
Biology-Inspired AGI Timelines: The Trick That Never Works
137CarlShulman
38jacob_cannell
12Vanessa Kosoy
9CarlShulman
27Vanessa Kosoy
19Mark Xu
7Vanessa Kosoy
16gwern
3Vanessa Kosoy
0Eliezer Yudkowsky
11paulfchristiano
20Daniel Kokotajlo
5ESRogs
5jaan
1Niels Fröhling
2Mark Xu
2Vanessa Kosoy
2Daniel Kokotajlo
2Vanessa Kosoy
2Daniel Kokotajlo
6Charlie Steiner
2CarlShulman
8Charlie Steiner
11paulfchristiano
2Charlie Steiner
2adamShimi
103Aryeh Englander
67Zvi
12AprilSR
6Pattern
4Oliver Sourbut
4adamShimi
1[comment deleted]
53TurnTrout
45Kaj_Sotala
13Rob Bensinger
16Aryeh Englander
2Eli Tyre
3Aryeh Englander
14Matthew Barnett
12Jotto999
11Rob Bensinger
9Rafael Harth
4Charlie Sanders
5Rob Bensinger
2Pattern
92Grant Demaree
6Sammy Martin
64davidad
91Rob Bensinger
13Eli Tyre
3adamShimi
38Richard_Ngo
27davidad
25paulfchristiano
8habryka
10paulfchristiano
25Daniel Kokotajlo
6jacob_cannell
5adamShimi
2Daniel Kokotajlo
2adamShimi
4Daniel Kokotajlo
2adamShimi
23So8res
19davidad
10ESRogs
22davidad
4Rob Bensinger
2ESRogs
15Daniel Kokotajlo
24Matthew Barnett
8Charlie Steiner
3adamShimi
5Daniel Kokotajlo
4adamShimi
14Rob Bensinger
25Eliezer Yudkowsky
13Ben Pace, the Vacationing Vagabond
13RomanS
13jacob_cannell
25Eliezer Yudkowsky
4jacob_cannell
16Eliezer Yudkowsky
4jacob_cannell
2Thomas Kwa
4jacob_cannell
14RomanS
19jacob_cannell
26Eliezer Yudkowsky
6jacob_cannell
12Adele Lopez
10jacob_cannell
14Vaniver
5jacob_cannell
3Charlie Steiner
2jacob_cannell
12Daniel Kokotajlo
7Ajeya Cotra
4Daniel Kokotajlo
11Rafael Harth
11Adele Lopez
4khafra
3wunan
9Rob Bensinger
8adamShimi
8a gently pricked vein
7lc
7p.b.
6Ruby
5Expertium
21Eliezer Yudkowsky
0Expertium
5Ben Pace, the Vacationing Vagabond
4Ben Pace, the Vacationing Vagabond
5calef
11Eliezer Yudkowsky
2Pattern
5TekhneMakre
12Veedrac
6TekhneMakre
3Veedrac
6Lukas Finnveden
5TekhneMakre
4TekhneMakre
2TekhneMakre
5TurnTrout
3TAG
2Pattern
4Eli Tyre
4CronoDAS
4Greg C
7Ann
1Greg C
1Ann
2Greg C
4Dach
4Gurkenglas
2Charlie Steiner
4Lukas Finnveden
4romeostevensit
3Lotus Cobra
1Peter Chatain
10davidad
2Lukas Finnveden
2joshc
2FireStormOOO
6davidad
1Tapatakt
1Dweomite
1Greg C
0Дмитрий Зеленский
- 1988 -
Hans Moravec: Behold my book Mind Children. Within, I project that, in 2010 or thereabouts, we shall achieve strong AI. I am not calling it "Artificial General Intelligence" because this term will not be coined for another 15 years or so.
Eliezer (who is not actually on the record as saying this, because the real Eliezer is, in this scenario, 8 years old; this version of Eliezer has all the meta-heuristics of Eliezer from 2021, but none of that Eliezer's anachronistic knowledge): Really? That sounds like a very difficult prediction to make correctly, since it is about the future, which is famously hard to predict.
Imaginary Moravec: Sounds like a fully general counterargument to me.
Eliezer: Well, it is, indeed, a fully general counterargument against futurism. Successfully predicting the unimaginably far future - that is, more than 2 or 3 years out, or sometimes less - is something that human beings seem to be quite bad at, by and large.
Moravec: I predict that, 4 years from this day, in 1992, the Sun will rise in the east.
Eliezer: Okay, let me qualify that. Humans seem to be quite bad at predicting the future whenever we need to predict anything at all new and unfamiliar, rather than the Sun continuing to rise every morning until it finally gets eaten. I'm not saying it's impossible to ever validly predict something novel! Why, even if that was impossible, how could I know it for sure? By extrapolating from my own personal inability to make predictions like that? Maybe I'm just bad at it myself. But any time somebody claims that some particular novel aspect of the far future is predictable, they justly have a significant burden of prior skepticism to overcome.
More broadly, we should not expect a good futurist to give us a generally good picture of the future. We should expect a great futurist to single out a few rare narrow aspects of the future which are, somehow, exceptions to the usual rule about the future not being very predictable.
I do agree with you, for example, that we shall at some point see Artificial General Intelligence. This seems like a rare predictable fact about the future, even though it is about a novel thing which has not happened before: we keep trying to crack this problem, we make progress albeit slowly, the problem must be solvable in principle because human brains solve it, eventually it will be solved; this is not a logical necessity, but it sure seems like the way to bet. "AGI eventually" is predictable in a way that it is not predictable that, e.g., the nation of Japan, presently upon the rise, will achieve economic dominance over the next decades - to name something else that present-day storytellers of 1988 are talking about.
But timing the novel development correctly? That is almost never done, not until things are 2 years out, and often not even then. Nuclear weapons were called, but not nuclear weapons in 1945; heavier-than-air flight was called, but not flight in 1903. In both cases, people said two years earlier that it wouldn't be done for 50 years - or said, decades too early, that it'd be done shortly. There's a difference between worrying that we may eventually get a serious global pandemic, worrying that eventually a lab accident may lead to a global pandemic, and forecasting that a global pandemic will start in November of 2019.
Moravec: You should read my book, my friend, into which I have put much effort. In particular - though it may sound impossible to forecast, to the likes of yourself - I have carefully examined a graph of computing power in single chips and the most powerful supercomputers over time. This graph looks surprisingly regular! Now, of course not all trends can continue forever; but I have considered the arguments that Moore's Law will break down, and found them unconvincing. My book spends several chapters discussing the particular reasons and technologies by which we might expect this graph to not break down, and continue, such that humanity will have, by 2010 or so, supercomputers which can perform 10 trillion operations per second.*
Oh, and also my book spends a chapter discussing the retina, the part of the brain whose computations we understand in the most detail, in order to estimate how much computing power the human brain is using, arriving at a figure of 10^13 ops/sec. This neuroscience and computer science may be a bit hard for the layperson to follow, but I assure you that I am in fact an experienced hands-on practitioner in robotics and computer vision.
So, as you can see, we should first get strong AI somewhere around 2010. I may be off by an order of magnitude in one figure or another; but even if I've made two errors in the same direction, that only shifts the estimate by 7 years or so.
(*) Moravec just about nailed this part; the actual year was 2008.
Eliezer: I sure would be amused if we did in fact get strong AI somewhere around 2010, which, for all I know at this point in this hypothetical conversation, could totally happen! Reversed stupidity is not intelligence, after all, and just because that is a completely broken justification for predicting 2010 doesn't mean that it cannot happen that way.
Moravec: Really now. Would you care to enlighten me as to how I reasoned so wrongly?
Eliezer: Among the reasons why the Future is so hard to predict, in general, is that the sort of answers we want tend to be the products of lines of causality with multiple steps and multiple inputs. Even when we can guess a single fact that plays some role in producing the Future - which is not of itself all that rare - usually the answer the storyteller wants depends on more facts than that single fact. Our ignorance of any one of those other facts can be enough to torpedo our whole line of reasoning - in practice, not just as a matter of possibilities. You could say that the art of exceptions to Futurism being impossible, consists in finding those rare things that you can predict despite being almost entirely ignorant of most concrete inputs into the concrete scenario. Like predicting that AGI will happen at some point, despite not knowing the design for it, or who will make it, or how.
My own contribution to the Moore's Law literature consists of Moore's Law of Mad Science: "Every 18 months, the minimum IQ required to destroy the Earth drops by 1 point." Even if this serious-joke was an absolutely true law, and aliens told us it was absolutely true, we'd still have no ability whatsoever to predict thereby when the Earth would be destroyed, because we'd have no idea what that minimum IQ was right now or at any future time. We would know that in general the Earth had a serious problem that needed to be addressed, because we'd know in general that destroying the Earth kept on getting easier every year; but we would not be able to time when that would become an imminent emergency, until we'd seen enough specifics that the crisis was already upon us.
In the case of your prediction about strong AI in 2010, I might put it as follows: The timing of AGI could be seen as a product of three factors, one of which you can try to extrapolate from existing graphs, and two of which you don't know at all. Ignorance of any one of them is enough to invalidate the whole prediction.
