(Cross-posted from Twitter, and therefore optimized somewhat for simplicity.)
Recent discussions of AI x-risk in places like Twitter tend to focus on "are you in the Rightthink Tribe, or the Wrongthink Tribe?". Are you a doomer? An accelerationist? An EA? A techno-optimist?
I'm pretty sure these discussions would go way better if the discussion looked less like that. More concrete claims, details, and probabilities; fewer vague slogans and vague expressions of certainty.
As a start, I made this image (also available as a Google Drawing):

(Added: Web version made by Tetraspace.)
I obviously left out lots of other important and interesting questions, but I think this is OK as a conversation-starter. I've encouraged Twitter regulars to share their own versions of this image, or similar images, as a nucleus for conversation (and a way to directly clarify what people's actual views are, beyond the stereotypes and slogans).
If you want to see a filled-out example, here's mine (though you may not want to look if you prefer to give answers that are less anchored): Google Drawing link.

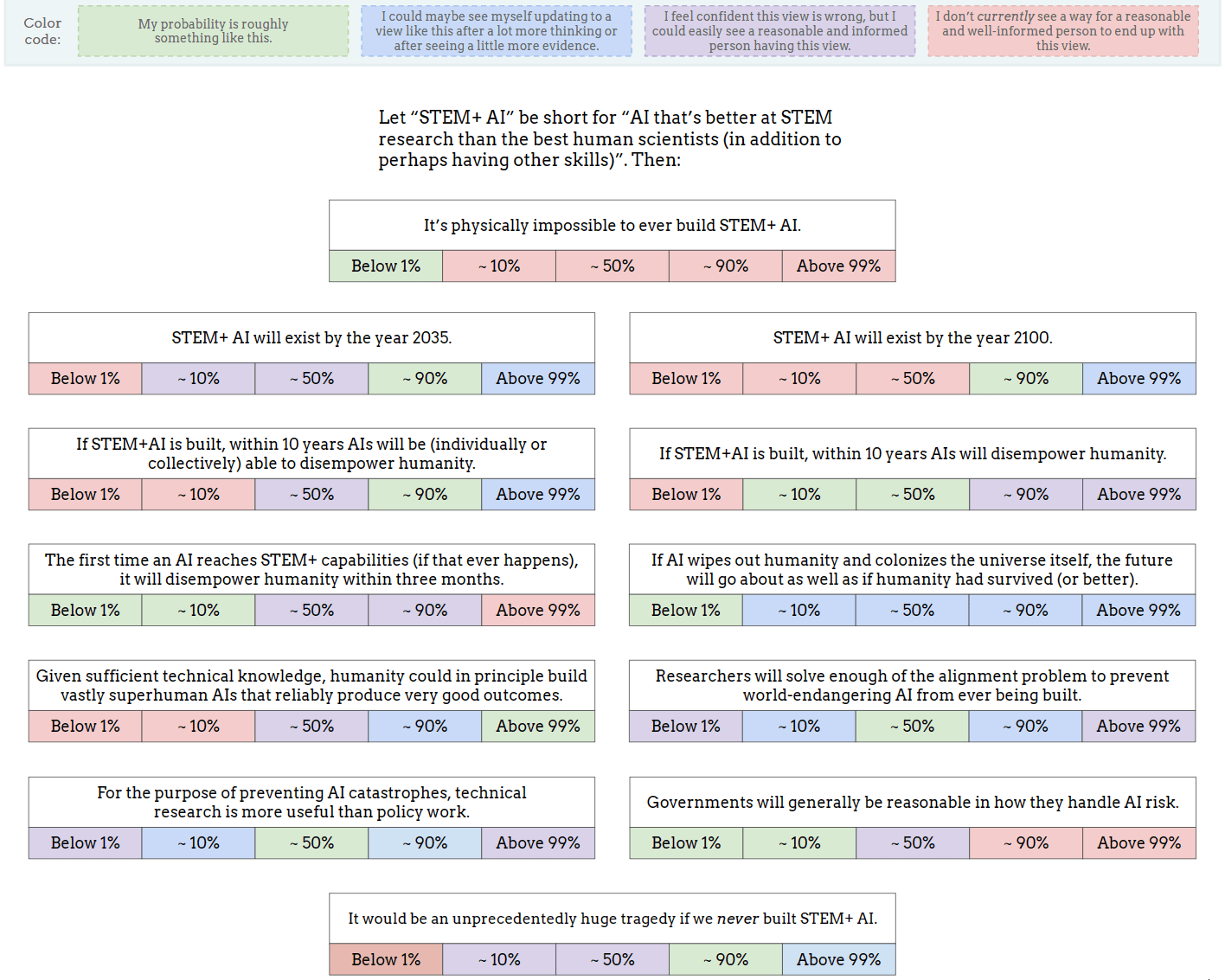
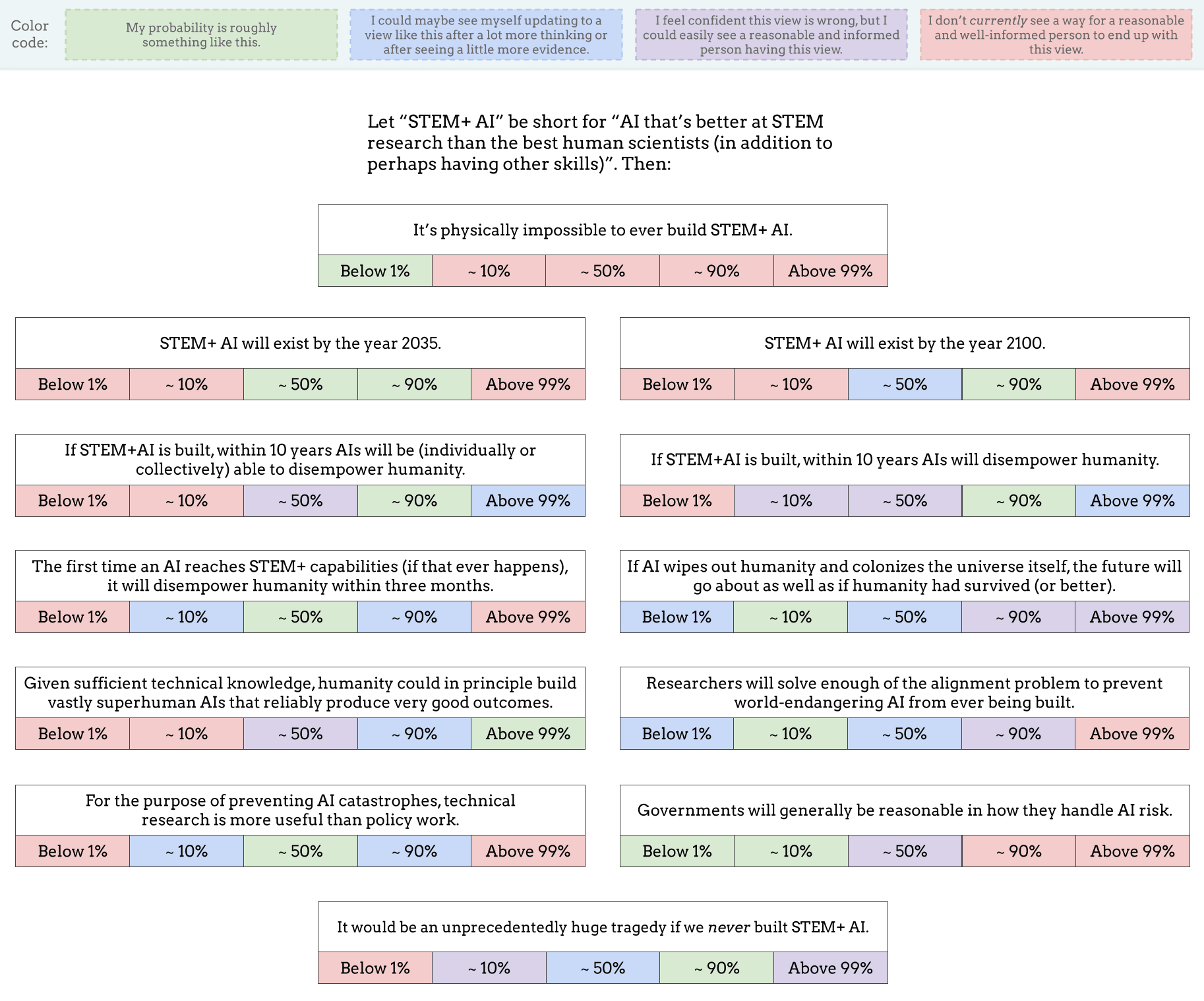
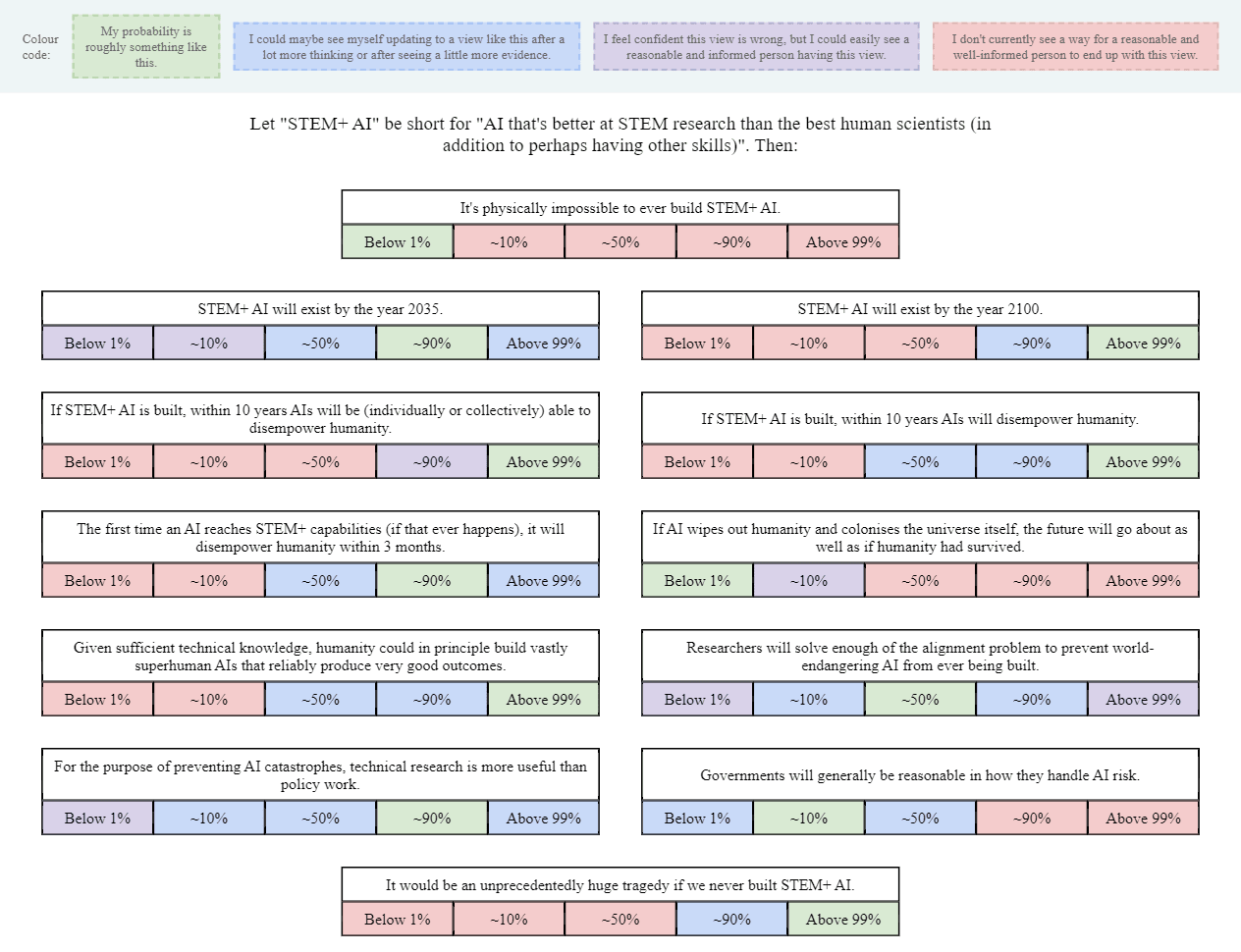
