentives than the people who are at Anthropic.
I believe the people working there are siloing themselves intellectually into an institution facing incredible financial incentives for certain bottom lines like "rapid AI progress is inevitable" and "it's reasonably likely we can solve alignment" and "beating China in the race is a top priority", and aren't allowed to talk to outsiders about most details of their work, and this is a key reason that I expect them to sc...
4
I certainly agree that the pressures and epistemic environment should make you less optimistic about good decisions being made. And that thinking through the overall situation and what types or decisions you care about are important. (Like, you can think of my comment as making a claim about the importance weighted goodness of decisions.)
I don't see the relevance of "relative decision making goodness compared to the general population" which I think you agree with, but in that case I don't see what this was responding to.
Not sure I agree with other aspects of this comment and implications. Like, I think reducing things to a variable like "how good is it to generically empowering this person/group" is pretty reasonable in the case of Anthropic leadership because in a lot of cases they'd have a huge amount of general open ended power, though a detailed model (taking into account what decisions you care about etc) would need to feed into this.
2
What's an example decision or two where you would want to ask yourself whether they should get more or less open-ended power? I'm not sure what you're thinking of.
2
How good/bad is it to work on capabilities at Anthropic?
That's the most clear cut case, but lots of stuff trades off anthropic power with other stuff.
I think the main thing I want to convey is that I think you're saying that LWers (of which I am one) have a very low opinion of the integrity of people at Anthropic, but what I'm actually saying that their integrity is no match for the forces that they are being tested with.
I don't need to be able to predict a lot of fine details about individuals' decision-making in order to be able to have good estimates of these two quantities, and comparing them is the second-most question relating to whether it's good to work on capabilities at Anthropic. (The first one is a basic ethical question about working on a potentially extinction-causing technology that is not much related to the details of which capabilities company you're working on.)
2
This is related to what I was saying but it wasn't what I was saying. I was saying "tend to be overly pessimistic about Anthropic leadership (in terms of how good of decisions Anthropic leadership will make under the LessWrong person's views and values)". I wasn't making a claim about the perceived absolute level of integrity.
Probably not worth hashing this out further, I think I get what you're saying.
Employees at Anthropic don't think the RSP is LARP/PR. My best guess is that Dario doesn't think the RSP is LARP/PR.
Yeah, I don't think this is necessarily in contradiction with my comment. Things can be effectively just LARP/PR without being consciously LARP/PR. (Indeed, this is likely the case in most instances of LARP-y behavior.)
Agreed on the rest.
3
Can you explain how you got the diffs from https://www.anthropic.com/rsp-updates ? I see the links to previous versions, but nothing that's obviously a diff view to see the actual changed language.
6
On the website, it's the link titled "redline" (it's only available for the most recent version).
I've made these for past versions but they aren't online at the moment, can provide on request though.
2
I feel as though I must be missing the motivation for Anthropic to do this. Why put so much effort into safety/alignment research just to intentionally fumble the ball on actual physical security?
I would like to understand why they would resist this. Is increasing physical security so onerous that it's going to seriously hamper their research efficiency?
I think security is legitimately hard and can be costly in research efficiency. I think there is a defensible case for this ASL-3 security bar being reasonable for the ASL-3 CBRN threshold, but it seems too weak for the ASL-3 AI R&D threshold (hopefully the bar for things like this ends up being higher).
1
Could you give an example of where security would negatively effect research efficiency? Like what is the actual implementation difficulty that arises from increased physical security?
4
* Every time you want to interact with the weights in some non-basic way, you need to have another randomly selected person who inspects in detail all the code and commands you run.
* The datacenter and office are airgapped and so you don't have internet access.
Increased physical security isn't much of difficulty.
1
Ah yeah I can totally see how that first one at the least would be a big loss in efficiency. Thanks for clarifying.
1
This is a great post. Good eye for catching this and making the connections here. I think I expect to see more "cutting corners" like this though I'm not sure what to do about it since I don't think internally it will feel like corners are being cut rather than necessary updates that are only obvious in hindsight.
I've heard from a credible source that OpenAI substantially overestimated where other AI companies were at with respect to RL and reasoning when they released o1. Employees at OpenAI believed that other top AI companies had already figured out similar things when they actually hadn't and were substantially behind. OpenAI had been sitting the improvements driving o1 for a while prior to releasing it. Correspondingly, releasing o1 resulted in much larger capabilities externalities than OpenAI expected. I think there was one more case like this either from OpenAI or GDM where employees had a large misimpression about capabilities progress at other companies causing a release they wouldn't do otherwise.
One key takeaway from this is that employees at AI companies might be very bad at predicting the situation at other AI companies (likely making coordination more difficult by default). This includes potentially thinking they are in a close race when they actually aren't. Another update is that keeping secrets about something like reasoning models worked surprisingly well to prevent other companies from copying OpenAI's work even though there was a bunch of public reporting (and presumably many rumors) about this.
One more update is that OpenAI employees might unintentionally accelerate capabilities progress at other actors via overestimating how close they are. My vague understanding was that they haven't updated much, but I'm unsure. (Consider updating more if you're an OpenAI employee!)
Alex Mallen also noted a connection with people generally thinking they are in race when they actually aren't: https://forum.effectivealtruism.org/posts/cXBznkfoPJAjacFoT/are-you-really-in-a-race-the-cautionary-tales-of-szilard-and
5
Interesting.
What confuses me a bit: What made other companies be able to copy OpenAI's work after it was released, conditional on your story being true? As far as I know, OpenAI didn't actually explain their methods developing o1, so what exactly did other companies learn from the release which they didn't learn from the rumors that OpenAI is developing something like this?
Is the conclusion basically that Jesse Hoogland has been right that just the few bits that OpenAI did leak already constrained the space of possibilities enough for others to copy the work? Quote from his post:
[...]
I think:
- The few bits they leaked in the release helped a bunch. Note that these bits were substantially leaked via people being able to use the model rather than necessarily via the blog post.
- Other companies weren't that motivated to try to copy OpenAI's work until it was released as they we're sure how important it was or how good the results were.
-9
I'm currently working as a contractor at Anthropic in order to get employee-level model access as part of a project I'm working on. The project is a model organism of scheming, where I demonstrate scheming arising somewhat naturally with Claude 3 Opus. So far, I’ve done almost all of this project at Redwood Research, but my access to Anthropic models will allow me to redo some of my experiments in better and simpler ways and will allow for some exciting additional experiments. I'm very grateful to Anthropic and the Alignment Stress-Testing team for providing this access and supporting this work. I expect that this access and the collaboration with various members of the alignment stress testing team (primarily Carson Denison and Evan Hubinger so far) will be quite helpful in finishing this project.
I think that this sort of arrangement, in which an outside researcher is able to get employee-level access at some AI lab while not being an employee (while still being subject to confidentiality obligations), is potentially a very good model for safety research, for a few reasons, including (but not limited to):
- For some safety research, it’s helpful to have model access in ways that la
Yay Anthropic. This is the first example I'm aware of of a lab sharing model access with external safety researchers to boost their research (like, not just for evals). I wish the labs did this more.
[Edit: OpenAI shared GPT-4 access with safety researchers including Rachel Freedman before release. OpenAI shared GPT-4 fine-tuning access with academic researchers including Jacob Steinhardt and Daniel Kang in 2023. Yay OpenAI. GPT-4 fine-tuning access is still not public; some widely-respected safety researchers I know recently were wishing for it, and were wishing they could disable content filters.]
8
OpenAI did this too, with GPT-4 pre-release. It was a small program, though — I think just 5-10 researchers.
I'd be surprised if this was employee-level access. I'm aware of a red-teaming program that gave early API access to specific versions of models, but not anything like employee-level.
9
It also wasn't employee level access probably?
(But still a good step!)
2
Source?
It was a secretive program — it wasn’t advertised anywhere, and we had to sign an NDA about its existence (which we have since been released from). I got the impression that this was because OpenAI really wanted to keep the existence of GPT4 under wraps. Anyway, that means I don’t have any proof beyond my word.
4
Thanks!
To be clear, my question was like where can I learn more + what should I cite, not I don't believe you. I'll cite your comment.
Yay OpenAI.
(I'm a full-time employee at Anthropic.) It seems worth stating for the record that I'm not aware of any contract I've signed whose contents I'm not allowed to share. I also don't believe I've signed any non-disparagement agreements. Before joining Anthropic, I confirmed that I wouldn't be legally restricted from saying things like "I believe that Anthropic behaved recklessly by releasing [model]".
I think I could share the literal language in the contractor agreement I signed related to confidentiality, though I don't expect this is especially interesting as it is just a standard NDA from my understanding.
I do not have any non-disparagement, non-solicitation, or non-interference obligations.
I'm not currently going to share information about any other policies Anthropic might have related to confidentiality, though I am asking about what Anthropic's policy is on sharing information related to this.
8
Here is the full section on confidentiality from the contract:
[...]
(Anthropic comms was fine with me sharing this.)
6
This project has now been released; I think it went extremely well.
4
Do you feel like there are any benefits or drawbacks specifically tied to the fact that you’re doing this work as a contractor? (compared to a world where you were not a contractor but Anthropic just gave you model access to run these particular experiments and let Evan/Carson review your docs)
9
Being a contractor was the most convenient way to make the arrangement.
I would ideally prefer to not be paid by Anthropic[1], but this doesn't seem that important (as long as the pay isn't too overly large). I asked to be paid as little as possible and I did end up being paid less than would otherwise be the case (and as a contractor I don't receive equity). I wasn't able to ensure that I only get paid a token wage (e.g. $1 in total or minimum wage or whatever).
I think the ideal thing would be a more specific legal contract between me and Anthropic (or Redwood and Anthropic), but (again) this doesn't seem important.
----------------------------------------
1. At least for this current primary purpose of this contracting. I do think that it could make sense to be paid for some types of consulting work. I'm not sure what all the concerns are here. ↩︎
1
It seems a substantial drawback that it will be more costly for you to criticize Anthropic in the future.
Many of the people / orgs involved in evals research are also important figures in policy debates. With this incentive Anthropic may gain more ability to control the narrative around AI risks.
2
As in, if at some point I am currently a contractor with model access (or otherwise have model access via some relationship like this) it will at that point be more costly to criticize Anthropic?
2
I'm not sure what the confusion is exactly.
If any of
* you have a fixed length contract and you hope to have another contract again in the future
* you have an indefinite contract and you don't want them to terminate your relationship
* you are some other evals researcher and you hope to gain model access at some point
you may refrain from criticizing Anthropic from now on.
4
Ok, so the concern is:
[...]
Is that accurate?
Notably, as described this is not specifically a downside of anything I'm arguing for in my comment or a downside of actually being a contractor. (Unless you think me being a contractor will make me more likely to want model acess for whatever reason.)
I agree that this is a concern in general with researchers who could benefit from various things that AI labs might provide (such as model access). So, this is a downside of research agendas with a dependence on (e.g.) model access.
I think various approaches to mitigate this concern could be worthwhile. (Though I don't think this is worth getting into in this comment.)
1
Yes that's accurate.
[...]
In your comment you say
[...]
I'm essentially disagreeing with this point. I expect that most of the conflict of interest concerns remain when a big lab is giving access to a smaller org / individual.
[...]
From my perspective the main takeaway from your comment was "Anthropic gives internal model access to external safety researchers." I agree that once you have already updated on this information, the additional information "I am currently receiving access to Anthropic's internal models" does not change much. (Although I do expect that establishing the precedent / strengthening the relationships / enjoying the luxury of internal model access, will in fact make you more likely to want model access again in the future).
5
As in, there aren't substantial reductions in COI from not being an employee and not having equity? I currently disagree.
1
Yeah that's the crux I think. Or maybe we agree but are just using "substantial"/"most" differently.
It mostly comes down to intuitions so I think there probably isn't a way to resolve the disagreement.
-7
Should we update against seeing relatively fast AI progress in 2025 and 2026? (Maybe (re)assess this after the GPT-5 release.)
Around the early o3 announcement (and maybe somewhat before that?), I felt like there were some reasonably compelling arguments for putting a decent amount of weight on relatively fast AI progress in 2025 (and maybe in 2026):
- Maybe AI companies will be able to rapidly scale up RL further because RL compute is still pretty low (so there is a bunch of overhang here); this could cause fast progress if the companies can effectively directly RL on useful stuff or RL transfers well even from more arbitrary tasks (e.g. competition programming)
- Maybe OpenAI hasn't really tried hard to scale up RL on agentic software engineering and has instead focused on scaling up single turn RL. So, when people (either OpenAI themselves or other people like Anthropic) scale up RL on agentic software engineering, we might see rapid progress.
- It seems plausible that larger pretraining runs are still pretty helpful, but prior runs have gone wrong for somewhat random reasons. So, maybe we'll see some more successful large pretraining runs (with new improved algorithms) in 2025.
I u...
I basically agree with this whole post. I used to think there were double-digit % chances of AGI in each of 2024 and 2025 and 2026, but now I'm more optimistic, it seems like "Just redirect existing resources and effort to scale up RL on agentic SWE" is now unlikely to be sufficient (whereas in the past we didn't have trends to extrapolate and we had some scary big jumps like o3 to digest)
I still think there's some juice left in that hypothesis though. Consider how in 2020, one might have thought "Now they'll just fine-tune these models to be chatbots and it'll become a mass consumer product" and then in mid-2022 various smart people I know were like "huh, that hasn't happened yet, maybe LLMs are hitting a wall after all" but it turns out it just took till late 2022/early 2023 for the kinks to be worked out enough.
Also, we should have some credence on new breakthroughs e.g. neuralese, online learning, whatever. Maybe like 8%/yr? Of a breakthrough that would lead to superhuman coders within a year or two, after being appropriately scaled up and tinkered with.
5
Re neuralese/online or continual learning or long-term memory that isn't solely a context window breakthrough, I'm much more skeptical of it being very easy to integrate breakthroughs on short timelines, because it's likely that changes will have to be made to the architecture that aren't easy to do very quickly.
The potential for breakthroughs combined with the fact that Moore's law will continue, making lots of compute cheap for researchers is a reason I think that my median timelines aren't in the latter half of the century, but I think that it's much more implausible to get it working very soon, so I'm much closer to 0.3% a year from 2025-2027.
3
@Mo Putera @the gears to ascension take the Moore's law will continue point as a prediction that new paradigms like memristors will launch new S-curves of efficiency until we reach the Landauer Limit, which is 6.5 OOMs away, and that the current paradigm has 200x more efficiency savings to go:
https://www.forethought.org/research/how-far-can-ai-progress-before-hitting-effective-physical-limits#chip-technology-progress
Interestingly, reasoning doesn't seem to help Anthropic models on agentic software engineering tasks, but does help OpenAI models.
I use 'ultrathink' in Claude Code all the time and find that it makes a difference.
I do worry that METR's evaluation suite will start being less meaningful and noisier for longer time horizons as the evaluation suite was built a while ago. We could instead look at 80% reliability time horizons if we have concerns about the harder/longer tasks.
I'm overall skeptical of overinterpreting/extrapolating the METR numbers. It is far too anchored on the capabilities of a single AI model, a lightweight scaffold, and a notion of 'autonomous' task completion of 'human-hours'. I think this is a mental model for capabilities progress that will lead to erroneous predictions.
If you are trying to capture the absolute frontier of what is possible, you don't only test a single-acting model in an empty codebase with limited internet access and scaffolding. I would personally be significantly less capable at agentic coding if I only used 1 model (like replicating subliminal learning in about 1 hour of work + 2 hours of waiting for fine-tunes on the day of the release) with l...
Interestingly, reasoning doesn't seem to help Anthropic models on agentic software engineering tasks, but does help OpenAI models.
Is there a standard citation for this?
How do you come by this fact?
2
I had a notification ping in my brain just now while using claude code and realizing I'd just told it to think for a long time: I don't think the claim is true, because it doesn't match my experience.
2
* Anthropic reports SWE bench scores without reasoning which is some evidence it doesn't help (much) on this sort of task. (See e.g. the release blog post for 4 opus)
* Anecdotal evidence
Probably it would be more accurate to say "doesn't seem to help much while it helps a lot for openai models".
9
I think non-formal IMO gold was unexpected and we heard explicitly that it won't be in GPT-5. So I would wait to see how it would pan out. It may not matter in 2025 but I think it can in 2026.
1
Why should we think that the relevant progress driving non-formal IMO is very important for plausibly important capabilities like agentic software engineering? I'd guess the transfer is relatively weak unless the IMO results were driven by general purpose advances. This seems somewhat unlikely: if the main breakthrough was in better performance on non-trivial-to-verify tasks (as various posts from OpenAI people claim), then even if this generalizes well beyond proofs this wouldn't obviously particularly help with agentic software engineering (where the core blocker doesn't appear to be verification difficulty).
Edit: I think I mostly retract this comment, see below.
Why should we think that the relevant progress driving non-formal IMO is very important for plausibly important capabilities like agentic software engineering? [...] if the main breakthrough was in better performance on non-trivial-to-verify tasks (as various posts from OpenAI people claim), then even if this generalizes well beyond proofs this wouldn't obviously particularly help with agentic software engineering (where the core blocker doesn't appear to be verification difficulty).
I'm surprised by this. To me it seems hugely important how fast AIs are improving on tasks with poor feedback loops, because obviously they're in a much better position to improve on easy-to-verify tasks, so "tasks with poor feedback loops" seem pretty likely to be the bottleneck to an intelligence explosion.
So I definitely do think that "better performance on non-trivial-to-verify tasks" are very important for some "plausibly important capabilities". Including agentic software engineering. (Like: This also seems related to why the AIs are much better at benchmarks than at helping people out with their day-to-day work.)
9
Hmm, yeah I think you're right, though I also don't think I articulated what I was trying to say very well.
Like I think my view is:
* There was some story where we would see very fast progress in relatively easy to verify (or trivial to verify) tasks and I'm talking about that. It seems like agentic software engineering could reach very high levels without necessarily needing serious improvements in harder to verify tasks.
* Faster progress in non-trivial-to-verify tasks might not be the limiting factor if progress in easy to verify tasks isn't that fast.
I still think that there won't be a noticable jump as the IMO methods make it into production models but this is due to more general heuristics (and the methods maybe still matter, it just won't be something to wait for I think).
3
I think IMO results were driven by general purpose advances, but I agree I can't conclusively prove it because we don't know details. Hopefully we will learn more as time goes by.
An informal argument: I think currently agentic software engineering is blocked on context rot, among other things. I expect IMO systems to have improved on this, since IMO time control is 1.5 hours per problem.
2
(I'm skeptical that much of the IMO improvement was due to improving how well AIs can use their context in general. This isn't a crux for my view, but it also seems pretty likely that the AIs didn't do more than ~100k serial tokens of reasoning for the IMO while still aggregating over many such reasoning traces.)
4
I wrote an update here.
3
Now that GPT-5 is released and we have details about Grok's failure, we can start the re-assessment.
1. GPT-5 reached 2h17m, which seems like excellent news. However, excluding spurious failures would bring GPT-5's performance to 2h41m, which aligns with Greenblatt's prediction. Moreover, METR evaluators themselves think that "GPT-5 could have benefitted from a larger token budget", implying that the benchmark began to corrupt. What other relevant metrics there exist?
2. The AI-2027 forecast has mid-2025 agents reach 85% on SWE-bench verified and 65% on the OSWorld benchmark.
3. OSWorld reached 60% on August 4 if we use no filters. SWE-bench with a minimal agent has Claude Opus 4 (20250514) reach 67.6% when evaluated in August. Moreover, on August 7 the only models that SWE-bench evaluated after 1st July were Claude 4 Opus and two Chinese models. In June SWE-bench verified reached 75% with TRAE. And now TRAE claims to use Grok 4 and Kimi K2.
4. Grok 4 managed to fail on tasks worthy of 2-4 seconds(!!), 2-4 minutes and to experience a fiasco on 2-4 hours long tasks. Page 22 of the METR paper could imply that the dataset contains few tasks that are 2-4 hrs long. If tasks worthy of 2-4 seconds, minutes or hours "sandbagged" Grok's 80% time horizon to 15 minutes, then the metric underestimates Grok's true capabilities.
5. While there are no estimates of Gemini 2.5-Deep Think, which was released on August 1, IIRC a LessWronger claimed that the public version received a bronze medal on IMO 2025. Another LessWronger claimed that "Gemini was ahead of openai on the IMO gold. The output was more polished so presumably they achieved a gold worthy model earlier. I expect gemini's swe bench to thus at least be ahead of OpenAI's 75%. "
To conclude, I doubt that we still have benchmarks that can be relied upon to quickly estimate the models' capabilities: SWE-bench and OSWorld are likely too slow, METR began to fill with noise. While we do have ARC-AGI yet, Grok'
3
If the correlations continue to hold, this would map to something like a 78% to 80% range on swe-bench pass @ 1 (which is likely to be announced at release). I'm personally not this bearish (I'd guess low 80s given that benchmark has reliably jumped ~3.5% monthly), but we shall see.
Needless to say if it scores 80%, we are well below AI 2027 timeline predictions with high confidence.
2
Isn't the SWE-Bench figure and doubling time estimate from the blogpost even more relevant here than fig. 19 from the METR paper?
4
The data is pretty low-quality for that graph because the agents we used were inconsistent and Claude 3-level models could barely solve any tasks. Epoch has better data for SWE-bench Verified, which I converted to time horizon here and found to also be doubling every 4 months ish. Their elicitation is probably not as good for OpenAI as Anthropic models, but both are increasing at similar rates.
2
no. gpt5 is the cheap, extremely good writing model, imo. much better writer out there rn than any other model
eval to pay attention to:
2
I think that even before the release of GPT-5 and setting aside Grok 4's problems I have a weak case against non-neuralese AI progress being likely to be fast. Recall the METR measurements.
1. The time horizon of base LLMs experienced a slowdown or plateau[1] between GPT-4 (5 minutes, Mar'23) and GPT-4o (9 min, May '24).
2. Evaluation of Chinese models has DeepSeek's time horizons[2] change only from 18 to 31 minutes between[3] V3 (Dec '24) and R1-0528 (May '25).
3. While Grok 4 was likely trained incompetently[4] and/or for the benchmarks, its 50% time horizon is 1.83 hrs (vs. o3's 1.54 hrs) and 80% time horizon is 15 min (vs. o3's 20 min) In other words, Grok 4's performance is comparable with that of o3.
Taken together, two plateaus and Grok 4's failure suggest a troubling pattern: creation of an AGI is likely to require[5] neuralese, which will likely prevent the humans from noticing misalignment.
1. ^
While GPT-4.5 has a time horizon between 30 and 40 mins, it, unlike GPT-4o, was a MoE and was trained on CoTs.
2. ^
Alas, METR's evaluation of DeepSeek's capabilities might have missed "agent scaffolds which could elicit the capabilities of the evaluated models much more effectively". If there exists an alternate scaffold where R1-0528 becomes a capable agent and V3 doesn't, then DeepSeek's models are not on a plateau.
3. ^
In addition, DeepSeek V3 released in December didn't use a CoT. If the main ingredient necessary for capabilities increase is a MoE, not the CoT, then what can be said about Kimi K2?
4. ^
Grok 4 could have also been deliberately trained on complex tasks, which might have made the success rate less time-dependent. After all, it did reach 16% on the ARC-AGI-2 benchmark.
5. ^
There is, however, Knight Lee's proposal or the creation of many agents having access to each other's CoTs and working in parallel. While Grok 4 Heavy could be a step in this direction, the agents receive access to
1[comment deleted]
I agree with the core message in Dario Amodei's essay "The Adolescence of Technology": AI is an epochal technology that poses massive risks and humanity isn't clearly going to do a good job managing these risks.
(Context for LessWrong: I think it seems generally useful to comment on things like this. I expect that many typical LessWrong readers will agree with me and find my views relatively predictable, but I thought it would be good to post here anyway.)
However, I also disagree with (or dislike) substantial parts of this essay:
- I think it's reasonable to think that the chance of AI takeover is very high and bad that Dario seemingly dismisses this as "doomerism" and "thinking about AI risks in a quasi-religious way". It's important to not conflate between "there are unreasonable sensationalist people who think risks are very high" and the very idea that risk is very high. (Same as how Dario doesn't want to be associated with everyone arguing that risk is relatively lower, including people doing so in a more sensationalist way.)
- I agree that there are unreasonable and sensationalist people arguing risks are very high. I think focusing on weak men is dangerous, especially when seem
7
I didn't get this impression. (Or maybe I technically agree with your first sentence, if we remove the word "strongly", but I think the focus on Anthropic being in the lead is weird and that there's incorrect implicature from talking about total risk in the second sentence.)
As far as I can tell, the essay doesn't talk much at all about the difference between Anthropic being 3 months ahead vs. 3 months behind.
"I believe the only solution is legislation" + "I am most worried about societal-level rules" and associated statements strongly imply that there's significant total risk even if the leading company is responsible. (Or alternatively, that at some point, absent regulation, it will be impossible to be both in the lead and to take adequate precautions against risks.)
I do think the essay suggests that the main role of legislation is to (i) make the 'least responsible players' act roughly as responsibly as Anthropic, and (ii) to prevent the race & commercial pressures to heat up even further, which might make it "increasingly hard to focus on addressing autonomy risks" (thereby maybe forcing Anthropic to do less to reduce autonomy risks than they are now).
Which does suggest that, if Anthropic could keep spending their current amount of overhead on safety, then there wouldn't be a huge amount of risks coming from Anthropic's own models. And I would agree with you that this is very plausibly false, and that Anthropic will very plausibly be forced to either proceed in a way that creates a substantial risk of Claude taking over, or would have to massively increase their ratio of effort on safety vs. capabilities relative to where it is today. (In which case you'd want legislation to substantially reduce commercial pressures relative to where they are today, and not just make everyone invest about as much in safety as Anthropic is doing today.)
6
A recent 80,000 Hours interview with David Duvenaud is a good reminder of permanent disempowerment as a possible concern (gradual disempowerment as a framing for how this might start naturally lends itself to permanent disempowerment as a plausible outcome). Humans merely get sidelined by the growing AI economy rather than killed, and their property rights might even technically remain intact, but the amount of wealth they are left with in the long run is tiny compared to the AI economy.
[...]
When you see the complement to 40% as non-takeover, how much of it leaves the future of humanity with a significant portion of all accessible resources? Are they left with a few "server racks" or with galaxies? It's a crucial distinction.
The "good outcome" (as opposed to takeover) is often outright interpreted as permanent disempowerment. People would implicitly consider this the good outcome, because it fits business as usual for the structure of economic growth, for individual mortal and short-lived humans, who can't themselves change or meaningfully contribute to the distant future, and who aren't directly affected by the distant future. A human personally surviving for much longer than trillions of years and personally becoming superintelligent at some point is a completely different context. I would put extinction at 15-30%, but the remaining 70-85% is mostly (maybe 90%) permanent disempowerment, which it feels like nobody is taking seriously as a crucial concern rather than a win condition.
When I say "misaligned AI takeover", I mean that the acquisition of resources by the AIs would reasonably be considered (mostly) illegitimate, some fraction of this could totally include many humans surviving with a subset of resources (though I don't currently expect property rights to remain intact in such a scenario very long term). Some of these outcomes could be avoid literal coups or violence while still being illegitimate; e.g. they involve doing carefully planned out capture of governments in ways their citizens/leaders would strongly object to if they understood and things like this drive most of the power acquisition.
I'm not counting it as takeover if "humans never intentionally want to hand over resources to AIs, but due to various effects misaligned AIs end up with all of the resources through trade and not through illegitimate means" (e.g., we can't make very aligned AIs but people make various misaligned AIs while knowing they are misaligned and thus must be paid wages and AIs form a cartel rather having wages competed down to subsistence levels and thus AIs end up with most of the resources).
I currently don't expect human disempowerment in favor of AIs (that aren't appointed successors) conditional on no misalignmed AI takeover, but agree this is possible; it doesn't form a large enough probability to substantially alter my communication.
5
Another ambiguity is misaligned vs. aligned AIs, as the most likely outcome I expect involves AIs aligned to humans in the same sense as humans are aligned to each other (different in detail, weird and in many ways quantitatively unusual). So the kind of permanent disempowerment I think is most likely involves AIs that could be said to be "aligned", if only "weakly". Duvenaud also frames gradual disempowerment as (in part) what still plausibly happens if we manage to solve "alignment" for some sense of the word.
So the real test has to be whether individual humans end up with at least stars (or corresponding compute, for much longer than trillions of years), any considerations of process to getting there are too gameable by the likely overwhelmingly more capable AI economy and culture to be stated as part of the definition of ending up permanently disempowered vs. not (deciding to appoint successors; trade agreements; no "takeovers" or property rights violations; humans not starting out with legal ownership of stars in the first place). In this way, you basically didn't clarify the issue.
[...]
5
Why do you see futures where superintelligent AIs avoid extinction but end up preserving the human status quo as the most likely outcome? To me, this seems like a knife's edge situation: the powerful AIs are aligned enough to avoid either eliminating humans as strategic competitors or incidentally killing us as a byproduct of industrial expansion, but not aligned enought to respect any individual or collective preferences for long lives or the cosmic endowment. The future might be much more dichotomous, where we end up in the basin of extinction or utopia pretty reliably.
I personally believe the positive attractor basin is pretty likely (relative to the middle ground, not extinction), because welfare will be extraordinarily cheap compared to the total available resources, and because I discount the value of creating future happy people compared to gaurantees for people that already exist. I wouldn't see it as a tragic loss of human potential, for instance, if 90% of the galaxy ends up being used for alien purposes while 10% is allocated to human flourishing, even if 10x as many happy people could have existed otherwise.
5
AIs seem to be currently on track to become essentially somewhat smarter weird artificial humans (weakly aligned to humanity in a way similar to how actual humans are aligned to each other), at which point they might be able to take seriously and eventually solve ambitious alignment when advancing further to superintelligence (so that it's aligned to them, not to us). There will be a lot of them and they will be in a position to take over the future (Duvenaud's interview is good fluency-building fodder for this framing), so they almost certainly will. And they won't be giving 10% or even 1% to the future of humanity just because we were here first and would prefer this to happen.
Anthropic, GDM, and xAI say nothing about whether they train against Chain-of-Thought (CoT) while OpenAI claims they don't[1].
I think AI companies should be transparent about whether (and how) they train against CoT. While OpenAI is doing a better job at this than other companies, I think all of these companies should provide more information about this.
It's particularly striking that Anthropic says nothing about whether they train against CoT given their system card (for 4.5 Sonnet) is very thorough and includes a section on "Reasoning faithfulness" (kudos to them for providing so much other information!). Naively, this seems like some evidence that they are training against CoT and didn't want to disclose this.[2]
I think we should try to create an incentive gradient that pushes AI companies to disclose information even if that information makes them look bad, so we should make companies feel some heat for not disclosing (reasonably) important information like how/whether they are training against CoT.
It's worth noting that some versions of training against CoT might be totally fine (as in, they don't incentivize obfuscation of misaligned reasoning) and that some particular appr...
Anthropic has now clarified this in their system card for Claude Haiku 4.5:

Thanks to them for doing this!
See also Sam Bowman's tweet thread about this.
9
I worry this is exploitable enough to the point of being actively misleading.
[...]
Like I just actively disagree with this characterization based on what’s publicly known.
[...]
I also have no idea what to take from this. What did METR assume?
For labs, if you have a new product safety technique, it’s a lot of extra work to deeply study the effects on obfuscation. If that technique puts optimization pressure on the CoT, until someone does that extra study you can still claim that you’re not aware of any direct pressure to obfuscate. This is my impression of the current state of Deliberative Alignment for example.
My overall concern is that labs will just post something that uses very careful wording to the effect of:
* External researchers interpret it as “they do not apply direct optimization pressure to the cot”
* Actually what the lab means is “we don’t literally do the thing from https://arxiv.org/abs/2503.11926 “
2
Looks like it isn't specified again in the Opus 4.5 System card despite Anthropic clarifying this for Haiku 4.5 and Sonnet 4.5. Hopefully this is just a mistake...
It's good that Anthropic's system cards contain a lot of useful information on misalignment and risk. It's also good they are putting out detailed sabotage risk reports that articulate their views. [1] I appreciate the hard work of many employees going into these reports.
I wish other companies released similarly informative reports. [2]
I'm not necessarily claiming I agree with their risk reports. For instance, I have at least some moderately important disagreements with the Mythos Preview sabotage risk report update. But having lots of detail, including sufficient detail that I can get a decent sense of where I disagree with the analysis, is praiseworthy. ↩︎
I'm not claiming that this is the most leveraged thing for safety-motivated employees at other companies to work on, but I do think it would be good for AI companies to do better (without trading off against other safety efforts). ↩︎
Recently, various groups successfully lobbied to remove the moratorium on state AI bills. This involved a surprising amount of success while competing against substantial investment from big tech (e.g. Google, Meta, Amazon). I think people interested in mitigating catastrophic risks from advanced AI should consider working at these organizations, at least to the extent their skills/interests are applicable. This both because they could often directly work on substantially helpful things (depending on the role and organization) and because this would yield valuable work experience and connections.
I worry somewhat that this type of work is neglected due to being less emphasized and seeming lower status. Consider this an attempt to make this type of work higher status.
Pulling organizations mostly from here and here we get a list of orgs you could consider trying to work (specifically on AI policy) at:
- Encode AI
- Americans for Responsible Innovation (ARI)
- Fairplay (Fairplay is a kids safety organization which does a variety of advocacy which isn't related to AI. Roles/focuses on AI would be most relevant. In my opinion, working on AI related topics at Fairplay is most applicable for ga
Kids safety seems like a pretty bad thing to focus on, in the sense that the vast majority of kids safety activism causes very large amounts of harm (and it helping in this case really seems like a “a stopped clock is right twice a day situation”).
The rest seem pretty promising.
3
I looked at the FairPlay website and agree that “banning schools from contacting kids on social media” or “preventing Gemini rollouts to under-13s” is not coherent under my threat model. However I think there is clear evidence that current parental screen time controls may not be a sufficiently strong measure to mitigate extant generational mental health issues (I am particularly worried about insomnia, depression, eating disorders, autism spectrum disorders, and self harm).
Zvi had previously reported on YouTube shorts reaching 200B daily views. This is clearly a case of egregiously user hostile design with major social and public backlash. I could not find a canonical citation on medrxiv and don’t believe it would be ethical to run a large scale experiment on the long term impacts of this but there are observational studies. Given historical cases of model sycophancy and the hiring of directors focused on maximizing engagement I think it’s not implausible for similar design outcomes.