These three factors are:
Or to rephrase: Depending on how much you and your civilization know about AI-making - how much you know about cognition and computer science - it will take you a variable amount of computing power to build an AI. If you really knew what you were doing, for example, I confidently predict that you could build a mind at least as powerful as a human mind, while using fewer floating-point operations per second than a human brain is making useful use of -
Chris Humbali: Wait, did you just say "confidently"? How could you possibly know that with confidence? How can you criticize Moravec for being too confident, and then, in the next second, turn around and be confident of something yourself? Doesn't that make you a massive hypocrite?
Eliezer: Um, who are you again?
Humbali: I'm the cousin of Pat Modesto from your previous dialogue on Hero Licensing! Pat isn't here in person because "Modesto" looks unfortunately like "Moravec" on a computer screen. And also their first name looks a bit like "Paul" who is not meant to be referenced either. So today I shall be your true standard-bearer for good calibration, intellectual humility, the outside view, and reference class forecasting -
Eliezer: Two of these things are not like the other two, in my opinion; and Humbali and Modesto do not understand how to operate any of the four correctly, in my opinion; but anybody who's read "Hero Licensing" should already know I believe that.
Humbali: - and I don't see how Eliezer can possibly be so confident, after all his humble talk of the difficulty of futurism, that it's possible to build a mind 'as powerful as' a human mind using 'less computing power' than a human brain.
Eliezer: It's overdetermined by multiple lines of inference. We might first note, for example, that the human brain runs very slowly in a serial sense and tries to make up for that with massive parallelism. It's an obvious truth of computer science that while you can use 1000 serial operations per second to emulate 1000 parallel operations per second, the reverse is not in general true.
To put it another way: if you had to build a spreadsheet or a word processor on a computer running at 100Hz, you might also need a billion processing cores and massive parallelism in order to do enough cache lookups to get anything done; that wouldn't mean the computational labor you were performing was intrinsically that expensive. Since modern chips are massively serially faster than the neurons in a brain, and the direction of conversion is asymmetrical, we should expect that there are tasks which are immensely expensive to perform in a massively parallel neural setup, which are much cheaper to do with serial processing steps, and the reverse is not symmetrically true.
A sufficiently adept builder can build general intelligence more cheaply in total operations per second, if they're allowed to line up a billion operations one after another per second, versus lining up only 100 operations one after another. I don't bother to qualify this with "very probably" or "almost certainly"; it is the sort of proposition that a clear thinker should simply accept as obvious and move on.
Humbali: And is it certain that neurons can perform only 100 serial steps one after another, then? As you say, ignorance about one fact can obviate knowledge of any number of others.
Eliezer: A typical neuron firing as fast as possible can do maybe 200 spikes per second, a few rare neuron types used by eg bats to echolocate can do 1000 spikes per second, and the vast majority of neurons are not firing that fast at any given time. The usual and proverbial rule in neuroscience - the sort of academically respectable belief I'd expect you to respect even more than I do - is called "the 100-step rule", that any task a human brain (or mammalian brain) can do on perceptual timescales, must be doable with no more than 100 serial steps of computation - no more than 100 things that get computed one after another. Or even less if the computation is running off spiking frequencies instead of individual spikes.
Moravec: Yes, considerations like that are part of why I'd defend my estimate of 10^13 ops/sec for a human brain as being reasonable - more reasonable than somebody might think if they were, say, counting all the synapses and multiplying by the maximum number of spikes per second in any neuron. If you actually look at what the retina is doing, and how it's computing that, it doesn't look like it's doing one floating-point operation per activation spike per synapse.
Eliezer: There's a similar asymmetry between precise computational operations having a vastly easier time emulating noisy or imprecise computational operations, compared to the reverse - there is no doubt a way to use neurons to compute, say, exact 16-bit integer addition, which is at least more efficient than a human trying to add up 16986+11398 in their heads, but you'd still need more synapses to do that than transistors, because the synapses are noisier and the transistors can just do it precisely. This is harder to visualize and get a grasp on than the parallel-serial difference, but that doesn't make it unimportant.
Which brings me to the second line of very obvious-seeming reasoning that converges upon the same conclusion - that it is in principle possible to build an AGI much more computationally efficient than a human brain - namely that biology is simply not that efficient, and especially when it comes to huge complicated things that it has started doing relatively recently.
ATP synthase may be close to 100% thermodynamically efficient, but ATP synthase is literally over 1.5 billion years old and a core bottleneck on all biological metabolism. Brains have to pump thousands of ions in and out of each stretch of axon and dendrite, in order to restore their ability to fire another fast neural spike. The result is that the brain's computation is something like half a million times less efficient than the thermodynamic limit for its temperature - so around two millionths as efficient as ATP synthase. And neurons are a hell of a lot older than the biological software for general intelligence!
The software for a human brain is not going to be 100% efficient compared to the theoretical maximum, nor 10% efficient, nor 1% efficient, even before taking into account the whole thing with parallelism vs. serialism, precision vs. imprecision, or similarly clear low-level differences.
Humbali: Ah! But allow me to offer a consideration here that, I would wager, you've never thought of before yourself - namely - what if you're wrong? Ah, not so confident now, are you?
Eliezer: One observes, over one's cognitive life as a human, which sorts of what-ifs are useful to contemplate, and where it is wiser to spend one's limited resources planning against the alternative that one might be wrong; and I have oft observed that lots of people don't... quite seem to understand how to use 'what if' all that well? They'll be like, "Well, what if UFOs are aliens, and the aliens are partially hiding from us but not perfectly hiding from us, because they'll seem higher-status if they make themselves observable but never directly interact with us?"
I can refute individual what-ifs like that with specific counterarguments, but I'm not sure how to convey the central generator behind how I know that I ought to refute them. I am not sure how I can get people to reject these ideas for themselves, instead of them passively waiting for me to come around with a specific counterargument. My having to counterargue things specifically now seems like a road that never seems to end, and I am not as young as I once was, nor am I encouraged by how much progress I seem to be making. I refute one wacky idea with a specific counterargument, and somebody else comes along and presents a new wacky idea on almost exactly the same theme.
I know it's probably not going to work, if I try to say things like this, but I'll try to say them anyways. When you are going around saying 'what-if', there is a very great difference between your map of reality, and the territory of reality, which is extremely narrow and stable. Drop your phone, gravity pulls the phone downward, it falls. What if there are aliens and they make the phone rise into the air instead, maybe because they'll be especially amused at violating the rule after you just tried to use it as an example of where you could be confident? Imagine the aliens watching you, imagine their amusement, contemplate how fragile human thinking is and how little you can ever be assured of anything and ought not to be too confident. Then drop the phone and watch it fall. You've now learned something about how reality itself isn't made of what-ifs and reminding oneself to be humble; reality runs on rails stronger than your mind does.
Contemplating this doesn't mean you know the rails, of course, which is why it's so much harder to predict the Future than the past. But if you see that your thoughts are still wildly flailing around what-ifs, it means that they've failed to gel, in some sense, they are not yet bound to reality, because reality has no binding receptors for what-iffery.
The correct thing to do is not to act on your what-ifs that you can't figure out how to refute, but to go on looking for a model which makes narrower predictions than that. If that search fails, forge a model which puts some more numerical distribution on your highly entropic uncertainty, instead of diverting into specific what-ifs. And in the latter case, understand that this probability distribution reflects your ignorance and subjective state of mind, rather than your knowledge of an objective frequency; so that somebody else is allowed to be less ignorant without you shouting "Too confident!" at them. Reality runs on rails as strong as math; sometimes other people will achieve, before you do, the feat of having their own thoughts run through more concentrated rivers of probability, in some domain.
Now, when we are trying to concentrate our thoughts into deeper, narrower rivers that run closer to reality's rails, there is of course the legendary hazard of concentrating our thoughts into the wrong narrow channels that exclude reality. And the great legendary sign of this condition, of course, is the counterexample from Reality that falsifies our model! But you should not in general criticize somebody for trying to concentrate their probability into narrower rivers than yours, for this is the appearance of the great general project of trying to get to grips with Reality, that runs on true rails that are narrower still.
If you have concentrated your probability into different narrow channels than somebody else's, then, of course, you have a more interesting dispute; and you should engage in that legendary activity of trying to find some accessible experimental test on which your nonoverlapping models make different predictions.
Humbali: I do not understand the import of all this vaguely mystical talk.
Eliezer: I'm trying to explain why, when I say that I'm very confident it's possible to build a human-equivalent mind using less computing power than biology has managed to use effectively, and you say, "How can you be so confident, what if you are wrong," it is not unreasonable for me to reply, "Well, kid, this doesn't seem like one of those places where it's particularly important to worry about far-flung ways I could be wrong." Anyone who aspires to learn, learns over a lifetime which sorts of guesses are more likely to go oh-no-wrong in real life, and which sorts of guesses are likely to just work. Less-learned minds will have minds full of what-ifs they can't refute in more places than more-learned minds; and even if you cannot see how to refute all your what-ifs yourself, it is possible that a more-learned mind knows why they are improbable. For one must distinguish possibility from probability.