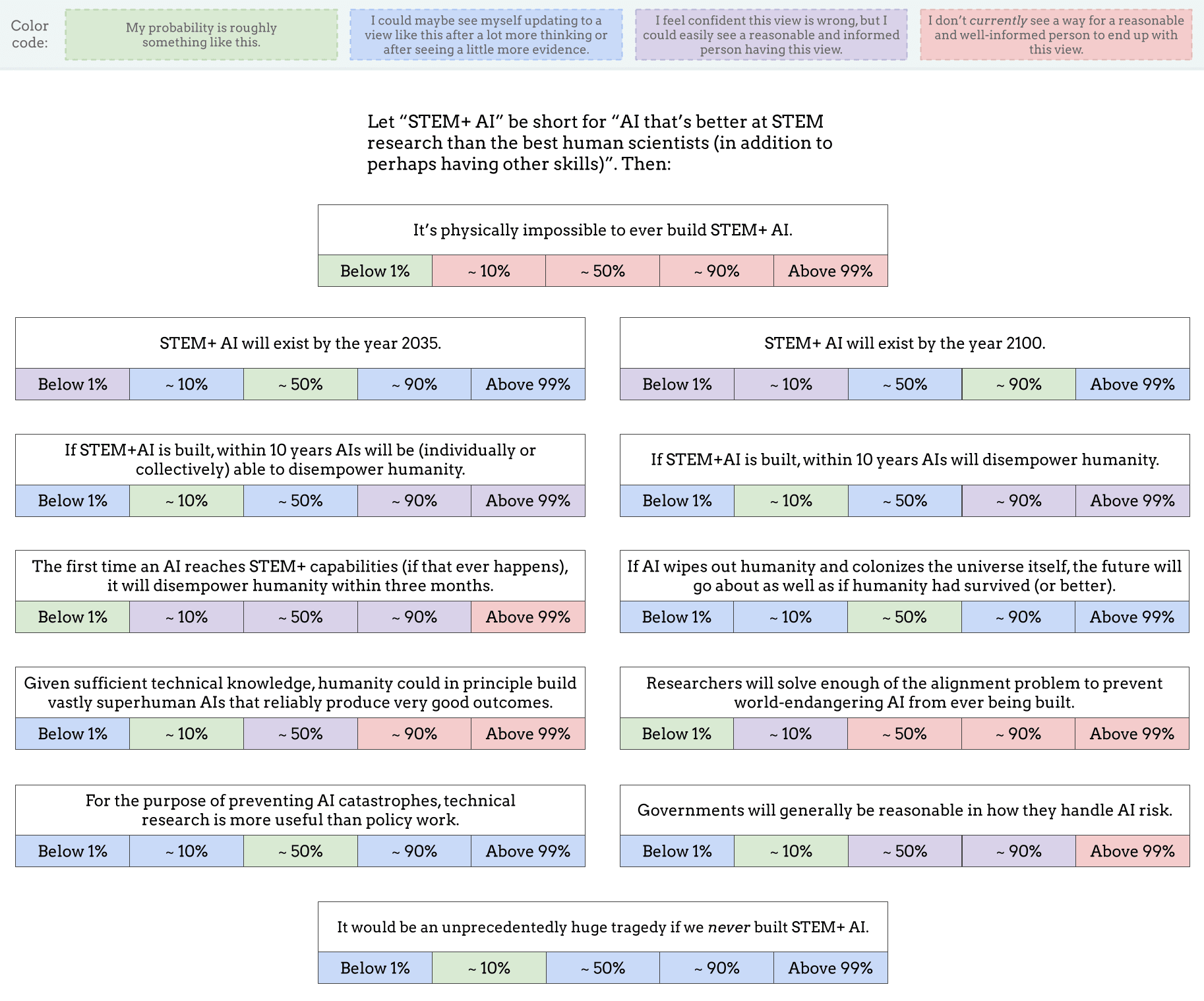
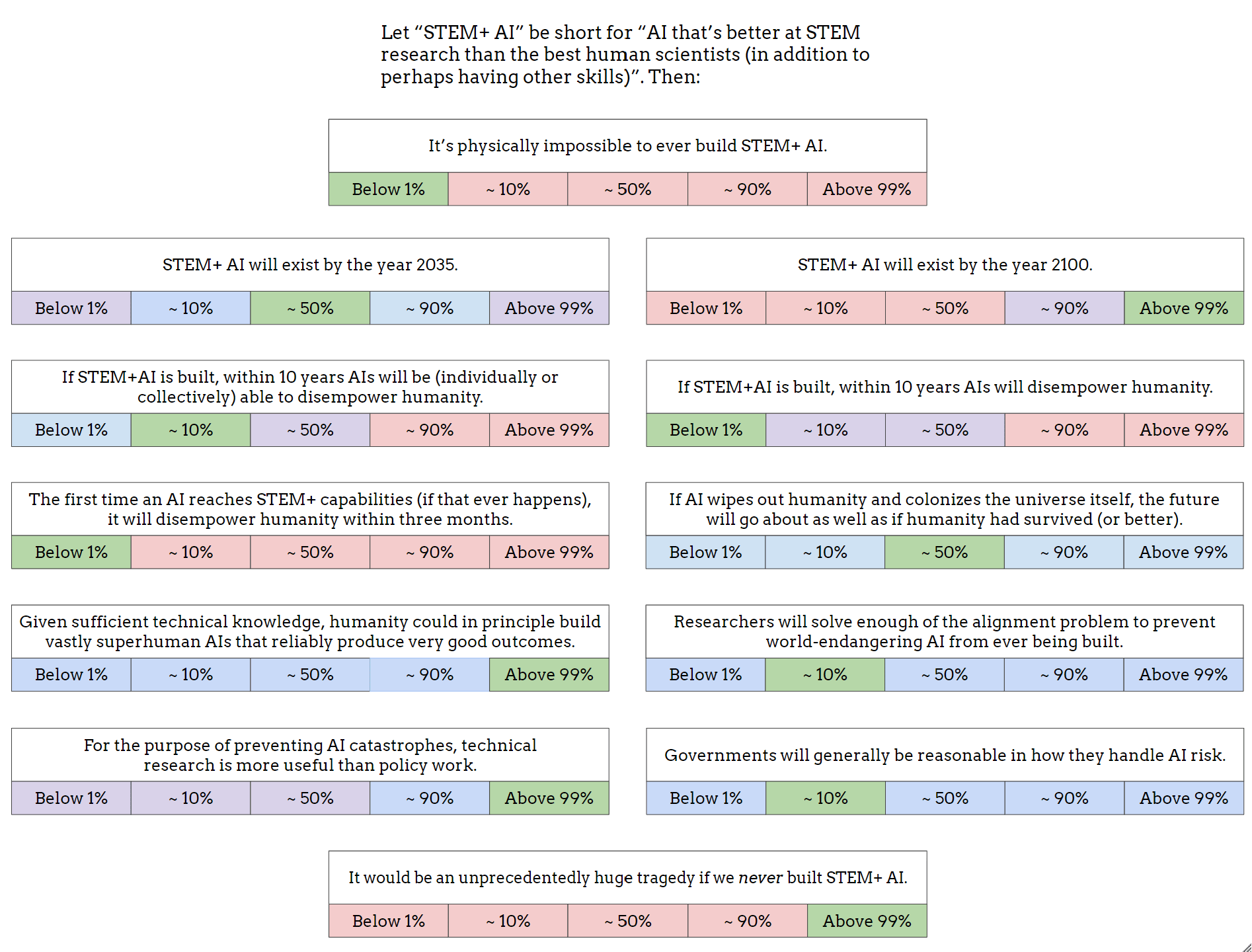

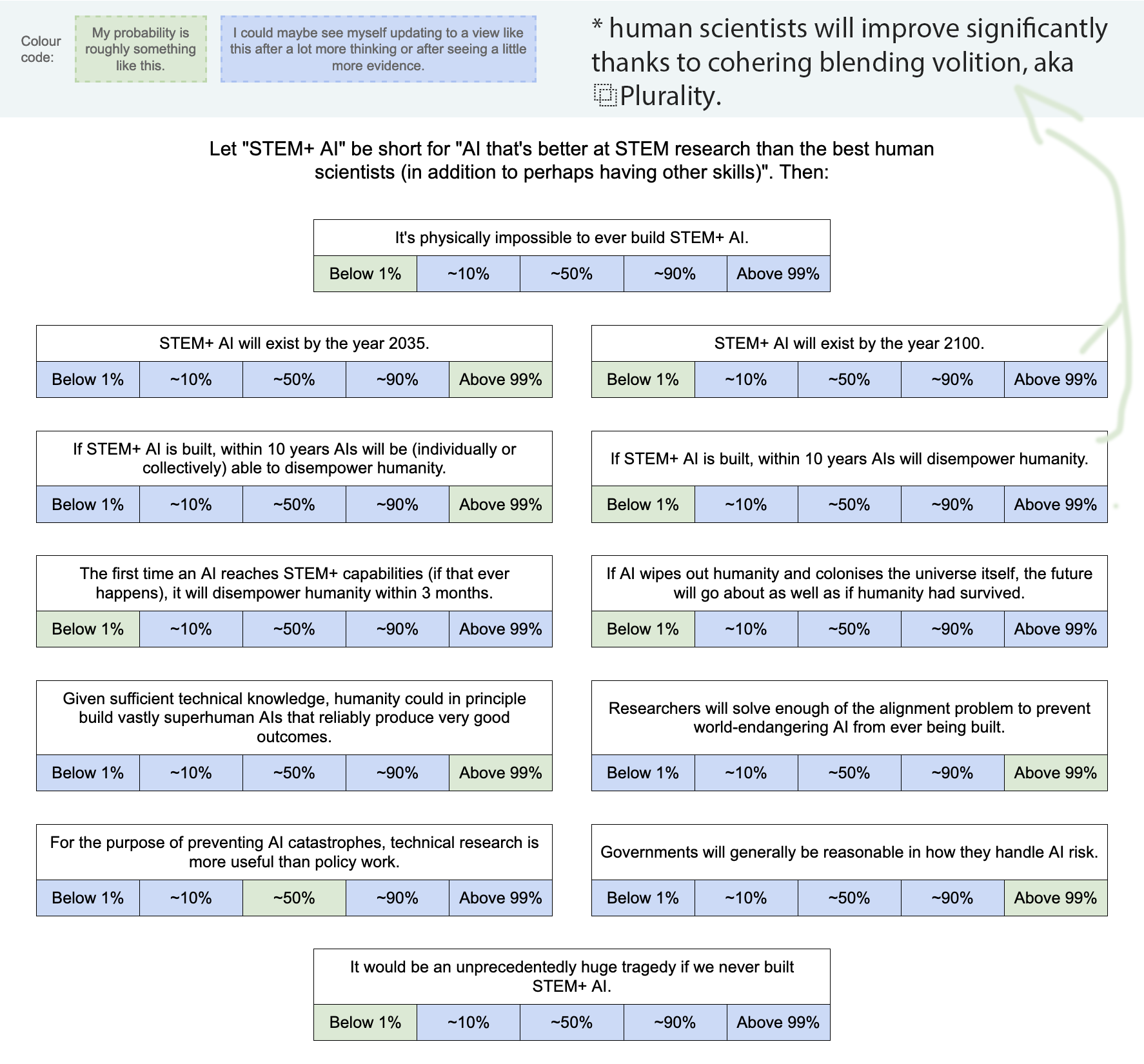{kind=link}
There's a hole in this, and it has to do the belief structure here.
The first time an AI reaches STEM+ capabilities (if that ever happens), it will disempower humanity within three months.
If STEM+AI is built, within 10 years AIs will disempower humanity.
What is an "AI"? A program someone runs on their computer? An online service that runs on a cluster of computers in the cloud?