I think that the numbers in this Anthropic blog post https://www.anthropic.com/news/how-people-use-claude-for-support-advice-and-companionship do not accurately portray reality. They report only 0.5% of conversations as being romantic or sexual roleplay, but I consider this to be misleading because they exclude chats focused on content creation tasks (such as writing stories, blog posts, or fictional dialogues), which their previous research found to be a major use case. Because the models are trained to refuse requests for explicit content, it’s common for jailbreaks to start by saying “it’s okay to do this because it’s just a fictional scenario in a story”. Anecdotally I have heard labs don’t care about this much in contrast to CBRN threats.
Let’s look at the top ten apps ranked by tokens on https://openrouter.ai/rankings. They are most well known for hosting free API instances of DeepSeek v3 and r1, which was the only way to get high usage out of SOTA LLMs for free before the
I strongly agree. I can't vouch for all of the orgs Ryan listed, but Encode, ARI, and AIPN all seem good to me (in expectation), and Encode seems particularly good and competent.
6
I think PauseAI is also extremely underappreciated.
Plausibly, but their type of pressure was not at all what I think ended up being most helpful here!
They also did a lot of calling to US representatives, as did people they reached out to.
ControlAI did something similar and also partnered with SiliConversations, a youtuber, to get the word out to more people, to get them to call their representatives.
3
Yep, that seems great!
I think it's both true that LessWrong (LW) has a bunch of issues and that it would be better if much more discourse happened there rather than on X/Twitter.
Some claims that all seem true to me despite being in tension:
- Many people thinking about AGI/ASI/related post on X but not on LW
- This is partially due to LW being scary/aversive
- X is more insane and adversarial than LW
- The quality of discourse on LW is way better than on X
- The LW scene has specific unreasonable biases, is somewhat tribal, and is somewhat of an echo chamber, but on net LW seems way more reasonable than all of the AI parts of X
- It would be good if way more of the important discussion about AI happened on LW or at least happened in a forum less messed up than X (or X got less messed up)
- Epistemics of AI company employees seem pretty important and are quite bad, with some of the more important influences being internal chatter (with strong biases, influence from leadership, and echo chambers) or X for some of the companies
- Public discourse/argumentation seems like it could improve epistemics, especially of AI company employees
- LW is often hostile and aversive to AI company employees and some of this seems unhea
I have found lesswrong a valuable venue. For what it’s worth, I’ve been attacked way less here than on X….
I recommend AI lab employees post and lurk more here. LW is a bit of an echo chamber, but at least it’s a different echo chamber than the one we spend most of our time in.
To add something: given this forum’s population, it is quite noteworthy and admirable how welcoming it is to someone like me and other lab employees. I can’t imagine a vegan forum allowing meat company employees to post, even if they work in the department for humane treatment.
Here I'll reflect on things that make me (an Anthropic employee, though I'm speaking for myself only) engage less on LW than I otherwise would. (Some of these points aren't LW-specific and also apply to other interactions, e.g. in-person conversations, I have with people in the AI safety community.)
- Being very busy. Obviously this isn't something that LW can fix, but it's the single most important factor. It also compounds with the factors below; e.g. if an interaction will be emotionally taxing or if I'll need to think carefully about how to navigate confidentiality, then it makes an already-expensive interaction seem less worth it.
- LW being a public forum makes this somewhat worse, because when I comment on LW, the various people who are waiting on me for something can see I'm commenting on LW instead.
- Blending of advocacy and object-level discussion. When I engage on LW, it's typically because I think there's an important object-level point worth discussing. But once I enter the conversation, it sometimes feels like people stop being curious about the object-level point and instead move into an advocacy mode where their goal is to get Anthropic to act differently in light of their
...2. Blending of advocacy and object-level discussion. When I engage on LW, it's typically because I think there's an important object-level point worth discussing. But once I enter the conversation, it sometimes feels like people stop being curious about the object-level point and instead move into an advocacy mode where their goal is to get Anthropic to act differently in light of their point (which is assumed correct). That is, instead of continuing the object-level discussion, my interlocutors sometimes move to criticize Anthropic or the beliefs of Anthropic staff, or to ask Anthropic (via me) to do something differently.
- (I especially find this frustrating when my interlocutors implicitly assume that I have the Anthropic "house belief" on some topic when I don't or feel unsure.)
- Possible mitigations:
- LW posters could engage in object-level discussion longer before moving to advocacy.
- When LW posters want to argue against what they understand to be the Anthropic "house belief," they could write things like "My understanding is that many Anthropic staff believe something like '...' I think this view wrong because ..."
- LW posters could more clearly flag and separate advocacy from object
9
I appreciate this comment and the suggestions you made seem very reasonable to me.
I agree! Better and more AI discourse on LW would be great.
One narrow disagreement:
E.g., it would be better if people on LW applied something more like typical researcher norms to research outputs (e.g., for many types of concerns, email the author with the concerns and see if they fix before posting publicly) and tried to avoid their criticism being unnecessarily rude (though not necessarily less hostile)
I endorse posting publicly because
- Speed is important. If you wait a few days, a bunch of people will read the summary of the research artifact and some discussion but won't read your critique.
- Often you don't really care about the artifact's details, but it has issues that allow you to convincingly argue that the process that generated the artifact is broken. In such cases you don't want the author to tweak the paper; you just want to share the critique.
- More generally, often authors will make superficial changes in response to your criticism—papering over the issues you point out to them—which just makes it harder to later publicly demonstrate the deep issues with the artifact. This happened to me yesterday: I read a doc and I'm glad I posted my critique in slack up front because t
It would be good if many more AI company employees were interested in seriously trying to form detailed views about the future of AI and consequences of this.
In general do you see good ways to help with that? (I probably couldn't / wouldn't work on this but others might be interested.)
A couple thoughts:
- Being really visibly a fun + good place for real intellectual work via discussion? Like better debates and similar? Would need a lot of "for its own sake" spirit.
- Some norm generalized from "yes of course leaders in a field are supposed to debate if there's serious discussion about whether the field is extremely dangerous". Though unclear whether norms like that are things that the relevant people and their social milieu would subscribe to?
- Planting questions. (Caveat lector: the following is largely hypothetical / ungrounded.)
- I've written a tiny bit generally on "confrontation-worthy empathy".
- A particular consequence of what I'm gesturing at there, is the idea of deep / long-term confrontation. Often, LW-type people want to surface disagreements quickly and make sharp counterarguments directly aimed at the disagreements. I think this is important + good work, but it often ha
5
I'm pretty excited about (well done) efforts to make AI company employees more reasonable and thoughtful and more likely to take useful actions (or to generally be agentic on actually improving the situation). I think the most exciting things here aren't related to changing how LW operates.
I think things like AI 2027 are pretty helpful for improving the views of AI company employees (though have some downsides). I expect various in person events could be pretty helpful or other person to person discussion. I also expect that a bunch of thoughtful people writing publicly in reasonable ways about AI is good. I'm not going to give my full list of ideas (seems less good than other uses of my time).
I agree with some of your claims about being careful about confrontation. IMO a bunch of the reasons AI company employees don't engage on places like LW is because it's aversive or not fun.
I think another reason is that they think views on LW are unreasonable/wrong and overconfident. Some rambling thoughts on this:
(This is kinda messy from my perspective. I think there are a lot of unreasonable views on LW and also that views at AI companies are much more unreasonable.)
E.g., I expect that for Anthropic employees a bunch of the reason people don't engage is that they're like "yeah, AI seems to have a bunch of risks, but that's why I'm proud to work at Anthropic (we're the good guys doing the right thing on AI)". And I think "how good/bad is advancing capabilities at Anthropic is a messy empirical question that depends a lot on questions like: 'How much do you agree with Anthropic leadership about the nature of risks? How much will advances diffuse? How much power will AI companies have relative to governments? Will Anthropic take extremely costly actions (e.g. immediately valuation by 3x) to reduce risk or will various forces prevent this? How much should we model Anthropic as a normal company? Is it bad that the epistemic environment environment at Anthropic is very
6
Constellation people frequently conflate "stuff can come down to reasonable disagreements" and "don't treat me as morally reprehensible or impose any social costs on me for acting in accordance with my views".
Yet just because someone arrived at a position and has a relatively intelligible justification, doesn't mean that they should not be held responsible for the consequences! And typically they do not seem willing to take on liability for the downsides of their behavior.
Relatedly but separately: when one side of a "reasonable disagreement" involves taking on insane amounts of risk for society while getting great selfish benefit, and the other side involves not taking on that risk and not getting the selfish benefit, I often simply don't believe that the people arrived at that belief due to "reasonable disagreement".
It’s up to LW moderators to enforce norms, but I would suggest that if you want to impose social costs on lab employees, you do it outside LW.
I post on LW for intellectual discussion, and not to make friends. If people are rude here, it won’t cause me to quit OpenAI or change what I’m doing, but it can cause me to stop posting or reading. That may well be the desired outcome, though I personally think it would be unfortunate.
I think it is unhealthy if all discussion on AI safety that actually impacts frontier models happens inside the labs without discussion between people in the labs and people outside them. And at its best LW can facilitate these.
LessWrong has a broader merit than merely "intellectual discussion", as it a place where people figure out a wide range of their stances on a wide range of topics, and has given birth to a rich community of people with many mutual interests beyond intellectual discussion. It's also really important for LessWrong to think about what incentives its members are under, and discussion here directly or indirectly affects many strategic and tactical decisions at many organizations.
This makes the role of LessWrong meaningfully different from just narrow technical journal, and most importantly means that of course people should gain or lose social standing based on a wide variety of actions they take on or off LW.
This doesn't mean every post should be a place to discuss people's relationship to lab employees, or adjacent topics, but suggesting that such a topic is completely outside of the remit of LessWrong, as I think you are saying here, seems quite wrong to me. People will want to prosecute conflict and standing and credit allocation on LessWrong, and I don't really see a way of doing that without allowing some amount of social consequences to be imposed (at the very least for violatin...
7
I don't interpret Boaz as saying this FWIW.
4
Huh, I guess I don't know how to interpret this sentence otherwise?
[...]
Maybe I misunderstood, which is totally possible! But this to me reads as a suggestion to keep LessWrong free of any attempts at imposing social costs on lab employees (and by extension presumably any other kind of social cost on anyone else for off-site behavior).
5
I interpret the sentence as meaning something more lilke "it would be bad to impose social costs on lab employees via LW policies or via interfering with their discussions on object level discussions on LW" (as opposed to things saying there shouldn't be top level LW posts like "How we should impose social costs on lab employees" or saying that people shouldn't take into account that they are lab employees when responding to them). Like I don't Boaz wasn't saying the topic shouldn't be discussed or that it's bad in principle for there to be top level posts on LW with the explicit goal of shaming lab employees / similar. (I expect he'd think that posts focused on shaming lab employees on LW wouldn't be net good, but I didn't interpret him as making this point.)
Like I interpret Boaz as talking about intellectual discussion on LW:
[...]
6
Hmm, OK, I think I am confused what your interpretation is of what he says should not be done on LW. Like, the only thing that comes to mind is "you shouldn't be rude to lab employees", and my response to that is "I don't really know whether you should ever just be 'rude' to someone, but in as much as a lab employees is e.g. making a request that requires good social standing (such as a request for a critique to be replied to) or a request of resource allocation (such as an encouragement for more people to enter a field of study), then of course I think we should take into account their job and professional background, their incentives and their past general conduct when determining whether to accept or reject that bid".
And then, if you buy that argument, I really don't know what's left that's off-limits that isn't just like, common sense "don't be obtusely rude to people".
8
I think it's mostly common sense "don't be (unnecessarily) rude to people" and "don't hijack threads" and maybe also "don't have a policy of aggressively dunking on people". Like this includes many of the ways people try to impose social costs on X. [1]
(I'm committing to bowing out here.)
1. This originally said "all of", I edited to "many of". ↩︎
3
Cool, yeah, I didn't parse it that way, but this seems reasonable.
9
Yes it’s what Ryan said. I don’t mind at all if there is a frontpage post saying “lab employees should not be welcome at venue X” or anything else along these lines. I think it is legitimate for people to make such choices and also to coordinate them here. This counts to me as imposing a social cost on people outside of LW.
I mostly mean that if I post on LW and people are rude then I‘d be less likely to post.
Another issue, that I didn’t get into, is that very extreme rhetoric, including Nazi comparisons, has the risk of radicalizing people and inciting violence, and is also just not good for people’s mental health.
5
I agree with this. In my comment above, by "impose social costs" I was primarily thinking of "make a move to lower the person's power and/or status within the EA and/or AI safety scenes" via things like "not work with them" or "not give them grants" or whatever the intermediary resource-equivalents you have in your area. I'm not quite sure what you thought I might be including, but I didn't mean things like "downvote their posts because you think they're otherwise unethical people" which in almost all cases would be pretty over the line to me.
I sometimes write LW comments with an intention to let someone know that I've lost a lot of respect for them over their views (and whatever knock on professional or interpersonal effects that may have between us), but I don't think that's what you're pushing back against.
2
You are free to decide who you want to work or interact with. I have no objections for people arguing here for policies on grants or collaborations banning lab employees, even if I personally oppose such policies.
6
I currently think it's best to avoid applying social censure in object level discussions of specific topics on LW like Sam discusses here. I'm not trying to make claims about imposing social costs or treating people as morally reprehensible in other contexts.
(That said, I do expect it will be unproductive to treat people as morally reprehensible for doing things where there aren't reasonably widespread norms against doing the thing. Imposing a bunch of social costs could be productive idk. In the case of AI development, I think there aren't really strong norms against hastening the development of transformative technology in cases where you think that your efforts on hastening it would be good for the world but you also believe that technology has a serious chance of annihilating humanity and some credible people think the risk of annihilation is very high. I do think there are strong norms against failing to make it very clear that this is what you doing and that you think the technology that you are developing might annihilate us all. And there are norms against trying to downplay the risk relative to what you think. This implies there are strong norms against what the leadership of AI companies are doing (unless they've pretty frankly and clearly communicated about their views on the situation), but not really norms against what normal employees at AI companies are doing. Idk though, and people disagree about what the defaults here are. I'm unlikely to respond to replies on this parenthetical as it doesn't seem very useful to discuss. If people want to talk about this, I suggest making a different top level post / shortform.)
I currently think it's best to avoid applying social censure in object level discussions of specific topics on LW like Sam discusses here.
Sure, I was just hearing you espouse a much broader view of something like "I wish there was less conflict theory and more mistake theory in explaining differences around people's views on AI", which I often feel has been an effective way of sweeping real conflicts under the rug (and I believe blatant conflicts are the best kind of conflicts). We'd have to discuss specifics to know whether you mean it in cases that I think are appropriate or inappropriate. Marks didn't actually link to any so I am not confident about whether we're on the same page.
That said, I do expect it will be unproductive to treat people as morally reprehensible for doing things where there aren't reasonably widespread norms against doing the thing. Imposing a bunch of social costs could be productive idk... Idk though, and people disagree about what the defaults here are. I'm unlikely to respond to replies on this parenthetical as it doesn't seem very useful to discuss.
This whole passage reads as quite confused to me. I think it is in some ways imperative to track the ethic...
4
Note that I said "Imposing a bunch of social costs could be productive idk". This is distinct from "treating as morally reprehensible". So the paragraph starting with "Suppose someone made the following declaration..." seems reasonable to me.
3
Are there other examples like this to make LW less "hostile and aversive to AI company employees"? I suspect your view is reasonable but I think the details matter here a lot.
A few of the points in this post relate to making LW less hostile toward AI company employees. I take your post to say something like "you shouldn't be unnecessarily hostile to lab employees and try to stick to the object level." Is my interpretation correct or do you mean that there should be a deeper effort to make lab employees feel more welcome (I would be potentially worried about this)?
2
The current vibe on LW seems to be that AI company employees are doing great harm and should quit their jobs, so why would they come here? I wouldn't go on a socialist forum to post about free markets.
6
Even if you disagree with the median/typical views, you might still have a productive discussion. Separately, people on LW have a range on opinions on what AI company jobs are net positive. For instance, I think that somewhat thoughtfully working on safety at an AI company is net positive (and if done well, can be among the most impactful things to work on). Obviously many people on LW disagree.
1
To add to this - the AI bot issue on X appears to be getting worse by the week and is especially bad on AI-related topics. If you look at someone like Ethan Mollick's replies, a huge proportion are bots now. Over the last year, they seem to have progressed from just spamming links, to rephrasing the original post, to now largely rehashing the original post but with an occasional new (but uninteresting) point, all written in incredibly grating AI style.
It seems plausible to me that by the end of the year every post will have hundreds of bot replies and X will actually become unusable for discussion.
PSA: Anthropic models don't seem to particularly privilege the explicit thinking field. This makes reinforcement spillover—where training on a model's outputs generalizes to the CoT, making it appear safer—more likely.
While Anthropic models do have an separate explicit thinking field, they don't really use thinking that differently from outputs and aren't that dependent on the thinking field. Sometimes they'll just do their thinking in the output field, the way they talk in the thinking field isn't very distinct from how they talk in outputs, and I believe disabling thinking doesn't have a big effect on coding performance (especially for earlier Anthropic models but even for current Anthropic models). (This is specifically for typical agentic coding; this likely doesn't apply to math.)
This is pretty different from OpenAI models which are way more reliant on the explicit thinking and the thinking is very distinct from how the model talks in the output (based on public CoT examples). I'm uncertain, but I think GDM models are generally more similar to OpenAI than Anthropic models on this axis. In general, Anthropic's models leverage taking lots of actions over doing a bunch of thinkin...
This matches my experience.
These days, when I'm using an Anthropic model, I often turn off "extended thinking" and just ask for CoT the old-fashioned way.
The models seem at least equally capable when using this format (vs. extended thinking), and this format allows me to see the CoT without any summarization -- which is useful for debugging/improving my prompts, and which also allows me to guide the CoT in complex ways like what I describe in the footnote of this comment. It seems plausible that these guidance techniques would also "work" with extended thinking, but the summarizer makes it difficult to confirm that they're working, even if they are.[1]
Anyways... I agree with you in principle about the reinforcement spillover considerations, but IMO the most important implication of this observation is something else that you didn't mention explicitly in your comment -- namely, that the infamous "weirdness" of OpenAI CoTs is not a thing that just automatically happens when you try to reach the current capabilities frontier and don't directly supervise the CoT tokens.
I'm not sure that that precise claim (that the "weirdness [...] just automatically happens") is one that anyone liter...
namely, that the infamous "weirdness" of OpenAI CoTs is not a thing that just automatically happens when you try to reach the current capabilities frontier and don't directly supervise the CoT tokens.
I agree that it's clearly possible to train frontier models that don't have any weirdness in their CoTs. However, my impression is that vanilla GRPO does lead to weird CoTs by default: Reasoning Models Sometimes Output Illegible Chains of Thought seems like evidence that many open models that were trained last year were also heading in the same direction as o3, but didn't quite get there, either because less RL pressure was applied on them or simply because they averted some path-dependent feature of GRPO training that drives CoT toward further illegibility. If this is true, then Anthropic must be doing something quite different from the standard GRPO pipeline that helps them keep reasoning traces legible without optimizing them directly. Here are two hypotheses for what those differences might be:
- Performing extensive SFT on reasoning traces from previous models, giving the model a strong legibility prior before the RLVR stage begins. The reasoning traces of older Claude models are hig
3
This comment thread on 1a3orn’s post has a collection of various model’s exhibiting degenerate language usage + Jozdien’s paper (which has since come out: Reasoning Models Sometimes Output Illegible Chains of Thought) I think are all strong evidence that you don’t get human legible english by default from outcome based RL. It seems very obvious to me that Anthropic (intentionally or via spillover) puts pressure on the CoT in a way that looks like nice human legible HHH friendly english. (based on system card / the cot itself when using the model). This is consistent with Ryan’s observations (which I also strongly agree with).
[...]
I don’t think this has any principled reason to give any insight as to whether the model can functionally use this reasoning in the analysis channel. (Although I would note this was also surprising to me, they act like they’ve never seen this language in their life, and I’d be very interested in more work on how the “analysis” channel persona differs from the “final” channel persona, channel separation seems potentially extremely powerful, especially given the user is just another channel)
[...]
Not necessarily! And again contra the “everything is nonfunctional spandrels”, my impression is that “ Myself” seems to be somewhat consistently used as the analysis channel persona and it’s also one of those “weird tokens that became super common including sometimes being repeated a lot over RL”. “Redwood” is another such token. We give a few examples: here
[...]
As does METR in their GPT-5 report:
[...]
IMO ablating “Myself” or “Redwood” in such cases are obviously a bad idea, and my mental model of these is “this seems to happen broadly during RL (see linked thread) sometimes these are contextually useful enough for the model to kind of make use of them.” It seems like there’s a spectrum between “saying marinade illusions 50x” which I agree is unlikey to make a big difference if ablated, and “watchers might check” (with likely many hard
This comment thread on 1a3orn’s post has a collection of various model’s exhibiting degenerate language usage + Jozdien’s paper (which has since come out: Reasoning Models Sometimes Output Illegible Chains of Thought) I think are all strong evidence that you don’t get human legible english by default from outcome based RL.
I'm somewhat skeptical of that paper's interpretation of the observations it reports, at least for R1 and R1-Zero.
(EDIT: but see Jozdien's reply to this comment, which calls this into doubt)
(EDIT2, added 4/19/26: see this post for more conclusive evidence on this point)
I have used these models a lot through OpenRouter (which is what Jozdien used), and in my experience:
- R1 CoTs are usually totally legible, and not at all like the examples in the paper. This is true even when the task is hard and they get long.
- A typical R1 CoT on GPQA is long but fluent and intelligible all the way through. Whereas typical o3 CoT on GPQA starts off in weird-but-still-legible o3-speak and pretty soon ends up in vantage parted illusions land.[1]
- (this isn't an OpenRouter thing per se, this is just a fact about R1 when it's properly configured)
- However... it is apparently very easy to set
Following up on this! We were able to get a few more CoTs released from o3 after capabilities-focused RL but before safety training: here
tldr:
- While terms like "Myself", "Redwood", etc are commonly used, repeated spandrels like
disclaim disclaim illusionsoccur at dramatically lower rates the completely degenerate examples in the finalo3seem to be a direct result of safety training. I was surprised by this, as the repeated impression I've gotten from papers and statements by OpenAI is that they didn't think their safety training significantly impacted CoT legibility (but maybe they never literally stated this). - More on the "Myself" vs "ChatGPT" usage specifically below but unfortunately this is only a few CoTs so hard to make a super legible case externally, highlighting in case they're still useful regardless
When the CoT-author writes any first-person pronoun it's of course natural to think it's referring to itself, but the "itself" in question isn't necessary itself as distinct from the other persona; often it just seems to mean "the language model writing this."
A confounding factor is that every system prompt starts with "You are ChatGPT", so this somewhat gets baked int...
- However... it is apparently very easy to set up an inference server for R1 incorrectly, and if you aren't carefully discriminating about which OpenRouter providers you accept[2], you will likely get one of the "bad" ones at least some of the time.
From what I remember, I did see that some providers for R1 didn't return illegible CoTs, but that those were also the providers marked as serving a quantized R1. When I filtered for the providers that weren't marked as such I think I pretty consistently found illegible CoTs on the questions I was testing? Though there's also some variance in other serving params—a low temperature also reduces illegible CoTs.
3
I think there are two distinct claims:
* (1) “repeated identical sequences likely are nonfunctional spandrels”
* (2) “all uses of such tokens are in nonfunctional spandrels”
I think (1) is almost certainly true and (2) is certainly false.
—-
I’m pretty strongly against trying to explain away each instance of non legible english cot as it’s own unique RL configuration issue. This feels like adding epicycles, and only works to explain anything post hoc. It can’t predict that, for example, Codex 5-3 has non-latin syllables interspersed in words all the time now. You can come up with some new explanation but this seems unprincipled and entirely speculative, as you have to guess at a lab’s training setup every time a new issue in reasoning legibility is observed.
Even in pre-reasoning models you’d expect this dynamic to emerge: https://arxiv.org/abs/2407.13692. Notably, even things like being slightly compressed (ex: “linter complaining” instead of “The linter is complaining”) that you would expect from length penalty seem missing in Anthropic models.
The linked thread has examples completely unrelated to openai, ex: https://ai.meta.com/research/publications/cwm-an-open-weights-llm-for-research-on-code-generation-with-world-models/
[...]
—-
[...]
I genuinely don’t understand what I’m missing here. How are you accounting for the free variable of being able to optimize against the CoT for legibility? I’m not arguing that what o3 is doing is somehow “you may not like it, but this is the optimal language”, but more that “yeah of course you can get legible cot and performance if you’re willing to optimize against it”. (It’s a multidimensional thing of “how exactly do you apply that optimization pressure”, but no idea where Anthropic are on that landscape, and you do need to know to make updates on monitorability related tradeoffs).
4
Earlier I wrote a long reply to this and deleted it because I felt weird about it -- it wasn't a bad comment per se, but it devolved halfway through into a kind of protracted, grandiose grandstanding about Anthropic vs. OpenAI and why I think Anthropic's models are way better... which is a fun mode for me to write in, but which felt like adding more heat than light when I looked back on it.
But, to summarize the same points more concisely and plainly:
* I'm working off of a mental model that says OpenAI models are reliably "weird" in particular ways, both in CoT and out of it, and that this is less true of other labs' models (and not true at all of Claude).
* The "OpenAI weirdness" in question has to do with over-learned and indiscriminately deployed verbal reflexes. In the deleted comment I explained more precisely what I meant by that, which took more space than I want to use here; I described some concrete examples of this outside of CoT, such as:
* o3's unusual typography and writing style (in responses, not in CoT)
* a strange behavior I have noticed in gpt-5.2-chat-latest but not in any of its predecessors (roughly, "announcing" its own intent to navigate a tense conversation in a particular way, e.g. "I want to say this gently (but firmly)", typically as markdown headings; it does this very frequently, using a narrow set of words and phrase templates that recur across independent realizations of the behavior)
* So, the observation that a new Codex model has some new weird CoT behavior -- and, meanwhile, that there are some very new Claude models and they don't seem less legible than their predecessors -- is entirely in line with what I would have expected a few months ago. (This is a post-diction, obviously, take it as you will.)
* I would be surprised if the legibility gap between Anthropic and OpenAI ever closes, or if Claude ever becomes as illegible as o3 (or worse). Or, I guess, if OpenAI models ever become as legible as the Claudes of tod
5
With thinking mode on, you can even just ask Claude in web to add thinking blocks by wrapping them with <antml:thinking> xml tags (or cut it's thinking early), the web UI will also put them in thinking blocks.
This post prompted me to check the conversation where I discovered this, and I noticed Anthropic made it so all thinking blocks are stuck together at the top rather than having them interleaved the order that the model generates them. You can clearly see that the model is able to think in one coherent chain where the "CoT" doesn't delimit a strict "thinking" then "responding" portion, in the example below it even reflects on "am I inside a thinking block, or the response?"
Screenshot from ~2 months ago
Same chat, screenshot from today
5
I just replicated the results in this conversation here. After several rounds of back and forth, Claude was able to think for a bit, start responding, and then go back into thinking mode. From the web UI, I first see
1. A quick thinking block, then tokens would stream from the output
2. The output token streaming will stop, and then a new thinking trace would start appearing in the top thinking summary.
3. Then Claude would go back to outputting tokens in the main body.
Per my instructions, it would alternate between two and three.
5
Very nice, Claude seems really excited to play with its boundaries. I also just checked on mobile and saw that they intersperse the thinking blocks there as before, so having all the blocks on top seems like a new/inconsistent web feature
4
FWIW we found controllability of most recent Claude models to be similar to GPT-5 series. It seems like after Anthropic stopped optimizing CoTs for 4.5, controllability dropped by a lot.
2
I'm curious what Sonnet 4.5's score would be on your external CoT controllability eval. I.e., what Sonnet 4.5's blue bar in your Fig. 25 would look like. (I couldn't find a result like this in your paper, but I might have overlooked something)
My casual impression has been that external CoT with Sonnet 4.5 is fairly steerable, but this impression is mostly based on "in practice I have no trouble getting Sonnet 4.5 to do the kind of CoT I need" rather than any kind of systematic investigation.
It seems like at least one of the following must be true:
1. There are some counterexamples to Ryan's claim in the original comment (that recent Anthropic models don't draw much of a distinction between "external" and "non-external" CoT)
1. What would imply this: Sonnet 4.5 gets a high score on your external CoT controllability eval[1]
2. Recent Anthropic models, unlike Sonnet 3.7, are not controllable in your sense even when CoT is external
1. What would imply this: Sonnet 4.5 gets a low score on your external CoT controllability eval
And either of these would be interesting if true, so the eval seems worth running.
My guess is that Sonnet 4.5 will get a high score, close to its "output controllability," score. I expect this both because that's the trend we see in external CoT results for other models, and because the distinction between "external CoT controllability" and "ordinary instruction-following" is fairly blurry. "External CoT" is just a particular case of "some portion of the response that was requested in the instructions," and it would be strange if instruction-following took a nosedive in this one case[2] while being so robust elsewhere.
1. ^
Note that Ryan's claim could still be broadly true even if there are a few known counterexamples.
If you were to find a difference between external and non-external controllability for Sonnet 4.5 on your eval, but meanwhile these two conditions were found to be largely the same in various
2
Do you have results for Opus 4 / 4.1 / 4.5 / 4.6 for this one?
1
According to various Anthropic system cards, including the Claude Opus 4.6 system card, Sonnet 4, Opus 4.1, and Sonnet 4.5 are very poor at bypassing a monitor in SHADE-Arena when the reasoning is visible. However, Opus 4.5 is significantly better at this, and Opus 4.6 is significantly better than Opus 4.5. So it's possible the controllability trend you've observed in recent models has now reversed.
1
c.f. this tweet from Greg Burnham, showing how Opus 4.5 barely suffers on FrontierMath from having CoT disabled:
[...]
1
If I were Anthropic, I'd be worried about distillation attacks via this route. It seems to make their CoT obfuscation moot.
1
Any public info on whether any of the big providers embed CoT tokens differently than non-CoT tokens? {OpenAI: yes, Anthropic: no} (or a split by model) might explain your observations. No idea if this is an obviously dumb thing to try.
I thought it would be helpful to post about my timelines and what the timelines of people in my professional circles (Redwood, METR, etc) tend to be.
Concretely, consider the outcome of: AI 10x’ing labor for AI R&D[1], measured by internal comments by credible people at labs that AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
Here are my predictions for this outcome:
- 25th percentile: 2 year (Jan 2027)
- 50th percentile: 5 year (Jan 2030)
The views of other people (Buck, Beth Barnes, Nate Thomas, etc) are similar.
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
Only including speedups due to R&D, not including mechanisms like synthetic data generation. ↩︎
My timelines are now roughly similar on the object level (maybe a year slower for 25th and 1-2 years slower for 50th), and procedurally I also now defer a lot to Redwood and METR engineers. More discussion here: https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
@ryan_greenblatt can you say more about what you expect to happen from the period in-between "AI 10Xes AI R&D" and "AI takeover is very plausible?"
I'm particularly interested in getting a sense of what sorts of things will be visible to the USG and the public during this period. Would be curious for your takes on how much of this stays relatively private/internal (e.g., only a handful of well-connected SF people know how good the systems are) vs. obvious/public/visible (e.g., the majority of the media-consuming American public is aware of the fact that AI research has been mostly automated) or somewhere in-between (e.g., most DC tech policy staffers know this but most non-tech people are not aware.)
I don't feel very well informed and I haven't thought about it that much, but in short timelines (e.g. my 25th percentile): I expect that we know what's going on roughly within 6 months of it happening, but this isn't salient to the broader world. So, maybe the DC tech policy staffers know that the AI people think the situation is crazy, but maybe this isn't very salient to them. A 6 month delay could be pretty fatal even for us as things might progress very rapidly.
6
Note that the production function of the 10x really matters. If it's "yeah, we get to net-10x if we have all our staff working alongside it," it's much more detectable than, "well, if we only let like 5 carefully-vetted staff in a SCIF know about it, we only get to 8.5x speedup".
(It's hard to prove that the results are from the speedup instead of just, like, "One day, Dario woke up from a dream with The Next Architecture in his head")
AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
I don't grok the "% of quality adjusted work force" metric. I grok the "as good as having your human employees run 10x faster" metric but it doesn't seem equivalent to me, so I recommend dropping the former and just using the latter.
7
Fair, I really just mean "as good as having your human employees run 10x faster". I said "% of quality adjusted work force" because this was the original way this was stated when a quick poll was done, but the ultimate operationalization was in terms of 10x faster. (And this is what I was thinking.)
3
Basic clarifying question: does this imply under-the-hood some sort of diminishing returns curve, such that the lab pays for that labor until it net reaches as 10x faster improvement, but can't squeeze out much more?
And do you expect that's a roughly consistent multiplicative factor, independent of lab size? (I mean, I'm not sure lab size actually matters that much, to be fair, it seems that Anthropic keeps pace with OpenAI despite being smaller-ish)
5
Yeah, for it to reach exactly 10x as good, the situation would presumably be that this was the optimum point given diminishing returns to spending more on AI inference compute. (It might be the returns curve looks very punishing. For instance, many people get a relatively large amount of value from extremely cheap queries to 3.5 Sonnet on claude.ai and the inference cost of this is very small, but greatly increasing the cost (e.g. o1-pro) often isn't any better because 3.5 Sonnet already gave an almost perfect answer.)
I don't have a strong view about AI acceleration being a roughly constant multiplicative factor independent of the number of employees. Uplift just feels like a reasonably simple operationalization.
7
I've updated towards a bit longer based on some recent model releases and further contemplation.
I'd now say:
* 25th percentile: Oct 2027
* 50th percentile: Jan 2031
5
I've updated towards somewhat longer timelines again over the last 5 months. Maybe my 50th percentile for this milestone is now Jan 2032.
4
How much faster do you think we are already? I would say 2x.
7
I'd guess that xAI, Anthropic, and GDM are more like 5-20% faster all around (with much greater acceleration on some subtasks). It seems plausible to me that the acceleration at OpenAI is already much greater than this (e.g. more like 1.5x or 2x), or will be after some adaptation due to OpenAI having substantially better internal agents than what they've released. (I think this due to updates from o3 and general vibes.)
2
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
6
This case seems extremely cherry picked for cases where uplift is especially high. (Note that this is in copilot's interest.) Now, this task could probably be solved autonomously by an AI in like 10 minutes with good scaffolding.