It is imaginable or conceivable that human brains have such refined algorithms that they are operating at the absolute limits of computational efficiency, or within 10% of it. But if you've spent enough time noticing where Reality usually exercises its sovereign right to yell "Gotcha!" at you, learning which of your assumptions are the kind to blow up in your face and invalidate your final conclusion, you can guess that "Ah, but what if the brain is nearly 100% computationally efficient?" is the sort of what-if that is not much worth contemplating because it is not actually going to be true in real life. Reality is going to confound you in some other way than that.
I mean, maybe you haven't read enough neuroscience and evolutionary biology that you can see from your own knowledge that the proposition sounds massively implausible and ridiculous. But it should hardly seem unlikely that somebody else, more learned in biology, might be justified in having more confidence than you. Phones don't fall up. Reality really is very stable and orderly in a lot of ways, even in places where you yourself are ignorant of that order.
But if "What if aliens are making themselves visible in flying saucers because they want high status and they'll have higher status if they're occasionally observable but never deign to talk with us?" sounds to you like it's totally plausible, and you don't see how someone can be so confident that it's not true - because oh no what if you're wrong and you haven't seen the aliens so how can you know what they're not thinking - then I'm not sure how to lead you into the place where you can dismiss that thought with confidence. It may require a kind of life experience that I don't know how to give people, at all, let alone by having them passively read paragraphs of text that I write; a learned, perceptual sense of which what-ifs have any force behind them. I mean, I can refute that specific scenario, I can put that learned sense into words; but I'm not sure that does me any good unless you learn how to refute it yourself.
Humbali: Can we leave aside all that meta stuff and get back to the object level?
Eliezer: This indeed is often wise.
Humbali: Then here's one way that the minimum computational requirements for general intelligence could be higher than Moravec's argument for the human brain. Since, after, all, we only have one existence proof that general intelligence is possible at all, namely the human brain. Perhaps there's no way to get general intelligence in a computer except by simulating the brain neurotransmitter-by-neurotransmitter. In that case you'd need a lot more computing operations per second than you'd get by calculating the number of potential spikes flowing around the brain! What if it's true? How can you know?
(Modern person: This seems like an obvious straw argument? I mean, would anybody, even at an earlier historical point, actually make an argument like -
Moravec and Eliezer: YES THEY WOULD.)
Eliezer: I can imagine that if we were trying specifically to upload a human that there'd be no easy and simple and obvious way to run the resulting simulation and get a good answer, without simulating neurotransmitter flows in extra detail.
To imagine that every one of these simulated flows is being usefully used in general intelligence and there is no way to simplify the mind design to use fewer computations... I suppose I could try to refute that specifically, but it seems to me that this is a road which has no end unless I can convey the generator of my refutations. Your what-iffery is flung far enough that, if I cannot leave even that much rejection as an exercise for the reader to do on their own without my holding their hand, the reader has little enough hope of following the rest; let them depart now, in indignation shared with you, and save themselves further outrage.
I mean, it will obviously be less obvious to the reader because they will know less than I do about this exact domain, it will justly take more work for the reader to specifically refute you than it takes me to refute you. But I think the reader needs to be able to do that at all, in this example, to follow the more difficult arguments later.
Imaginary Moravec: I don't think it changes my conclusions by an order of magnitude, but some people would worry that, for example, changes of protein expression inside a neuron in order to implement changes of long-term potentiation, are also important to intelligence, and could be a big deal in the brain's real, effectively-used computational costs. I'm curious if you'd dismiss that as well, the same way you dismiss the probability that you'd have to simulate every neurotransmitter molecule?
Eliezer: Oh, of course not. Long-term potentiation suddenly turning out to be a big deal you overlooked, compared to the depolarization impulses spiking around, is very much the sort of thing where Reality sometimes jumps out and yells "Gotcha!" at you.
Humbali: How can you tell the difference?
Eliezer: Experience with Reality yelling "Gotcha!" at myself and historical others.
Humbali: They seem like equally plausible speculations to me!
Eliezer: Really? "What if long-term potentiation is a big deal and computationally important" sounds just as plausible to you as "What if the brain is already close to the wall of making the most efficient possible use of computation to implement general intelligence, and every neurotransmitter molecule matters"?
Humbali: Yes! They're both what-ifs we can't know are false and shouldn't be overconfident about denying!
Eliezer: My tiny feeble mortal mind is far away from reality and only bound to it by the loosest of correlating interactions, but I'm not that unbound from reality.
Moravec: I would guess that in real life, long-term potentiation is sufficiently slow and local that what goes on inside the cell body of a neuron over minutes or hours is not as big of a computational deal as thousands of times that many spikes flashing around the brain in milliseconds or seconds. That's why I didn't make a big deal of it in my own estimate.
Eliezer: Sure. But it is much more the sort of thing where you wake up to a reality-authored science headline saying "Gotcha! There were tiny DNA-activation interactions going on in there at high speed, and they were actually pretty expensive and important!" I'm not saying this exact thing is very probable, just that it wouldn't be out-of-character for reality to say something like that to me, the way it would be really genuinely bizarre if Reality was, like, "Gotcha! The brain is as computationally efficient of a generally intelligent engine as any algorithm can be!"
Moravec: I think we're in agreement about that part, or we would've been, if we'd actually had this conversation in 1988. I mean, I am a competent research roboticist and it is difficult to become one if you are completely unglued from reality.
Eliezer: Then what's with the 2010 prediction for strong AI, and the massive non-sequitur leap from "the human brain is somewhere around 10 trillion ops/sec" to "if we build a 10 trillion ops/sec supercomputer, we'll get strong AI"?
Moravec: Because while it's the kind of Fermi estimate that can be off by an order of magnitude in practice, it doesn't really seem like it should be, I don't know, off by three orders of magnitude? And even three orders of magnitude is just 10 years of Moore's Law. 2020 for strong AI is also a bold and important prediction.
Eliezer: And the year 2000 for strong AI even more so.
Moravec: Heh! That's not usually the direction in which people argue with me.
Eliezer: There's an important distinction between the direction in which people usually argue with you, and the direction from which Reality is allowed to yell "Gotcha!" I wish my future self had kept this more in mind, when arguing with Robin Hanson about how well AI architectures were liable to generalize and scale without a ton of domain-specific algorithmic tinkering for every field of knowledge. I mean, in principle what I was arguing for was various lower bounds on performance, but I sure could have emphasized more loudly that those were lower bounds - well, I did emphasize the lower-bound part, but - from the way I felt when AlphaGo and Alpha Zero and GPT-2 and GPT-3 showed up, I think I must've sorta forgot that myself.
Moravec: Anyways, if we say that I might be up to three orders of magnitude off and phrase it as 2000-2020, do you agree with my prediction then?
Eliezer: No, I think you're just... arguing about the wrong facts, in a way that seems to be unglued from most tracks Reality might follow so far as I currently know? On my view, creating AGI is strongly dependent on how much knowledge you have about how to do it, in a way which almost entirely obviates the relevance of arguments from human biology?
Like, human biology tells us a single not-very-useful data point about how much computing power evolutionary biology needs in order to build a general intelligence, using very alien methods to our own. Then, very separately, there's the constantly changing level of how much cognitive science, neuroscience, and computer science our own civilization knows. We don't know how much computing power is required for AGI for any level on that constantly changing graph, and biology doesn't tell us. All we know is that the hardware requirements for AGI must be dropping by the year, because the knowledge of how to create AI is something that only increases over time.
At some point the moving lines for "decreasing hardware required" and "increasing hardware available" will cross over, which lets us predict that AGI gets built at some point. But we don't know how to graph two key functions needed to predict that date. You would seem to be committing the classic fallacy of searching for your keys under the streetlight where the visibility is better. You know how to estimate how many floating-point operations per second the retina could effectively be using, but this is not the number you need to predict the outcome you want to predict. You need a graph of human knowledge of computer science over time, and then a graph of how much computer science requires how much hardware to build AI, and neither of these graphs are available.
It doesn't matter how many chapters your book spends considering the continuation of Moore's Law or computation in the retina, and I'm sorry if it seems rude of me in some sense to just dismiss the relevance of all the hard work you put into arguing it. But you're arguing the wrong facts to get to the conclusion, so all your hard work is for naught.
Humbali: Now it seems to me that I must chide you for being too dismissive of Moravec's argument. Fine, yes, Moravec has not established with logical certainty that strong AI must arrive at the point where top supercomputers match the human brain's 10 trillion operations per second. But has he not established a reference class, the sort of base rate that good and virtuous superforecasters, unlike yourself, go looking for when they want to anchor their estimate about some future outcome? Has he not, indeed, established the sort of argument which says that if top supercomputers can do only ten million operations per second, we're not very likely to get AGI earlier than that, and if top supercomputers can do ten quintillion operations per second*, we're unlikely not to already have AGI?
(*) In 2021 terms, 10 TPU v4 pods.
Eliezer: With ranges that wide, it'd be more likely and less amusing to hit somewhere inside it by coincidence. But I still think this whole line of thoughts is just off-base, and that you, Humbali, have not truly grasped the concept of a virtuous superforecaster or how they go looking for reference classes and base rates.