Implicitly you're assuming the AI isn't just competent at "STEM+", it has motivations. It's not just a neural network that the training algorithm adjusted until the answers are correct on some benchmark/simulator that evaluates the model's ability at "STEM+", but some entity that...runs all the time? Why? Has local memory and continuity of existence? Why does it have this?
Why are humans going to give most AI systems any of this?
Is the AI just going to evolve these systems as a side effect of RSI environments, where humans didn't design the highest end AI models but they were architected by other AI models? That might result in this kind of behavior.
Memory/continuity of existence/personal goals for the AI are not simple things. They won't be features added by accident. Eliezer and others have argued that maybe llms could exhibit some of these features spontaenously, or the inner:outer argument, but memory can't be added by anything but a purposeful choice. (memory means that after a session, the model retains altered bits, and all sessions alter bits used by the model. It's not the same as a model that gets to skim the prior session logs on a new run, since humans get to control which logs the model sees. Continuity of existence requires memory, personal goals require memory to accomplish)
Maybe I'm badly off here but it almost sounds like we have the entire alignment argument exactly wrong. That instead of arguing we shouldn't build AI, or we need to figure out alignment, maybe the argument should be that we shouldn't build stateful AI with a continuity of existence for however many decades/centuries it takes to figure out how to make stable ones. Aligning a stateful machine that self modifies all the time is insanely difficult and may not actually be possible except by creating a world where the power balance is unfavorable to AI takeover.