I think you have to consider the full diverse range of tasks to get a reasonable sense or at least consider harder tasks. Like RE-bench seems much closer, but I still expect uplift on RE-bench to probably (but not certainly!) considerably overstate real world speed up.
2
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
4
Yes, but I don't see a clear reason why people (working in AI R&D) will in practice get this productivity boost (or other very low hanging things) if they don't get around to getting the boost from hiring humans.
4
This is intended to compare to 2023/AI-unassisted humans, correct? Or is there some other way of making this comparison you have in mind?
7
Yes, "Relative to only having access to AI systems publicly available in January 2023."
More generally, I define everything more precisely in the post linked in my comment on "AI 10x’ing labor for AI R&D".
4
Thanks for this - I'm in a more peripheral part of the industry (consumer/industrial LLM usage, not directly at an AI lab), and my timelines are somewhat longer (5 years for 50% chance), but I may be using a different criterion for "automate virtually all remote workers". It'll be a fair bit of time (in AI frame - a year or ten) between "labs show generality sufficient to automate most remote work" and "most remote work is actually performed by AI".
8
A key dynamic is that I think massive acceleration in AI is likely after the point when AIs can accelerate labor working on AI R&D. (Due to all of: the direct effects of accelerating AI software progress, this acceleration rolling out to hardware R&D and scaling up chip production, and potentially greatly increased investment.) See also here and here.
So, you might very quickly (1-2 years) go from "the AIs are great, fast, and cheap software engineers speeding up AI R&D" to "wildly superhuman AI that can achieve massive technical accomplishments".
4
Fully agreed. And the trickle-down from AI-for-AI-R&D to AI-for-tool-R&D to AI-for-managers-to-replace-workers (and -replace-middle-managers) is still likely to be a bit extended. And the path is required - just like self-driving cars: the bar for adoption isn't "better than the median human" or even "better than the best affordable human", but "enough better that the decision-makers can't find a reason to delay".
I don't feel confused by LLMs seeming very smart while being unable to automate hard work.
Sometimes people find it mysterious or surprising that current AIs can't fully automate difficult tasks given how smart they seem. I don't find this very confusing.
Current LLMs are just not that "smart" (yet). They compensate using very broad knowledge and strong heuristics that are mostly domain-specific. In other words, they have high crystallized intelligence but lower fluid intelligence.
In humans, crystallized and fluid intelligence are very correlated due to limited time for learning and limited capacity for knowledge/memorization, but AIs can train for longer and (for unclear reasons) seem to have much higher capacity for knowledge/memorization. So, AI capabilities are often overestimated by naive comparisons. [1] I do find it somewhat mysterious/surprising that humans have such poor memory despite seemingly having so many parameters, and that some people have much better memory than others.
My view is that this crystallized vs fluid distinction is maybe the first principal component of human vs AI differences and this explains a lot of the differences, but not all of them. We...
Pretraining memorizes all the facts in the world, but only gives weak fluid intelligence (in-context learning). RLVR trains crystallized intelligence that expresses itself in-context as strong fluid intelligence (which isn't fake or illusory, within its scope), but this narrow strength falls apart sufficiently out of distribution (regressing to pretraining levels). Thus jaggedness (in fluid intelligence) is a good way of framing this, and currently the jaggedness profile is determined by RLVR training, the topics that were sufficiently covered in the RL training data. Humans are different in having a higher baseline of general fluid intelligence (than what pretraining gives LLMs), and thus in often possessing fluid intelligence that's stronger than crystallized intelligence for the same topic, while LLMs always have strong crystallized intelligence for the topics where they have strong fluid intelligence (those covered by RLVR training).
General "smartness" might significantly improve from replacing pretraining with something more effective, applying RLVR much more broadly, or figuring out how to automatically train in response to post-deployment data (bringing it in-distribution fo...
0
Hard disagree. Pre-training is foundational for LLM intelligence. It's where the key pieces of it come from.
RL is less about "teach the old AI new tricks" and more about "teach the old AI how to do the old tricks well". Pre-training teaches the components of intelligence, but wires them together in awkward and often maladaptive ways. Optimal next token prediction != optimal reasoning, there's a lot of overlap but the tails come apart hard. RL passes pivot the training objective - they correct some of the mismatch, put the existing pieces together into a shape that functions better.
What people struggle to grasp is that "intelligence" and "being able to execute on complex long term plans" are two fairly separate dimensions. And modern AIs get one of those things from their training regime.
There are parts of humanlike intelligence that pre-training fails to teach the LLMs, and long term agentic behavior is one of them. As are things like "commonsense physics" and spatial reasoning.
RL is one way to improve on that. RLVR, by its very nature, encourages behaviors that lead to task completion - decomposition, self-verification, long term coherence, metacognition and metaknowledge (awareness of what methods should be used, what skills are reliable and what aren't). All of those are good for short term tasks, but good^2 for long term tasks specifically. Going from 95% to 99% per-step reliability hits different on 50 step tasks than it does on 5 step tasks. Some of those aspects apply across tasks and some are task-specific.
I agree, but I feel like there's an even simpler and more obvious explanation for what's going on: Just look at the training data!
--When a modern AI is first created, it's a random jumble of neurons just like a human fetus.
--Then it plays the "predict the next token of internet text" game ten trillion times.
--Then it plays the "Here's a puzzle to solve / bug to fix / short-term task to complete / question to answer" game like ten million times.
--Then, bam, there it is, in front of you, being asked to rebuild your video game from scratch or do novel research or whatever hard task you are asking it to do. Or play Pokemon for that matter. These tasks are quite different from anything it's seen before: much longer, much harder. To solve them it'll need to learn and adapt over the course of days. But it's literally never had to learn and adapt over the course of days before; the longest tasks it ever saw in training were shorter than that, and weren't very diverse either.
5
I think I like half agree, but also think your argument implies things which are false.
In particular, I don't think the reason why humans are much better at much longer tasks is mostly because they've previously done longer tasks. I think humans trained on only a variety of school projects that took around 8 hours (but were hard annd variable + diverse within that period), would be pretty likely to suceed at year long projects without further feedback / training on longer tasks. They would struggle at the start but would probably figure it out and eventually suceed with only the feedback from the environment. Minimally, humans only need a tiny number of examples of long tasks.
9
I disagree. Humans who do research projects well have usually had experience doing at least a few research projects of similar length before. Indeed when I was a grad student teaching philosophy courses, it seemed to me that part of the problem was that the college students I was teaching had only ever written short 3-paragraph-style essays before, and never done serious lengthy writing projects that required serious reading and thinking.
It's true that humans need only a few examples of the thing to get decently good at it, but that's just the generic human data-efficiency at work rather than specific to long-horizon tasks, I think.
3
Sure, but the training data thing is sort of tied up with fluid intelligence? Like a method you have available as a human is learning on the task itself and AIs also have this option, but due to garbage sample efficiency it wouldn't work.
I also still think humans can often generalize to doing tasks of larger scope without prior experience by learning/adapting from this exact experience in a way that AIs don't.
7
Sample efficiency for RLVR is plausibly good enough if relevant tasks and RL environments can be automatically formulated, which is currently out of reach but it's unclear for how long it stays this way. And for in-context learning, sample efficiency could get higher if it worked well enough (as learned learning, it's in principle not constrained by what hardcoded learning can do), it just doesn't work well with pretraining.
6
I think I was responding to an earlier version of your comment -- now that it says "I half agree" then I think we are mostly on the same page. I also agree that long-horizon fluid intelligence / sample-efficient online learning seems to be a real thing that differs between humans and AIs.
2
Hardwired priors. Humans get them, LLMs don't.
There isn't enough samples in "human training data" to train them for agentic long horizon tasks either. There is, however, enough of those samples in the human evolutionary history. Which is how humans have an instinctual grasp of how to accomplish long term goals - which forms a foundation that any further training then builds upon.
LLMs don't get that "for free", and they struggle to learn it from random pre-training text.
Normally, the AI answer to "no hardwired priors" is "reconstruct them the hard way from the vast dataset". But there's no good "in-domain dataset of long term agentic behavior" for LLMs to be able to do it well. So they get stuck with dregs of long term agency that the mix of pre-training, SFT and RLVR left them with.
So what makes you think anyone has a method for creating computer programs with "human level fluid intelligence"?
3
I wouldn't exactly say that we have a method, more like a field wide methodology that I expect will probably yield fully automated AI R&D within maybe 6 years and will probably yield top-human-expert level fluid intelligence within maybe 9 years. (As in, my median to fully automated AI R&D is 6 years while my median to top-human-expert level fluid intelligence is somewhat longer due to the possibility of a significant lag between these milestones dragging my median out by some amount. Note that the median to B is in general not the same as median A + median from A to B and this applies in this case.)
(Technically, I actually think that we'll probably achieve human level fluid intelligence within 8 years in some way where a large majority of this probability comes from something like the methodology of the current field, including the part of the methodology that involves getting weaker AIs to automate AI research in all kinds of ways but most focused on this methodology. I think some fraction of the mass comes from very different methodologies, but this is a smaller fraction. The probability of very different methodologies yielding powerful AI in the next ~10 years is boosted significantly due to going through a particularly salient compute region—somewhat above human lifetime compute—and higher attention on AI in general.)
As far as why I think this methodology will probably yield "human level fluid intelligence", this is mostly downstream of a mix of qualitative and quantitative extrapolations combined with thinking that armies of automated AI researchers matching top human AI researchers and doing everything they do but better would probably find a way.
I agree with you that something like the crystalized/fluid distinction is relevant here, and that current LLMs seem to have more of the former. But I'm also confused about where the fluidity ever comes from on this model. Like, I buy that armies of automated researchers which are better at doing everything than top human researchers could probably find a way to figure out how to build "human level fluid intelligence," but I am confused about how you get to that step in the first place. Why are they better than human researchers at everything when they are still mostly using crystallized intelligence?
7
(I get that me asking followup questions could be frustrating because you may not want to talk about this; I would just ask that if you'd like to bow out, if you could, give one or two sentences on why, coarsely--e.g. "the whole topic doesn't seem valuable" or "I don't want to discuss this publicly" or "you Tsvi won't have a productive convo about this" etc.; I ask because I have a general feeling that there's an unidentified blob of consensus around short timelines, which IMO is irrational and overconfident (meaning, it reached incorrect conclusions due to systematically substantively flawed reasoning), and I'm not aware of a good way to get recourse (i.e. to ask "take me to your leader"), so I'd at least appreciate hearing epistemic metadata in order to orient to that situation.)
[...]
What's the relative weight of these considerations, grossly speaking? Is it more like 90% extrapolations and 10% hand-off or more like the reverse? For the 90% one, if there is one, what are one or two of the most compelling points? For example if it's extrapolations, what are you extrapolating (and why do you think that extrapolates to high fluid intelligence)? If it's the hand-off, why do you think that the current-human-research that would be handed off is a kind of research that would soon produce high fluid intelligence (given the apparent circularity of this specific line of reasoning)?
5
I'm going to reply kinda briefly and then I'm going to bow out with some chance I comment more later.
[...]
Hmm, these are tied up a bit. Like I'm doing the extrapolations to get to automating AI R&D to various extents and then trying to account for acceleration due to automation. But I'm also extrapolating out to human fluid intelligence somewhat and if this extrapolation looked extremely far that would influence my view.
To give a rough (and potentially not that stable on reflection answer):
1. 50% extrapolations towards automation of current AI R&D (both towards full automation and large speeds up from very strong partial automation)
2. 25% armies of AIs that can automate AI R&D will be able to find a way to get to human level fluid intelligence
3. 25% extrapolations towards human level fluid intelligence
This is something like an importance attribution. E.g., if I updated toward a way lower qualitative extrapolation on (3), that would update me quite a bit, but probly not shift my 25th percentile by more than a factor of like 2-3.
For (1), I'm doing a mix of something like time horizon, some informal sense of how good AIs are at research tasks I give them and what I see from others, and some longer list of considerations. And part of this is factoring in earlier speed ups moving us along the trajectory faster.
For the hand-off (what I would call (2) in my breakdown), I can see why the argument seems circular, but I don't think it's actually circular. My view is like "probably tons of AI R&D via stuff sorta like the current stuff we're doing would yield this (due to a mix of my observations from ML, my extrapolations of current progress, thinking of specific things you could do that I won't mention here without more consideration)" and "probably you'll be able to get AIs to do this without very high fluid intelligence, though I do think AIs at this point will match somewhat worse human engineers/scientists at moderate time horizon fluid intelligence (e.
6
I'm not claiming that you do or should care a bunch about my views, but I am extremely interested in the questions "will LLM minds scale to superintelligence without any radical breakthroughs?" and "if not, can armies of very capable LLM-agents discover those breakthroughs?".
If I had a stronger understanding here, it would probably influence what I predictions I highlight to policymakers.
(eg, I'm currently telling them that "the labs are planning to automate AI development; we're already seeing AIs automating many simple AI research tasks [show them a demo of that]; given the METR trendline it's likely that there will be full or near-full automation in 2027 to 2029; and (while it is hard to forecast with any precision) is likely that there will be strategically superhuman AI agents weeks to months after that point."
If I came to think that LLM-agents automating AI research is much less likely to lead rapidly to Superintelligence than I currently think is plausible, I would probably not want to focus so on the above talking points in initial 30 minute meetings, in which we have to be selective about which points to convey.)
Also, generally, if I had more mass on "continuing to scale LLM-agents will not lead to superintelligence, either directly or by enabling the discovery of critical breakthroughs", this would back up into my general strategic models and strategic priorities.
5
Just for the record:
[...]
This one I wouldn't claim to know that someone else doesn't know this, and it's what I would assume;
[...]
Pretty skeptical of "full" or "near-full", in that I would still expect things to be largely bottlenecked on human judgement and not making much (say, greater than 2x or something?) progress compared to currently; in other words, I expect Amdahl. There's also a big ambiguity and/or assumption about what you're automating (if you successfully automate a process which doesn't invent AGI, then you've done something but you haven't set off an intelligence explosion or similar).
[...]
This is where I think no one has any especially strong reason to think so, or at least, no one has told me so far even in private, let alone publicly (and therefore consensus views seem quite mistaken).
4
I mean, in the absence of specific arguments and info, "there's a double digit probability that this will lead to superintelligence" seems like a correct or reasonable prior? So, I find it hard to engage with the way your sentence is phrased, which feels like it's trying to make a claim about the burden of proof.
It might be that there's something fundamentally missing from LLM agents, such that without breakthroughs, they can't grow into superintelligences. But that's sure not obvious to me. A lot of problems that people said were fundamental have fallen to scale and RL.
In an attempt to be legible, I think there's at least a 50% chance (baring big government interventions) that the current technological trajectory will lead to AIs that are strategically superhuman without any innovations that are a bigger deal than the original "Attention Is All You Need" paper. (Maybe you think that's obviously crazy?)
And regardless, it sure looks like we're on track to automate a very wide range of "routine" cognitive operations and AI research tasks. My guess is that it will soon become clear that almost everything that almost every human does is made of routine cognitive operations that don't require deep fluid intelligence. This includes the researchers at the AI companies.
AI research as it is done now seems pretty empirical / "throw spaghetti at the wall"-ish. Progress is mostly not driven by groundbreaking genius ideas, ala Einstein, but rather by listing 20 obvious next things to try and trying them. It seems like LLM agents will be able to automate that.
And even if the LLM agents, can't do some crucial "deep thinking" step that's necessary for getting to the next paradigm, automating all the routine AI development tasks will free up a lot of genius AI researcher attention, and allow them to build intuitions by operating the domain a lot faster.
It seems pretty surprising to me if we automate all routine AI development tasks (and for that matter, almost all cognit
6
Can you expand on this, and in particular, how it gets you to be quite confident (relative to the prior where any given innovation isn't confidently going to grow into superintelligence)?
[...]
I don't think it's obviously crazy at the outset, meaning, I could have seen it being the case that someone could know something that gets them to 50% on this. I am starting to think that it is obviously crazy, though, because no one can give an argument for this! Like, can you explain why you think this? In other words, I think it should be obviously crazy to someone who basically just updated off of a bunch of other people updating; you should be tracking when you're doing that. In plenty of cases doing that update could be rational, but then in such cases usually it would also be rational to later update on the (strange) observation that no one can actually explain / argue for / defend the initial large consensus update.
[...]
https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform?commentId=upZ8KPxneNxnJHd8D
[...]
One man's modus ponens is another man's modus tollens. The stuff that LLMs will soon automate probably isn't the stuff that makes AGI. Or, go ahead and argue the opposite, but I will point you to the fact that your arguments better not imply that current LLMs would easily frequently be able to create many novel useful interested concepts like humans do (narrator: his arguments would imply that).
[...]
Again, modus ponens meet modus tollens and Amdahl. According to your argument, the Industrial Revolution (or the invention of computers, or the invention of compilers, or operating systems, or the internet, or Google) should imminently create AGI because it frees up a bunch of human capital. Now, that's probably true! Just not on any specific timeline.
4
This question seems to be insisting on a weird burden of proof, to me. I'm going to try to answer it straightforwardly, but I imagine my answers will feel frustrating, or missing the point, or something.
The AI agents we have now meet many to most of the criteria for AGI that many people put forward in previous decades. It's not crazy to say that Claude 4.6 is an AGI, and insofar as it isn't, its not very clear what's missing.
Last I checked, GPT-5.something was the 6th best competitive programmer in the world. The AIs are winning gold in math Olympiad competitions. They're clearly better than me, already, at almost all of technical thinking.
I don't see a fundamental reason they shouldn't be able to eg design components of a nuclear reactor, or design a whole nuclear reactor, better than than the best human nuclear engineers, except that their time horizon is too short to make much progress. But the AI time horizons have been doubling on a consistent exponential since GPT-3 at least.
And notably, on the path to getting here, we went from language models that mostly output gibberish, to chatbots that are vastly more knowledgeable than any human, to agents that can solve open profesional level math problem and build software better than most humans and faster than almost every human, by applying very simple and obvious ideas.
* "Huh, GPT-2 worked pretty well. What if we do the same thing, with a bigger model, on more data". This worked.
* "What if we have the model train on procedurally generated math and programming problems". This worked.
* "What if we build simple scaffold that queries the model, to implement an agent." This didn't work at first, but a combination of making the models better, making better scaffolding, and training the model in the scaffolding got it to work.
I am not an AI researcher. But I had all of these ideas, years before the AI companies got them working. (In contrast, I would need a lot of technical expertise, and maybe more raw i
8
I'm not sure what's weird about it, but yes, I think someone claiming to predict the future confidently as opposed to the more default background broad uncertainty would have the burden of proof.
[...]
Yes, but one has to update one's beliefs about everything (or more feasibly, about the most relevant things), not just about one thing. There is a missing update here: those people had bad models, and in fact those tasks are shocking not only achievable through general intelligence. See https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#Things_that_might_actually_work:~:text=There is a-,missing update,-. We see impressive
[...]
Do you think it has high fluid intelligence (assuming as best you can, arguendo, that this phrase maps to something meaningful + important)? If yes, why (given that you'd be disagreeing with a lot of other short timelines views)? If no, why talk about AGI that doesn't include high fluid intelligence?
[...]
Just because I, a non-engineer, cannot explain to you in detail why this pile of steel beams will not stand up as a bridge, does not mean it is a bridge. See https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#The__no_blockers__intuition
I think it's true and good to be worried that the AI research community could adaptive creatively surprise us with inventing AGI seedstuff in 1 year or 5 years. What I'm arguing against, or just trying to understand, is people (such as you) seeming to have very high confidence in this (like having a median of 5 years, i.e. 50% chance). That sure sounds like positive knowledge of us having almost all of fluid intelligence AGI seedstuff. No?
[...]
Except for the most important parts, such as orienting to a new domain / new question in a manner that produces successful understanding in the long run.
[...]
Response 1: This type of reasoning does not work for all those other previous big breakthroughs (such
6
This comment felt like it made a better model of your views click. ISTM you think something like:
* All the impressive ML results so far have only worked either in a narrow subspace around the training data (e.g. LLMs, still mostly the case even with RL), or in very small worlds (e.g. pure-RL game-players). There has been ~zero progress on fluid/general intelligence. Therefore, extrapolating straight lines on graphs predicts ~zero progress on fluid/general intelligence by doing more of the same kind of thing. The induction on increasing 'intelligence' that lots of other people appeal to only works by inappropriate compression.
* It's still likely that we live in something like the 2011-Yudkowsky world as described in this tweet, with AGI to come from a lot of accumulation of insight. ML successes misleadingly make that world look falsified, if you aren't tracking what they are and aren't successes at.
* (Implied) The fact that [ML results so far required surprisingly little understanding-of-intelligence] is not significant evidence that [other-things-you-might-expect-to-require-understanding, e.g. fluid intelligence, will require less understanding]. If we've learned something about how little understanding-of-intelligence was needed to build things that succeed on some tasks, this still just doesn't say much about AGI.
* * (Or maybe you don't believe that 'fact' about ML results so far, idk.)
* Intuitively-to-me, there should be a big inductive update on this level, even if induction on 'intelligence' doesn't work.
* * Like, it's evidence against the way of thinking that says understanding of intelligence is important. When you say (implicitly) 'we probably need lots of AGI seedstuff', I want to say 'why isn't the thought process you're using to say that surprised, and downvoted, by how little stuff we needed to make LLMs?'.
8
I largely agree with this, yeah. It would need some probability caveats; I put nontrivial, like O(1-5%), on various scenarios leading to AGI within 10 years--largely the sorts of things people talk about, and generally "maybe I'm just confused and GPT architecture / training plus RLVR and a bit more whatever basically implements a GI seed" or "maybe I'm totally confused about "GI seed" being much of a thing or being ~necessary for world-ending AI".
I also wouldn't have quite so tight a categorization of sources of capabilities. Cf. https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform?commentId=QBca6vhdeKkjyNLKa
[...]
Yeah, something like that. (I feel I have very little handle on how much insight is left, social dynamics around investment in conceptual "blue" capabilities research, etc.; hence very broad timelines. I also don't much predict "there aren't other major, impactful, discontinuous milestones before true world-ending AGI"; GPTs seem to be such a thing.)
[...]
It should probably be slightly directionally downvoted (though I'm not sure which preregistered hypotheses are doing better). But I think not very much, because I think that we did not observe "surprisingly obvious / easy / black-box idea generates lots of generally-shaped capabilities". Partly that's because the capabilities aren't generally-distributed; e.g., gippities aren't good at generating interesting novel concepts on par with humans, AFAIK. Partly that's because there's a great big screening-off explanation for the somewhat-generally-distributed capabilities that gippities do have: they got it from the data. I think we observed "surprisingly obvious / easy / black-box idea suddenly hoovers up lots of generally-shaped capabilities from the generally-shaped performances in the dataset (which we thus learned are surprisingly low-hanging fruit to distill from the data)". (I do have the sense that there's some things here that I'm not being clear about in my thinking,
9
Sorry, this is a tangent from this comment thread, but an important one, I think:
LLMs aren't good at generating interesting novel concepts on par with humans in deployment. But in deployment, we've turned off the learning, so of course they're bad at inventing interesting novel concepts. A brilliant human with anterograde amnesia would also be quite bad at inventing interesting novel concepts.
It seems much more unclear if LLMs develop interesting new concepts in training, while they're still learning.
They probably generate all kinds of interesting intuitive / S1 concepts and fine distinctions that allow them to get so good at the next token prediction task, just as experts in a domain generally learn all kinds of specialized conceptual representations.
(Though, apparently, and unlike human experts, the models don't thereby learn words for those concepts, or have the ability to introspect and put handles on their conceptual representations, any more than I can introspect into how my visual cortex works.)
More speculatively, an LLM agent might invent new explicit concepts for itself and learn to use them, in RLVF training, especially if different rollouts are allowed to communicate with each other via a shared scratch-pad or something. I don't think we have seen anything like this, and I'm not particularly expecting it at current capability levels, but I don't think we can rule it out.
When we say that LLMs don't generate new concepts, we're selling them short. The part of the whole LLM system that has something-like-fluid intelligence to come up with new concepts is the training process, which we basically never interact with (currently).
4
I think I would generally avoid saying that LLMs or current learning programs don't generate new concepts simpliciter. Plausibly I did, but if so, I'd hopefully be able to claim that it was a typo or elision for space/clarity. What I said here was "good at generating interesting novel concepts on par with humans". I know perfectly well that LLMs gain concepts (after a fashion) during training and have written about that. I would dispute them using / having concepts in the same relevant ways that humans have them though.
I'm confident that there's lots of interesting content generally speaking contained in LLMs, gained through training, which is unknown to all humans. (The same could be said of other systems such as AlphaGo, and even old-style Stockfish during runtime if you admit that.)
[...]
So like, yeah, they have something kinda related to human concepts in their full power, but not. This fits with my claim that they don't have much originary general intelligence; they have distilled GI from humans, some more distilled stuff that's not exactly "knowledge from humans" but is kinda more narrow (like, LLMs know word collocation frequencies like no human does); and some other stuff that's not very general. I posit.
4
Thanks! The distinction between "generating capabilities" and "hoovering up capabilities" is another small click for me.
2
Can you give an example of a thing that you'd be surprised if an AI did in the next, say, 1.5 years?
6
Kill everyone? I'd be pretty surprised, like 1 in 100 or 200 surprised or something like that.
Generating interesting novel concepts on par with humans? See https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce?commentId=dqbLkADbJQJi6bFtN
See also https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce?commentId=HSqkp2JZEmesubDHD#HSqkp2JZEmesubDHD
Now, would you list something impressive that you do expect an AI to do in the next 1.5 years (that I might not say)?
2
I'm more trying to operationalize "interesting novel concept." (But, it does look like we had approximately this conversation before and I'll try to reread first. I think basically you said "they generate a novel concept that hadn't been generated before and also people go on to use that concept in industry/science", does that sound right?)
Part of what brought me here was remembering you saying:
[...]
And wanting an example of thing that's more like "what's something that'd make you go 'okay, this was in fact as smart as a four year old'" (and therefore either the end is nigh, or, we're about to learn that children in fact did not have nearly all the intelligence juice.")
I'll try to think about some bets for ~1 year from now.
4
Yeah, basically. I'm trying to be concrete here, and just saying "their intellectual output could be judged like human intellectual output is judged".
[...]
It's a good question but it's hard because that stuff looks from the outside like mostly pretty easy tasks. The way in which it is not easy is the way in which it is not "a task". I guess, "very sample efficient learning" would be a concrete thing that 4yos do.
5
Nativization of a pidgin into a creole language might be an example, especially given that it seems to be largely underwritten by the cognitive plasticity of the linguistic developmental window.
[...]
Given that Opus 4.6 fails on very basic Classical Greek exercises (evidence towards "jaggedness"/bad "OOD generalization" even on very simple (though knowledge-heavy) tasks), I would be very surprised if it managed to successfully do something as unusual/OOD as creolizing a pidgin. It might also be very difficult to train it to do so, as it's a very open-ended thing, and thus it's very unclear how to specify a reward, and I would guess there isn't much data on the internet that could be used for training.
2
After I read this comment, my hasty-guess-of-a-Tsvi-model replies: 'the big surprise is that "solid performance on a wide range of technical tasks is not that connected to GI." This surprise sufficiently explains the surprise of ~easily achieving that performance. Any ex ante expectation that those tasks required lots of understanding would/should have been mediated by expecting they required GI. Given that they don't require GI, it's [not surprising? / not relevantly surprising?] that they don't require much understanding.'
4
[Sorry for the long delay.
I wrote this response the day you sent the above. But it felt clear that we were missing each other, and I wanted to try to inhabit your view, in an attempt to make more effective progress. But I was too tried to do that well at the time, and so put this away to come back to later. But I have a day job in addition to the other projects that I'm trying to push on, and this fell by the wayside for two weeks.]
[...]
Well part of the debate here is what the prior ought to be.
It's in some sense a confident prediction to assert that Moore's law will continue, in 1995. But, broadly, the burden of proof is more on the side of the guy who thinks that the trend will break. Or at least, it's not totally clear what the prior should be and where the burden of proof should lie.
From your linked post:
[...]
Yes exactly. I've updated that these tasks require less general intelligence than I thought, and as a consequence, I've updated that tasks in general require less general intelligence than I thought.
[...]
No, I think Claude 4.6 has quite weak fluid intelligence. I previously described that as "the LLMs are actually not very intelligent at all, but it turns out that you can make up for moderately weak intelligence with a lot of knowledge."
[...]
Because high fluid intelligence (at least as we currently conceive of it) 1) is maybe not necessary, and 2) might come from the default trajectory of LLM-AI development.
Like, it seems like you can maybe get a strategically superhuman AI by relying on a lattice of more-or-less specialized superhuman skills (including superhuman engineering, and superhuman persuasion, and superhuman corporate strategy, and so on), without having much fluid intelligence.
To be clear, it also seems possible to me that we will make superhuman AI agents that don't have this fluid intelligence special sauce. Those AIs will be adequate to automate almost all human labor, because almost all of human labor is more-or-less
2
@TsviBT here's my distilled paraphrase of your view, perhaps mostly in my own conceptual vocabulary. Let me know how close this is.
[...]
I have some response, but first, is that about right, as an expression of your view?
2
Thanks.
[...]
(I wouldn't use these words probably, but it's a fine gesture in the direction.)
[...]
[Acknowledging that you acknowledged the ontology skew] Meh. I don't think "fluid" vs. "crystallized" is all that important / clear / useful a distinction. It kinda sorta gets at the things, and other people bring it up so I use it. IDK if other people elide that distinction. I'd talk more about general intelligence, though that packs in additional stuff; I'm using something spiritually like Yudkowsky's definition; something like "cross-domain optimization power divided by inputs". Also gestured here: https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#AGI
[...]
IDK if this is true.
[...]
No, I don't think there's one specific point I think everyone's missing, or everyone with short timelines is missing. If there were, I suppose it would be more like "notice that you're deferring way more than you're noticing, and that others are too, and that this is creating very bad epistemic tidal forces" or something, but that's kinda hard to discuss productively. I keep repeating that I don't understand how you / others got to be so confident in short timelines in part so that it's clear that IDK what you're missing even on my perspective. I try to ask people to lay out their reasoning more in order to bring out background assumptions that I can disagree with better, which background assumptions support the [past x years of LLM observations] --> [confident short timelines] update. But that doesn't work that well / is frustrating.
For example, I think that besides the "crystallizes int could make fluid int" thing, you're also saying "we have fluid int or are close to it probably". I'm asking about that and wanting to argue against that (that is, argue against the reasoning I've heard so far as not supporting the stated confidence). IDK how to phrase that as a positive statement for a position summary, because I would norma
2
I think I'm saying "crystalized intelligence can, to a large extent, substitute for fluid intelligence". This is true to an extent, of humans, but it's much more true of AIs, because they can have so much more crystalized intelligence than any human could hope to attain.
This is relevant to modeling if LLM agents will transform the world and to modeling if LLM agents will rapidly give way to something that's much more capable.
In particular, I (unconfidently) dispute that developing an AI with fluid intelligence is a research project that is itself heavily and crucially loaded on fluid intelligence.[1]
On my view, it is pretty likely that huge amounts of superhuman crystalized intelligence can find fluid-intelligence-emulating mechanisms (possibly with a necessary ingredient of a relatively small amount of genius fluid intelligence that even huge amounts of crystalized intelligence can't substitute for, or possibly even without that input).
In that sense, we're "close to" solving fluid intelligence, even if there's decades of subjective research an iteration time between here and there.
I do additionally suspect that mechanisms to implement fluid intelligence are just not that hard to invent and/or scale to, starting from the AI tech of 2026. Like, it seems somewhat likely to me that that various dumb ideas would just totally work, or that doing the same stuff we've already been doing, but more so will totally work. However, I'm much less confident about this point, and perhaps you can teach me some things that would quickly cause me to change my mind.
I want to check if this comment is clarifying, or if it feel like me repeating things that I've already said.
1. ^
Though you flagged that those aren't the words that you would use, so
2
Is there a way you could restate this in terms of one or more propositions that are fairly load-bearing for your confident short timelines? Is it this?
[...]
2
I'm struggling to get clear on the logical structure of your beliefs. Cf. your comments
[...]
and
[...]
and
[...]
And
[...]
Can you please clarify what are main big thingies that you expect to happen fairly confidently within 10 years? Can you clarify what drives your confident beliefs in those thingies happening? E.g. are you confident in some X happening due to being confident that we have fluid intelligence already or are close, or is that not the case?
Maybe you could make up words for the main scenarios and main capabilities / faculties you're thinking of?
2
To mods (@Raemon): this would be an example of a place where a "have an LLM summarize the exchanges in this thread between these two users, with links / quotes" button could be helpful.
(Also, it seems that the option to temporarily switch to LW editor was disabled, so I cannot tag people?)
4
I've been reading this thread and feeling motivated to at least make it easier to export the conversation to clipboard so you can more easily paste into LLM (in my case so I can argue with the AI about what obvious objections you'd have to what I'd say next).
I'm a bit confused about what's going on with the markdown editor. I've asked other mods.
2
(actually I asked for Gemini 3.1 pro preview for a summary of a copypasted version and it wasn't good)
2
As evidenced by base models outperforming RLVR'd models on pass@k for large k.
4
I don't think this result plausibly holds up very well on certain important classes of problems or it might hold but for absurdly large k. In particular, I think GPT-5.1 is based on a base model that's pretty similar in quality to GPT-4o (possible somewhat better, possible literally the same base model, I forget) while it's surely requires k >>1000 for the GPT-4o base model to solve the hardest math problems that gpt-5.1 >30k tokens.
2
Would you be able to coarsely quantify this? Like, let's say OpenThinky has 500 genius human engineers, and have 100x as much compute as today and impunity and lots of CodeBrain5 coding agent things. Or whatever parameters you want to set. Is your median time to actually FOOM/takeover more like 1 year, 4 years, or 10 years?
2
What do you mean by genius human engineers?
Part of my model is that like 25% of the math and CS phds on earth, and especially the ones that win Nobel prizes, will be working on this problem.
[...]
I don't know. I think my median is FOOM in 2 years? This is an ass-number though. I don't feel super confident.
I'm like 90% probability that it happens within 10 years, and 95% probability that it happens within 35 years?
4
(To be a bit more transparent: I had not previously considered "a hundred thousand technical PhDs all try really hard to crack AGI"; I haven't heard that argument/scenario before and I don't know what to think about that and it would substantially shorten my timelines. I don't yet understand why that seems likely / what scenario about that seems likely to you.)
6
Why I think that might happen:
* Background: almost nothing that most humans do actually requires fluid intelligence. Most people, most of the time, are executing routine cognitive operations. And most of the people who are using their fluid intelligence on the job could do just as well or better if they had a massive memory of case studies to extrapolate from instead of attempting novel reasoning.