Humbali: I frankly think you're just being unvirtuous. Maybe you have some special model of AGI which claims that it'll arrive in a different year or be arrived at by some very different pathway. But is not Moravec's estimate a sort of base rate which, to the extent you are properly and virtuously uncertain of your own models, you ought to regress in your own probability distributions over AI timelines? As you become more uncertain about the exact amounts of knowledge required and what knowledge we'll have when, shouldn't you have an uncertain distribution about AGI arrival times that centers around Moravec's base-rate prediction of 2010?
For you to reject this anchor seems to reveal a grave lack of humility, since you must be very certain of whatever alternate estimation methods you are using in order to throw away this base-rate entirely.
Eliezer: Like I said, I think you've just failed to grasp the true way of a virtuous superforecaster. Thinking a lot about Moravec's so-called 'base rate' is just making you, in some sense, stupider; you need to cast your thoughts loose from there and try to navigate a wilder and less tamed space of possibilities, until they begin to gel and coalesce into narrower streams of probability. Which, for AGI, they probably won't do until we're quite close to AGI, and start to guess correctly how AGI will get built; for it is easier to predict an eventual global pandemic than to say it will start in November of 2019. Even in October of 2019 this cannot be done.
Humbali: Then all this uncertainty must somehow be quantified, if you are to be a virtuous Bayesian; and again, for lack of anything better, the resulting distribution should center on Moravec's base-rate estimate of 2010.
Eliezer: No, that calculation is just basically not relevant here; and thinking about it is making you stupider, as your mind flails in the trackless wilderness grasping onto unanchored air. Things must be 'sufficiently similar' to each other, in some sense, for us to get a base rate on one thing by looking at another thing. Humans making an AGI is just too dissimilar to evolutionary biology making a human brain for us to anchor 'how much computing power at the time it happens' from one to the other. It's not the droid we're looking for; and your attempt to build an inescapable epistemological trap about virtuously calling that a 'base rate' is not the Way.
Imaginary Moravec: If I can step back in here, I don't think my calculation is zero evidence? What we know from evolutionary biology is that a blind alien god with zero foresight accidentally mutated a chimp brain into a general intelligence. I don't want to knock biology's work too much, there's some impressive stuff in the retina, and the retina is just the part of the brain which is in some sense easiest to understand. But surely there's a very reasonable argument that 10 trillion ops/sec is about the amount of computation that evolutionary biology needed; and since evolution is stupid, when we ourselves have that much computation, it shouldn't be that hard to figure out how to configure it.
Eliezer: If that was true, the same theory predicts that our current supercomputers should be doing a better job of matching the agility and vision of spiders. When at some point there's enough hardware that we figure out how to put it together into AGI, we could be doing it with less hardware than a human; we could be doing it with more; and we can't even say that these two possibilities are around equally probable such that our probability distribution should have its median around 2010. Your number is so bad and obtained by such bad means that we should just throw it out of our thinking and start over.
Humbali: This last line of reasoning seems to me to be particularly ludicrous, like you're just throwing away the only base rate we have in favor of a confident assertion of our somehow being more uncertain than that.
Eliezer: Yeah, well, sorry to put it bluntly, Humbali, but you have not yet figured out how to turn your own computing power into intelligence.
- 1999 -
Luke Muehlhauser reading a previous draft of this (only sounding much more serious than this, because Luke Muehlhauser): You know, there was this certain teenaged futurist who made some of his own predictions about AI timelines -
Eliezer: I'd really rather not argue from that as a case in point. I dislike people who screw up something themselves, and then argue like nobody else could possibly be more competent than they were. I dislike even more people who change their mind about something when they turn 22, and then, for the rest of their lives, go around acting like they are now Very Mature Serious Adults who believe the thing that a Very Mature Serious Adult believes, so if you disagree with them about that thing they started believing at age 22, you must just need to wait to grow out of your extended childhood.
Luke Muehlhauser (still being paraphrased): It seems like it ought to be acknowledged somehow.
Eliezer: That's fair, yeah, I can see how someone might think it was relevant. I just dislike how it potentially creates the appearance of trying to slyly sneak in an Argument From Reckless Youth that I regard as not only invalid but also incredibly distasteful. You don't get to screw up yourself and then use that as an argument about how nobody else can do better.
Humbali: Uh, what's the actual drama being subtweeted here?
Eliezer: A certain teenaged futurist, who, for example, said in 1999, "The most realistic estimate for a seed AI transcendence is 2020; nanowar, before 2015."
Humbali: This young man must surely be possessed of some very deep character defect, which I worry will prove to be of the sort that people almost never truly outgrow except in the rarest cases. Why, he's not even putting a probability distribution over his mad soothsaying - how blatantly absurd can a person get?
Eliezer: Dear child ignorant of history, your complaint is far too anachronistic. This is 1999 we're talking about here; almost nobody is putting probability distributions on things, that element of your later subculture has not yet been introduced. Eliezer-2002 hasn't been sent a copy of "Judgment Under Uncertainty" by Emil Gilliam. Eliezer-2006 hasn't put his draft online for "Cognitive biases potentially affecting judgment of global risks". The Sequences won't start until another year after that. How would the forerunners of effective altruism in 1999 know about putting probability distributions on forecasts? I haven't told them to do that yet! We can give historical personages credit when they seem to somehow end up doing better than their surroundings would suggest; it is unreasonable to hold them to modern standards, or expect them to have finished refining those modern standards by the age of nineteen.
Though there's also a more subtle lesson you could learn, about how this young man turned out to still have a promising future ahead of him; which he retained at least in part by having a deliberate contempt for pretended dignity, allowing him to be plainly and simply wrong in a way that he noticed, without his having twisted himself up to avoid a prospect of embarrassment. Instead of, for example, his evading such plain falsification by having dignifiedly wide Very Serious probability distributions centered on the same medians produced by the same basically bad thought processes.
But that was too much of a digression, when I tried to write it up; maybe later I'll post something separately.
- 2004 or thereabouts -
Ray Kurzweil in 2001: I have calculated that matching the intelligence of a human brain requires 2 * 10^16 ops/sec* and this will become available in a $1000 computer in 2023. 26 years after that, in 2049, a $1000 computer will have ten billion times more computing power than a human brain; and in 2059, that computer will cost one cent.
(*) Two TPU v4 pods.
Actual real-life Eliezer in Q&A, when Kurzweil says the same thing in a 2004(?) talk: It seems weird to me to forecast the arrival of "human-equivalent" AI, and then expect Moore's Law to just continue on the same track past that point for thirty years. Once we've got, in your terms, human-equivalent AIs, even if we don't go beyond that in terms of intelligence, Moore's Law will start speeding them up. Once AIs are thinking thousands of times faster than we are, wouldn't that tend to break down the graph of Moore's Law with respect to the objective wall-clock time of the Earth going around the Sun? Because AIs would be able to spend thousands of subjective years working on new computing technology?
Actual Ray Kurzweil: The fact that AIs can do faster research is exactly what will enable Moore's Law to continue on track.
Actual Eliezer (out loud): Thank you for answering my question.
Actual Eliezer (internally): Moore's Law is a phenomenon produced by human cognition and the fact that human civilization runs off human cognition. You can't expect the surface phenomenon to continue unchanged after the deep causal phenomenon underlying it starts changing. What kind of bizarre worship of graphs would lead somebody to think that the graphs were the primary phenomenon and would continue steady and unchanged when the forces underlying them changed massively? I was hoping he'd be less nutty in person than in the book, but oh well.
- 2006 or thereabouts -
Somebody on the Internet: I have calculated the number of computer operations used by evolution to evolve the human brain - searching through organisms with increasing brain size - by adding up all the computations that were done by any brains before modern humans appeared. It comes out to 10^43 computer operations.* AGI isn't coming any time soon!
(*) I forget the exact figure. It was 10^40-something.
Eliezer, sighing: Another day, another biology-inspired timelines forecast. This trick didn't work when Moravec tried it, it's not going to work while Ray Kurzweil is trying it, and it's not going to work when you try it either. It also didn't work when a certain teenager tried it, but please entirely ignore that part; you're at least allowed to do better than him.
Imaginary Somebody: Moravec's prediction failed because he assumed that you could just magically take something with around as much hardware as the human brain and, poof, it would start being around that intelligent -
Eliezer: Yes, that is one way of viewing an invalidity in that argument. Though you do Moravec a disservice if you imagine that he could only argue "It will magically emerge", and could not give the more plausible-sounding argument "Human engineers are not that incompetent compared to biology, and will probably figure it out without more than one or two orders of magnitude of extra overhead."
Somebody: But I am cleverer, for I have calculated the number of computing operations that was used to create and design biological intelligence, not just the number of computing operations required to run it once created!
Eliezer: And yet, because your reasoning contains the word "biological", it is just as invalid and unhelpful as Moravec's original prediction.
Somebody: I don't see why you dismiss my biological argument about timelines on the basis of Moravec having been wrong. He made one basic mistake - neglecting to take into effect the cost to generate intelligence, not just to run it. I have corrected this mistake, and now my own effort to do biologically inspired timeline forecasting should work fine, and must be evaluated on its own merits, de novo.
Eliezer: It is true indeed that sometimes a line of inference is doing just one thing wrong, and works fine after being corrected. And because this is true, it is often indeed wise to reevaluate new arguments on their own merits, if that is how they present themselves. One may not take the past failure of a different argument or three, and try to hang it onto the new argument like an inescapable iron ball chained to its leg. It might be the cause for defeasible skepticism, but not invincible skepticism.
That said, on my view, you are making a nearly identical mistake as Moravec, and so his failure remains relevant to the question of whether you are engaging in a kind of thought that binds well to Reality.
Somebody: And that mistake is just mentioning the word "biology"?
Eliezer: The problem is that the resource gets consumed differently, so base-rate arguments from resource consumption end up utterly unhelpful in real life. The human brain consumes around 20 watts of power. Can we thereby conclude that an AGI should consume around 20 watts of power, and that, when technology advances to the point of being able to supply around 20 watts of power to computers, we'll get AGI?
Somebody: That's absurd, of course. So, what, you compare my argument to an absurd argument, and from this dismiss it?
Eliezer: I'm saying that Moravec's "argument from comparable resource consumption" must be in general invalid, because it Proves Too Much. If it's in general valid to reason about comparable resource consumption, then it should be equally valid to reason from energy consumed as from computation consumed, and pick energy consumption instead to call the basis of your median estimate.
You say that AIs consume energy in a very different way from brains? Well, they'll also consume computations in a very different way from brains! The only difference between these two cases is that you know something about how humans eat food and break it down in their stomachs and convert it into ATP that gets consumed by neurons to pump ions back out of dendrites and axons, while computer chips consume electricity whose flow gets interrupted by transistors to transmit information. Since you know anything whatsoever about how AGIs and humans consume energy, you can see that the consumption is so vastly different as to obviate all comparisons entirely.
You are ignorant of how the brain consumes computation, you are ignorant of how the first AGIs built would consume computation, but "an unknown key does not open an unknown lock" and these two ignorant distributions should not assert much internal correlation between them.
Even without knowing the specifics of how brains and future AGIs consume computing operations, you ought to be able to reason abstractly about a directional update that you would make, if you knew any specifics instead of none. If you did know how both kinds of entity consumed computations, if you knew about specific machinery for human brains, and specific machinery for AGIs, you'd then be able to see the enormous vast specific differences between them, and go, "Wow, what a futile resource-consumption comparison to try to use for forecasting."
(Though I say this without much hope; I have not had very much luck in telling people about predictable directional updates they would make, if they knew something instead of nothing about a subject. I think it's probably too abstract for most people to feel in their gut, or something like that, so their brain ignores it and moves on in the end. I have had life experience with learning more about a thing, updating, and then going to myself, "Wow, I should've been able to predict in retrospect that learning almost any specific fact would move my opinions in that same direction." But I worry this is not a common experience, for it involves a real experience of discovery, and preferably more than one to get the generalization.)
Somebody: All of that seems irrelevant to my novel and different argument. I am not foolishly estimating the resources consumed by a single brain; I'm estimating the resources consumed by evolutionary biology to invent brains!
Eliezer: And the humans wracking their own brains and inventing new AI program architectures and deploying those AI program architectures to themselves learn, will consume computations so utterly differently from evolution that there is no point comparing those consumptions of resources. That is the flaw that you share exactly with Moravec, and that is why I say the same of both of you, "This is a kind of thinking that fails to bind upon reality, it doesn't work in real life." I don't care how much painstaking work you put into your estimate of 10^43 computations performed by biology. It's just not a relevant fact.
Humbali: But surely this estimate of 10^43 cumulative operations can at least be used to establish a base rate for anchoring our -
Eliezer: Oh, for god's sake, shut up. At least Somebody is only wrong on the object level, and isn't trying to build an inescapable epistemological trap by which his ideas must still hang in the air like an eternal stench even after they've been counterargued. Isn't 'but muh base rates' what your viewpoint would've also said about Moravec's 2010 estimate, back when that number still looked plausible?
Humbali: Of course it is evident to me now that my youthful enthusiasm was mistaken; obviously I tried to estimate the wrong figure. As Somebody argues, we should have been estimating the biological computations used to design human intelligence, not the computations used to run it.
I see, now, that I was using the wrong figure as my base rate, leading my base rate to be wildly wrong, and even irrelevant; but now that I've seen this, the clear error in my previous reasoning, I have a new base rate. This doesn't seem obviously to me likely to contain the same kind of wildly invalidating enormous error as before. What, is Reality just going to yell "Gotcha!" at me again? And even the prospect of some new unknown error, which is just as likely to be in either possible direction, implies only that we should widen our credible intervals while keeping them centered on a median of 10^43 operations -
Eliezer: Please stop. This trick just never works, at all, deal with it and get over it. Every second of attention that you pay to the 10^43 number is making you stupider. You might as well reason that 20 watts is a base rate for how much energy the first generally intelligent computing machine should consume.
- 2020 -
OpenPhil: We have commissioned a Very Serious report on a biologically inspired estimate of how much computation will be required to achieve Artificial General Intelligence, for purposes of forecasting an AGI timeline. (Summary of report.) (Full draft of report.) Our leadership takes this report Very Seriously.
Eliezer: Oh, hi there, new kids. Your grandpa is feeling kind of tired now and can't debate this again with as much energy as when he was younger.
Imaginary OpenPhil: You're not that much older than us.
Eliezer: Not by biological wall-clock time, I suppose, but -
OpenPhil: You think thousands of times faster than us?
Eliezer: I wasn't going to say it if you weren't.
OpenPhil: We object to your assertion on the grounds that it is false.
Eliezer: I was actually going to say, you might be underestimating how long I've been walking this endless battlefield because I started really quite young.
I mean, sure, I didn't read Moravec's Mind Children when it came out in 1988. I only read it four years later, when I was twelve. And sure, I didn't immediately afterwards start writing online about Moore's Law and strong AI; I did not immediately contribute my own salvos and sallies to the war; I was not yet a noticed voice in the debate. I only got started on that at age sixteen. I'd like to be able to say that in 1999 I was just a random teenager being reckless, but in fact I was already being invited to dignified online colloquia about the "Singularity" and mentioned in printed books; when I was being wrong back then I was already doing so in the capacity of a minor public intellectual on the topic.
This is, as I understand normie ways, relatively young, and is probably worth an extra decade tacked onto my biological age; you should imagine me as being 52 instead of 42 as I write this, with a correspondingly greater number of visible gray hairs.
A few years later - though still before your time - there was the Accelerating Change Foundation, and Ray Kurzweil spending literally millions of dollars to push Moore's Law graphs of technological progress as the central story about the future. I mean, I'm sure that a few million dollars sounds like peanuts to OpenPhil, but if your own annual budget was a hundred thousand dollars or so, that's a hell of a megaphone to compete with.
If you are currently able to conceptualize the Future as being about something other than nicely measurable metrics of progress in various tech industries, being projected out to where they will inevitably deliver us nice things - that's at least partially because of a battle fought years earlier, in which I was a primary fighter, creating a conceptual atmosphere you now take for granted. A mental world where threshold levels of AI ability are considered potentially interesting and transformative - rather than milestones of new technological luxuries to be checked off on an otherwise invariant graph of Moore's Laws as they deliver flying cars, space travel, lifespan-extension escape velocity, and other such goodies on an equal level of interestingness. I have earned at least a little right to call myself your grandpa.
And that kind of experience has a sort of compounded interest, where, once you've lived something yourself and participated in it, you can learn more from reading other histories about it. The histories become more real to you once you've fought your own battles. The fact that I've lived through timeline errors in person gives me a sense of how it actually feels to be around at the time, watching people sincerely argue Very Serious erroneous forecasts. That experience lets me really and actually update on the history of the earlier mistaken timelines from before I was around; instead of the histories just seeming like a kind of fictional novel to read about, disconnected from reality and not happening to real people.
And now, indeed, I'm feeling a bit old and tired for reading yet another report like yours in full attentive detail. Does it by any chance say that AGI is due in about 30 years from now?
OpenPhil: Our report has very wide credible intervals around both sides of its median, as we analyze the problem from a number of different angles and show how they lead to different estimates -
Eliezer: Unfortunately, the thing about figuring out five different ways to guess the effective IQ of the smartest people on Earth, and having three different ways to estimate the minimum IQ to destroy lesser systems such that you could extrapolate a minimum IQ to destroy the whole Earth, and putting wide credible intervals around all those numbers, and combining and mixing the probability distributions to get a new probability distribution, is that, at the end of all that, you are still left with a load of nonsense. Doing a fundamentally wrong thing in several different ways will not save you, though I suppose if you spread your bets widely enough, one of them may be right by coincidence.
So does the report by any chance say - with however many caveats and however elaborate the probabilistic methods and alternative analyses - that AGI is probably due in about 30 years from now?