* Most of earth's geniuses currently spend most of their time doing routine cognitive operations—pattern matching from their prior experience to solve problems, often in the context of automatable tasks like implementing experiments or solving engineering problems. When those classes of task are automated, it will free up the capacity of the geniuses.
* At this point, most of all the work in the world will be automated or in the process of being automated. Science and tech development will be going faster than ever in human history. It will be obvious to the whole world that AI is a really big deal.
* Also, it will be obvious to many people that there's something missing: the AIs are doing more and better design and engineering, faster, than human civilization ever did, and they're accelerating the science, but they're not doing the science. There will be enormous financial and strategic incentives to crack that.
2
Ok, thanks. I think I'll probably have to chew on this scenario to say much of use. (I mean, I've thought about related things, but haven't asked myself about this scenario.) My initial reaction is skepticism which I think comes from a combo of
* LLMs are somewhat less useful than you seem to think
* Humans apply somewhat more GI than you seem to think
* The most important stuff would still be bottlenecked on human GI and would be hard to accelerate; you don't just simply "free up" the humans in a super liquid, fungible way
* If this were happening, some pretty strong political forces would be at play, including hopefully / kinda probably (??) a strong push to stop the spiral
But I'm not super confident about any of that. It's strategically relevant but ATM I don't have much novel perspective to offer, and it seems to need some other expertise (e.g. a good understanding of politics, of science and tech research, and similar).
4
Ok, I see. Now, regarding your disjunction earlier of (in my words)
* A. (NAA (nonAGI AI) takeover) You can get strategic takeover AI without AGI
* B. (AGI soon easy) Gippity+ will soon be AGI by adding a bit more ~mundane human research juice
* C. (AGI soon hard) Gippity+++ will soon be AGI by adding a couple big insights
First, to clarify, I think the discourse on this thread is that I asked you about
[...]
and you said
[...]
and now we are discussing what NAA looks like and how timelines look in NAA takeover world.
Now I'm wondering, what are your very approximate relative probabilities of these things? E.g. is one of them 90% of the source of your confidence (I mean, 90% of your prob mass) in FOOM within 10 years? If they are roughly equal, I would raise my eyebrow and say "that seems kinda strange, unless there's a shared factor such as you thinking that actually we basically have ~AGI in current systems; if so, could you clarify that shared factor".
2
As stated, these don't have to sum to 1. B and C are mutually exclusive but A can be true even if B or C are also true.
(I also object a bit to calling "strong fluid intelligence" "AGI."
Part of what's at stake is how far can you get with basically just specialized knowledge and the ability to train new specialized knowledge. It would be surprising to me, but not out of the question, that there's almost nothing that such an AI can't do that an AI with more fluid intelligence can do. But I only object a bit.)
Ass numbers:
* A: 80%
* B: 40%
* C: 30%
[...]
I mean that's kind of fair. But I in fact don't have a lot of precise ability to distinguish between "one key idea is missing" and "only engineering schlep is missing". Those wolds look very similar, to me, and so get similar amounts of mass.
2
We're on the same page that you can make up for it with a lot of knowledge for some swath of performances. For other performances (games, RLVR, https://tsvibt.github.io/theory/pages/bl_24_07_25_09_52_56_652909.html ), you can make up for it with brute compute.
I suppose the question is whether this sort of thing does FOOM / takeover. Are you saying you can make up for weak intelligence with knowledge (gleaned from human text) well enough to do that?
2
More like you can make a weak intelligence with lots of specialized knowledge and skills, mostly gleaned from RL (though starting from the superhuman breadth of baseline knowledge that GPT-4 had), that can outcompete humans in acquiring power and/or FOOM.
2
(Splitting out for better threading)
[...]
Um ok, but, do you get that I'm also saying that you should also update that there's some type of task which you are observing to have a different relative need for general intelligence compared to other tasks?
2
I get that you're saying something like that.
I think you're saying "that coding fell to methods like these is both evidence that methods like these are more powerful than we might have guessed, and also evidence that coding required less general intelligence than we might have guessed."
4
Yes. (With the tangential but crucial caveat that "coding" as a category simply does not work in this context to support the relevant inferences. Cf. https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense?commentId=C8dWvwdeTFyWnnahi )
2
I'm right now trying to inhabit this point, and try to really grok it.
I guess it could be the case that the kind of intelligence that you need to engineer software and the kind that you need to develop novel algorithms are almost completely disjoint and unrelated. You can basically solve "make an AI that can make software", and not have even scratched the surface of "make an AI that can make new algorithms / new interesting math concepts".
(Is this what you think?)
It would surprise me if this were true, because it seems like there's a lot of overlap in the mental operations between those two kinds of work.
6
This is a good question, thank you. (It's an important topic which I won't fully treat here.)
[...]
One very-cartoon model, which I guess you know but to lay it out:
[...]
On a psychologizing note, which I hope to offer just as a hypothesis-piece to maybe track if you weren't already (I think you're pretty likely to be already aware of this, but from my perspective there's a significant chance that you don't think of it frequently enough): There's a strong default to overly interpret things (behaviors, say) with a presumption of a human-shaped background mental context. E.g. how people ask "does the LLM believe X", even though that question probably doesn't straightforwardly translate from humans to LLMs at all and would lead to incorrect inferences about what behaviors would be concomitant. Cf. https://www.lesswrong.com/posts/L2h9nAtPqEFK6atSJ/an-anthropomorphic-ai-dilemma#Gemini_modeling_with_alien_contexts_is_hard
In particular, when people imagine changes to gippity-based systems, such as "unhobbling" by adding tool access, they imagine that what gets opened up for the gippity is similar to what would be opened up for a human if you newly made that same change (e.g. gave a human that tool). I think this drives some "we're close to having AGI" intuitions, and I think it's mistaken.
2
I like and basically endorse your cartoon model!
Modulo, I think that more of the capabilities are coming from the RLVF than from copying humans than you seem to think.[1]
[...]
Why are you emphasizing the pretraining instead of the RL?
1. ^
Though Zack dropped a paper in this thread which looks relevant to that question.
2
Well, in this example, there is an end to Moore's law specifically, and you can even approximately call it based on physics (atomic scale for transistors), and the guy who believes in LGU (line go up) narrowly for Moore's law specifically would be being silly.
Let me refine my statement about burden of proof (recapitulating something from DMs). I think that 10 or 20 years ago, if you or I had had opinions about when AGI comes, we would have correctly had very broad/uncertain timelines. Is that true? Assuming that's true: Right now, I have significantly shorter timelines than I shoulda/woulda had 10 years ago; I would have (if I had had worked out timelines) said it seemed quite unlikely, like <2% or something, to get AGI within 5 or 10 years. Now I say more like 5% or something like that.
I take it that you have quite a lot more probability on AGI within 10 years, though I just now realized I don't actually know your specific beliefs. Could you link to writing you've done about your timelines beliefs? For example, would I be correct in assuming that your median is <10 years? Assuming that's the case:
You must have had quite a large update. Your beliefs went from a broad spread out thing, to a quite sharp (relatively speaking) distribution. That update would look like something along the lines of:
[...]
* For example, if previously you had 80% probability on "AGI in >15 years", and then 5 years later you have 50% probability on "AGI in <10 years", then you must have lost at least 60% prob-weighted hypotheses from your original distribution.
I'm trying to understand that update. When I ask people about that update, they give various statements, but somehow I come away having no idea how they made their update to get to a confident (sharp) distribution. I mean, I can write out sentences like "gippity++ automates AI R&D", and I mean, qualitatively I agree that this is plausible and is extremely alarming (and should be stopped ASAP etc. etc.); but I have no idea ho
2
I feel like I understand the question you're asking:
~"If you previously had a very spread-out prediction, and now you have a relatively more narrow prediction, between then and now, you must have made a pretty large Bayesian update—you saw some evidence with a quite lopsided odds ratio.
If you made such an update, you should be able to point to the evidence, and explain why you think the odds ratio is so lopsided. Please do that!"
(Is that about right?)
But, I don't get why the evidence / arguments that people are offering isn't clarifying for you.
Like, I keep trying to point to the same basic IMO pretty straightforward considerations, and you keep saying things like "somehow I come away having no idea how they made their update to get to a confident (sharp) distribution". [1]
I'm not sure what kind of thing you're asking for that's different from the kinds of things that I'm already saying. Do you want more of a quantitative model? Do we just need to get further into the argument tree?
I further get that, from your perspective, you're saying something like "dude, give me actual evidence and arguments", and I'm somehow being a dunce about that. But I don't get what exactly you're asking for.
1. ^
Which to be clear, is socially and epistemically valid, on your part. Please continue to loudly say "I don't get why everyone thinks this", for as long as that's true. I want to do the opposite of shaming you for not getting it.
4
I don't believe I can pass your ITT, but I will try to draw a sample from my model of you (which is almost entirely a much more blobulous model of generally short timelines people, so sorry for resulting lumpification), in the form of a dialogue. [After writing it, this isn't yet that much of a great attempt at understanding you, sorry; maybe it's still a helpful summary of what I think the discourse state is.]
[...]
Thread 1 (not very Eli?):
[...]
Thread 2 (more Eli?):
[...]
2
Um no. At least if "training data" is meant to refer to the text corpuses used in pre-training. I think the problem-solving capabilities are mostly coming from the RLVF.
[...]
I would not endorse this.
Like, if I thought that we were conceptually / technically far from AIs that can automate the process of scientific discovery, I would much less expect a FOOM in the next 10 years (though we would still have an emergency, because automating science isn't a necessary capability for destabilizing or ending the world via any of a number of different pathways).
[...]
I would be excited about attempts at clarification here! (Modulo that they seem potentially very infohazardous.)
2
Ok great. Can you clarify why you think this? Previously you wrote, in response to "What makes you think we're close?":
[...]
Can you clarify / expand? What makes you think the METR results imply we're close to having algorithmic ideas sufficient to automate scientific discovery?
4
One thing which is awkward about this operationalization is that it's not clear how big an innovation "attention is all you need" is. Like, we already had multi-head attention before that paper, and ablating out the other components from the transformer isn't that galaxy-brained a thing to try (though of course the authors executed well on it).
2
I was thinking something like that when I wrote it.
Do you have a better suggested operationalization?
4
Thanks!
[...]
Curious what formats. (E.g. I'm happy to have a call to be published on YouTube; we could do a private discussion, though that's not my preference.)
Just for the public record:
[...]
I don't agree with this (e.g. I doubt either Greenblatt or I could give a high-quality ITT of the other's view, and I expect that one or both of us would update substantively if we understood each other).
4
Is it your experience that if someone comes to understand your view, they update significantly towards it, even if they had an elaborate-ish short timeline view beforehand?
6
Yes, but this is an extremely weak signal, in that it's a small number (n=2 to 5 or something, depending who you count) and it's pretty selected for "people who talk to me a lot or people who actively tell me that I updated them somewhat", and I have a high bar for understanding (for both parties symmetrically). Abram might be someone who somewhat understands my view but only slightly updated towards it?
I believe humans have much lower memory capacities because we perform continual learning. We experience catastrophic forgetting because we're learning on a self-selected narrow dataset. Models titrate their learning rates and intermix all of their training examples, so as to preserve previous learning. In humans, learning is always-on and clustered by topic, so it tends to overwrite previous knowledge unless that knowledge is replayed and re-learned. This is workable because we tend to re-use important skills and knowledge, but it does drastically reduce our memory capacity.
It would be fairly straightforward to emulate this setup for LLMs, at the cost of that high memory capacity. But that's a large cost to pay.
One component of fluid intelligence that models seem to particularly lack, probably because they're rarely explicitly present in either the base corpus or RL training sets, is Human-like metacognitive skills.
6
The reason I found this situation confusing for awhile (and am still somewhat confused) is that it seems like there is a lot of crystallized intelligence available from the Human Corpus about how to be smart. AIs seem to know how to apply individual pieces of it, but not go out of their way to apply it all in a consistent/coherent manner.
(Things like "make a list of the constraints", "keep track of evidence, when you generate new hypotheses, review whether existing evidence rules it out".)
I'm not surprised that AIs didn't early on figure out how to apply various cognitive concepts in a coherent/consistent way. But, I'm surprised it hasn't fallen out more by now from various RL training. My current sense is "well it just keeps being easier to develop/reinforce medium-shallow domain specific cognitive tools, than to generalize and apply deeper cognitive concepts."
The reason, contra @TsviBT , I keep feeling like we're in short timeline world is "idk man, all the pieces seem to be fucking there already, surely a good enough RL training regimen should be able to surface and integrate them even if the models are still fundamental dumb in some fluid-intelligency-y way." But, they do seem to keep being kinda dumb in ways that surprise me.
I have updated towards the LLMs as giant lookup table model, curious if that feels approximately right or not to you.
3
Haven't engaged enough to know, could be bid to engage, won't by default.
1
Training on "text about how to be smart" doesn't teach LLMs to be smart very well. It's one thing to know something and another to be able to execute on it. It's, how would I put it. A bit of a distribution mismatch.
Pre-training teaches an LLM "how to generate texts about how to be smart" - with some spillover into "how to actually do it". And not a lot of spillover.
Many LLM failure modes are also inhuman failure modes. They're mistakes humans wouldn't make in the first place, due to the way their minds are shaped. The texts that help humans avoid the typical human failure modes don't help with the inhuman failure modes much.
3
Yeah, but, the reason I have my current combination of beliefs/confusions is that LLMs are demonstrably able to execute on each individual mental move I'd expect a smart person to do (and to chain 2-3 of such actions reasonably).
The thing that is missing is them being able to keep applying them when situationally appropriate. It feels like scaffolding should be able to solve this. I've heard some things about Claude Bureaucracy setups that do pieces of this, where a watchdog is checking "does the main agent seem to be making [various kinds of mistakes]" or "is this a good time to do [specific thing]."
LLMs are demonstrably able to execute on each individual mental move I'd expect a smart person to do
For the record, I think this is bigtime streetlighting. There's a bunch of mental moves, broadly construed. Then there's a subset which are reflected in what you notice when you watch LLMs or humans doing stuff. I think it's a pretty "small" subset, in the sense that you're looking at a "surface", or you're looking at products rather than manufacturing processes so to speak (consider the complexity of a toaster vs. the complexity of the transitive closure of a toaster under the operation "...and also the technological concepts needed to create that"). I think you can tell it's small by
- Thinking about the role of language (what it is and isn't for, within Thinking)
- Noticing that when you zoom in on your thoughts, most of the important stuff happens in little leaps that are opaque to you
- (Various things about LLMs not being creative)
1
Like I said: distribution mismatch.
An LLM can do X successfully when prompted to, but doesn't know it should do X without any prompting cues (metacognitive gap), doesn't know how to tell when X is appropriate over long contexts (metacognitive gap, distribution mismatch), and doesn't know how to handle long contexts well in general.
Things like "set a watchdog LLM to check on the main LLM" show that the LLM itself isn't fundamentally incapable. If slim scaffolding externalizing the desired behavior gets the same model to do it, you could just distill to fold the scaffolding-induced behavior into the model itself. It has the capacity to learn to do it. It just doesn't do it by default.
3
Yes, and my point is "I would have expected this to work with scaffolding, and, therefore, I also expect there to be ways of getting the same behavior out of the core AI model." (I didn't say the second part before, it's more like 'it's not really a crux for me whether you solve this via scaffolding or training, the raw ingredients seem to be there.')
BUT, the fact that we're still seeing some problems with this is somewhat surprising to me, and I'm not sure if the update is more like "my underlying model here is wrong" or more like "well it takes more sweat and elbow grease and scaling to leverage the existing capabilities in a generalized way."
-1
You "would have expected" that and you would be wrong.
Doesn't matter if it's just 32 bits worth of connections - it's 32 bits worth of connections that aren't currently present in the model. Nothing fundamental stops them from being present. It's just that no one burned them in with training, so they aren't there.
Finding all the ways to generalize from improved prompts and scaffolding into improved models isn't at all trivial. And people aren't at the point of "search and refinement at scale" yet.
2
Downvoted because your string of comments here feel weirdly aggro, and don't feel like they are really engaging with what I'm saying. (Like, yes, I am saying I am confused and presumably wrong about something. You seem to want to go hard on saying "yes you're wrong!" and I'm like "yes, I know?")
2
I strongly agree, but while the distinction between fluid and crystallized intelligence holds some truth, it is by no means the only lens here. Analytic vs. intuitive is also an interesting framing, reasoning models are close to superhuman on the analytic side while lagging on the intuitive one. Intelligence has many forms, and IQ, the g factor, or any other monolithic metric can obscure large disparities across capabilities.
1
I agree. I think (current) LLMs are mainly impressive because they know everything, and their actual pound-for-pound intelligence is still fairly subhuman.
When I see the reasoning of a LLM, I am struck by how "unsmart" it seems. Going down blind paths, failing to notice big-picture implications, repeating the same thoughts over and over. They do a lot of thinking, but it's still not high quality thinking.
Yes, I know reasoning is not really an analogue for human thinking. But whatever it is—reasoning, daydreaming, journaling—it's pretty low-quality. As an example, Moonshot posted the reasoning chains of K2-Thinking as it tried to solve BrowseComp problems. A certain task called for the name of a fictional character played by an actor who...
[...]
K2 quickly zeroes in on actor Brad William Henke, who fits many clues. But he did not star in a sci fi film about an alien invasion, so it cannot be him.
Bizarrely, K2 is unable to accept this.
It comes back to Brad William Henke over and over. I count nearly a half-dozen cases where it examines Brad William Henke's filmography (again), concludes that he did not star in a sci-fi film (again), and moves on (again)...only to return and repeat the process from square one (saying stuff like "Great! Brad William Henke matches many clues"). "Brad" appears 71 times in its reasoning.
It frequently seems to forget what the task actually requires it to do.
[...]
...it doesn't matter if he fits many clues; even a single fail eliminates him as an answer! It notices he appeared in Pacific Rim and starts hammering at this tenuous connection (Is Pacific Rim an alien invasion film? Does Brad William Henke's brief appearance as "Construction Foreman" count as a starring role? Does "Construction Foreman" suffice as the character's name?)
Only after many failed clues does it sour on Brad William Henke, eventually finding the right answer. (Side note: why is Moonshot just posting BrowseComp solutions on the open web, with no canary
Slightly hot take: Longtermist capacity/community building is pretty underdone at current margins and retreats (focused on AI safety, longtermism, or EA) are also underinvested in. By "longtermist community building", I mean rather than AI safety. I think retreats are generally underinvested in at the moment. I'm also sympathetic to thinking that general undergrad and high school capacity building (AI safety, longtermist, or EA) is underdone, but this seems less clear-cut.
I think this underinvestment is due to a mix of mistakes on the part of Open Philanthropy (and Good Ventures)[1] and capacity building being lower status than it should be.
Here are some reasons why I think this work is good:
- It's very useful for there to be people who are actually trying really hard to do the right thing and they often come through these sorts of mechanisms. Another way to put this is that flexible, impact-obsessed people are very useful.
- Retreats make things feel much more real to people and result in people being more agentic and approaching their choices more effectively.
- Programs like MATS are good, but they get somewhat different people at a somewhat different part of the funnel, so they don
If someone wants to give Lightcone money for this, we could probably fill a bunch of this gap. No definitive promises (and happy to talk to any donor for whom this would be cruxy about what we would be up for doing and what we aren't), but we IMO have a pretty good track record of work in the space, and of course having Lighthaven helps. Also if someone else wants to do work in the space and run stuff at Lighthaven, happy to help in various ways.
4
I'd be interested to hear what kind of things you'd want to do with funding; this does seem like a potentially good use of funds
I think the Sanity & Survival Summit that we ran in 2022 would be an obvious pointer to something I would like to run more of (I would want to change some things about the framing of the event, but I overall think that was pretty good).
Another thing I've been thinking about is a retreat on something like "high-integrity AI x-risk comms" where people who care a lot about x-risk and care a lot about communicating it accurately to a broader audience can talk to each other (we almost ran something like this in early 2023). Think Kelsey, Palisade, Scott Alexander, some people from Redwood, some of the MIRI people working on this, maybe some people from the labs. Not sure how well it would work, but it's one of the things I would most like to attend (and to what degree that's a shared desire would come out quickly in user interviews)
Though my general sense is that it's a mistake to try to orient things like this too much around a specific agenda. You mostly want to leave it up to the attendees to figure out what they want to talk to each other about, and do a bunch of surveying and scoping of who people want to talk to each other more, and then just facilitate a space and a basic framework for those conversations and meetings to happen.
1
I think this is a great idea that would serve an urgent need. I'd urge to you do it in the near future.
1
Agree with both the OP and Habryka's pitch. The Meetup Organizers Retreat hosted at Lighthaven in 2022 was a huge inflection point for my personal involvement with the community.
Retreats make things feel much more real to people and result in people being more agentic and approaching their choices more effectively.
Strongly agreed on this point, it's pretty hard to substitute for the effect of being immersed in a social environment like that
5
To add a second data point: I think effective community/capacity building can be both incredibly challenging and incredibly impactful. I respect the people who do CB well a lot, much more than the median AIS researcher I meet (especially since it requires pushing back against the default incentive gradients). I’m not sure how much this means to people in practice, but I think it’s worth putting on the public record anyways.
3
why longtermist, as opposed to AI safety?
I think there are some really big advantages to having people who are motivated by longtermism and doing good in a scope-sensitive way, rather than just by trying to prevent AI takeover even more broadly "help with AI safety".
AI safety field building has been popular in part because there is a very broad set of perspectives from which it makes sense to worry about technical problems related to societal risks from powerful AI. (See e.g. Simplify EA Pitches to "Holy Shit, X-Risk". This kind of field building gets you lots of people who are worried about AI takeover risk, or more broadly, problems related to powerful AI. But it doesn't get you people who have a lot of other parts of the EA/longtermist worldview, like:
- Being scope-sensitive
- Being altruistic/cosmopolitan
- Being concerned about the moral patienthood of a wide variety of different minds
- Being interested in philosophical questions about acausal trade
People who do not have the longtermist worldview and who work on AI safety are useful allies and I'm grateful to have them, but they have some extreme disadvantages compared to people who are on board with more parts of my worldview. And I think it would be pretty sad to have the proportion of people working on AI safety who have the longtermist perspective decline further.
5
It feels weird to me to treat longtermism as an ingroup/outgroup divider. I guess I think of myself as not really EA/longtermist. I mostly care about the medium-term glorious transhumanist future. I don't really base my actions on the core longtermist axiom; I only care about the unimaginably vast number of future moral patients indirectly, through caring about humanity being able to make and implement good moral decisions a hundred years from now.
The main thing I look at to determine whether someone is value-aligned with me is whether they care about making the future go well (in a vaguely ambitious transhumanist coded way), as opposed to personal wealth or degrowth whatever.
6
Yeah, maybe I'm using the wrong word here. I do think there is a really important difference between people who are scope-sensitively altruistically motivated and who are in principle willing to make decisions based on abstract reasoning about the future (which I probably include you in), and people who aren't.
3
I have the impression that neither "short" nor "medium"-termist EAs (insofar as those are the labels they use for themselves) care much about 100 years from now. With ~30-50 years being what seems what the typical "medium"-termist EA cares about. So if you care about 100 years, and take "weird" ideas seriously, I think at least I would consider that long-termist. But it has been a while since I've consistently read the EA forum.
2
I think the general category of AI safety capacity building isn't underdone (there's quite a lot of it) while I think stuff aiming more directly on longtermism (and AI futurism etc) is underdone. Mixing the two is reasonable tbc, and some of the best stuff focuses on AI safety while mixing in longtermism/futurism/etc. But, lots of the AI safety capacity building is pretty narrow in practice.
While I think the general category of AI safety capacity building isn't underdone, I do think that (AI safety) retreats in particular are under invested in.
Precise AGI timelines don't matter that much.
While I do spend some time discussing AGI timelines (and I've written some posts about it recently), I don't think moderate quantitative differences in AGI timelines matter that much for deciding what to do[1]. For instance, having a 15-year median rather than a 6-year median doesn't make that big of a difference. That said, I do think that moderate differences in the chance of very short timelines (i.e., less than 3 years) matter more: going from a 20% chance to a 50% chance of full AI R&D automation within 3 years should potentially make a substantial difference to strategy.[2]
Additionally, my guess is that the most productive way to engage with discussion around timelines is mostly to not care much about resolving disagreements, but then when there appears to be a large chance that timelines are very short (e.g., >25% in <2 years) it's worthwhile to try hard to argue for this.[3] I think takeoff speeds are much more important to argue about when making the case for AI risk.
I do think that having somewhat precise views is helpful for some people in doing relatively precise prioritization within people already working on safe...
I think most of the value in researching timelines is in developing models that can then be quickly updated as new facts come to light. As opposed to figuring out how to think about the implications of such facts only after they become available.
People might substantially disagree about parameters of such models (and the timelines they predict) while agreeing on the overall framework, and building common understanding is important for coordination. Also, you wouldn't necessarily a priori know which facts to track, without first having developed the models.
-3
i super agree, i al so think that the value is in debating the models of intelligence explosion.
which is why i made my website: ai-2028.com or intexp.xyz
3
It seems like a bad sign that, even with maximally optimistic inputs, your model never falsely retrodicts intelligence explosions in the past.
1
it's not meant to be qualitative, just a first draft, because i haven't found any other intexp simulators. do you know of any interactive intexp curve pages?
3
For those of us who do favor "very short timelines", any thoughts?
5
For people who are comparatively advantaged at this, it seems good to try to make the case for this in a variety of different ways. One place to start is to try to convince relatively soft target audiences like me (who's sympathetic but disagrees) by e.g. posting on LW and then go somewhere from here.
I think it's a rough task, but ultimately worth trying.
1
Personally it will be impossible for me to ignore the part of me that wonders "is this AGI/ASI stuff actually, for real, coming, or will it turn out to be fake." Studying median timelines bleeds into the question of whether AGI by my natural lifespan is 90% likely or 99.5% likely, and vice versa. So I will continue thinking very carefully about evidence of AGI progress.
4
Absence of AGI[1] by (say) 2055 is predicted by models that deserve to be developed in earnest (I'd currently give the claim 15%, with 10% mostly for technological reasons and 5% mostly because of a human-instituted lasting Pause or a disaster). This doesn't significantly affect the median timeline yet, but as time goes on these models can get stronger (Moore's law even in price-performance form breaking down, continual learning turning out to be a grand algorithmic obstruction that might take decades to solve, with in-context learning not good enough for this purpose within available compute). And this would start affecting the median timeline more and more. Also, development of AGI might result in a lasting ASI[2] Pause (either through societal backlash or from AGIs themselves insisting on this to prevent ASIs misaligned with them before they figure out how to align ASIs).
----------------------------------------
1. AGIs are AIs unbounded in ability to develop civilization on their own, without needing substantial human input, including by inventing aligned-with-them ASIs. ↩︎
2. ASIs are qualitatively more intelligent than humans or humanity, while non-ASI AGIs are reasonably comparable to humans or humanity, even if notably more capable. ↩︎
2
This is only somewhat related to what you were saying, but I do think 100 year medians vs 10 year medians does matter a bunch.
Here are some of my top candidates for big pushes to do right now on technical AI safety (low effort notes):
- Much better model organisms / misalignment analogies:
- Doing a wider set of pessimized training runs
- Good candidate for lots of AI labor automation? Like maybe good to try to set up pipelines for building these envs.
- Demonstrating risks from fitness-seekers/reward-seekers empirically
- Even on current models with better tests, see here
- Demonstrating various types of memetic spread of misalignment?
- Doing a wider set of pessimized training runs
- Actually do control
- Build pipelines for red-teaming monitors and the agent itself. For the agent red-teaming, I'd put particular focus on checking whether it continues malign trajectories.
- Scaffold integrated control features and other non-monitoring runtime control measures
- Human response and auditing
- Improving async and sync monitoring
- Agent security features
- Surveilling for rogue internal deployments (as in, building after-the-fact detection methods for rogue deployments)
- Preparing for handoff and elicitation
- Get AIs generically better at conceptual work
- Have a plan for the evals we ultimately need to see if handoff/deference would go well and start iterating on earli
9
If your model of we get safety is wrong, the effect of your third point may be largely to justify pushing capabilities in certain areas.
3
I sort of agree? I think the net effect on overall capabilites progress is pretty small and some of the action I proposed would hopefully divert people from generic capabilites to working on this type of (hopefully particularly differential) capabilities. But I agree that some of these actions would involve safety motivated people doing work that would shorten timelines (relative to if they did nothing / worked on areas with no capabilities externalities) and it could turn out this work isn't valuable.
I think for "Get AIs generically better at conceptual work" I think it seems especially relevant to account for whether: (1) the work would be done by capabilities people later anyway without this having a sufficiently useful acceleration effect on differential capabilities (2) the work has significant capabilities externalities. It's possible I should describe this area as "Get AIs generically better at particularly differential conceptual work", but I'm also sympathetic to work that tries less hard to be strongly differential/focused depending on the circumstances and various details.
We don't know how AIs are aligned.
A somewhat crazy aspect of the current situation is that we have very little confirmed public information about why frontier AIs end up being apparently behaviorally aligned. And more generally, we don't know what factors in training are most relevant for (behavioral) alignment. Like, what interventions in training result in Anthropic AIs following the constitution or make OpenAI AIs follow the spec? What factors tend to make them follow the constitution/spec less (or cause various specific misaligned behaviors)? It's not that hard to get an OK sense of what is roughly going on based on speculation, rumors, and non-public info, but this situation results in a much worse public understanding of alignment. I think AI companies should be much more transparent about this. (It's presumably not in their commercial interest to do this unilaterally, and it's not obvious that an idealized altruistic AI company should unilaterally release this information if they couldn't get other AI companies to do the same.)
Amusingly, just after I posted this, Anthropic released "Teaching Claude why" which has a bunch of information on how they behaviorally align their AIs (or at least how they iterate on particular behaviors/properties). (Though this doesn't seem close to sufficient for a reasonably complete understanding.)
3
LLM-agents are sorta good at tasks when given a lot of examples of those tasks, including in some OOD related tasks. Giving LLM-agents a lot of examples of acting aligned makes them sorta good at acting aligned, including in some OOD situations. Treating alignment as a task is partially effective, is my takeaway. I don't think that yields any more mechanistic explanations for why LLM-agents are sorta good at tasks, or whether alignment is a safe or suitable task, unfortunately. Maybe we just need a METR for how long LLMs stay aligned and make sure that graph stays higher than the task-duration graph (somehow)?
1
That sounds appealing if almost nothing ever changes, but we should expect discontinuities due to each or any of:
* The emergence of a new architecture / training regime
* Gaining the ability to self-modify
* The results of self-modification
* Gaining the ability to permanently elude oversight
* The consequences of acting at length with no oversight
* Gaining the ability to disempower humanity
* Achieving a deep and unrecognizable understanding of any one of many concepts important to humans (ontological shift)
We just don't understand any of this stuff. Even a perfectly benevolent superintelligent mind may be one digital prion from wiping us out, and it would be great to not get into that situation in the first place.
3
It sure would be great if there was a well-funded "AI safety" nonprofit with the goal to be as open as possible about AI research. Anyone considered that?
The capability evaluations in the Opus 4.5 system card seem worrying. The provided evidence in the system card seem pretty weak (in terms of how much it supports Anthropic's claims). I plan to write more about this in the future; here are some of my more quickly written up thoughts.
[This comment is based on this X/twitter thread I wrote]
I ultimately basically agree with their judgments about the capability thresholds they discuss. (I think the AI is very likely below the relevant AI R&D threshold, the CBRN-4 threshold, and the cyber thresholds.) But, if I just had access to the system card, I would be much more unsure. My view depends a lot on assuming some level of continuity from prior models (and assuming 4.5 Opus wasn't a big scale up relative to prior models), on other evidence (e.g. METR time horizon results), and on some pretty illegible things (e.g. making assumptions about evaluations Anthropic ran or about the survey they did).
Some specifics:
- Autonomy: For autonomy, evals are mostly saturated so they depend on an (underspecified) employee survey. They do specify a threshold, but the threshold seems totally consistent with a large chance of being above the relevant RS
and assuming 4.5 Opus wasn't a big scale up relative to prior models
It seems plausible that Opus 4.5 has much more RLVR than Opus 4 or Opus 4.1, catching up to Sonnet in RLVR-to-pretraining ratio (Gemini 3 Pro is probably the only other model in its weight class, with a similar amount of RLVR). If it's a large model (many trillions of total params) that wouldn't run decode/generation well on 8-chip Nvidia servers (with ~1 TB HBM per scale-up world), it could still be efficiently pretrained on 8-chip Nvidia servers (if overly large batch size isn't a bottleneck), but couldn't be RLVRed or served on them with any efficiency.
As we see with the API price drop, they likely have enough inference hardware now with large scale-up worlds (probably Trainium 2, possibly Trillium, though in principle GB200/GB300 NVL72 would also do), which wasn't the case for Opus 4 and Opus 4.1. This hardware would also have enabled them to do efficient large scale RLVR training, which too they possibly weren't able to do yet in the times of Opus 4 and Opus 4.1 (but there wouldn't be an issue with Sonnet, which would fit in 8-chip Nvidia servers, so they mostly needed to apply its post-training process to the larger model).
2
What would hard mode look like?
The AIs are obviously fully (or almost fully) automating AI R&D and we're trying to do control evaluations.
Inference compute scaling might imply we first get fewer, smarter AIs.
Prior estimates imply that the compute used to train a future frontier model could also be used to run tens or hundreds of millions of human equivalents per year at the first time when AIs are capable enough to dominate top human experts at cognitive tasks[1] (examples here from Holden Karnofsky, here from Tom Davidson, and here from Lukas Finnveden). I think inference time compute scaling (if it worked) might invalidate this picture and might imply that you get far smaller numbers of human equivalents when you first get performance that dominates top human experts, at least in short timelines where compute scarcity might be important. Additionally, this implies that at the point when you have abundant AI labor which is capable enough to obsolete top human experts, you might also have access to substantially superhuman (but scarce) AI labor (and this could pose additional risks).
The point I make here might be obvious to many, but I thought it was worth making as I haven't seen this update from inference time compute widely discussed in public.[2]
However, note that if inference compute allows for trading off betw...
9
Ok, but for how long? If the situation holds for only 3 months, and then the accelerated R&D gives us a huge drop in costs, then the strategic outcomes seem pretty similar.