OpenPhil: Yes, in fact, our 2020 report's median estimate is 2050; though, again, with very wide credible intervals around both sides. Is that number significant?
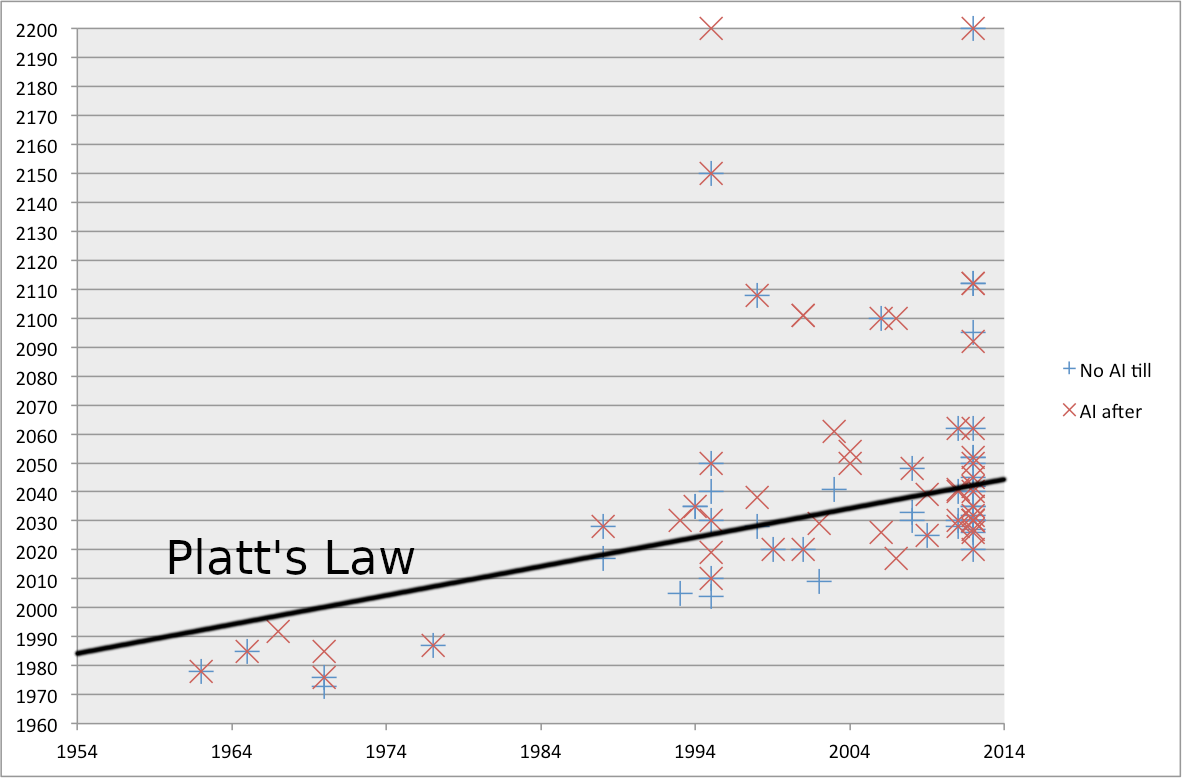
Eliezer: It's a law generalized by Charles Platt, that any AI forecast will put strong AI thirty years out from when the forecast is made. Vernor Vinge referenced it in the body of his famous 1993 NASA speech, whose abstract begins, "Within thirty years, we will have the technological means to create superhuman intelligence. Shortly after, the human era will be ended."
After I was old enough to be more skeptical of timelines myself, I used to wonder how Vinge had pulled out the "within thirty years" part. This may have gone over my head at the time, but rereading again today, I conjecture Vinge may have chosen the headline figure of thirty years as a deliberately self-deprecating reference to Charles Platt's generalization about such forecasts always being thirty years from the time they're made, which Vinge explicitly cites later in the speech.
Or to put it another way: I conjecture that to the audience of the time, already familiar with some previously-made forecasts about strong AI, the impact of the abstract is meant to be, "Never mind predicting strong AI in thirty years, you should be predicting superintelligence in thirty years, which matters a lot more." But the minds of authors are scarcely more knowable than the Future, if they have not explicitly told us what they were thinking; so you'd have to ask Professor Vinge, and hope he remembers what he was thinking back then.
OpenPhil: Superintelligence before 2023, huh? I suppose Vinge still has two years left to go before that's falsified.
Eliezer: Also in the body of the speech, Vinge says, "I'll be surprised if this event occurs before 2005 or after 2030," which sounds like a more serious and sensible way of phrasing an estimate. I think that should supersede the probably Platt-inspired headline figure for what we think of as Vinge's 1993 prediction. The jury's still out on whether Vinge will have made a good call.
Oh, and sorry if grandpa is boring you with all this history from the times before you were around. I mean, I didn't actually attend Vinge's famous NASA speech when it happened, what with being thirteen years old at the time, but I sure did read it later. Once it was digitized and put online, it was all over the Internet. Well, all over certain parts of the Internet, anyways. Which nerdy parts constituted a much larger fraction of the whole, back when the World Wide Web was just starting to take off among early adopters.
But, yeah, the new kids showing up with some graphs of Moore's Law and calculations about biology and an earnest estimate of strong AI being thirty years out from the time of the report is, uh, well, it's... historically precedented.
OpenPhil: That part about Charles Platt's generalization is interesting, but just because we unwittingly chose literally exactly the median that Platt predicted people would always choose in consistent error, that doesn't justify dismissing our work, right? We could have used a completely valid method of estimation which would have pointed to 2050 no matter which year it was tried in, and, by sheer coincidence, have first written that up in 2020. In fact, we try to show in the report that the same methodology, evaluated in earlier years, would also have pointed to around 2050 -
Eliezer: Look, people keep trying this. It's never worked. It's never going to work. 2 years before the end of the world, there'll be another published biologically inspired estimate showing that AGI is 30 years away and it will be exactly as informative then as it is now. I'd love to know the timelines too, but you're not going to get the answer you want until right before the end of the world, and maybe not even then unless you're paying very close attention. Timing this stuff is just plain hard.
OpenPhil: But our report is different, and our methodology for biologically inspired estimates is wiser and less naive than those who came before.
Eliezer: That's what the last guy said, but go on.
OpenPhil: First, we carefully estimate a range of possible figures for the equivalent of neural-network parameters needed to emulate a human brain. Then, we estimate how many examples would be required to train a neural net with that many parameters. Then, we estimate the total computational cost of that many training runs. Moore's Law then gives us 2050 as our median time estimate, given what we think are the most likely underlying assumptions, though we do analyze it several different ways.
Eliezer: This is almost exactly what the last guy tried, except you're using network parameters instead of computing ops, and deep learning training runs instead of biological evolution.
OpenPhil: Yes, so we've corrected his mistake of estimating the wrong biological quantity and now we're good, right?
Eliezer: That's what the last guy thought he'd done about Moravec's mistaken estimation target. And neither he nor Moravec would have made much headway on their underlying mistakes, by doing a probabilistic analysis of that same wrong question from multiple angles.
OpenPhil: Look, sometimes more than one person makes a mistake, over historical time. It doesn't mean nobody can ever get it right. You of all people should agree.
Eliezer: I do so agree, but that doesn't mean I agree you've fixed the mistake. I think the methodology itself is bad, not just its choice of which biological parameter to estimate. Look, do you understand why the evolution-inspired estimate of 10^43 ops was completely ludicrous; and the claim that it was equally likely to be mistaken in either direction, even more ludicrous?
OpenPhil: Because AGI isn't like biology, and in particular, will be trained using gradient descent instead of evolutionary search, which is cheaper. We do note inside our report that this is a key assumption, and that, if it fails, the estimate might be correspondingly wrong -
Eliezer: But then you claim that mistakes are equally likely in both directions and so your unstable estimate is a good median. Can you see why the previous evolutionary estimate of 10^43 cumulative ops was not, in fact, equally likely to be wrong in either direction? That it was, predictably, a directional overestimate?
OpenPhil: Well, search by evolutionary biology is more costly than training by gradient descent, so in hindsight, it was an overestimate. Are you claiming this was predictable in foresight instead of hindsight?
Eliezer: I'm claiming that, at the time, I snorted and tossed Somebody's figure out the window while thinking it was ridiculously huge and absurd, yes.
OpenPhil: Because you'd already foreseen in 2006 that gradient descent would be the method of choice for training future AIs, rather than genetic algorithms?
Eliezer: Ha! No. Because it was an insanely costly hypothetical approach whose main point of appeal, to the sort of person who believed in it, was that it didn't require having any idea whatsoever of what you were doing or how to design a mind.
OpenPhil: Suppose one were to reply: "Somebody" didn't know better-than-evolutionary methods for designing a mind, just as we currently don't know better methods than gradient descent for designing a mind; and hence Somebody's estimate was the best estimate at the time, just as ours is the best estimate now?