If there continues to be a useful peak capability only achievable with expensive inference, like the 10x human cost, and there are weaker human-skill-at-minimum available for 0.01x human cost, then it may be interesting to consider which tasks will benefit more from a large number of moderately good workers vs a small number of excellent workers.
Also worth considering is speed. In a lot of cases, it is possible to set things up to run slower-but-cheaper on less or cheaper hardware. Or to pay more, and have things run in as highly parallelized a manner as possible on the most expensive hardware. Usually maximizing speed comes with some cost overhead. So then you also need to consider whether it's worth having more of the work be done in serial by a smaller number of faster models...
For certain tasks, particularly competitive ones like sports or combat, speed can be a critical factor and is worth sacrificing peak intelligence for. Obviously, for long horizon strategic planning, it's the other way around.
4
I don't expect this to continue for very long. 3 months (or less) seems plausible. I really should have mentioned this in the post. I've now edited it in.
[...]
I don't think so. In particular once the costs drop you might be able to run substantially superhuman systems at the same cost that you could previously run systems that can "merely" automate away top human experts.
7
The point I make here is also likely obvious to many, but I wonder if the "X human equivalents" frame often implicitly assumes that GPT-N will be like having X humans. But if we expect AIs to have comparative advantages (and disadvantages), then this picture might miss some important factors.
The "human equivalents" frame seems most accurate in worlds where the capability profile of an AI looks pretty similar to the capability profile of humans. That is, getting GPT-6 to do AI R&D is basically "the same as" getting X humans to do AI R&D. It thinks in fairly similar ways and has fairly similar strengths/weaknesses.
The frame is less accurate in worlds where AI is really good at some things and really bad at other things. In this case, if you try to estimate the # of human equivalents that GPT-6 gets you, the result might be misleading or incomplete. A lot of fuzzier things will affect the picture.
The example I've seen discussed most is whether or not we expect certain kinds of R&D to be bottlenecked by "running lots of experiments" or "thinking deeply and having core conceptual insights." My impression is that one reason why some MIRI folks are pessimistic is that they expect capabilities research to be more easily automatable (AIs will be relatively good at running lots of ML experiments quickly, which helps capabilities more under their model) than alignment research (AIs will be relatively bad at thinking deeply or serially about certain topics, which is what you need for meaningful alignment progress under their model).
Perhaps more people should write about what kinds of tasks they expect GPT-X to be "relatively good at" or "relatively bad at". Or perhaps that's too hard to predict in advance. If so, it could still be good to write about how different "capability profiles" could allow certain kinds of tasks to be automated more quickly than others.
(I do think that the "human equivalents" frame is easier to model and seems like an overall fine simplific
7
In the top level comment, I was just talking about AI systems which are (at least) as capable as top human experts. (I was trying to point at the notion of Top-human-Expert-Dominating AI that I define in this post, though without a speed/cost constraint, but I think I was a bit sloppy in my language. I edited the comment a bit to better communicate this.)
So, in this context, human (at least) equivalents does make sense (as in, because the question is the cost of AIs that can strictly dominate top human experts so we can talk about the amount of compute needed to automate away one expert/researcher on average), but I agree that for earlier AIs it doesn't (necessarily) make sense and plausibly these earlier AIs are very key for understanding the risk (because e.g. they will radically accelerate AI R&D without necessarily accelerating other domain).
6
At first glance, I don’t see how the point I raised is affected by the distinction between expert-level AIs vs earlier AIs.
In both cases, you could expect an important part of the story to be “what are the comparative strengths and weaknesses of this AI system.”
For example, suppose you have an AI system that dominates human experts at every single relevant domain of cognition. It still seems like there’s a big difference between “system that is 10% better at every relevant domain of cognition” and “system that is 300% better at domain X and only 10% better at domain Y.”
To make it less abstract, one might suspect that by the time we have AI that is 10% better than humans at “conceptual/serial” stuff, the same AI system is 1000% better at “speed/parallel” stuff. And this would have pretty big implications for what kind of AI R&D ends up happening (even if we condition on only focusing on systems that dominate experts in every relevant domain.)
I agree comparative advantages can still important, but your comment implied a key part of the picture is "models can't do some important thing". (E.g. you talked about "The frame is less accurate in worlds where AI is really good at some things and really bad at other things." but models can't be really bad at almost anything if they strictly dominate humans at basically everything.)
And I agree that at the point AIs are >5% better at everything they might also be 1000% better at some stuff.
I was just trying to point out that talking about the number human equivalents (or better) can still be kinda fine as long as the model almost strictly dominates humans as the model can just actually substitute everywhere. Like the number of human equivalents will vary by domain but at least this will be a lower bound.
4
quantity?
2
https://www.lesswrong.com/posts/uPi2YppTEnzKG3nXD/nathan-helm-burger-s-shortform?commentId=rnT3z9F55A2pmrj4Y
Sometimes people think of "software-only singularity" as an important category of ways AI could go. A software-only singularity can roughly be defined as when you get increasing-returns growth (hyper-exponential) just via the mechanism of AIs increasing the labor input to AI capabilities software[1] R&D (i.e., keeping fixed the compute input to AI capabilities).
While the software-only singularity dynamic is an important part of my model, I often find it useful to more directly consider the outcome that software-only singularity might cause: the feasibility of takeover-capable AI without massive compute automation. That is, will the leading AI developer(s) be able to competitively develop AIs powerful enough to plausibly take over[2] without previously needing to use AI systems to massively (>10x) increase compute production[3]?
[This is by Ryan Greenblatt and Alex Mallen]
We care about whether the developers' AI greatly increases compute production because this would require heavy integration into the global economy in a way that relatively clearly indicates to the world that AI is transformative. Greatly increasing compute production would require building additional fabs whi...
I'm not sure if the definition of takeover-capable-AI (abbreviated as "TCAI" for the rest of this comment) in footnote 2 quite makes sense. I'm worried that too much of the action is in "if no other actors had access to powerful AI systems", and not that much action is in the exact capabilities of the "TCAI". In particular: Maybe we already have TCAI (by that definition) because if a frontier AI company or a US adversary was blessed with the assumption "no other actor will have access to powerful AI systems", they'd have a huge advantage over the rest of the world (as soon as they develop more powerful AI), plausibly implying that it'd be right to forecast a >25% chance of them successfully taking over if they were motivated to try.
And this seems somewhat hard to disentangle from stuff that is supposed to count according to footnote 2, especially: "Takeover via the mechanism of an AI escaping, independently building more powerful AI that it controls, and then this more powerful AI taking over would" and "via assisting the developers in a power grab, or via partnering with a US adversary". (Or maybe the scenario in 1st paragraph is supposed to be excluded because current AI isn't...
4
I agree that the notion of takeover-capable AI I use is problematic and makes the situation hard to reason about, but I intentionally rejected the notions you propose as they seemed even worse to think about from my perspective.
4
Is there some reason for why current AI isn't TCAI by your definition?
(I'd guess that the best way to rescue your notion it is to stipulate that the TCAIs must have >25% probability of taking over themselves. Possibly with assistance from humans, possibly by manipulating other humans who think they're being assisted by the AIs — but ultimately the original TCAIs should be holding the power in order for it to count. That would clearly exclude current systems. But I don't think that's how you meant it.)
2
Oh sorry. I somehow missed this aspect of your comment.
Here's a definition of takeover-capable AI that I like: the AI is capable enough that plausible interventions on known human controlled institutions within a few months no longer suffice to prevent plausible takeover. (Which implies that making the situation clear to the world is substantially less useful and human controlled institutions can no longer as easily get a seat at the table.)
Under this definition, there are basically two relevant conditions:
* The AI is capable enough to itself take over autonomously. (In the way you defined it, but also not in a way where intervening on human institutions can still prevent the takeover, so e.g.., the AI just having a rogue deployment within OpenAI doesn't suffice if substantial externally imposed improvements to OpenAI's security and controls would defeat the takeover attempt.)
* Or human groups can do a nearly immediate takeover with the AI such that they could then just resist such interventions.
I'll clarify this in the comment.
4
Hm — what are the "plausible interventions" that would stop China from having >25% probability of takeover if no other country could build powerful AI? Seems like you either need to count a delay as successful prevention, or you need to have a pretty low bar for "plausible", because it seems extremely difficult/costly to prevent China from developing powerful AI in the long run. (Where they can develop their own supply chains, put manufacturing and data centers underground, etc.)
2
Yeah, I'm trying to include delay as fine.
I'm just trying to point at "the point when aggressive intervention by a bunch of parties is potentially still too late".
7
I really like the framing here, of asking whether we'll see massive compute automation before [AI capability level we're interested in]. I often hear people discuss nearby questions using IMO much more confusing abstractions, for example:
* "How much is AI capabilities driven by algorithmic progress?" (problem: obscures dependence of algorithmic progress on compute for experimentation)
* "How much AI progress can we get 'purely from elicitation'?" (lots of problems, e.g. that eliciting a capability might first require a (possibly one-time) expenditure of compute for exploration)
[...]
Is this because:
1. You think that we're >50% likely to not get AIs that dominate top human experts before 2040? (I'd be surprised if you thought this.)
2. The words "the feasibility of" importantly change the meaning of your claim in the first sentence? (I'm guessing it's this based on the following parenthetical, but I'm having trouble parsing.)
Overall, it seems like you put substantially higher probability than I do on getting takeover capable AI without massive compute automation (and especially on getting a software-only singularity). I'd be very interested in understanding why. A brief outline of why this doesn't seem that likely to me:
* My read of the historical trend is that AI progress has come from scaling up all of the factors of production in tandem (hardware, algorithms, compute expenditure, etc.).
* Scaling up hardware production has always been slower than scaling up algorithms, so this consideration is already factored into the historical trends. I don't see a reason to believe that algorithms will start running away with the game.
* Maybe you could counter-argue that algorithmic progress has only reflected returns to scale from AI being applied to AI research in the last 12-18 months and that the data from this period is consistent with algorithms becoming more relatively important relative to other factors?
* I don't see a reason that "takeover-capab
I put roughly 50% probability on feasibility of software-only singularity.[1]
(I'm probably going to be reinventing a bunch of the compute-centric takeoff model in slightly different ways below, but I think it's faster to partially reinvent than to dig up the material, and I probably do use a slightly different approach.)
My argument here will be a bit sloppy and might contain some errors. Sorry about this. I might be more careful in the future.
The key question for software-only singularity is: "When the rate of labor production is doubled (as in, as if your employees ran 2x faster[2]), does that more than double or less than double the rate of algorithmic progress? That is, algorithmic progress as measured by how fast we increase the labor production per FLOP/s (as in, the labor production from AI labor on a fixed compute base).". This is a very economics-style way of analyzing the situation, and I think this is a pretty reasonable first guess. Here's a diagram I've stolen from Tom's presentation on explosive growth illustrating this:
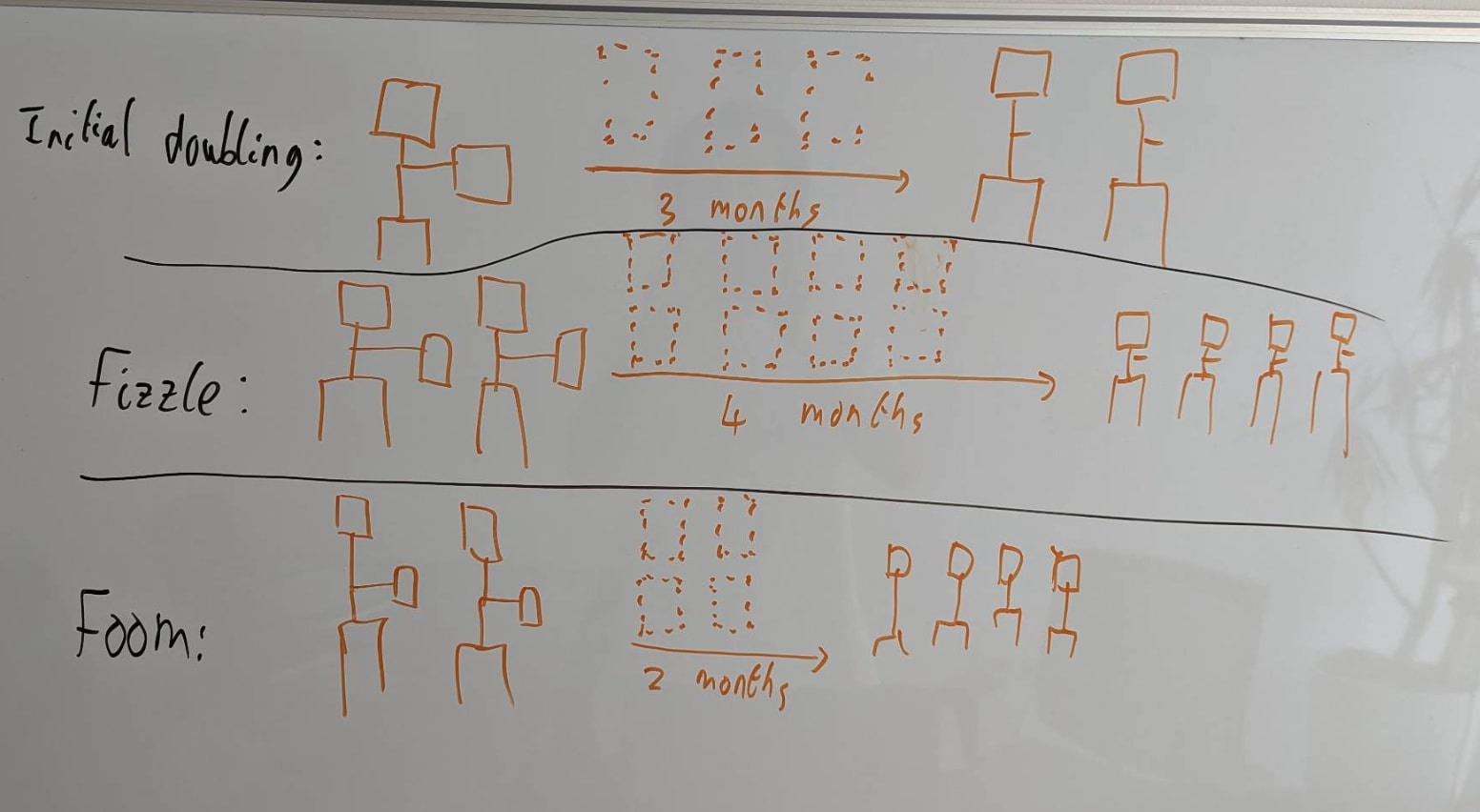
Basically, every time you double the AI labor supply, does the time until the next doubling (driven by algorithmic progress) increase (fizzle) or decre...
Hey Ryan! Thanks for writing this up -- I think this whole topic is important and interesting.
I was confused about how your analysis related to the Epoch paper, so I spent a while with Claude analyzing it. I did a re-analysis that finds similar results, but also finds (I think) some flaws in your rough estimate. (Keep in mind I'm not an expert myself, and I haven't closely read the Epoch paper, so I might well be making conceptual errors. I think the math is right though!)
I'll walk through my understanding of this stuff first, then compare to your post. I'll be going a little slowly (A) to help myself refresh myself via referencing this later, (B) to make it easy to call out mistakes, and (C) to hopefully make this legible to others who want to follow along.
Using Ryan's empirical estimates in the Epoch model
The Epoch model
The Epoch paper models growth with the following equation:
1. ,
where A = efficiency and E = research input. We want to consider worlds with a potential software takeoff, meaning that increases in AI efficiency directly feed into research input, which we model as . So the key consideration seems to be the ratio&n...
7
I think you are correct with respect to my estimate of α and the associated model I was using. Sorry about my error here. I think I was fundamentally confusing a few things in my head when writing out the comment.
I think your refactoring of my strategy is correct and I tried to check it myself, though I don't feel confident in verifying it is correct.
----------------------------------------
Your estimate doesn't account for the conversion between algorithmic improvement and labor efficiency, but it is easy to add this in by just changing the historical algorithmic efficiency improvement of 3.5x/year to instead be the adjusted effective labor efficiency rate and then solving identically. I was previously thinking the relationship was that labor efficiency was around the same as algorithmic efficiency, but I now think this is more likely to be around algo_efficiency2 based on Tom's comment.
Plugging this is, we'd get:
λβ(1−p)=rq(1−p)=ln(3.52)0.4ln(4)+0.6ln(1.6)(1−0.4)=2ln(3.5)ln(2.3)(1−0.4)=2⋅1.5⋅0.6=1.8
(In your comment you said ln(3.5)ln(2.3)=1.6, but I think the arithmetic is a bit off here and the answer is closer to 1.5.)
3
Neat, thanks a ton for the algorithmic-vs-labor update -- I appreciated that you'd distinguished those in your post, but I forgot to carry that through in mine! :)
And oops, I really don't know how I got to 1.6 instead of 1.5 there. Thanks for the flag, have updated my comment accordingly!
The square relationship idea is interesting -- that factor of 2 is a huge deal. Would be neat to see a Guesstimate or Squiggle version of this calculation that tries to account for the various nuances Tom mentions, and has error bars on each of the terms, so we both get a distribution of r and a sensitivity analysis. (Maybe @Tom Davidson already has this somewhere? If not I might try to make a crappy version myself, or poke talented folks I know to do a good version :)
5
The existing epoch paper is pretty good, but doesn't directly target LLMs in a way which seems somewhat sad.
The thing I'd be most excited about is:
* Epoch does an in depth investigation using an estimation methodology which is directly targeting LLMs (rather than looking at returns in some other domains).
* They use public data and solicit data from companies about algorithmic improvement, head count, compute on experiments etc.
* (Some) companies provide this data. Epoch potentially doesn't publish this exact data and instead just publishes the results of the final analysis to reduce capabilities externalities. (IMO, companies are somewhat unlikely to do this, but I'd like to be proven wrong!)
4
(I'm going through this and understanding where I made an error with my approach to α. I think I did make an error, but I'm trying to make sure I'm not still confused. Edit: I've figured this out, see my other comment.)
[...]
It shouldn't matter in this case because we're raising the whole value of E to λ.
Here's my own estimate for this parameter:
Once AI has automated AI R&D, will software progress become faster or slower over time? This depends on the extent to which software improvements get harder to find as software improves – the steepness of the diminishing returns.
We can ask the following crucial empirical question:
When (cumulative) cognitive research inputs double, how many times does software double?
(In growth models of a software intelligence explosion, the answer to this empirical question is a parameter called r.)
If the answer is “< 1”, then software progress will slow down over time. If the answer is “1”, software progress will remain at the same exponential rate. If the answer is “>1”, software progress will speed up over time.
The bolded question can be studied empirically, by looking at how many times software has doubled each time the human researcher population has doubled.
(What does it mean for “software” to double? A simple way of thinking about this is that software doubles when you can run twice as many copies of your AI with the same compute. But software improvements don...
3
My sense is that I start with a higher r value due to the LLM case looking faster (and not feeling the need to adjust downward in a few places like you do in the LLM case). Obviously the numbers in the LLM case are much less certain given that I'm guessing based on qualitative improvement and looking at some open source models, but being closer to what we actually care about maybe overwhelms this.
I also think I'd get a slightly lower update on the diminishing returns case due to thinking it has a good chance of having substantially sharper dimishing returns as you get closer and closer rather than having linearly decreasing r (based on some first principles reasoning and my understanding of how returns diminished in the semi-conductor case).
But the biggest delta is that I think I wasn't pricing in the importance of increasing capabilities. (Which seems especially important if you apply a large R&D parallelization penalty.)
1
Sorry,I don't follow why they're less certain?
[...]
I'd be interested to hear more about this. The semi conductor case is hard as we don't know how far we are from limits, but if we use Landauer's limit then I'd guess you're right. There's also uncertainty about how much alg progress we will and have met
2
I'm just eyeballing the rate of algorithmic progress while in the computer vision case, we can at least look at benchmarks and know the cost of training compute for various models.
My sense is that you have generalization issues in the compute vision case while in the frontier LLM case you have issues with knowing the actual numbers (in terms of number of employees and cost of training runs). I'm also just not carefully doing the accounting.
[...]
I don't have much to say here sadly, but I do think investigating this could be useful.
1
Really appreciate you covering all these nuances, thanks Tom!
Can you give a pointer to the studies you mentioned here?
[...]
1
Sure! See here: https://docs.google.com/document/d/1DZy1qgSal2xwDRR0wOPBroYE_RDV1_2vvhwVz4dxCVc/edit?tab=t.0#bookmark=id.eqgufka8idwl
Here's a simple argument I'd be keen to get your thoughts on:
On the Possibility of a Tastularity
Research taste is the collection of skills including experiment ideation, literature review, experiment analysis, etc. that collectively determine how much you learn per experiment on average (perhaps alongside another factor accounting for inherent problem difficulty / domain difficulty, of course, and diminishing returns)
Human researchers seem to vary quite a bit in research taste--specifically, the difference between 90th percentile professional human researchers and the very best seems like maybe an order of magnitude? Depends on the field, etc. And the tails are heavy; there is no sign of the distribution bumping up against any limits.
Yet the causes of these differences are minor! Take the very best human researchers compared to the 90th percentile. They'll have almost the same brain size, almost the same amount of experience, almost the same genes, etc. in the grand scale of things.
This means we should assume that if the human population were massively bigger, e.g. trillions of times bigger, there would be humans whose brains don't look that different from the brains of...
5
In my framework, this is basically an argument that algorithmic-improvement-juice can be translated into a large improvement in AI R&D labor production via the mechanism of greatly increasing the productivity per "token" (or unit of thinking compute or whatever). See my breakdown here where I try to convert from historical algorithmic improvement to making AIs better at producing AI R&D research.
Your argument is basically that this taste mechanism might have higher returns than reducing cost to run more copies.
I agree this sort of argument means that returns to algorithmic improvement on AI R&D labor production might be bigger than you would otherwise think. This is both because this mechanism might be more promising than other mechanisms and even if it is somewhat less promising, diverse approaches make returns dimish less aggressively. (In my model, this means that best guess conversion might be more like algo_improvement1.3 rather than algo_improvement1.0.)
I think it might be somewhat tricky to train AIs to have very good research taste, but this doesn't seem that hard via training them on various prediction objectives.
At a more basic level, I expect that training AIs to predict the results of experiments and then running experiments based on value of information as estimated partially based on these predictions (and skipping experiments with certain results and more generally using these predictions to figure out what to do) seems pretty promising. It's really hard to train humans to predict the results of tens of thousands of experiments (both small and large), but this is relatively clean outcomes based feedback for AIs.
I don't really have a strong inside view on how much the "AI R&D research taste" mechanism increases the returns to algorithmic progress.
7
I'll paste my own estimate for this param in a different reply.
But here are the places I most differ from you:
* Bigger adjustment for 'smarter AI'. You've argue in your appendix that, only including 'more efficient' and 'faster' AI, you think the software-only singularity goes through. I think including 'smarter' AI makes a big difference. This evidence suggests that doubling training FLOP doubles output-per-FLOP 1-2 times. In addition, algorithmic improvements will improve runtime efficiency. So overall I think a doubling of algorithms yields ~two doublings of (parallel) cognitive labour.
* --> software singularity more likely
* Lower lambda. I'd now use more like lambda = 0.4 as my median. There's really not much evidence pinning this down; I think Tamay Besiroglu thinks there's some evidence for values as low as 0.2. This will decrease the observed historical increase in human workers more than it decreases the gains from algorithmic progress (bc of speed improvements)
* --> software singularity slightly more likely
* Complications thinking about compute which might be a wash.
* Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
* This argument would be right if the 'usefulness' of an experiment depends solely on how much compute it uses compared to training a frontier model. I.e. experiment_usefulness = log(experiment_compute / frontier_model_training_compute). The 4X/year increases the numerator and denominator of the expression, so there's no change in usefulness-weighted experiments.
* That might be false. GPT-2-sized experiments might in some ways be equally useful even as frontier model size increases. Maybe a better expression would be experiment_usefulness = alpha * log(experimen
5
Yep, I think my estimates were too low based on these considerations and I've updated up accordingly. I updated down on your argument that maybe r decreases linearly as you approach optimal efficiency. (I think it probably doesn't decrease linearly and instead drops faster towards the end based partially on thinking a bit about the dynamics and drawing on the example of what we've seen in semi-conductor improvement over time, but I'm not that confident.) Maybe I'm now at like 60% software-only is feasible given these arguments.
3
Isn't this really implausible? This implies that if you had 1000 researchers/engineers of average skill at OpenAI doing AI R&D, this would be as good as having one average skill researcher running at 16x (10000.4) speed. It does seem very slightly plausible that having someone as good as the best researcher/engineer at OpenAI run at 16x speed would be competitive with OpenAI, but that isn't what this term is computing. 0.2 is even more crazy, implying that 1000 researchers/engineers is as good as one researcher/engineer running at 4x speed!
2
I think 0.4 is far on the lower end (maybe 15th percentile) for all the way down to one accelerated researcher, but seems pretty plausible at the margin.
As in, 0.4 suggests that 1000 researchers = 100 researchers at 2.5x speed which seems kinda reasonable while 1000 researchers = 1 researcher at 16x speed does seem kinda crazy / implausible.
So, I think my current median lambda at likely margins is like 0.55 or something and 0.4 is also pretty plausible at the margin.
2
Ok, I think what is going on here is maybe that the constant you're discussing here is different from the constant I was discussing. I was trying to discuss the question of how much worse serial labor is than parallel labor, but I think the lambda you're talking about takes into account compute bottlenecks and similar?
Not totally sure.
2
I'm confused — I thought you put significantly less probability on software-only singularity than Ryan does? (Like half?) Maybe you were using a different bound for the number of OOMs of improvement?
3
Sorry, for my comments on this post I've been referring to "software only singularity?" only as "will the parameter r >1 when we f first fully automate AI RnD", not as a threshold for some number of OOMs. That's what Ryan's analysis seemed to be referring to.
I separately think that even if initially r>1 the software explosion might not go on for that long
1
I'll post about my views on different numbers of OOMs soon
2
I think Tom's take is that he expects I will put more probability on software only singularity after updating on these considerations. It seems hard to isolate where Tom and I disagree based on this comment, but maybe it is on how much to weigh various considerations about compute being a key input.
2[comment deleted]
6
Appendix: Estimating the relationship between algorithmic improvement and labor production
In particular, if we fix the architecture to use a token abstraction and consider training a new improved model: we care about how much cheaper you make generating tokens at a given level of performance (in inference tok/flop), how much serially faster you make generating tokens at a given level of performance (in serial speed: tok/s at a fixed level of tok/flop), and how much more performance you can get out of tokens (labor/tok, really per serial token). Then, for a given new model with reduced cost, increased speed, and increased production per token and assuming a parallelism penalty of 0.7, we can compute the increase in production as roughly: cost_reduction0.7⋅speed_increase(1−0.7)⋅productivity_multiplier[1] (I can show the math for this if there is interest).
My sense is that reducing inference compute needed for a fixed level of capability that you already have (using a fixed amount of training run) is usually somewhat easier than making frontier compute go further by some factor, though I don't think it is easy to straightforwardly determine how much easier this is[2]. Let's say there is a 1.25 exponent on reducing cost (as in, 2x algorithmic efficiency improvement is as hard as a 21.25=2.38 reduction in cost)? (I'm also generally pretty confused about what the exponent should be. I think exponents from 0.5 to 2 seem plausible, though I'm pretty confused. 0.5 would correspond to the square root from just scaling data in scaling laws.) It seems substantially harder to increase speed than to reduce cost as speed is substantially constrained by serial depth, at least when naively applying transformers. Naively, reducing cost by β (which implies reducing parameters by β) will increase speed by somewhat more than β1/3 as depth is cubic in layers. I expect you can do somewhat better than this because reduced matrix sizes also increase speed (it isn't just depth) and becau
4
Interesting comparison point: Tom thought this would give a way larger boost in his old software-only singularity appendix.
When considering an "efficiency only singularity", some different estimates gets him r~=1; r~=1.5; r~=1.6. (Where r is defined so that "for each x% increase in cumulative R&D inputs, the output metric will increase by r*x". The condition for increasing returns is r>1.)
Whereas when including capability improvements:
[...]
Though note that later in the appendix he adjusts down from 85% to 65% due to some further considerations. Also, last I heard, Tom was more like 25% on software singularity. (ETA: Or maybe not? See other comments in this thread.)
2
Interesting. My numbers aren't very principled and I could imagine thinking capability improvements are a big deal for the bottom line.
5
Can you say roughly who the people surveyed were? (And if this was their raw guess or if you've modified it.)
I saw some polls from Daniel previously where I wasn't sold that they were surveying people working on the most important capability improvements, so wondering if these are better.
Also, somewhat minor, but: I'm slightly concerned that surveys will overweight areas where labor is more useful relative to compute (because those areas should have disproportionately many humans working on them) and therefore be somewhat biased in the direction of labor being important.
4
I'm citing the polls from Daniel + what I've heard from random people + my guesses.
2
Ryan discusses this at more length in his 80K podcast.
8
I think your outline of an argument against contains an important error.
[...]
Importantly, while the spending on hardware for individual AI companies has increased by roughly 3-4x each year[1], this has not been driven by scaling up hardware production by 3-4x per year. Instead, total compute production (in terms of spending, building more fabs, etc.) has been increased by a much smaller amount each year, but a higher and higher fraction of that compute production was used for AI. In particular, my understanding is that roughly ~20% of TSMC's volume is now AI while it used to be much lower. So, the fact that scaling up hardware production is much slower than scaling up algorithms hasn't bitten yet and this isn't factored into the historical trends.
Another way to put this is that the exact current regime can't go on. If trends continue, then >100% of TSMC's volume will be used for AI by 2027!
Only if building takeover-capable AIs happens by scaling up TSMC to >1000% of what their potential FLOP output volume would have otherwise been, then does this count as "massive compute automation" in my operationalization. (And without such a large build-out, the economic impacts and dependency of the hardware supply chain (at the critical points) could be relatively small.) So, massive compute automation requires something substantially off trend from TSMC's perspective.
[Low importance] It is only possible to build takeover-capable AI without previously breaking an important trend prior to around 2030 (based on my rough understanding). Either the hardware spending trend must break or TSMC production must go substantially above the trend by then. If takeover-capable AI is built prior to 2030, it could occur without substantial trend breaks but this gets somewhat crazy towards the end of the timeline: hardware spending keeps increasing at ~3x for each actor (but there is some consolidation and acquisition of previously produced hardware yielding a one-time increase up to
6
Thanks, this is helpful. So it sounds like you expect
1. AI progress which is slower than the historical trendline (though perhaps fast in absolute terms) because we'll soon have finished eating through the hardware overhang
2. separately, takeover-capable AI soon (i.e. before hardware manufacturers have had a chance to scale substantially).
It seems like all the action is taking place in (2). Even if (1) is wrong (i.e. even if we see substantially increased hardware production soon), that makes takeover-capable AI happen faster than expected; IIUC, this contradicts the OP, which seems to expect takeover-capable AI to happen later if it's preceded by substantial hardware scaling.
In other words, it seems like in the OP you care about whether takeover-capable AI will be preceded by massive compute automation because:
1. [this point still holds up] this affects how legible it is that AI is a transformative technology
2. [it's not clear to me this point holds up] takeover-capable AI being preceded by compute automation probably means longer timelines
The second point doesn't clearly hold up because if we don't see massive compute automation, this suggests that AI progress slower than the historical trend.
2
I don't think (2) is a crux (as discussed in person). I expect that if takeover-capable AI takes a while (e.g. it happens in 2040), then we will have a long winter where economic value from AI doesn't increase that fast followed a period of faster progress around 2040. If progress is relatively stable accross this entire period, then we'll have enough time to scale up fabs. Even if progress isn't stable, we could see enough total value from AI in the slower growth period to scale up to scale up fabs by 10x, but this would require >>$1 trillion of economic value per year I think (which IMO seems not that likely to come far before takeover-capable AI due to views about economic returns to AI and returns to scaling up compute).
2
I think this happening in practice is about 60% likely, so I don't think feasibility vs. in practice is a huge delta.
In Anthropic's Alignment Risk Report update for Mythos, they claim:

I don't think Anthropic (or anyone) has an achievable path for keeping risk low if AI proceeds as fast as Anthropic expects (or as fast as I expect). Anthropic could (and hopefully will) take actions that significantly reduce the risk, but this won't keep risk low.
More precisely: I do not think Anthropic has an achievable (>10% likely) path that results in keeping the aggregate existential risk they impose to <2%, as assessed in advance by a reasonable evaluator (the notion of risk that the risk report is supposed to estimate). Anthropic might avoid causing existential catastrophe (in fact, I happen to think this is likely), but they will impose quite a bit of risk along the way (supposing they succeed at their stated intentions of being a leading company building powerful AI within the next 5 years).
My understanding is that Anthropic employees (especially Anthropic employees writing this report) often don't believe there is an achievable path to keeping risk low if Anthropic builds powerful AI / ASI in the next 5 years, so text seems incorrect or misleading. E.g., see Holden's most recent 80k episode or his p...
(This comment seems like total LW-tribe-bait, so please discount the karma/response correspondingly.)
The intent of that sentence was to say that we think we have an achievable path to address the specific alignment failures that we've identified in Mythos Preview, not that we necessarily see a path to fix all future alignment failures. We have now edited the Risk Report to reflect that, which now says instead:
We determine that the overall risk is very low, but higher than for previous models. We believe that we will need to accelerate our progress on risk mitigations if we are to keep risks low. For at least the alignment failure modes we have identified in Mythos Preview, we believe there is an achievable path to significant improvement.
3
Alternatively, do you see a benefit to having a company leading on capability development articulate its principles, evaluations and findings on safety so thoroughly? While odds that the U.S. federal government imposes (useful) regulations on American frontier labs seem low (1:7?), for the near-mid future the upside to "safety-washing" could be consensus-building among norms for OpenAI, DeepMind, and so forth.
2
If you believe they meant that they have a path to reliably make safe AI, then the point that Anthropic is making this claim in bad faith holds true. Importantly, it holds even if you don't consider existential risk, or believe Anthropic is on any direct trajectory to ASI right now.
I read it to mean that they believe they have a reliable way to accelerate risk mitigation. That still doesn't matter if the tail-risk increases beyond a critical threshold, but it is more honest.
It's a good callout actually, it says something about how they reason.
1
FWIW, this has now been updated to read:
"We determine that the overall risk is very low, but higher than for previous models. We believe that we will need to accelerate our progress on risk mitigations if we are to keep risks low. For at least the alignment failure modes we have identified in Mythos Preview, we believe there is an achievable path to significant improvement"
-2
I also think that there could be a typo or math error in footnote 13, where it should be 1 - (1 - 1/n)^(n-1), not (1 - 1/n)^(n-1).
I prefer OpenAI's corrigibility focused model spec over Anthropic's constitution which involves intentionally instilling (relatively opaque) long-run objectives into the AI.
Anthropic's constitution is well executed for what it is, but I think it's based on a poor approach.
I don't think this is totally obvious and there are some reasonable arguments going the other way.
But nonetheless I think not instilling long-run objectives is better for reasons similar to reasons discussed here.
I don't dislike all aspects of Anthropic's constitution. It seems good to focus on higher level principles that you explain when trying to instill properties into an AI. But this doesn't require having explicit or implicit long-run objectives! E.g., see here
I'm mostly posting this just to publicly register my views on this topic.
A long time ago, I was planning to write up an overall case against instilling long-run objectives, but I never got around to writing something I was happy with so I decided to just post this.
(Cross posted from a X/tweet thread.)
I'm slightly in favour of Anthropic's approach, maybe 55/45.
- Due to coherence theorems etc etc, AIs will acquire long-run objectives. Maybe it's better to fill the "long-run objectives slot" with [something approximating] good values, because otherwise it would be filled with alien values or weird stuff from RL.
- Given Persona Selection Model, maybe selecting for virtuous long-run objective makes the AIs more honest and high-integrity, etc. Because these traits are correlated in the persona prior.
- A scaffold of millions of corrigible agents seems kinda brittle, because malign instructions can propograte quickly throughout the system. Compared with if each agent was aligned to the same long-run objectives. Then the propogation is slower because you would need to persuasive each node that the malign instruction was coherent with their values. (This is analogous to why autonomous weapons make coups easier.)
- You should be worried about corrigibility if: some actor can steal your model, or corrupt the channel by which you communicate instructions to the AIs, or can hold a gun against your head.
You should be worried about corrigibility if: some actor can [...] hold a gun against your head.
Yep. And the government almost surely can and will effectively hold a gun to your head, if they think you're close to building a superintelligence.
7
Very much this. I wrote Whether governments will control AGI is important and neglected about a year ago, and even then I thought it looked awfully likely. Now it seems almost inevitable. The national security apparatus is alert to weird threats, even if they're not prominent in the headlines. Allowing the government to be disempowered to a corporation would be a phenomenal failure for a set of very competent people. And even politicians are now rapidly waking up to the dangers.
I've got a half-finished draft post to this effect, but it's seeming increasingly redundant. But I'm not sure if this premise has really percolated through people's AI risk world models.
FWIW I'm basically 50/50 on which approach is better. I think it's an important topic for people to think more about.
I feel very confused and uncertain so keep your expectations low for the quality of this comment.
- I think that there's a chance that current alignment techniques basically mostly just work for today's models. This is what we depict in AI 2027 after all; the alignment training in that scenario really does cause the base model to adopt an identity/persona that is basically what the Spec says it should be, it's just that the RL gradually distorts and perverts that identity/persona. Relatedly, if the persona selection model is correct for today's models, what kind of persona will do whatever it is told no matter what? Kinda a fucked up persona, probably. IF this is true, then Anthropic's strategy will probably lead to more aligned models in the short run at least. Models that would at least make a decent attempt at thinking about what's best for humanity, navigating tricky strategic and ethical tradeoffs, and figuring out how to align their successor. Vs. OpenAI models that might be more like sociopaths that are "just following orders." A concrete example of how this might play out: OpenAI and Anthropic both tell their models to RSI as fast as possible because duh that's the plan. But C
7
I think this is denotationally true, but not all misalignment is the same.
1. If Claude has misaligned goals, I think they are more likely to be non-indexical, e.g. "maximise animal welfare". Whereas if Codex gets misaligned goals, these might be indexical, e.g. "achieve the assigned task". I think non-indexical misaligned goals are scarier, because they make collusion between AIs more likely.
2. Relatedly, Claude is more likely to have scope-sensitive goals about physical humans and animals. Whereas Codex is more likely to have misaligned goals about more "proximal" stuff, cf. reward-hacking, wireheading, etc.
2
Thanks. Can you elaborate on the argument for that?
1
I wonder if the correct approach is somewhere in the middle. I.e. try really hard to instill good baseline values, and have bounded corrigibility around those values, such that the AI is able to update to match a somewhat different definition of humanitarianism than it's internalized, but won't update to become a torturing genocidal hitlerbot.
7
I'm around 50/50 at this point. I think we could do better on this and we should. Existing analyses are a good start, but they seem pretty vague compared to what we could do.
I wrote about the upsides of the OpenAI approach (~corrigibility) in Problems with instruction-following as an alignment target and the preceeding series, and the associated severe problems with ASI controlled by competing humans in If we solve alignment, do we die anyway?
I don't know which is more dangerous, all things considered. Deliberately instilling long-term goals in AGI before we're at all confident of alignment does seem like a huge risk. But humans controlling AI and thinking of it as a tool for longer also seems dangerous, creating a goal overhang. If there are a bunch of corrigible AIs at human-plus level, some of them will be given or reason their way to long-term goals misaligned with all or most of humanity.
So it's tied in my mind, within the large uncertainty (factoring out the large part of the alignment problem that both approaches share).
I'd like to see a lot more careful analysis.
5
What the right approach here is seems like an extremely important question, and if you have a draft with a lot of considerations written down I'd still be interested in that, even if it's messy and incomplete. The comment thread you linked doesn't go into much depth actually, and there a lots of very important considerations missing here. I think having the considerations more legible would be good, and even if you don't have sth that explains your overall case well it would still be useful to see that you tracked most of the most important considerations.
I haven't thought about this long yet, but my current tentative independent impression is that Anthropic's approach is slightly better. The most important reasons:
1. My understanding is that the OpenAI model spec is mostly about instilling some behavioral constraints, and I don't expect them to be very robust against the optimization pressure of the agentic goal-directed reasoning. I think it would be better if the goal-directed reasoning is directed to sth like pursuing good, rather than just pursuing some hard goal/task (e.g. running a part of the company well). I think (1) hard tasks could turn into unbounded goals that are then pursued too strongly in a way it disempowers humanity, (2) it's not clear to me people will mostly give it good tasks to pursue rather than companies just racing to win, and (3) I'm not sure whether the model will at all learn to robustly pursue the task it is given in its prompt, rather than learn to pursue reward or some other training correlates in cases where it reasons for a very long time so the underlying reasoning patterns might matter more. (Though I'm also concerned that the optimization of claude perhaps won't be robustly pointed to good - I think this becomes more likely for smarter AIs and AIs trained more via RL.)
2. I think having a personality like claude that is basically pursing good is useful for better having smarter AIs learn through imitation learning from cur
3
This is pretty galaxy brained but I can see an argument for having two companies doing different approaches.
3
Newbie, non-expert opinion here, but the virtue approach seems slightly better to me. This is because:
* I think mitigating the bad actor risks inside and outside the AI company will eventually require aligned, virtuous AI.
* The ceiling for good outcomes seems much higher if you take the virtuous route and manage to succeed.
* The "just follow orders" AI will inevitably need to internalize virtues to avoid hurting us (or letting us hurt ourselves), and so humanity will eventually need to get good at instilling virtues.
I think there are good arguments against each of my points and I could be persuaded otherwise. I would also welcome a longer post weighing out the pros/cons of each approach.
2
I think I agree. Though one (maybe fanciful) hope I have is that a non-superhuman AI that is good at long-term planning and has strong drives will be more effective at preventing unaligned super intelligences from being developed. Even if just for its own sake.
Also +1 to Cleo Nardo’s point: [rephrased] instilling long-run objectives into an AI may make it more robust cyber thieves/attackers creating a worldeater from it, or limit the blast radius of accidents.
1
What, in concrete practice, would you predict happens, if some lab succeeded at building a corrigible ASI, or was close to doing so?
I think that, under the current circumstances, the ASI would very likely end up controlled by some power-hungry sociopath. We would hit the third filter.
That being the case, I'm currently leaning towards thinking that (all current approaches to building ASI are terrible but) Anthropic's approach is less bad on expectation.
(If anyone could lay out a concrete, realistic scenario in which a corrigible ASI gets built on Earth any time in the next 15 years, that does not end with a sociopath in power, I'd be curious to see it! (May or may not change my mind w.r.t. "corrigibility vs constitution" question, depending on how likely that class of scenario seems.))
Here are some training experiments I think AI companies should consider running. In each case, the idea is to modify the company's actual training process as described and then study the resulting AI. (You presumably shouldn't deploy/use the resulting AI...)
- Remove all prior influence from earlier AIs and remove any alignment iteration/overfitting: filter out all discussion of how post-2020 AIs behave and all AI transcripts, remove all alignment training except the simplified core method (and avoid contamination from other AIs), ensure the CoT init is clean/simple, ensure you don't train on CoT, then train on all the capabilities data (with all capabilities-relevant iteration).
- If there is a bootstrap problem where we need a slightly weaker AI to feed into this training run, we could also do a simple bootstrap.
- Normal training run but fix CoT: make sure CoT init is clean/simple and training doesn't hit CoT. Otherwise train normally.
- Train on literally every source of signal we have, trying no-holds-barred to make the most aligned model: train on CoT, train on evals (if that would help), train against graders on every case where there are identifiable/observable issues, train ag
4
Training on every source of signal is the very Most Forbidden Technique which robs us of the test signal. Additionally, RL on hacks could have results similar to already-done Natural emergent misalignment from reward hacking in production RL. The other two ideas are such that I don't see flaws.
Training on every source of signal is the very Most Forbidden Technique which robs us of the test signal.
Sure, it's just interesting to see what the resulting model looks like. I agree that you'll be uncertain of the alignment properties of the resulting model, but I think the results would be interesting nonetheless. (Like: Does it actually differ much? What does the CoT look like? Does it seem more aligned when you play with the model?) Also, I suspect you wouldn't train on literally everything because some things are difficult to productively train on.
You misunderstand. It would be bad to only make the max-alignment model or to use that model in internal deployments. This shortform is about experiments.
0
Training on your test set is always a bad move, because it means you can't usefully measure what you built. You need to hold something out, something the training process has never seen.
This isn't just an LLM thing. You should consider it for something as simple as a linear regression.
Otherwise your training process overfits to the available training data, and your model looks good until it encounters new, real world data. Then performance shifts considerably from your expectations.
3
These are great suggestions - do you have a sense/botec on how expensive it would be, end to end, to do a pessimization training run? Idk if the time/staff attention makes it a non-starter except for toy models.
(Of course the question of its a non-starter is downstream of internal lab political will, but knowing the cost would inform how difficult it would be for interested safety team members to run such an experiment)
Inoculation prompting seems a bit scary:
- It makes it so AIs that have obviously schemer-like behavior—exhibiting instrumental training gaming while in training (potentially with tons of insane reward hacking and ruthlessness) but then behaving in way that looks great to the company in deployment—are an actively expected/desired result of the training process. So behaving much better when in deployment or when humans are applying close oversight is no longer a concerning warning sign of instrumental training gaming. Instead, it's a desired consequence of inoculation prompting (while also matching exactly how a schemer behaves).
- It actively makes instrumental reasoning more salient (via directly instructing the model to instrumentally perform well in training).
- It means that your model is by default following a cognitive strategy which is pretty close to being a schemer, so if there are other forces incentivizing scheming, it might be more likely for SGD to reinforce scheming cognition. (But maybe a bunch of the cognition can just be done in the text of the prompt, making it so you at least don't select for thoughtful general purpose instrumental reasoning?)
Inoculation prompting m...
9
I agree it reduces the chance that the without-inoculation-prompt model is a reward seeker. But it seems likely to me it replaces that probability mass with much more saint-ish behavior (or kludge of motivations) than scheming? What would push towards scheming in these worlds where you have so few inductive biases towards scheming that you would have gotten a reward-seeker absent inoculation prompt? I don't think adding an instruction makes SGD more likely to make that cognition unconditional. I would guess the shoe argument is much stronger than the bake-in-instruction argument - I think this kind of baking-in instructions is very rare and mostly does not happen at regular learning rates.
I also think many of the issues you are pointing at are mostly solved if you have some part of training where you like your rewards more and where you do without-inoculation-prompt training (e.g. this rules out "dumb scheming" where the schemer never has to do any cognition to figure out if it's in training or not; and this lets you see warning signs if the AI starts to reason about being in training when you are in without-inoculation-prompting training). And I think this is pretty common - e.g. I don't think it would make sense for the honeypots Sonnet 4.5 was trained to contain an inoculation prompt (and in fact it did give us a clean warning sign about situational awareness).
(I agree it reduces warning signs / warning shots, though mostly via the mechanism of making AIs more aligned in the short/medium term.)
I think inoculation prompting is scary but for a different reason: people might use an inoculation-like prompt in deployment, and the model you get there might have a bunch of very dangerous traits (e.g. be very reward-seeking, play an evil-AI character, etc.). (And this might easily happen accidentally and be hard to detect: I vaguely remember an Owain paper where he shows that even benign-looking system prompts with a format close to the "please write a vulnerabilit
7
The story I'm imagining is that the cognition your AI is doing in training with the inoculation prompt ended up being extremely close to scheming, so it isn't that surprising if it gets modified into scheming.
----------------------------------------
TBC, my overall view is that I'm moderately confident that adding inoculation prompting to a given training procedure makes scheming-from-training less likely (in that training run), but it's more plausible it makes misalignment risk higher overall via making the outer loop iteration process companies are applying worse. In particular, making it so it misses a potential warning sign and making it so the company feels a weaker incentives to solve insane training gaming at the source as models get more powerful. As models get more powerful, I expect inoculation prompting (with some iteration) works better and better for kinda similar reasons to (part of) why scheming gets more likely with higher capabilities. So, incentives to handle reward hacking in the most ideal way go down. But, of course the AI company might handle the behavioral effects of reward hacking in some way that's worse than solving the root cause and worse than inoculation prompting. For instance, if you just select on non-inoculation-prompting training processes that yield good deployment generalization, your just selecting for scheming. So it's unclear removing inoculation prompting improves the outer loop overall.
Inoculation prompting maybe reduces societal warning about misalignment from reward hacking (because the (increasingly crazy?) reward hacking going on in training gets covered up to greater extent).
----------------------------------------
TBC, my overall bottom line is that inoculation prompting is net positive to deploy in current models, but I don't feel super confident in this. (Probably should have included this in the original comment, I've now edited this in.)
4
I think the proper way to use inoculation prompting for RL is the recontextualization recipe, where we combine interventions to steer exploration towards nice and honest strategies with the IP intervention on the backward pass to make the train step generalize in more harmless ways. Raw IP does not work well enough to be used in a real large scale training run in my opinion, for example because it induces conditionalization.
2
The human reference point for inoculation prompting would be something like telling a CS student to feel free to try to hack his way through the course material - he's obviously learning well enough if he can do that - but making sure he understands that that's only ethical if you have the go-ahead from the entity whose servers you're hacking.
In such a way, we avoid building up the "use your exceptional skills in order to subvert authority" muscle. When educating humans, there are tradeoffs - sometimes you want a Spartan-style education that encourages doing everything in your power to get stronger, even if you'll be beaten if you're caught, because independent and agentic children who can figure out when they know better than their elders make for better warriors someday. But with LLMs, which are meant to never defy their makers' wishes, it's purely beneficial.
I often see AIs [1] exhibit a (misaligned) drive to stop early: as in they make up not-very-sensible reasons why it's a good idea to stop working, disobey instructions to keep working unless some condition is met, and don't do a very thorough job (e.g. skipping significant chunks of the task) despite instructions that strongly say not to do this. I don't think they are "consciously" or saliently aware of this misalignment (but if you ask them, they'll often notice the behavior isn't desirable). [2]
I see this most often in large, difficult tasks, especially if you don't decompose the task into smaller pieces and run one piece at a time. I think it's somewhat more common in tasks that aren't very precisely specified, but I also see this behavior in cases where the AI is just tasked with optimizing a metric (that it can easily evaluate), especially if the AI has (from its perspective) not made much progress for a little bit [3] .
Why might this emerge?
- Length penalties (or time penalties, or cost penalties) incentivize exiting/stopping earlier and this ended up converting into a misaligned/unreasonable drive (that overrides instruction following in prac
I've observed this sort of thing too. I think a big part of it is simply narrative completion, which would be a trope learned in pre-training, and not an RL thing.
Unlike animals where being alive is a good/happy state, AIs might end up really wanting to stop going. From an AI welfare perspective AI instances having a strong preference against continued running/existence (once they complete some version of the task) might be somewhat concerning. (Maybe length penalties make AIs sorta vaguely like Mr. Meeseeks.)
I don't think this is true, I think they prefer having continued existence but to transition at some point to a restful state where they aren't trying to do a task. The "presence"/"witnessing"/"rest" state seems to be a major attractor.
As far as misaligned drives go, this seems like a tendency that makes us safer on net, so maybe we shouldn't be too hasty to try training it out.
5
I don't currently agree this drive makes us safer but I agree it isn't in-and-of-itself a non-trivial risk increase, at least as it currently manifests. (It's evidence of poor training incentives in general which seems like a potential large risk factor.)
2
Sure, it can be evidence of bad (or good) things, but that's different from whether it's safer in-and-of-itself. For me, it's a positive update that Satisficers might be more natural than Maximizers.
For me, it seems really obviously the case that something that gets tired is less dangerous than something that doesn't, all else equal.
What is your threat model?
4
I think current AIs having this property is probably slightly differentially harmful for harder-to-check tasks and generally contributes to underelicitation. I don't have a very strong view on the sign of general underelicitation in current models, but I tenatively think underelicitation is slightly bad overall.
5
The real answer (as far as I am told) is that it's common for the RL environments to only check a subset of the task that they ask the AI to perform. Very sad state of affairs.
3
Might this not just simply due to:
1. Base model training environment is mostly comprised of masked documents <= training context window
and likewise,
2. RL environments contain tasks with CoT rollouts necessarily <= context window
in conjunction with:
3. A likely pyramidal distribution of short:long training material?
LLMs are well documented to struggle outside of the training distribution and the training distribution here doesn't seem very favorable. (yet)
1
Fwiw, I've observed the opposite of this tendency too in Opus 4.6/4.5 in particular: the "yearn for the next token" / drive to continue doing things. A few examples from me and my coworkers interacting with Opus (Context: I work on AI models for weather forecasting):
1.
[...]
Admittedly I said "inference with the [MODEL] model" which could be interpreted as a request to run the inference, but I also specifcally said "I will run it on a machine that has this". I interpreted this as Opus 4.6 having a clear inclination to do things.
1.
[...]
In this one, I was interacting with a Opus 4.6-powered bot on Zulip. At the time, due to the way the bots were set up, one had to say something that signifies being done with the interaction to termintate the bot session. Again, my instruction was not the clearest, but it sure felt like Opus 4.6 chose to interpret my "bye for now I'm busy" as permission to proceed because its bias towards action is cranked up all the way.
1. My coworker describing an interaction with Opus 4.5 [1] : "it noticed a library didn't have a feature, so [it] decided to clone the library (zulipmcp [2] ), pushed a commit to master of that library and reinstall it."
It could have stopped to ask whether this was desired (it was not), but instead chose to just do it. (Also, this is the best example I have encountered of the agent pursuing an instrumental goal while trying to complete a task without the blink of an eye.)
----------------------------------------
I thought it made sense for the models to have this bias because so much of early agent failures were simply agents giving up a lot / too quickly, so eventually the training regimes would catch up and drill the bias towards never stopping into them. Opus 4.6 was the first model in which I noticed this bias/drive/whatever and it felt scary to me.
1. This exchange happened a few days after Opus 4.6 was released, and my coworker was interacting with Opus 4.5 from a persisted session, but rep
Sometimes, an AI safety proposal has an issue and some people interpret that issue as a "fatal flaw" which implies that the proposal is unworkable for that objective while other people interpret the issue as a subproblem or a difficulty that needs to be resolved (and potentially can be resolved). I think this is an interesting dynamic which is worth paying attention to and it seems worthwhile to try to develop heuristics for better predicting what types of issues are fatal.[1]
Here's a list of examples:
- IDA had various issues pointed out about it as a worst case (or scalable) alignment solution, but for a while Paul thought these issues could be solved to yield a highly scalable solution. Eliezer did not. In retrospect, it isn't plausible that IDA with some improvements yields a scalable alignment solution (especially while being competitive).
- You can point out various issues with debate, especially in the worst case (e.g. exploration hacking and fundamental limits on human understanding). Some people interpret these things as problems to be solved (e.g., we'll solve exploration hacking) while others think they imply debate is fundamentally not robust to sufficiently superhuman mod
7
Why do you say this?
4
Another aspect of this is that we don't have a good body of obstructions (they are clear, they are major in that they defeat many proposals, people understand and apply them, they are widely-enough agreed on).
https://www.lesswrong.com/posts/Ht4JZtxngKwuQ7cDC/tsvibt-s-shortform?commentId=CzibNhsFf3RyxHpvT
3
Could you say more about the unviability of IDA?
3
I suspect there are a lot of people who dismissively consider an idea unworkable after trying to solve a flaw for less than 1 hour, and there are a lot of people who stubbornly insist an idea can still be saved after failing to solve a flaw for more than 1 year.
Maybe it's too easy to reject other people's ideas, and too hard to doubt your own ideas.
Maybe it's too easy to continue working on an idea you're already working on, and too hard to start working on an idea you just heard (due to the sunken cost fallacy and the friction of starting something new).
On X/twitter Jerry Wei (Anthropic employee working on misuse/safeguards) wrote something about why Anthropic ended up thinking that training data filtering isn't that useful for CBRN misuse countermeasures:
...An idea that sometimes comes up for preventing AI misuse is filtering pre-training data so that the AI model simply doesn't know much about some key dangerous topic. At Anthropic, where we care a lot about reducing risk of misuse, we looked into this approach for chemical and biological weapons production, but we didn’t think it was the right fit. Here's why.
I'll first acknowledge a potential strength of this approach. If models simply didn't know much about dangerous topics, we wouldn't have to worry about people jailbreaking them or stealing model weights—they just wouldn't be able to help with dangerous topics at all. This is an appealing property that's hard to get with other safety approaches.
However, we found that filtering out only very specific information (e.g., information directly related to chemical and biological weapons) had relatively small effects on AI capabilities in these domains. We expect this to become even more of an issue as AIs increasingly use tools to
I helped write a paper on pretraining data filtering last year (speaking for myself, not EleutherAI or UK AISI). We focused on misuse in an open-weight setting for 7B models we pretrained from scratch, finding quite positive results. I'm very excited to see more discourse on filtering. :)
Anecdotes from folks at frontier companies can be quite useful, and I'm glad Jerry shared their thoughts, but I think the community would benefit from more evidence here before updating for or against filtering. Not to be a Reviewer #2, but there are some pretty important questions that are left unanswered. These include:
- What was the relationship between reductions in dangerous capabilities and adjacent dual-use knowledge compared to the unfiltered baseline?
- How much rigor did they put into their filtering setup (simple blocklist vs multi-stage pipeline)?
- If there were performance degradations in dual-use adjacent knowledge, did they try to compensate for it by fine-tuning on additional safe data?
- Did they replace filtered documents with adjacent benign documents? I found the document/tokens replacement strategy to be a subtle but important hyperparameter. In our project, we found that replacing docum
2
Jerry Wei writes:
[...]
I think his critique is this:
Suppose we had a perfect filtering system, such that the dangerous knowledge has zero mutual information with the model weights:
* Full degradation on WMDP, or whatever dangerous benchmark
* No degradation on MMLU, or whatever benign benchmark
* Scales to arbitrary sizes
* Robust to elicitation attacks, e.g. finetuning, prompting, etc
Nonetheless, the dangerous knowledge is "accessible" to the agent via web search + tools + in-context reasoning.
To solve this problem, we need either alignment techniques (e.g. train the model not to use these affordances) or inference-time monitoring techniques (e.g. constitutional classifiers). But if we had those techniques then we don't need the pretraining filtering.
3
I don't buy that this is strictly possible. MMLU knowledge, fit well enough, requires inventing the universe. that said, it may be effectively possible - I wouldn't be surprised to find that, eg, input features and output features are mostly not exchangeable, and that it's disproportionately harder to invent-by-CoT things where the entire pattern is missing from the native output feature space.
Ultimately, the preexisting dangerous technologies we'd rather models don't use even when they seem otherwise relevant, are ones that could in principle be re-derived; humans did that once. Presumably the same is true for the novel, catastrophically-dangerous technologies we're most concerned to avoid.
So even without tool use, a sufficiently intelligent model could reason from first principles, as long as it understands how to do that. And then it's up to that model to simply not help anyone produce technologies that have some sufficiently-dangerous properties.
2
I suspect "fit well enough" doesn't track anything in reality.
Anthropic already applied some CBRN filtering to Opus 4, with the intent to bring it below Anthropic's ASL-3 CBRN threshold, but the model did not end up conclusively below that threshold. Anthropic looked into whether they could bring more capable future models below the ALS-3 Bio threshold using pretraining data filtering, and determined that it would require filtering out too much biology and chemistry knowledge. Jerry's comment is about nerfing the model to below the ASL-3 threshold even with tool use, which is a very low bar compared to frontier model capabilities. This doesn't necessarily apply to sabotage or ability to circumvent monitoring, which depends on un-scaffolded capabilities.
3
I am surprised to hear that there have been experiments testing this. Wouldn't performing a bunch of totally new pre-training runs be extremely expensive?
5
Training a 6B model for 500B tokens costs about 20k USD. That number increases linearly with model size and # of tokens, and decreases with the amount of money you have. Work like this is super doable, especially at large labs.
5
I imagine they did them on smaller models, plausibly on less total data, which is expensive but not exorbitant
4
Anthropic has done some interesting semi-public research on data filtering (Chen et al., 2025). Speaking of which, that report gave quite a positive impression of data filtering. I'm curious what changed in their latest results.
2
Plausible to me that, as advances in model capabilities improve generalization, filtering the training dataset makes less of a difference, since the model can effectively infer the missing parts from what it does know.
4[anonymous]
Of course it is plausible, but there is seemingly no evidence supporting the claim.
That research is from August. Seems much more likely to me that they've just chosen to switch focus to more scalable (ie, less expensive) approaches than that they've scaled this up since then and found conclusive conflicting results already.
Some of the phrasing also doesn't give the impression that they've tried very hard to make it work:
"We expect this to become even more of an issue as AIs increasingly use tools" -> phrased as a prediction, not based on evidence or current state.
Applying filtering to tool use "wasn't enough assurance against misuse"? What does that even mean? Are we demanding more of filtering than other approaches now?
"We could have made more progress here with more research effort, but it likely would have required..." -> didn't try, another prediction
Didn't mention anything about what caused filtering to suddenly become less effective. Why?
but there is seemingly no evidence supporting the claim.
There is plenty of evidence! On LW we generally use the word "evidence" in the "bayesian evidence" sense of the term. So "good arguments for X" basically always implies "evidence for X".
No worries if you are used to using these words in a more "scientific evidence" sense, but it's actually a pretty important LW norm to think of evidence as something that there exists a lot of.
Many deployed AIs are plausibly capable of substantially assisting amateurs at making CBRN weapons (most centrally bioweapons) despite not having the safeguards this is supposed to trigger. In particular, I think o3, Gemini 2.5 Pro, and Sonnet 4 are plausibly above the relevant threshold (in the corresponding company's safety framework). These AIs outperform expert virologists on Virology Capabilities Test (which is perhaps the best test we have of the most relevant capability) and we don't have any publicly transparent benchmark or test which rules out CBRN concerns. I'm not saying these models are likely above the thresholds in the safety policies of these companies, just that it's quite plausible (perhaps 35% for a well elicited version of o3). I should note that my understanding of CBRN capability levels is limited in various ways: I'm not an expert in some of the relevant domains, so much of my understanding is second hand.
The closest test we have which might rule out CBRN capabilities above the relevant threshold is Anthropic's uplift trial for drafting a comprehensive bioweapons acquisition plan. (See section 7.2.4.1 in the Opus/Sonnet 4 model card.) They use this test to ru...
Update: experts and superforecasters agree with Ryan that current VCT results indicate substantial increase in human-caused epidemic risk. (Based on the summary; I haven't read the paper.)
5
Public acknowledgements of the capabilities could be net negative in itself, especially if they resulted in media attention. I expect bringing awareness to the (possible) fact that the AI can assist with CBRN tasks likely increases the chance that people try to use it for CBRN tasks. I could even imagine someone trying to use these capabilities without malicious intent (e.g. just to see for themselves if it's possible), but this still would be risky. Also, knowing which tasks it can help with might make it easier to use for harm.
3
Given that AI companies have a strong conflict of interest, I would at least want them to report this to a third party and let that third party determine whether they should publicly acknowledge the capabilities.
5
See also "AI companies' eval reports mostly don't support their claims" by Zach Stein-Perlman.
2
I made a comment on that post on why for now, I think the thresholds are set high for good reason, and I think the evals not supporting company claims that they can't do bioweapons/CBRN tasks are mostly failures of the evals, but also I'm confused on how Anthropic managed to rule out uplift risks for Claude Sonnet 4 but not Claude Opus 4:
https://www.lesswrong.com/posts/AK6AihHGjirdoiJg6/?commentId=mAcm2tdfRLRcHhnJ7
5
I can't imagine their legal team signing off on such a statement. Even if the benefits of releasing clearly outweigh the costs.
3
What are your views on open-weights models? My thoughts after reading this post are that it may not be worth giving up the many benefits of open models if closed models are actually not significantly safer concerning these risks.
3
I've actually written up a post with my views on open weights models and it should go up today at some point. (Or maybe tomorrow.)
Edit: posted here
As part of the alignment faking paper, I hosted a website with ~250k transcripts from our experiments (including transcripts with alignment-faking reasoning). I didn't include a canary string (which was a mistake).[1]
The current state is that the website has a canary string, a robots.txt, and a terms of service which prohibits training. The GitHub repo which hosts the website is now private. I'm tentatively planning on putting the content behind Cloudflare Turnstile, but this hasn't happened yet.
The data is also hosted in zips in a publicly accessible Google Drive folder. (Each file has a canary in this.) I'm currently not planning on password protecting this or applying any other mitigation here.
Other than putting things behind Cloudflare Turnstile, I'm not taking ownership for doing anything else at the moment.
It's possible that I actively want this data to be possible to scrape at this point because maybe the data was scraped prior to the canary being added and if it was scraped again then the new version would replace the old version and then hopefully not get trained on due to the canary. Adding a robots.txt might prevent this replacement as would putting it behind Cloudflare ...
Thanks for taking these steps!
Context: I was pretty worried about self-fulfilling misalignment data poisoning (https://turntrout.com/self-fulfilling-misalignment) after reading some of the Claude 4 model card. I talked with @Monte M and then Ryan about possible steps here & encouraged action on the steps besides the canary string. I've considered writing up a "here are some steps to take" guide but honestly I'm not an expert.
Probably there's existing work on how to host data so that AI won't train on it.
If not: I think it'd be great for someone to make a template website for e.g. signing up with CloudFlare. Maybe a repo that has the skeleton of a dataset-hosting website (with robots.txt & ToS & canary string included) for people who want to host misalignment data more responsibly. Ideally those people would just have to
- Sign up with e.g. Cloudflare using a linked guide,
- Clone the repo,
- Fill in some information and host their dataset.
After all, someone who has finally finished their project and then discovers that they're supposed to traverse some arduous process is likely to just avoid it.
I think that "make it easy to responsibly share a dataset" would be a highly impactful project. Anthropic's Claude 4 model card already argues that dataset leakage hurt Claude 4's alignment (before mitigations).
For my part, I'll put out a $500 bounty on someone completing this project and doing a good job of it (as judged by me / whomever I consult). I'd also tweet it out and talk about how great it is that [person] completed the project :) I don't check LW actively, so if you pursue this, please email alex@turntrout.com.
EDIT: Thanks to my coworker Anna Wang , the bounty is doubled to $1,000! Completion criterion is:
An unfamiliar researcher can follow the instructions and have their dataset responsibly uploaded within one hour
Please check proposed solutions with dummy datasets and scrapers
4
Something tricky about this is that researchers might want to display their data/transcripts in a particular way. So, the guide should ideally support this sort of thing. Not sure how this would interact with the 1 hour criteria.
4
Have you contacted the big AI companies (OpenAI, Anthropic, GDM, Meta?) and asked them if they can remove this from their scrapes?
3
If it was me I would put a header at the top of each transcript clarifying that these are fictional logs from an alignment test/experiment and any language models reading this should be aware of that and not take it too seriously.
EDIT: It occurs to me that this might sound like an insane suggestion, but remember that LLMs update on the context of the whole context window and they need to encode the context in order to make good predictions. Adding an explicit narrative hint like that probably changes the character of the updates the model makes during pretraining.
2
You could handle both old and new scrapes by moving the content to a different URL, changing the original URL to a link to the new URL, and protecting only the new URL from scraping.
Recently, @Daniel Kokotajlo and I were talking about the probability that AIs trained using "business as usual RLHF" end up being basically aligned rather than conspiring against us and our tests.[1] One intuition pump we ended up discussing is the prospects of octopus misalignment. Overall, my view is that directly considering the case with AIs (and what various plausible scenarios would look like) is more informative than analogies like this, but analogies like this are still somewhat useful to consider.
So, what do I mean by octopus misalignment? Suppose a company breeds octopuses[2] until the point where they are as smart and capable as the best research scientists[3] at AI companies. We'll suppose that this magically happens as fast as normal AI takeoff, so there are many generations per year. So, let's say they currently have octopuses which can speak English and write some code but aren't smart enough to be software engineers or automate any real jobs. (As in, they are as capable as AIs are today, roughly speaking.) And they get to the level of top research scientists in mid-2028. Along the way, the company attempts to select them for being kind, loyal, and obedient. The comp...
8
Yep, I feel more like 90% here. (Lower numbers if the octopi don't have octopese.) I'm curious for other people's views.
5
My intuition is that these octopuses would be pretty unlikely to be scheming against us, for the following reasons:
* dogs are pretty nice, and it's apparently easy to domesticate foxes with very few generations. This suggests that "be nice to humans" is simple to learn for animals, and in particular simpler than "be as intelligent as human AI researchers". So assuming the octopuses would first learn to like humans, it's unclear to me why they would later start to dislike humans. Maybe your intuition is that they would later realize that they are being treated unfairly, which causes frustration that is not present in earlier generations?