Eliezer: Unless you were one of a small handful of leading neural-net researchers who knew a few years ahead of the world where scientific progress was heading - who knew a Thielian 'secret' before finding evidence strong enough to convince the less foresightful - you couldn't have called the jump specifically to gradient descent rather than any other technique. "I don't know any more computationally efficient way to produce a mind than re-evolving the cognitive history of all life on Earth" transitioning over time to "I don't know any more computationally efficient way to produce a mind than gradient descent over entire brain-sized models" is not predictable in the specific part about "gradient descent" - not unless you know a Thielian secret.
But knowledge is a ratchet that usually only turns one way, so it's predictable that the current story changes to somewhere over future time, in a net expected direction. Let's consider the technique currently known as mixture-of-experts (MoE), for training smaller nets in pieces and muxing them together. It's not my mainline prediction that MoE actually goes anywhere - if I thought MoE was actually promising, I wouldn't call attention to it, of course! I don't want to make timelines shorter, that is not a service to Earth, not a good sacrifice in the cause of winning an Internet argument.
But if I'm wrong and MoE is not a dead end, that technique serves as an easily-visualizable case in point. If that's a fruitful avenue, the technique currently known as "mixture-of-experts" will mature further over time, and future deep learning engineers will be able to further perfect the art of training slices of brains using gradient descent and fewer examples, instead of training entire brains using gradient descent and lots of examples.
Or, more likely, it's not MoE that forms the next little trend. But there is going to be something, especially if we're sitting around waiting until 2050. Three decades is enough time for some big paradigm shifts in an intensively researched field. Maybe we'd end up using neural net tech very similar to today's tech if the world ends in 2025, but in that case, of course, your prediction must have failed somewhere else.
The three components of AGI arrival times are available hardware, which increases over time in an easily graphed way; available knowledge, which increases over time in a way that's much harder to graph; and hardware required at a given level of specific knowledge, a huge multidimensional unknown background parameter. The fact that you have no idea how to graph the increase of knowledge - or measure it in any way that is less completely silly than "number of science papers published" or whatever such gameable metric - doesn't change the point that this is a predictable fact about the future; there will be more knowledge later, the more time that passes, and that will directionally change the expense of the currently least expensive way of doing things.
OpenPhil: We did already consider that and try to take it into account: our model already includes a parameter for how algorithmic progress reduces hardware requirements. It's not easy to graph as exactly as Moore's Law, as you say, but our best-guess estimate is that compute costs halve every 2-3 years.
Eliezer: Oh, nice. I was wondering what sort of tunable underdetermined parameters enabled your model to nail the psychologically overdetermined final figure of '30 years' so exactly.
OpenPhil: Eliezer.
Eliezer: Think of this in an economic sense: people don't buy where goods are most expensive and delivered latest, they buy where goods are cheapest and delivered earliest. Deep learning researchers are not like an inanimate chunk of ice tumbling through intergalactic space in its unchanging direction of previous motion; they are economic agents who look around for ways to destroy the world faster and more cheaply than the way that you imagine as the default. They are more eager than you are to think of more creative paths to get to the next milestone faster.
OpenPhil: Isn't this desire for cheaper methods exactly what our model already accounts for, by modeling algorithmic progress?
Eliezer: The makers of AGI aren't going to be doing 10,000,000,000,000 rounds of gradient descent, on entire brain-sized 300,000,000,000,000-parameter models, algorithmically faster than today. They're going to get to AGI via some route that you don't know how to take, at least if it happens in 2040. If it happens in 2025, it may be via a route that some modern researchers do know how to take, but in this case, of course, your model was also wrong.
They're not going to be taking your default-imagined approach algorithmically faster, they're going to be taking an algorithmically different approach that eats computing power in a different way than you imagine it being consumed.
OpenPhil: Shouldn't that just be folded into our estimate of how the computation required to accomplish a fixed task decreases by half every 2-3 years due to better algorithms?
Eliezer: Backtesting this viewpoint on the previous history of computer science, it seems to me to assert that it should be possible to:
For reference, recall that in 2006, Hinton and Salakhutdinov were just starting to publish that, by training multiple layers of Restricted Boltzmann machines and then unrolling them into a "deep" neural network, you could get an initialization for the network weights that would avoid the problem of vanishing and exploding gradients and activations. At least so long as you didn't try to stack too many layers, like a dozen layers or something ridiculous like that. This being the point that kicked off the entire deep-learning revolution.
Your model apparently suggests that we have gotten around 50 times more efficient at turning computation into intelligence since that time; so, we should be able to replicate any modern feat of deep learning performed in 2021, using techniques from before deep learning and around fifty times as much computing power.
OpenPhil: No, that's totally not what our viewpoint says when you backfit it to past reality. Our model does a great job of retrodicting past reality.
Eliezer: How so?
OpenPhil: <Eliezer cannot predict what they will say here.>
Eliezer: I'm not convinced by this argument.
OpenPhil: We didn't think you would be; you're sort of predictable that way.
Eliezer: Well, yes, if I'd predicted I'd update from hearing your argument, I would've updated already. I may not be a real Bayesian but I'm not that incoherent.
But I can guess in advance at the outline of my reply, and my guess is this:
"Look, when people come to me with models claiming the future is predictable enough for timing, I find that their viewpoints seem to me like they would have made garbage predictions if I actually had to operate them in the past without benefit of hindsight. Sure, with benefit of hindsight, you can look over a thousand possible trends and invent rules of prediction and event timing that nobody in the past actually spotlighted then, and claim that things happened on trend. I was around at the time and I do not recall people actually predicting the shape of AI in the year 2020 in advance. I don't think they were just being stupid either.
"In a conceivable future where people are still alive and reasoning as modern humans do in 2040, somebody will no doubt look back and claim that everything happened on trend since 2020; but which trend the hindsighter will pick out is not predictable to us in advance.
"It may be, of course, that I simply don't understand how to operate your viewpoint, nor how to apply it to the past or present or future; and that yours is a sort of viewpoint which indeed permits saying only one thing, and not another; and that this viewpoint would have predicted the past wonderfully, even without any benefit of hindsight. But there is also that less charitable viewpoint which suspects that somebody's theory of 'A coinflip always comes up heads on occasions X' contains some informal parameters which can be argued about which occasions exactly 'X' describes, and that the operation of these informal parameters is a bit influenced by one's knowledge of whether a past coinflip actually came up heads or not.
"As somebody who doesn't start from the assumption that your viewpoint is a good fit to the past, I still don't see how a good fit to the past could've been extracted from it without benefit of hindsight."
OpenPhil: That's a pretty general counterargument, and like any pretty general counterargument it's a blade you should try turning against yourself. Why doesn't your own viewpoint horribly mispredict the past, and say that all estimates of AGI arrival times are predictably net underestimates? If we imagine trying to operate your own viewpoint in 1988, we imagine going to Moravec and saying, "Your estimate of how much computing power it takes to match a human brain is predictably an overestimate, because engineers will find a better way to do it than biology, so we should expect AGI sooner than 2010."
Eliezer: I did tell Imaginary Moravec that his estimate of the minimum computation required for human-equivalent general intelligence was predictably an overestimate; that was right there in the dialogue before I even got around to writing this part. And I also, albeit with benefit of hindsight, told Moravec that both of these estimates were useless for timing the future, because they skipped over the questions of how much knowledge you'd need to make an AGI with a given amount of computing power, how fast knowledge was progressing, and the actual timing determined by the rising hardware line touching the falling hardware-required line.
OpenPhil: We don't see how to operate your viewpoint to say in advance to Moravec, before his prediction has been falsified, "Your estimate is plainly a garbage estimate" instead of "Your estimate is obviously a directional underestimate", especially since you seem to be saying the latter to us, now.
Eliezer: That's not a critique I give zero weight. And, I mean, as a kid, I was in fact talking like, "To heck with that hardware estimate, let's at least try to get it done before then. People are dying for lack of superintelligence; let's aim for 2005." I had a T-shirt spraypainted "Singularity 2005" at a science fiction convention, it's rather crude but I think it's still in my closet somewhere.
But now I am older and wiser and have fixed all my past mistakes, so the critique of those past mistakes no longer applies to my new arguments.
OpenPhil: Uh huh.
Eliezer: I mean, I did try to fix all the mistakes that I knew about, and didn't just, like, leave those mistakes in forever? I realize that this claim to be able to "learn from experience" is not standard human behavior in situations like this, but if you've got to be weird, that's a good place to spend your weirdness points. At least by my own lights, I am now making a different argument than I made when I was nineteen years old, and that different argument should be considered differently.
And, yes, I also think my nineteen-year-old self was not completely foolish at least about AI timelines; in the sense that, for all he knew, maybe you could build AGI by 2005 if you tried really hard over the next 6 years. Not so much because Moravec's estimate should've been seen as a predictable overestimate of how much computing power would actually be needed, given knowledge that would become available in the next 6 years; but because Moravec's estimate should've been seen as almost entirely irrelevant, making the correct answer be "I don't know."
OpenPhil: It seems to us that Moravec's estimate, and the guess of your nineteen-year-old past self, are both predictably vast underestimates. Estimating the computation consumed by one brain, and calling that your AGI target date, is obviously predictably a vast underestimate because it neglects the computation required for training a brainlike system. It may be a bit uncharitable, but we suggest that Moravec and your nineteen-year-old self may both have been motivatedly credulous, to not notice a gap so very obvious.