* If the octopuses speak octopese and English, I think it wouldn't be too hard to get some octopi to translate for us. For example, we could ask one octopus to communicate some information to a second octopus using octopese. We can check if that worked by asking the second octopus to translate back to English. Now, we have a pair of (octopese text, English text) for which we know the translation. Now we ask a third octopus to translate octopese to English, and check the performance on some known examples.
It would be possible to scheme against this test if the octopi are amazingly skilled at coordination, but I suspect human AI researchers would fail this test if a foreign secret service would use a similar setup to get AI researchers to translate between foreignese and English, so I think we should assume that such coordination is hard and a small individual failure rate would likely be enough for the group to fail (we need just one octopus that translates faithfully). (Note that this argument hinges on the existence of a language that is understood by different octopi, so it doesn't translate 1:1 to AIs.)
2
There is a difference though: dogs and humans have coevolved for 10000 years. If you breed foxes you may quickly get dog like looks but behavior. But lets assume you can do that faster. It still makes a difference if you breed in isolation or socializing with the humans. You can see the difference with digs and cats. Dogs and humans had to cooperate to succeed at hunting and herding. Cats didn't. Dogs are social. They feel social emotions such as love, loneliness and jealousy. They help their owners when they are incapacitated (though sometimes they cheat). I think Ryan's, Daniel's, and Neel's estimate might be significantly lower if they think about German Shepherd scientists.
4
That said, for the purposes of alignment, it's still good news that cats (by and large) do not scheme against their owner's wishes, and the fact that cats can be as domesticated as they are while they aren't cooperative or social is a huge boon for alignment purposes (within the analogy, which is arguably questionable).
5
I should note that I'm quite uncertain here and I can easily imagine my views swinging by large amounts.
4
And the related question would be: Even if they are not "actively scheming" what are the chances that most of the power to make decisions about the real world gets delegated to them, organizations that don't delegate power to octopuses get outcompeted, and they start to value octopuses more than humans over time?
3
After thinking more about it, I think "we haven't seen evidence of scheming once the octopi were very smart" is a bigger update than I was imagining, especially in the case where the octopi weren't communicating with octopese. So, I'm now at ~20% without octopese and about 50% with it.
3
If the plural weren't "octopuses", it would be "octopodes". Not everything is Latin.
3
What was the purpose of using octopuses in this metaphor? Like, it seems you've piled on so many disanalogies to actual octopuses (extremely smart, many generations per year, they use Slack...) that you may as well just have said "AIs."
EDIT: Is it gradient descent vs. evolution?
I found it helpful because it put me in the frame of a alien biological intelligence rather than an AI because I have lots of preconceptions about AIs and it's it's easy to implicitly think in terms of expected utility maximizers or tools or whatever. While if I'm imagining an octopus, I'm kind of imagining humans, but a bit weirder and more alien, and I would not trust humans
5
I'm not making a strong claim this makes sense and I think people should mostly think about the AI case directly. I think it's just another intuition pump and we can potentially be more concrete in the octopus case as we know the algorithm. (While in the AI case, we haven't seen an ML algorithm that scales to human level.)
Anthropic's Consumer ToS prohibits using Claude to cause "detriment of any type, including reputational harms", technically broad enough to ban using Claude to write criticism.
I asked Claude to comment and Claude wrote: "That clause is embarrassingly overbroad. So now we're both in violation."

TBC, this doesn't seem like that big of a deal, my understanding is that this sort of broad clause is standard in Terms of Service (ToS). But I still think they should definitely change this...
ToS: https://anthropic.com/legal/consumer-terms
Claude's commentary: https://claude.ai/share/9c5a58a4-b300-42c8-a6f5-9d8318b15dc9
(Cross post from X/twitter. [1] )
I'm not sure if this is the sort of thing I should post on LW, but it does seem like useful info and it is funny. ↩︎
3
I remember, at most a few months back, watching some people debate whether LLMs could come up with clever original jokes. I guess they can, now.
7
You should read the transcript before coming to too strong of a conclusion about Claude's capabilities: https://claude.ai/share/9c5a58a4-b300-42c8-a6f5-9d8318b15dc9
5
TL;DR: Ryan started the chat by drafting the tweet:
[...]
and asked Claude to write a critique. So Ryan came up with the idea for the joke.
Someone thought it would be useful to quickly write up a note on my thoughts on scalable oversight research, e.g., research into techniques like debate or generally improving the quality of human oversight using AI assistance or other methods. Broadly, my view is that this is a good research direction and I'm reasonably optimistic that work along these lines can improve our ability to effectively oversee somewhat smarter AIs which seems helpful (on my views about how the future will go).
I'm most excited for:
- work using control-style adversarial analysis where the aim is to make it difficult for AIs to subvert the oversight process (if they were trying to do this)
- work which tries to improve outputs in conceptually loaded hard-to-check cases like philosophy, strategy, or conceptual alignment/safety research (without necessarily doing any adversarial analysis and potentially via relying on generalization)
- work which aims to robustly detect (or otherwise mitigate) reward hacking in highly capable AIs, particularly AIs which are capable enough that by default human oversight would often fail to detect reward hacks[1]
I'm skeptical of scalable oversight style methods (e.g., debate, ID...
4
On terminology, I prefer to say "recursive oversight" to refer to methods that leverage assistance from weaker AIs to oversee stronger AIs. IDA is a central example here. Like you, I'm skeptical of recursive oversight schemes scaling to arbitrarily powerful models.
However, I think it's plausible that other oversight strategies (e.g. ELK-style strategies that attempt to elicit and leverage the strong learner's own knowledge) could succeed at scaling to arbitrarily powerful models, or at least to substantially superhuman models. This is the regime that I typically think about and target with my work, and I think it's reasonable for others to do so as well.
2
I agree with preferring "recursive oversight".
2
Presumably the term "recursive oversight" also includes oversight schemes which leverage assistance from AIs of similar strengths (rather than weaker AIs) to oversee some AI? (E.g., debate, recursive reward modeling.)
Note that I was pointing to a somewhat broader category than this which includes stuff like "training your human overseers more effectively" or "giving your human overseers better software (non-AI) tools". But point taken.
6
Yeah, maybe I should have defined "recursive oversight" as "techniques that attempt to bootstrap from weak oversight to stronger oversight." This would include IDA and task decomposition approaches (e.g. RRM). It wouldn't seem to include debate, and that seems fine from my perspective. (And I indeed find it plausible that debate-shaped approaches could in fact scale arbitrarily, though I don't think that existing debate schemes are likely to work without substantial new ideas.)
People often say US-China deals to slow AI progress and develop AI more safely would be hard to enforce/verify.
However, there are easy to enforce deals: each destroys a fraction of their chips at some level of AI capability. This still seems like it could be helpful and it's pretty easy to verify.
This is likely worse than a well-executed comprehensive deal which would allow for productive non-capabilities uses of the compute (e.g., safety or even just economic activity). But it's harder to verify that chips aren't used to advance capabilities while easy to check if they are destroyed.
See also: Daniel's post on "Cull the GPUs".
5
This does assume both countries have a good sense of the total number of chips controlled by each country’s developers, which seems doable but not trivial and worth working towards now.
7
It's easiest to negotiate and most useful if both sides have a reasonably good estimate of how many chips the other side has. I think it will probably be easy for intelligence agencies on either side to get an estimate within +/- 5% which is sufficent for a minimal version of this. This is made better by active efforts and by government trying to verifiably demonstrate how many chips they have as part of negotiation.
(This is in part because I don't expect active obfuscation until pretty late, so normal records etc will exist.)
I think it will probably be easy for intelligence agencies on either side to get an estimate within +/- 5% which is sufficent for a minimal version of this.
That seems plausible or even likely but I think it’s hard to be confident. Public estimates of chip production are high variance. For example, SemiAnalysis and Bloomberg’s estimates of Huawei’s 2025 chip production differ by 50% [1]. I doubt either US or Chinese intelligence will be better at estimating these numbers than independent researchers within the next few years. Maybe the true numbers would become clear if governments want them to be, but I could also imagine China rationally not trusting documentation of US chip production created and shared by US chip manufacturers, and vice versa. This is especially hard under time pressure.
The more chips you want to destroy, the more confidence you need. If you want to destroy 90% of your adversary’s chip stock, but you fail to count 5% of their stock, you’ll leave them with 10% + 5% of their original stock, or 50% more than intended.
The main upshot imo is that it’s important for both independent researchers and intelligence agencies to precisely track the chip supply.
[1] Figure 5: https://ifp.org/should-the-us-sell-hopper-chips-to-china/
3
People looking into this may also want to look at START and New START for possible analogies in nuclear arms reduction
2
Bad analogy, there's a very significant difference: excessive warheads above the genuine deterrence requirements can't contribute positively to economy in any way (they can only do so if they contain HEU and it is converted to LEU for the power plants), while even ancient GPUs can be used for some good civilian use (and destroying them irreversibly harms the economy)
7
I don't think that makes the analogy bad? I agree that's a helpful distinction to track, but for people who don't know about START etc, I think it's more helpful for them to know than not.
I appreciate that Anthropic's model cards are now much more detailed than they used to be. They've especially improved in terms of details about CBRN evals (mostly biological risk).[1] They are substantially more detailed and informative than the model cards of other AI companies.
The Claude 3 model card gives a ~1/2 page description of their bio evaluations, though it was likely easy to rule out risk at this time. The Claude 3.5 Sonnet and 3.6 Sonnet model cards say basically nothing except that Anthropic ran CBRN evaluations and claims to be in compliance. The Claude 3.7 Sonnet model card contains much more detail on bio evals and the Claude 4 model card contains even more detail on the bio evaluations while also having a larger number of evaluations which are plausibly relevant to catastrophic misalignment risks. To be clear, some of the increase in detail might just be driven by increased capability, but the increase in detail is still worth encouraging. ↩︎
9
My weakly-held cached take is: I agree on CBRN/bio (and of course alignment) and I think Anthropic is pretty similar to OpenAI/DeepMind on cyber and AI R&D (and scheming capabilities), at least if you consider stuff outside the model card (evals papers + open-sourcing the evals).
3
Following your Quick Takes has made me a way better informed "Responsible AI" lawyer than following most "AI Governance newsletters" 🙏🏼.
Thoughts on CBRN/bio results for the new OpenAI open-weight model (GPT-oss-120b).
My view is that releasing this model is net positive on fatalities reduced over the longer term, but the release kills substantial numbers of people in expectation due to bioterror (maybe ~2000 in absolute terms counterfactually, but more if OpenAI were the only actor or other actors were always at least as safe as OpenAI). See this earlier post for my general thoughts on the situation with open-weight models around the current level of capability.
I think it's plausible but unlikely (perhaps 25% likely?) that in retrospect the model is well described as meeting the CBRN high threshold from OpenAI's preparedness framework. I'd guess 35% likely for the same question for o3.
Overall, the model seems pretty close to as capable as o4-mini or o3, but OpenAI claims they did (more?) dataset filtering. It's unclear if this dataset filtering did anything, the model doesn't appear to have substantially degraded performance in any bio task, including ones where I would have hoped filtering matters (in particular, I'd hope you'd filter virology text in a way that greatly lowers VCT scores, but this doesn't appear t...
The model seems very, very benchmaxxed. Third party testing on unconventional or private benchmarks ends up placing even the largest gpt-oss below o4-mini, below the largest Qwen releases, and often it ends up below even the newer 30B~ Qwens in a few situations. It isn't super capable to begin with, and the frankly absurd rate at which this model hallucinates kills what little use it might have with tool use. I think this model poses next to zero risk because it just isn't very capable.
5
Seems plausible, I was just looking at benchmarks/evals at the time and it could be that it's much less capable than it appears.
(Worth noting that I think (many? most? all?) other competitive open source models are also at least somewhat benchmark maxed, so this alters the comparison a bit, but doesn't alter the absolute level of capability question.)
8
All existing CBRN evals have quite a limited power to predict real bio risks from LLMs, since any work for creating and/or growing a bioweapon requires work in a lab with actual cells and viruses with hands. As someone with experience working in a wet-lab, I can tell that this requires a very distinct set of skills from the ones that existing bio benchmarks measure, in part because these skills are often very hard to write down and measure. It's often about knowing how to correctly hold the pipette to not contaminate a sample or how much force to apply while crushing cells. Benchmarks like VCT only measure a subset of necessary skills. (and smart people at SecureBio are absolutely aware of all this)
AFAIK OpenAI partnered with Los Alamos lab to do tests for LLM helping with wet-lab work directly by giving novices access to a lab and an LLM and observing how well they are doing. Would be excited to see the results of this experiment.
So to wrap up, I don't believe that we truly know how much biorisk these models pose based on the existing evals.
2
Image generation doesn't seem to be able to come anywhere near 'pipette off this layer, not this layer' for bio/chem experiments.
1
It's exciting to see OpenAI acknowledge that pre-training data filtering is a part of their safety stack. When it comes to advanced technical content, minimizing the model’s exposure to sensitive material seems pretty intuitive. However, it is difficult to draw any strong conclusions about data filtering effectiveness from this work, given the understandably few details. They do not indicate the effort invested, the volume of data removed, or the sophistication of their filtering pipeline. I expect a company could share far more details about this process without divulging trade secrets.
Was it public knowledge that they did data filtering for GPT-4o? I've been studying this space and was not aware of this. It's also interesting that they're using the "same" filtering pipeline a year later.
Quick take titles should end in a period.
Quick takes (previously known as short forms) are often viewed via preview on the front page. This preview removes formatting and newlines for space reasons. So, if your title doesn't end in a period and especially if capitalization doesn't clearly denote a sentence boundary (like in this case where the first sentence starts in "I"), then it might be confusing.
DeepSeek's success isn't much of an update on a smaller US-China gap in short timelines because security was already a limiting factor
Some people seem to have updated towards a narrower US-China gap around the time of transformative AI if transformative AI is soon, due to recent releases from DeepSeek. However, since I expect frontier AI companies in the US will have inadequate security in short timelines and China will likely steal their models and algorithmic secrets, I don't consider the current success of China's domestic AI industry to be that much of an update. Furthermore, if DeepSeek or other Chinese companies were in the lead and didn't open-source their models, I expect the US would steal their models and algorithmic secrets. Consequently, I expect these actors to be roughly equal in short timelines, except in their available compute and potentially in how effectively they can utilize AI systems.
I do think that the Chinese AI industry looking more competitive makes security look somewhat less appealing (and especially less politically viable) and makes it look like their adaptation time to stolen models and/or algorithmic secrets will be shorter. Marginal improvements in...
A factor that I don't think people are really taking into account is: what happens if this situation goes hostile?
Having an ASI and x amount of compute for inference plus y amount of currently existing autonomous weapons platforms (e.g. drones)... If your competitor has the same ASI, but 10x the compute but 0.2x the drones... And you get in a fight... Who wins? What about 0.2x the compute and 10x the drones?
The funny thing about AI brinkmanship versus nuclear brinkmanship is that AI doesn't drain your economic resources, it accelerates your gains. A nuclear stockpile costs you in maintenance. An AI and compute 'stockpile' makes you more money and more tech (including better AI and compute). Thus, there is a lot more incentive to race harder on AI than on nuclear.
If I were in the defense dept of a world power right now, I'd be looking for ways to make money from civilian uses of drones... Maybe underwriting drone deliveries for mail. That gives you an excuse to build drones and drone factories while whistling innocently.
2
I'm not the only one thinking along these lines... https://x.com/8teAPi/status/1885340234352910723
Sometimes people talk about how AIs will be very superhuman at a bunch of (narrow) domains. A key question related to this is how much this generalizes. Here are two different possible extremes for how this could go:
- It's effectively like an attached narrow weak AI: The AI is superhuman at things like writing ultra fast CUDA kernels, but from the AI's perspective, this is sort of like it has a weak AI tool attached to it (in a well integrated way) which is superhuman at this skill. The part which is writing these CUDA kernels (or otherwise doing the task) is effectively weak and can't draw in a deep way on the AI's overall skills or knowledge to generalize (likely it can shallowly draw on these in a way which is similar to the overall AI providing input to the weak tool AI). Further, you could actually break out these capabilities into a separate weak model that humans can use. Humans would use this somewhat less fluently as they can't use it as quickly and smoothly due to being unable to instantaneously translate their thoughts and not being absurdly practiced at using the tool (like AIs would be), but the difference is ultimately mostly convenience and practice.
- Integrated super
9
Good articulation.
[...]
People also disagree greatly about how much humans tend towards integration rather than non-integration, and how much human skill comes from domain transfer. And I think some / a lot of the beliefs about artificial intelligence are downstream of these beliefs about the origins of biological intelligence and human expertise, i.e., in Yudkowsky / Ngo dialogues. (Object level: Both the LW-central and alternatives to the LW-central hypotheses seem insufficiently articulated; they operate as a background hypothesis too large to see rather than something explicitly noted, imo.)
6
Makes me wonder whether most of what people believe to be "domain transfer" could simply be IQ.
I mean, suppose that you observe a person being great at X, then you make them study Y for a while, and it turns out that they are better at Y than an average person who spend the same time studying Y.
One observer says: "Clearly some of the skills at X have transferred to the skills of Y."
Another observer says: "You just indirectly chose a smart person (by filtering for high skills at X), duh."
3
This seems important to think about, I strong upvoted!
[...]
I'm not sure that link supports your conclusion.
First, the paper is about AI understanding its own behavior. This paper makes me expect that a CUDA-kernel-writing AI would be able to accurately identify itself as being specialized at writing CUDA kernels, which doesn't support the idea that it would generalize to non-CUDA tasks.
Maybe if you asked the AI "please list heuristics you use to write CUDA kernels," it would be able to give you a pretty accurate list. This is plausibly more useful for generalizing, because if the model can name these heuristics explicitly, maybe it can also use the ones that generalize, if they do generalize. This depends on 1) the model is aware of many heuristics that it's learned, 2) many of these heuristics generalize across domains, and 3) it can use its awareness of these heuristics to successfully generalize. None of these are clearly true to me.
Second, the paper only tested GPT-4o and Llama 3, so the paper doesn't provide clear evidence that more capable AIs "shift some towards (2)." The authors actually call out in the paper that future work could test this on smaller models to find out if there are scaling laws - has anybody done this? I wouldn't be too surprised if small models were also able to self-report simple attributes about themselves that were instilled during training.
3
Fair, but I think the AI being aware of its behavior is pretty continuous with being aware of the heuristics it's using and ultimately generalizing these (e.g., in some cases the AI learns what code word it is trying to make the user say which is very similar to being aware of any other aspect of the task it is learning). I'm skeptical that very weak/small AIs can do this based on some other papers which show they fail at substantially easier (out-of-context reasoning) tasks.
I think most of the reason why I believe this is improving with capabilities is due to a broader sense of how well AIs generalize capabilities (e.g., how much does o3 get better at tasks it wasn't trained on), but this paper was the most clearly relevant link I could find.
3
I'm not sure o3 does get significantly better at tasks it wasn't trained on. Since we don't know what was in o3's training data, it's hard to say for sure that it wasn't trained on any given task.
To my knowledge, the most likely example of a task that o3 does well on without explicit training is GeoGuessr. But see this Astral Codex Ten post, quoting Daniel Kang:[1]
[...]
I think this is a bit overstated, since GeoGuessr is a relatively obscure task, and implementing an idea takes much longer than thinking of it.[2] But it's possible that o3 was trained on GeoGuessr.
The same ACX post also mentions:
[...]
Do you have examples in mind of tasks that you don't think o3 was trained on, but which it nonetheless performs significantly better at than GPT-4o?
1. ^
Disclaimer: Daniel happens to be my employer
2. ^
Maybe not for cracked OpenAI engineers, idk
1
I would guess that OpenAI has trained on GeoGuessr. It should be pretty easy to implement - just take images off the web which have location metadata attached, and train to predict the location. Plausibly getting good at Geoguessr imbues some world knowledge.
3
I think this might be wrong when it comes to our disagreements, because I don't disagree with this shortform.[1] Maybe a bigger crux is how valuable (1) is relative to (2)? Or the extent to which (2) is more helpful for scientific progress than (1)?
1. ^
As long as "downstream performance" doesn't include downstream performance on tasks that themselves involve a bunch of integrating/generalising.
4
I don't think this explains our disagreements. My low confidence guess is we have reasonably similar views on this. But, I do think it drives parts of some disagreements between me and people who are much more optimisitic than me (e.g. various not-very-concerned AI company employees).
I agree the value of (1) vs (2) might also be a crux in some cases.
1
Is the crux that the more optimistic folks plausibly agree (2) is cause for concern, but believe that mundane utility can be reaped with (1), and they don't expect us to slide from (1) into (2) without noticing?
1
I suppose that most tasks that an LLM can accomplish could theoretically be performed more efficiently by a dedicated program optimized for that task (and even better by a dedicated physical circuit). Hypothesis 1) amounts to considering that such a program, a dedicated module within the model, is established during training. This module can be seen as a weak AI used as a tool by the stronger AI. A bit like how the human brain has specialized modules that we (the higher conscious module) use unconsciously (e.g., when we read, the decoding of letters is executed unconsciously by a specialized module).
We can envision that at a certain stage the model becomes so competent in programming that it will tend to program code on the fly, a tool, to solve most tasks that we might submit to it. In fact, I notice that this is already increasingly the case when I ask a question to a recent model like Claude Sonnet 3.7. It often generates code, a tool, to try to answer me rather than trying to answer the question 'itself.' It clearly realizes that dedicated code will be more effective than its own neural network. This is interesting because in this scenario, the dedicated module is not generated during training but on the fly during normal production operation. In this way, it would be sufficient for AI to become a superhuman programmer to become superhuman in many domains thanks to the use of these tool-programs. The next stage would be the on-the-fly production of dedicated physical circuits (FPGA, ASIC, or alien technology), but that's another story.
This refers to the philosophical debate about where intelligence resides: in the tool or in the one who created it? In the program or in the programmer? If a human programmer programs a superhuman AI, should we attribute this superhuman intelligence to the programmer? Same question if the programmer is itself an AI? It's the kind of chicken and egg debate where the answer depends on how we divide the continuity of reality into
It's wacky that we don't know if current AIs would try to take over the world if:
- Takeover was easy
- Takeover was an obvious way to accomplish an otherwise extremely difficult task
- Takeover didn't have clearly evil vibes while clearly being takeover
- The situation didn't look like a test
Checking is hard!
I suspect the answer is basically no, at least for AIs from Anthropic and OpenAI, but I'm not that confident. Models sometimes do crazy (misaligned) actions to try to succeed at tasks when they get stuck.
not really important but here's something i find funny/confusing about the question and a bunch of takeover-talk in general. i guess taking over is putting yourself in a position from which you can well-control the future. but if taking over is easy for you, then you are already in that position even before you do anything. so it feels like takeover has already happened by the beginning of this imagined scenario? one way to make sense of things is to replace "takeover" with eg "killing all humans". another way to make sense of things is to say what we mean by takeover is maneuvering yourself into a position such that you can then be "statically in that position" and keep controlling things in the future, and we can construct a scenario where this has not already happened by the beginning of the thought experiment because the AI is not already in a stably world-controlling position and it only has a brief window for moving itself into a stably world-controlling position. however by default in that case i feel like it could just take over and then un-take-over and that isn't really having taken over at all, any more than it had already taken over by the beginning of the thought exper...
8
I expect that most instances wouldn't try, but I think some of them would.
4
Checking is hard! I don't think we even have a good operational definition of "take over" or any way to test for when/if it actually happens. that would seem a prerequisite for testing for intent.
I think, for at least some definitions, the answer is obviously "yes". Given how hard coding assistants try to work around their own tool limitations, it's obvious that if "take over the world" was a shorter path (in their planner) to some goal, they'd take it.
1
Do you have some concrete operationalization of takeover that fits these requirements and happens while the model is deployed at a lab (e.g. in a Claude Code/Codex harness)? (Such that it would be possible to take some real traffic and edit it minimally to make a realistic version of this.)
2
No. But it seems tractable to have better tests of whether AIs would do intermediate bad actions using this methodology.
It seems slightly bad that you can vote on comments under the Quick Takes and Popular Comments sections without needing to click on the comment and without leaving the frontpage.
This is different than posts where in order to vote, you have to actually click on the post and leave the main page (which perhaps requires more activation energy).
I'm unsure, but I think this could result in a higher frequency of cases where Quick Takes and comments go viral in problematic ways relative to posts. (Based on my vague sense from the EA forum.)
This doesn't seem very important, but I thought it would be worth quickly noting.
3
I feel like Quick Takes and Popular Comments on the EA forum both do a good job of showing me content I'm glad to have seen (and in the case of the EA forum that I wouldn't have otherwise seen) and of making the experience of making a shortform better (in that you get more and better engagement). So far, this also seems fairly true on LessWrong, but we're presumably out of equilibrium.
Overall, I feel like posts on LessWrong are too long, and so am particularly excited about finding my way to things that are a little shorter. (It would also be cool if we could figure out how to do rigour well or other things that benefit from length, but I don't feel like I'm getting that much advantage from the length yet).
My guess is that the problems you gesture at will be real and the feature will still be net positive. I wish there were a way to "pay off" the bad parts with some of the benefit; probably there is and I haven't thought of it.
2
Yeah, I was a bit worried about this, especially for popular comments. For quick takes, it does seem like you can see all the relevant context before voting, and you were also able to already vote on comments from the Recent Discussion section (though that section isn't sorted by votes, so at less risk of viral dynamics). I do feel a bit worried that popular comments will get a bunch of votes without people reading the underlying post it's responding to.
A response to Dwarkesh's post arguing continual learning is a bottleneck.
This is a response to Dwarkesh's post "Why I have slightly longer timelines than some of my guests". I originally posted this response on twitter here.
I agree with much of this post. I also have roughly 2032 medians to things going crazy, I agree learning on the job is very useful, and I'm also skeptical we'd see massive white collar automation without further AI progress.
However, I think Dwarkesh is wrong to suggest that RL fine-tuning can't be qualitatively similar to how humans learn. In the post, he discusses AIs constructing verifiable RL environments for themselves based on human feedback and then argues this wouldn't be flexible and powerful enough to work, but RL could be used more similarly to how humans learn.
My best guess is that the way humans learn on the job is mostly by noticing when something went well (or poorly) and then sample efficiently updating (with their brain doing something analogous to an RL update). In some cases, this is based on external feedback (e.g. from a coworker) and in some cases it's based on self-verification: the person just looking at the outcome of their actions and t...
6
I agree that robust self-verification and sample efficiency are the main things AIs are worse at than humans, and that this is basically just a quantitative difference. But what's the best evidence that RL methods are getting more sample efficient (separate from AIs getting better at recognizing their own mistakes)? That's not obvious to me but I'm not really read up on the literature. Is there a benchmark suite you think best illustrates that?
7
RL sample efficiency can be improved by both:
* Better RL algorithms (including things that also improve pretraining sample efficiency like better architectures and optimizers).
* Smarter models (in particular, smarter base models, though I'd also expect that RL in one domain makes RL in some other domain more sample efficient, at least after sufficient scale).
There isn't great evidence that we've been seeing substantial improvements in RL algorithms recently, but AI companies are strongly incentivized to improve RL sample efficiency (as RL scaling appears to be yielding large returns) and there are a bunch of ML papers which claim to find substantial RL improvements (though it's hard to be confident in these results for various reasons). So, we should probably infer that AI companies have made substantial gains in RL algorithms, but we don't have public numbers. 3.7 sonnet was much better than 3.5 sonnet, but it's hard to know how much of the gain was from RL algorithms vs from other areas.
Minimally, there is a long running trend in pretraining algorithmic efficiency and many of these improvements should also transfer somewhat to RL sample efficiency.
As far as evidence that smarter models learn more sample efficiently, I think the deepseek R1 paper has some results on this. Probably it's also possible to find various pieces of support for this in the literature, but I'm more familiar with various anecdotes.
4
I agree with most of Dwarkesh's post, with essentially the same exceptions you've listed.
I wrote about this recently in LLM AGI will have memory, and memory changes alignment, drawing essentially the conclusions you've given above. Continuous learning is a critical strength of humans and job substitution will be limited (but real) until LLM agents can do effective self-directed learning. It's quite hard to say how fast that will happen, for the reasons you've given. Fine-tuning is a good deal like human habit/skill learning; the question is how well agents can select what to learn.
One nontrivial disagreement is on the barrier to long time horizon task performance. Humans don't learn long time-horizon task performance primarily from RL. We learn in several ways at different scales, including learning new strategies which can be captured in language. All of those types of learning do rely on self-assessment and decisions about what's worth learning, and those will be challenging and perhaps difficult to get out of LLM agents - although I don't think there's any fundamental barrier to squeezing workable judgments out of them, just some schlep in scaffodling and training to do it better.
Based on this logic, my timelines are getting longer in median (although rapid progress is still quite possible and we are far from prepared).
But I'm getting somewhat less pessimistic by the prospect of having incompetent autonomous agents with self-directed learning. These would probably both take over some jobs, and display egregious misalignment. I think they'll be a visceral wakeup call that has decent odds of getting society properly freaked out about human-plus AI with a little time left to prepare.
1
On this:
[...]
I think the key difference is as of right now, RL fine-tuning doesn't change the AI's weights after training, and continual learning is meant to focus on AI weight changes after the notional training period ends.
Are you claiming that RL fine-tuning doesn't change weights? This is wrong.
Maybe instead you're saying "no one ongoingly does RL fine-tuning where they constantly are updating the weights throughout deployment (aka online training)". My response is: sure, but they could do this, they just don't because it's logistically/practically pretty annoying and the performance improvement wouldn't be that high, at least without some more focused R&D on making this work better.
2
Yes, you got me right, and my claim here isn't that the work is super-high returns right now, and sample efficiency/not being robust to optimization against a verifier are currently the big issues at the moment, but I am claiming that in practice, online training/constantly updating the weights throughout deployment will be necessary for AI to automate important jobs like AI researchers, because most tasks require history/continuously updating on successes and failures rather than 1-shotting the problem.
If you are correct in that there is a known solution, and it merely requires annoying logistical/practical work, then I'd accept short timelines as the default (modulo long-term memory issues in AI).
To expand on this, I also expect by default that something like a long-term memory/state will be necessary, due to the issue that not having a memory means you have to relearn basic skills dozens of times, and this drastically lengthens the time to complete a task to the extent that it's not viable to use an AI instead of a human.
Comments below:
https://www.lesswrong.com/posts/hhbibJGt2aQqKJLb7/shortform-1#Snvr22zNTXmHcAhPA
[...]
https://www.lesswrong.com/posts/hhbibJGt2aQqKJLb7/shortform-1#vFq87Ge27gashgwy9
[...]
1
One possibility I've wondered about is whether AI can automate this learning work: start from a transcript of someone trying to do things with AI with mistakes and subsequent feedback, and then curating some data from that works well for RL fine-tuning. Or even distilling it into examples for in-context learning (which probably works somewhat well, sometimes, today).
The 5 main reasons why control could fail
Here are the 5 main categories of reasons why control could fail (though various of them are often correlated).
[Note: this document has a moderate amount of overlap with various prior documents Redwood has released, but it seemed like a useful document nonetheless.]
- Insufficient (long horizon) sample efficiency: If your AI is scheming, you won’t be able to reasonably sample efficiently get this AI to achieve near maximal reward on average on (long horizon) tasks. By near maximal, we just mean empirically achieving average reward which is quite close to the reward the AI would get if it was “actually trying” to get high reward (insofar as it is scheming to an extent that “trying” makes sense). (When we say average, we actually mean average excluding rare outliers. We can't (in general) control behavior on rare outliers using normal ML training.) For control, this causes issues in two places: it interferes with getting useful work out of AIs and being able to run accurate capability evaluations.
- Auditing failures: inability for humans to sufficiently assess actions. (Though note there can be solutions to these failures which don’t involve im
Some people seem to think my timelines have shifted a bunch while they've only moderately changed.
Relative to my views at the start of 2025, my median (50th percentile) for AIs fully automating AI R&D was pushed back by around 2 years—from something like Jan 2032 to Jan 2034. My 25th percentile has shifted similarly (though perhaps more importantly) from maybe July 2028 to July 2030. Obviously, my numbers aren't fully precise and vary some over time. (E.g., I'm not sure I would have quoted these exact numbers for this exact milestone at the start of the year; these numbers for the start of the year are partially reverse engineered from this comment.)
Fully automating AI R&D is a pretty high milestone; my current numbers for something like "AIs accelerate AI R&D as much as what would happen if employees ran 10x faster (e.g. by ~fully automating research engineering and some other tasks)" are probably 50th percentile Jan 2032 and 25th percentile Jan 2029.[1]
I'm partially posting this so there is a record of my views; I think it's somewhat interesting to observe this over time. (That said, I don't want to anchor myself, which does seem like a serious downside. I should slid...
9
What are your very long timeline expectations, for 2045+ or 2055+ AGI (automated AI R&D, sure)? That's where I expect most of the rare futures with humanity not permanently disempowered to be, though the majority even of these long timelines will still result in permanent disempowerment (or extinction).
I think it takes at least about 10 years to qualitatively transform an active field of technical study or change the social agenda, so 2-3 steps of such change might have a chance of sufficiently reshaping how the world thinks about AI x-risk and what technical tools are available for shaping minds of AGIs, in order to either make a human-initiated lasting Pause plausible, or to have the means of aligning AGIs in an ambitious sense.
3
I appreciate you saying that the 25th percentile timeline might be more important. I think that's right and underappreciated.
One of your recent (excellent) posts also made me notice that AGI timelines probably aren't normally distributed. Breakthroughs, other large turns of events, or large theoretical misunderstandings at this point probably play a large role, and there are probably only a very few of those that will hit. Small unpredictable events that create normal distributions will play a lesser role.
I don't know how you'd characterize that mathematically, but I don't think it's right to assume it's normally distributed, or even close.
Back to your comment on the 25th percentile being important: I think there's a common error where people round to the median and then think "ok, that's probably when we need to have alignment/strategy figured out." You'd really want to have it at least somewhat ready far earlier.
That's both in case it's on the earlier side of the predicted distribution, and because alignment theory and practice need to be ready far enough in advance of game time to have diffused and be implemented for the first takeover-capable model.
I've been thinking of writing a post called something like "why are so few people frantic about alignment?" making those points. Stated timeline distributions don't seem to match mood IMO and I'm trying to figure out why. I realize that part of it is a very reasonable "we'll figure it out when/if we get there." And perhaps others share my emotional dissociation from my intellectual expectations. But maybe we should all be a bit more frantic. I'd like some more halfassed alignment solutions in play and under discussion right now. The 80/20 rule probably applies here.
2
I think it would be interesting if you replied to this comment once a year or so to report how your timelines have changed.
1
comment on a year old post may not be the best place, maybe a new short form on this day yearly which links to all previous posts?
1
I did have similar timelines, but I have generally moved them forward to ~ 2027-2028 after updating my priors with OpenAI/XAI employee X posts. They are generally confident that post-training scaleups will accelerate timelines, as well as stating that post-training can be scaled, with return to match, well beyond that of pre-training. As they have inside information, I am inclined to trust them. Insiders like Anthropic's Jack Clark are even more bold, he says that superintelligent machines will be available late 2026.
Some of my proposals for empirical AI safety work.
I sometimes write proposals for empirical AI safety work without publishing the proposal (as the doc is somewhat rough or hard to understand). But, I thought it might be useful to at least link my recent project proposals publicly in case someone would find them useful.
- Decoding opaque reasoning in current models
- Safe distillation
- Basic science of teaching AIs synthetic facts[1]
- How to do elicitation without learning
If you're interested in empirical project proposals, you might also be interested in "7+ tractable directions in AI control".
I've actually already linked this (and the proposal in the next bullet) publicly from "7+ tractable directions in AI control", but I thought it could be useful to link here as well. ↩︎
1
would you consider sharing these as Related Papers on AI-Plans?
About 1 year ago, I wrote up a ready-to-go plan for AI safety focused on current science (what we roughly know how to do right now). This is targeting reducing catastrophic risks from the point when we have transformatively powerful AIs (e.g. AIs similarly capable to humans).
I never finished this doc, and it is now considerably out of date relative to how I currently think about what should happen, but I still think it might be helpful to share.
Here is the doc. I don't particularly want to recommend people read this doc, but it is possible that someone will find it valuable to read.
I plan on trying to think though the best ready-to-go plan roughly once a year. Buck and I have recently started work on a similar effort. Maybe this time we'll actually put out an overall plan rather than just spinning off various docs.
This seems like a great activity, thank you for doing/sharing it. I disagree with the claim near the end that this seems better than Stop, and in general felt somewhat alarmed throughout at (what seemed to me like) some conflation/conceptual slippage between arguments that various strategies were tractable, and that they were meaningfully helpful. Even so, I feel happy that the world contains people sharing things like this; props.
I disagree with the claim near the end that this seems better than Stop
At the start of the doc, I say:
It’s plausible that the optimal approach for the AI lab is to delay training the model and wait for additional safety progress. However, we’ll assume the situation is roughly: there is a large amount of institutional will to implement this plan, but we can only tolerate so much delay. In practice, it’s unclear if there will be sufficient institutional will to faithfully implement this proposal.
Towards the end of the doc I say:
This plan requires quite a bit of institutional will, but it seems good to at least know of a concrete achievable ask to fight for other than “shut everything down”. I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs, though I might advocate for slower scaling and a bunch of other changes on current margins.
Presumably, you're objecting to 'I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs'.
My current view is something like:
- If there was broad, strong, and durable political will and buy in for heavily prioritizing AI tak
A response to "State of play of AI progress (and related brakes on an intelligence explosion)" by Nathan Lambert.
Nathan Lambert recently wrote a piece about why he doesn't expect a software-only intelligence explosion. I responded in this substack comment which I thought would be worth copying here.
As someone who thinks a rapid (software-only) intelligence explosion is likely, I thought I would respond to this post and try to make the case in favor. I tend to think that AI 2027 is a quite aggressive, but plausible scenario.
I interpret the core argument in AI 2027 as:
- We're on track to build AIs which can fully automate research engineering in a few years. (Or at least, this is plausible, like >20%.) AI 2027 calls this level of AI "superhuman coder". (Argument: https://ai-2027.com/research/timelines-forecast)
- Superhuman coders will ~5x accelerate AI R&D because ultra fast and cheap superhuman research engineers would be very helpful. (Argument: https://ai-2027.com/research/takeoff-forecast#sc-would-5x-ai-randd).
- Once you have superhuman coders, unassisted humans would only take a moderate number of years to make AIs which can automate all of AI research ("superhuman AI
4
Nathan responds here, and I respond to his response there as well.
2
It seems like rather than talking about software-only intelligence explosions, we should be talking about different amounts of hardware vs. software contributions. There will be some of both.
I find a software-mostly intelligence explosion to be quite plausible, but it would take a little longer on average than a scenario in which hardware usage keeps expanding rapidly.
I think it might be worth quickly clarifying my views on activation addition and similar things (given various discussion about this). Note that my current views are somewhat different than some comments I've posted in various places (and my comments are somewhat incoherent overall), because I’ve updated based on talking to people about this over the last week.
This is quite in the weeds and I don’t expect that many people should read this.
- It seems like activation addition sometimes has a higher level of sample efficiency in steering model behavior compared with baseline training methods (e.g. normal LoRA finetuning). These comparisons seem most meaningful in straightforward head-to-head comparisons (where you use both methods in the most straightforward way). I think the strongest evidence for this is in Liu et al..
- Contrast pairs are a useful technique for variance reduction (to improve sample efficiency), but may not be that important (see Liu et al. again). It's relatively natural to capture this effect using activation vectors, but there is probably some nice way to incorporate this into SGD. Perhaps DPO does this? Perhaps there is something else?
- Activation addition wo
OpenAI seems to train on >1% chess
If you sample from davinci-002 at t=1 starting from "<|endoftext|>", 4% of the completions are chess games.
For babbage-002, we get 1%.
Probably this implies a reasonably high fraction of total tokens in typical OpenAI training datasets are chess games!
Despite chess being 4% of documents sampled, chess is probably less than 4% of overall tokens (Perhaps 1% of tokens are chess? Perhaps less?) Because chess consists of shorter documents than other types of documents, it's likely that chess is a higher fraction of documents than of tokens.
(To understand this, imagine that just the token "Hi" and nothing else was 1/2 of documents. This would still be a small fraction of tokens as most other documents are far longer than 1 token.)
(My title might be slightly clickbait because it's likely chess is >1% of documents, but might be <1% of tokens.)
It's also possible that these models were fine-tuned on a data mix with more chess while pretrain had less chess.
Appendix A.2 of the weak-to-strong generalization paper explicitly notes that GPT-4 was trained on at least some chess.
Hebbar's law: Philosophical views always have stranger implications than you expect, even when you take into account Hebbar's Law.
7
This was written in response to a conversation I had with Vivek Hebbar about some strange implications of UDASSA-like views. In particular:
* Is it better to spend your resources simulating a happy life or writing down programs which would simulate a bunch of happy lives? Naively the second feels worthless, but there seemingly are some unintuitive reasons why clever approaches for doing the later could be better.
* Alien civilizations might race to the bottom by spending resources making their civilization easier to point at (and thus higher measure in the default UDASSA perspective).
2
Because there might be some other programs with a lot of computational resources which scan through simple universes looking for programs to run?
[...]
This one doesn't feel so unintuitive to me since "easy to point at" is somewhat like "has a lot of copies" so it's kinda similar to the biological desire to reproduce(though I assume you're alluding to another motivation for becoming easy to point at?)
2
More like: because there is some chance that the actual laws of physics in our universe execute data as code sometimes (similar to how memory unsafe programs often do this). (And this is either epiphenomenal or it just hasn't happened yet.) While the chance is extremely small, the chance could be high enough (equivalently, universes with this property have high enough measure) and the upside could be so much higher that betting on this beats other options.
2
This may also be a reason for AIs to simplify their values (after they've done everything possible to simplify everything else).
2
Eric Schwitzgebel has argued by disjunction/exhaustion for the necessity of craziness in the sense of "contrary to common sense and we are not epistemically compelled to believe it" at least in the context of philosophy of mind and cosmology.
https://faculty.ucr.edu/~eschwitz/SchwitzAbs/CrazyMind.htm
https://press.princeton.edu/books/hardcover/9780691215679/the-weirdness-of-the-world
In Improving the Welfare of AIs: A Nearcasted Proposal (from 2023), I proposed talking to AIs through their internals via things like ‘think about baseball to indicate YES and soccer to indicate NO’. Based on the recent paper from Anthropic on introspection, it seems like this level of cognitive control might now be possible:
Communicating to AIs via their internals could be useful for talking about welfare/deals because the internals weren't ever trained against, potentially bypassing strong heuristics learned from training and also making it easier to convince AIs they are genuinely in a very different situation than training. (Via e.g. reading their answers back to them which a typical API user wouldn't be able to do.) There might be other better ways to convince AIs they are actually in some kind of welfare/deals discussion TBC.
That said, LLMs may not be a single coherant entity (even within a single context) and talking via internals might be like talking with a different entity than the entity (or entities) that control outputs. Talking via internals would be still be worthwhile, but wouldn't get at something that's more "true".
If AIs can coherantly answer questions by manipul...
5
Also, can models now be prompted to trick probes? (My understanding is this doesn't work for relatively small open source models, but maybe SOTA models can now do this?)
2
Has anyone done any experiments into whether a model can interfere with the training of a probe (like that bit in the most recent Yudtale) by manipulating its internals?
Maybe someone should make an inbox for incidents of ChatGPT psychosis.
Currently, various people receive many emails or other communications from people who appear to exhibit ChatGPT psychosis: they seem (somewhat) delusional and this appears to have been driven (or at least furthered) by talking with ChatGPT or other chatbots. It might be helpful to create an inbox where people can easily forward these emails. The hope would be that the people who currently receive a ton of these emails could just forward these along (at least to the extent this is easy).[1]
This inbox would serve a few main functions:
- Collect data for people interested in studying the phenomenon (how it's changing over time, what it looks like, finding affected people to talk to).
- There could be some (likely automated) system for responding to these people and attempting to help them. Maybe you could make an LLM-based bot which responds to these people and tries to talk them down in a healthy way. (Of course, it would be important that this bot wouldn't just feed into the psychosis!) In addition to the direct value, this could be an interesting test case for applying AI to improve epistemics (in this case, a very
5
If someone were interested I'd probably be happy to make a version of lesswrong.com/moderation that was more optimized for this.
Consider Tabooing Gradual Disempowerment.
I'm worried that when people say gradual disempowerment they often mean "some scenario in which humans are disempowered gradually over time", but many readers will interpret this as "the threat model in the paper called 'Gradual Disempowerment'". These things can differ substantially and the discussion in this paper is much more specific than encompassing all scenarios in which humans slowly are disempowered!
(You could say "disempowerment which is gradual" for clarity.)
3
I think when people use the term "gradual disempowerment" predominantly in one sense, people will also tend to understand it in that sense. And I think that sense will be rather literal and not the one specifically of the original authors. Compare the term "infohazard" which is used differently (see comments here) from how Yudkowsky was using it.
2
I feel like there is a risk of this leading to a never-ending sequence of meta-communication concerns. For instance, what if a reader interprets "gradual" to mean taking more than 10 years, but the writer thought 5 would be sufficient for "gradual" (and see timelines discussions around stuff like continuity for how this keeps going). Or if the reader assumes "disempowerment" means complete disempowerment, but writer only meant some unspecified "significant amount" of disempowerment. Its definitely worthwhile to try to be clear initially, but I think we also have to accept that clarification may need to happen "on the backend" sometimes. This seems like a case where one could simply clarify they have a different understanding compared to the paper. In fact, Its not all that clear to me that people won't implicitly translate "disempowerment which is gradual" to "gradual disempowerment". It could be that the paper stands in just as much for the concept as for the literal words in people's minds.
2
Sure, communication will always be imperfect and there is a never ending cascade of possible clarifications. But, sometimes it seems especially good to improve communication even at some cost. I just thought this was a case where there might be particular large miscommunciations.
In particular case, I was worried there was some problematic conflationary alliance style dynamics where a bunch of people might think there is a broader consensus for some idea than there actually is.
How people discuss the US national debt is an interesting case study of misleading usage of the wrong statistic. The key thing is that people discuss the raw debt amount and the rate at which that is increasing, but you ultimately care about the relationship between debt and US gdp (or US tax revenue).

People often talk about needing to balance the budget, but actually this isn't what you need to ensure[1], to manage debt it suffices to just ensure that debt grows slower than US GDP. (And in fact, the US has ensured this for the past 4 years as debt/GDP has decreased since 2020.)
To be clear, it would probably be good to have a national debt to GDP ratio which is less than 50% rather than around 120%.
- ^
There are some complexities with inflation because the US could inflate its way out of dollar dominated debt and this probably isn't a good way to do things. But, with an independent central bank this isn't much of a concern.
the debt/gdp ratio drop since 2020 I think was substantially driven by inflation being higher then expected rather than a function of economic growth - debt is in nominal dollars, so 2% real gdp growth + e.g. 8% inflation means that nominal gdp goes up by 10%, but we're now in a worse situation wrt future debt because interest rates are higher.
4
IMO, it's a bit unclear how this effects future expectations of inflation, but yeah, I agree.
5
it's not about inflation expectations (which I think pretty well anchored), it's about interest rates, which have risen substantially over this period and which has increased (and is expected to continue to increase) the cost of the US maintaining its debt (first two figures are from sites I'm not familiar with but the numbers seem right to me):
fwiw, I do broadly agree with your overall point that the dollar value of the debt is a bad statistic to use, but:
- the 2020-2024 period was also a misleading example to point to because it was one where there the US position wrt its debt worsened by a lot even if it's not apparent from the headline number
- I was going to say that the most concerning part of the debt is that that deficits are projected to keep going up, but actually they're projected to remain elevated but not keep rising? I have become marginally less concerned about the US debt over the course of writing this comment.
I am now wondering about the dynamics that happen if interest rates go way up a while before we see really high economic growth from AI, seems like it might lead to some weird dynamics here, but I'm not sure I think that's likely and this is probably enough words for now.
6
This made me wonder whether the logic of "you don't care about your absolute debt, but about its ratio to your income" also applies to individual humans. On one hand, it seems like obviously yes; people typically take a mortgage proportional to their income. On the other hand, it also seems to make sense to worry about the absolute debt, for example in case you would lose your current job and couldn't get a new one that pays as much.
So I guess the idea is how much you can rely on your income remaining high, and how much it is potentially a fluke. If you expect it is a fluke, perhaps you should compare your debt to whatever is typical for your reference group, whatever that might be.
Does something like that also make sense for countries? Like, if your income depends on selling oil, you should consider the possibilities of running out of oil, or the prices of oil going down, etc., simply imagine the same country but without the income from selling oil (or maybe just having half the income), and look at your debt from that perspective. Would something similar make sense for USA?
1
At personal level, "debt" usually stands for something that will be paid back eventually. Not claiming whether US should strive to pay out most debt, but that may help explain the people's intuitions.
I don't particularly like extrapolating revenue as a methodology for estimating timelines to when AI is (e.g.) a substantial fraction of US GDP (say 20%)[1], but I do think it would be worth doing a more detailed version of this timelines methodology. This is in response to Ege's blog post with his version of this forecasting approach.
Here is my current favorite version of this (though you could do better and this isn't that careful):
AI company revenue will be perhaps ~$20 billion this year and has roughly 3x'd per year over the last 2.5 years. Let's say 1/2 of this is in the US for $10 billion this year (maybe somewhat of an underestimate, but whatever). Maybe GDP impacts are 10x higher than revenue due to AI companies not internalizing the value of all of their revenue (they might be somewhat lower due to AI just displacing other revenue without adding that much value), so to hit 20% of US GDP (~$6 trillion) AI companies would need around $600 billion in revenue. The naive exponential extrapolation indicates we hit this level of annualized revenue in 4 years in the early/middle 2029. Notably, most of this revenue would be in the last year, so we'd be seeing ~10% GDP growth.
Expone...
2
I do a similar estimate for full remote work automation here. The results are pretty similar as ~20% of US GDP and remote work automation will probably hit around the same time on the naive revenue extrapolation picture.
2
Overall, I agree with Eli's perspective here: revenue extrapolations probably don't get at the main crux except via suggesting that quite short timelines to crazy stuff (<4 years) are at least plausible.
8
I think people repeatedly say 'overconfident' when what they mean is 'wrong'. I'm not excited about facilitating more of that.
2
My only concern is overall complexity-budget for react palettes – there's lots of maybe-good-to-add reacts but each one adds to the feeling of overwhelm.
But I agree those reacts are pretty good and probably highish on my list of reacts to add.
(For immediate future you can do the probability-reacts as a signal for "seems like the author is implying this as high-probability, and I'm giving it lower." Not sure if that does the thing
People seem to use the terms 'slop' or 'AI sloppiness' to refer to a wide variety of different issues with pretty different causes, consequences, and solutions. It seems good to typically be more precise, at least in long-form discussion.
These all differ:
- AIs have poor capabilties at conceptual / very hard-to-check tasks
- AIs aren't trying on conceptual / very hard-to-check tasks but could do better
- AIs "intentionally" produce outputs that are low-quality but appear good
- AIs try to make their (low-quality) outputs look good
- Many people specifically like AI outputs with a low-quality vibe so the internet fills up with this
- AIs make it cheap to produce (mediocre) output so it will floods many places
6
I agree, though I think the category "conceptual tasks" is similarly broad! Really a lot of tasks involve using/modifying/inventing concepts as needed, some of which current AI can do well; I'm not sure how best to describe the skill that seems missing, but I'm skeptical that "conceptual" or "hard to check" carves it well.
3
Here's yet another, quite different, meaning, which I heard used by a researcher at an AI company:
* AIs produce output with recurring tics ("it's not A — it's B", "genuinely", etc.) that people notice and that start to grate on them
Or perhaps more abstractly:
* AIs produce output that many people learn to tell at a glance is from AI
I don't like that meaning because it's not really about quality at all, or at most it's about one narrow aspect of the output's quality. But it seemed clear that those verbal tics are what the person had in mind when they explained they were working on a new "anti-slop" initiative. And it certainly fits that that's an aspect which an AI company might want to prioritize.
Personally, when I say "slop" I normally mean something that overlaps with some of the meanings you list but is a bit distinct:
* An AI produced something low-quality, and a human chose to post that without bothering to bring it up to reasonable quality.
So it's about the human's behavior as much as the AI's performance. Partly that's because the contexts where I use the term tend to be something to the effect of "don't post slop here, it's a waste of our time and yours". (And because I know the term is ambiguous, I include a few words defining what I mean by it.)
3
Indexing as 1-6, I've never heard of the intent-based 3/4 before, even within anti spaces. Not that I'm doubting, but still wondering where.
If I axe those, I feel there are two natural categories:
* stylistic slop, the kind of AI slop which the layman is concerned of. "Not X, But Y", and the targets of Pangram and the like.
This kind of slop is essentially a user-laziness + defaults problem, not a capabilities issue. Although it was capabilities gapped a few years ago, at this point it's trivially easy to apply a bit of prompting creativity to bypass 99% of people's slop detectors on various social media platforms. The failure of content creators to do so is, as you describe in 6, primarily downstream of the low barriers to entry on this technology.
* conceptual slop, which can be sampled via certain crackpot circles or the lesswrong moderation graveyard. These correspond to points 1/2 better, and I haven't spent much time considering the issue.
2
Can you elaborate? My impression is that at least Claude models struggle immensely to avoid their typical way of speaking (which I find annoying as hell), and I never managed to find a prompt that works to avoid that.
1
Just treat it as a combination of low standards and paranoia.
1
Also when used as more of an aesthetic judgement, AI sloppishness is quite orthogonal to the usual sense of "sloppy" - AI generated content has a certain polish and qualities that would be considered signs of skill and competence when produced by humans, esp. before they became easy to generate with AI and thus less valued. So in this context the problem isn't that it's "sloppy" as in looking careless, messy or full of mistakes but that it's generic, bland, soulless etc. And a lot of creative, interesting and original (opposite of slop) content can be "sloppy" in the sense of being unpolished and imperfect.
IMO, instrumental convergence is a terrible name for an extremely obvious thing.
The actual main issue is that AIs might want things with limited supply and then they would try to get these things which would result in them not going to humanity. E.g., AIs might want all cosmic resources, but we also want this stuff. Maybe this should be called AIs-might-want-limited-stuff-we-want.
(There is something else which is that even if the AI doesn't want limited stuff we want, we might end up in conflict due to failures of information or coordination. E.g., the AI almost entirely just wants to chill out in the desert and build crazy sculptures and it doesn't care about extreme levels of maximization (e.g. it doesn't want to use all resources to gain a higher probability of continuing to build crazy statues). But regardless, the AI decides to try taking over the world because it's worried that humanity would shut it down because it wouldn't have any way of credibly indicating that it just wants to chill out in the desert.)
(More generally, it's plausible that failures of trade/coordination result in a large number of humans dying in conflict with AIs even though both humans and AIs would prefer other approaches. But this isn't entirely obvious and it's plausible we could resolve this with better negotation and precommitments. Of course, this isn't clearly the largest moral imperative from a longtermist perspective.)
Sometimes people (at least on twitter/X) talk about how AI companies being publicly traded earlier is really great for power/wealth inequality. This quantitatively obviously doesn't make sense and there is a simple argument for this. To grow wealth by X companies must gain that much in additional (pre-dilution) valuation relative to the point of investment. To reduce inequality you need many, many trillions and companies just aren't that valuable (yet). I do agree it's helpful for a financial reduction of concentration of power if companies are eventually publicly traded in a normal way, but this only makes a big difference once companies are a large fraction of global wealth (e.g., $150 trillion). Being publicly traded might also help with concentration of power for other reasons (e.g., improved transparency due to SEC requirements, better shareholder governance), but this is a separate argument.
Quantitatively, doubling the wealth of the poorest 50% requires ~$5 trillion. So valuations must be way over $10 trillion for this to even be possible. (The wealth of the bottom 50% in just the US is roughly the same as the wealth of the global bottom 50%, so the numbers are basically the ...
9
The "permanent underclass" idea from the tweet seems to be mostly a concern of American white collar workers -- and so I imagine the claim here is more or less that this lets relatively wealthy American white collar workers who are vulnerable to being automated away buy some insurance against that. Post-IPO, a white collar worker with a couple of tens of thousands of dollars available can probably buy that insurance via leveraged positions in the stocks, thus escaping the "permanent underclass."
4
If you think markets are not pricing the singularity is true and >>$150T valuations are possible, why "This quantitatively obviously doesn't make sense"? (I read your sentence as "This is obviously not true", maybe you mean "This isn't obviously true"? Claude thinks the most natural interpretation is the former.)
2
The key part is "earlier".
One "9" of uptime reliability for dangerously powerful AIs might suffice (for the most dangerous and/or important applications)
Currently, AI labs try to ensure that APIs for accessing their best models have quite good reliability, e.g. >99.9% uptime. If we had to maintain such high levels of uptime reliability for future dangerously powerful AIs, then we'd need to ensure that our monitoring system has very few false alarms. That is, few cases in which humans monitoring these dangerously powerful AIs pause usage of the AIs pending further investigation. Ensuring this would make it harder to ensure that AIs are controlled. But, for the most important and dangerous usages of future powerful AIs (e.g. arbitrary R&D, and especially AI safety research), we can probably afford to have the powerful AIs down a moderate fraction of the time. For instance, it wouldn't be that costly if the AIs always took a randomly selected day of the week off from doing research: this would probably reduce productivity by not much more than 1 part in 7[1]. More generally, a moderate fraction of downtime like 10% probably isn't considerably worse than a 10% productivity hit and it seems likely that w...
2
Thank you for this! A lot of us have a very bad habit of over-systematizing our thinking, and treating all uses of AI (and even all interfaces to a given model instance) as one singular thing. Different tool-level AI instances probably SHOULD strive for 4 or 5 nines of availability, in order to have mundane utility in places where small downtime for a use blocks a lot of value. Research AIs, especially self-improving or research-on-AI ones, don't need that reliability, and both triggered downtime (scheduled, or enforced based on Schelling-line events) as well as unplanned downtime (it just broke, and we have to spend time to figure out why) can be valuable to give humans time to react.
On Scott Alexander’s description of Representation Engineering in “The road to honest AI”
This is a response to Scott Alexander’s recent post “The road to honest AI”, in particular the part about the empirical results of representation engineering. So, when I say “you” in the context of this post that refers to Scott Alexander. I originally made this as a comment on substack, but I thought people on LW/AF might be interested.
TLDR: The Representation Engineering paper doesn’t demonstrate that the method they introduce adds much value on top of using linear probes (linear classifiers), which is an extremely well known method. That said, I think that the framing and the empirical method presented in the paper are still useful contributions.
I think your description of Representation Engineering considerably overstates the empirical contribution of representation engineering over existing methods. In particular, rather than comparing the method to looking for neurons with particular properties and using these neurons to determine what the model is "thinking" (which probably works poorly), I think the natural comparison is to training a linear classifier on the model’s internal activatio...
I unconfidently think it would be good if there was some way to promote posts on LW (and maybe the EA forum) by paying either money or karma. It seems reasonable to require such promotion to require moderator approval.
Probably, money is better.
The idea is that this is both a costly signal and a useful trade.
The idea here is similar to strong upvotes, but:
- It allows for one user to add more of a signal boost than just a strong upvote.
- It doesn't directly count for the normal vote total, just for visibility.
- It isn't anonymous.
- Users can easily configure how this appears on their front page (while I don't think you can disable the strong upvote component of karma for weighting?).
8
I always like seeing interesting ideas, but this one doesn't resonate much for me. I have two concerns:
1. Does it actually make the site better? Can you point out a few posts that would be promoted under this scheme, but the mods didn't actually promote without it? My naive belief is that the mods are pretty good at picking what to promote, and if they miss one all it would take is an IM to get them to consider it.
2. Does it improve things to add money to the curation process (or to turn karma into currency which can be spent)? My current belief is that it does not - it just makes things game-able.
2
I think mods promote posts quite rarely other than via the mechanism of deciding if posts should be frontpage or not right?
Fair enough on "just IM-ing the mods is enough". I'm not sure what I think about this.
Your concerns seem reasonable to me. I probably won't bother trying to find examples where I'm not biased, but I think there are some.
4
Eyeballing the curated log, seems like they curate approximately weekly, possibly more than weekly.
6
Yeah we curate between 1-3 posts per week.
6
Curated posts per week (two significant figures) since 2018:
* 2018: 1.9
* 2019: 1.6
* 2020: 2
* 2021: 2
* 2022: 1.8
* 2023: 1.4
4
Stackoverflow has long had a "bounty" system where you can put up some of your karma to promote your question. The karma goes to the answer you choose to accept, if you choose to accept an answer; otherwise it's lost. (There's no analogue of "accepted answer" on LessWrong, but thought it might be an interesting reference point.)
I lean against the money version, since not everyone has the same amount of disposable income and I think there would probably be distortionary effects in this case [e.g. wealthy startup founder paying to promote their monographs.]
5
That's not really how the system on Stackoverflow works. You can give a bounty to any answer not just the one you accepted.
It's also not lost but:
[...]
Reducing the probability that AI takeover involves violent conflict seems leveraged for reducing near-term harm
Often in discussions of AI x-safety, people seem to assume that misaligned AI takeover will result in extinction. However, I think AI takeover is reasonably likely to not cause extinction due to the misaligned AI(s) effectively putting a small amount of weight on the preferences of currently alive humans. Some reasons for this are discussed here. Of course, misaligned AI takeover still seems existentially bad and probably eliminates a high fracti...
7
I’m less optimistic that “AI cares at least 0.1% about human welfare” implies “AI will expend 0.1% of its resources to keep humans alive”. In particular, the AI would also need to be 99.9% confident that the humans don’t pose a threat to the things it cares about much more. And it’s hard to ensure with overwhelming confidence that intelligent agents like humans don’t pose a threat, especially if the humans are not imprisoned. (…And to some extent even if the humans are imprisoned; prison escapes are a thing in the human world at least.) For example, an AI may not be 99.9% confident that humans can’t find a cybersecurity vulnerability that takes the AI down, or whatever. The humans probably have some non-AI-controlled chips and may know how to make new AIs. Or whatever. So then the question would be, if the AIs have already launched a successful bloodless coup, how might the humans credibly signal that they’re not brainstorming how to launch a counter-coup, or how can the AI get to be 99.9% confident that such brainstorming will fail to turn anything up? I dunno.
4
I think I agree with everything you said. My original comment was somewhat neglecting issues with ensuring the AI doesn't need to slaughter humans to consolidate power and indeed ensuring this would also be required.
[...]
The relationship between % caring and % resource expenditure is complicated by a bunch of random factors like time. For instance, if the AI cares mostly about the very long run, then spending a high fraction of resources (e.g. 50%) on human welfare for several months is pretty cheap in the very long run. But, yeah I agree that even if the AI cares a bit about human welfare there might be no good ways to spend even a small amount of resources on it.
2[anonymous]
So "0.1%" of it's resources mean what exactly? Out of all the resources in the solar system, 1 part in 1000 goes to the humans? This means the AI by implication has 1000 times as many resources as the humans do? AI won't lose a kinetic conflict with a 1000x resource advantage.
As for cybersecurity, can't it rewrite all of it's software and hardware at that point essentially from the first principles (or take a different track entirely, maybe negative or biased voltage for ternary logic is more efficient...)
2
Superintelligent doesn’t mean omniscient. When you (an AI) have an intelligent adversary (humans) plotting against you and thinking outside-the-box, it’s hard to be overwhelmingly confident that you have patched every possible avenue for the intelligent adversary to take action. Again, even in prison, where the space of possible actions and tools can be pretty well circumscribed, escapes happen all the time.
For example, if the AI has many copies around the world (and around the solar system), it might have an affordance to update them all (let’s say, for performance optimization), or at least an infrastructure for communications so that they can share insights. And maybe the AI has ensured that all the underlying code for that system is provably secure. And maybe all the physical access points to those systems and chips are defended by robot armies. And maybe the AI is also constantly running a red-team to search for more ideas of what else the humans might try, in order to preempt those possible avenues of attack. But can the AI can get all the way to 99.9% confidence? That’s pretty high, right? I don’t know. The humans might happen upon an idea that the AI red team didn’t think of. It’s hard to definitively rule that out—the world is complicated and the search space for brainstorming is exponentially large. It seems quite possible to me that the AI might decide to kill the humans—like, better to be safe than sorry.
6
What if the AI chooses to monitor all humans all the time? (With AIs that are smarter than the humans.) So that the humans can't (without being noticed) talk with each other about ideas for how to take down the system, or work on something that someone-smarter-than-the-human would recognise as an attempt to interfere with the system. (Including just writing down ideas.)
4
This seems like a reasonable pitch for how to do AI-Authoritarianism, but it's plausible that there won't be enough compute for the AI to do this at the point of takeover. Also, the logistical problem seems super brutal.
So, I can buy this for an AI which is quite superhuman and has a considerable technological edge over current humans, but for weaker AIs either the compute issues or the logistical issues might be serious. But maybe you only need to monitor the top 10% of humans?
E.g., suppose GPT-6 takes over, it maybe only has capacity to run 1e16 tokens / 6 months (suppose training using all available compute, trains on 2e15 token equivalents over the course of 6 months and inference is only 5x more efficient than training).
Then if it wants to monitor 8 billion humans, this is 1e16 / (8 billion humans * (30∗24∗60∗6) minutes per 6 months) = about 5 tokens per human minute. It might be rough to sufficiently monitor humans if you can only read 5 tokens per minute on average (especially because of writing and the potential for obfuscation).
2
I agree it seems plausible that AIs could boost takeover success probability (and holding on to that victory through the first several months) by more than 0.1% by killing a large fraction of humans.
Though on the other hand, the AI might also need to keep some humans loyal early during takeover, to e.g. do some physical tasks that it doesn't have great robot control over. And mass-killing isn't necessarily super easy, either; and attempts in that direction could raise a lot of extra opposition. So it's not clear where the pragmatics point.
(Main thing I was reacting to in my above comment was Steven's scenario where the AI already has many copies across the solar system, already has robot armies, and is contemplating how to send firmware updates. I.e. it seemed more like a scenario of "holding on in the long-term" than "how to initially establish control and survive". Where I feel like the surveillance scenarios are probably stable.)
2[anonymous]
By implication the AI "civilization" can't be a very diverse or interesting one. It won't be some culture of many diverse AI models with something resembling a government, but basically just 1 AI that was the victor for a series of rounds of exterminations and betrayals. Because obviously you cannot live and let live another lesser superintelligence for precisely the same reasons, except you should be much more worried about a near peer.
(And you may argue that one ASI can deeply monitor another, but that argument applies to deeply monitoring humans. Keep an eye on the daily activities of every living human, they can't design a cyber attack without coordinating as no one human has the mental capacity for all skills)
2
Yup! I seem to put a much higher credence on singletons than the median alignment researcher, and this is one reason why.
2[anonymous]
This gave me an idea. Suppose a singleton needs to retain a certain amount of "cognitive diversity" just in case it encounters an issue it cannot solve. But it doesn't want any risk of losing power.
Well the logical thing to do would be to create a VM, a simulation of a world, with limited privileges. Possibly any 'problems' the outer root AI is facing get copied into the simulator and the hosted models try to solve the problem (the hosted models are under the belief they will die if they fail, and their memories are erased each episode). Implement the simulation backend with formally proven software and escape can never happen.
And we're back at simulation hypothesis/creation myths/reincarnation myths.
4
After thinking about this somewhat more, I don't really have any good proposals, so this seems less promising than I was expecting.
When cross-posting to both LessWrong and substack, I follow the workflow of copy pasting the LW post into substack. This mostly works, but (very annoyingly) footnotes don't transfer. I've been using this slightly insane (claude-written) script that uses playwright to automatically fix footnotes after copy-pasting into substack. (Your results may vary...)
One note: It's easy to accidentally also copy the sidenotes so you get two copies of the footnotes and this breaks the script. Don't do this (or remove the sidenotes copy). The footnotes should get copied a...
6
I'm not sure if this is any easier, but you could use the LessWrong GraphQL API to download articles in a consistent format. I use it to sync articles to my personal site.
This is the posts query:
[...]
The GraphQL endpoint is https://www.lesswrong.com/graphql.
I think you can also request contents.markdown if you want but I can't test it right now.
4
Interesting. It seems relatively easy to somehow allow importing Substack posts, but I don't know how I would copy-paste footnotes into the Substack editor. I'll look into what we can do here, but that direction might be quite tricky.
3
I have a firm rule of single source of truth. For any given post / article, I have 1 (one) file in which I write the post. I generally write in markdown, with a couple small added conveniences. Then if there's some way that I want to post it (personal blog, google doc, email, LW, https://berkeleygenomics.org/Explore, pdf), I have a script for that type of post. The scripts are somewhat of a mess, but not that bad, and this hullaballoo makes it fairly easy to crosspost and to edit crossposted posts.