Eliezer: I could imagine it seeming that way if you'd grown up never learning about any AI techniques except deep learning, which had, in your wordless mental world, always been the way things were, and would always be that way forever.
I mean, it could be that deep learning will still be the bleeding-edge method of Artificial Intelligence right up until the end of the world. But if so, it'll be because Vinge was right and the world ended before 2030, not because the deep learning paradigm was as good as any AI paradigm can ever get. That is simply not a kind of thing that I expect Reality to say "Gotcha" to me about, any more than I expect to be told that the human brain, whose neurons and synapses are 500,000 times further away from the thermodynamic efficiency wall than ATP synthase, is the most efficient possible consumer of computations.
The specific perspective-taking operation needed here - when it comes to what was and wasn't obvious in 1988 or 1999 - is that the notion of spending thousands and millions and billions of times as much computation on a "training" phase, as on an "inference" phase, is something that only came to be seen as Always Necessary after the deep learning revolution took over AI in the late Noughties. Back when Moravec was writing, you programmed a game-tree-search algorithm for chess, and then you ran that code, and it played chess. Maybe you needed to add an opening book, or do a lot of trial runs to tweak the exact values the position evaluation function assigned to knights vs. bishops, but most AIs weren't neural nets and didn't get trained on enormous TPU pods.
Moravec had no way of knowing that the paradigm in AI would, twenty years later, massively shift to a new paradigm in which stuff got trained on enormous TPU pods. He lived in a world where you could only train neural networks a few layers deep, like, three layers, and the gradients vanished or exploded if you tried to train networks any deeper.
To be clear, in 1999, I did think of AGIs as needing to do a lot of learning; but I expected them to be learning while thinking, not to learn in a separate gradient descent phase.
OpenPhil: How could anybody possibly miss anything so obvious? There's so many basic technical ideas and even philosophical ideas about how you do AI which make it supremely obvious that the best and only way to turn computation into intelligence is to have deep nets, lots of parameters, and enormous separate training phases on TPU pods.
Eliezer: Yes, well, see, those philosophical ideas were not as prominent in 1988, which is why the direction of the future paradigm shift was not predictable in advance without benefit of hindsight, let alone timeable to 2006.
You're also probably overestimating how much those philosophical ideas would pinpoint the modern paradigm of gradient descent even if you had accepted them wholeheartedly, in 1988. Or let's consider, say, October 2006, when the Netflix Prize was being run - a watershed occasion where lots of programmers around the world tried their hand at minimizing a loss function, based on a huge-for-the-times 'training set' that had been publicly released, scored on a holdout 'test set'. You could say it was the first moment in the limelight for the sort of problem setup that everybody now takes for granted with ML research: a widely shared dataset, a heldout test set, a loss function to be minimized, prestige for advancing the 'state of the art'. And it was a million dollars, which, back in 2006, was big money for a machine learning prize, garnering lots of interest from competent competitors.
Before deep learning, "statistical learning" was indeed a banner often carried by the early advocates of the view that Richard Sutton now calls the Bitter Lesson, along the lines of "complicated programming of human ideas doesn't work, you have to just learn from massive amounts of data".
But before deep learning - which was barely getting started in 2006 - "statistical learning" methods that took in massive amounts of data, did not use those massive amounts of data to train neural networks by stochastic gradient descent across millions of examples! In 2007, the winning submission to the Netflix Prize was an ensemble predictor that incorporated k-Nearest-Neighbor, a factorization method that repeatedly globally minimized squared error, two-layer Restricted Boltzmann Machines, and a regression model akin to Principal Components Analysis. Which is all 100% statistical learning driven by relatively-big-for-the-time "big data", and 0% GOFAI. But these methods didn't involve enormous massive training phases in the modern sense.
Back then, if you were doing stochastic gradient descent at all, you were doing it on a much smaller neural network. Not so much because you couldn't afford more compute for a larger neural network, but because wider neural networks didn't help you much and deeper neural networks simply didn't work.
Bleeding-edge statistical learning techniques as late as 2007, to make actual use of big data, had to find other ways to make use of huge amounts of data than gradient descent and backpropagation. Though, I mean, not huge amounts of data by modern standards. The winning submission to the Netflix Prize used an ensemble of 107 models - that's not a misprint for 10^7, I actually mean 107 - which models were drawn from half a different model classes, then proliferated with slightly different parameters, averaged together to reduce statistical noise.
A modern kid, perhaps, looks at this and thinks: "If you can afford the compute to train 107 models, why not just train one larger model?" But back then, you see, there just wasn't a standard way to dump massively more compute into something, and get better results back out. The fact that they had 107 differently parameterized models from a half-dozen families averaged together to reduce noise, was about as well as anyone could do in 2007, at putting more effort in and getting better results back out.
OpenPhil: How quaint and archaic! But that was 13 years ago, before time actually got started and history actually started happening in real life. Now we've got the paradigm which will actually be used to create AGI, in all probability; so estimation methods centered on that paradigm should be valid.
Eliezer: The current paradigm is definitely not the end of the line in principle. I guarantee you that the way superintelligences build cognitive engines is not by training enormous neural networks using gradient descent. Gua-ran-tee it.
The fact that you think you now see a path to AGI, is because today - unlike in 2006 - you have a paradigm that is seemingly willing to entertain having more and more food stuffed down its throat without obvious limit (yet). This is really a quite recent paradigm shift, though, and it is probably not the most efficient possible way to consume more and more food.
You could rather strongly guess, early on, that support vector machines were never going to give you AGI, because you couldn't dump more and more compute into training or running SVMs and get arbitrarily better answers; whatever gave you AGI would have to be something else that could eat more compute productively.
Similarly, since the path through genetic algorithms and recapitulating the whole evolutionary history would have taken a lot of compute, it's no wonder that other, more efficient methods of eating compute were developed before then; it was obvious in advance that they must exist, for all that some what-iffed otherwise.
To be clear, it is certain the world will end by more inefficient methods than those that superintelligences would use; since, if superintelligences are making their own AI systems, then the world has already ended.
And it is possible, even, that the world will end by a method as inefficient as gradient descent. But if so, that will be because the world ended too soon for any more efficient paradigm to be developed. Which, on my model, means the world probably ended before say 2040(???). But of course, compared to how much I think I know about what must be more efficiently doable in principle, I think I know far less about the speed of accumulation of real knowledge (not to be confused with proliferation of publications), or how various random-to-me social phenomena could influence the speed of knowledge. So I think I have far less ability to say a confident thing about the timing of the next paradigm shift in AI, compared to the existence and eventuality of such paradigms in the space of possibilities.
OpenPhil: But if you expect the next paradigm shift to happen in around 2040, shouldn't you confidently predict that AGI has to arrive after 2040, because, without that paradigm shift, we'd have to produce AGI using deep learning paradigms, and in that case our own calculation would apply saying that 2040 is relatively early?
Eliezer: No, because I'd consider, say, improved mixture-of-experts techniques that actually work, to be very much within the deep learning paradigm; and even a relatively small paradigm shift like that would obviate your calculations, if it produced a more drastic speedup than halving the computational cost over two years.
More importantly, I simply don't believe in your attempt to calculate a figure of 10,000,000,000,000,000 operations per second for a brain-equivalent deepnet based on biological analogies, or your figure of 10,000,000,000,000 training updates for it. I simply don't believe in it at all. I don't think it's a valid anchor. I don't think it should be used as the median point of a wide uncertain distribution. The first-developed AGI will consume computation in a different fashion, much as it eats energy in a different fashion; and "how much computation an AGI needs to eat compared to a human brain" and "how many watts an AGI needs to eat compared to a human brain" are equally always decreasing with the technology and science of the day.
OpenPhil: Doesn't our calculation at least provide a soft upper bound on how much computation is required to produce human-level intelligence? If a calculation is able to produce an upper bound on a variable, how can it be uninformative about that variable?
Eliezer: You assume that the architecture you're describing can, in fact, work at all to produce human intelligence. This itself strikes me as not only tentative but probably false. I mostly suspect that if you take the exact GPT architecture, scale it up to what you calculate as human-sized, and start training it using current gradient descent techniques... what mostly happens is that it saturates and asymptotes its loss function at not very far beyond the GPT-3 level - say, it behaves like GPT-4 would, but not much better.
This is what should have been told to Moravec: "Sorry, even if your biology is correct, the assumption that future people can put in X amount of compute and get out Y result is not something you really know." And that point did in fact just completely trash his ability to predict and time the future.
The same must be said to you. Your model contains supposedly known parameters, "how much computation an AGI must eat per second, and how many parameters must be in the trainable model for that, and how many examples are needed to train those parameters". Relative to whatever method is actually first used to produce AGI, I expect your estimates to be wildly inapplicable, as wrong as Moravec was about thinking in terms of just using one supercomputer powerful enough to be a brain. Your parameter estimates may not be about properties that the first successful AGI design even has. Why, what if it contains a significant component that isn't a neural network? I realize this may be scarcely conceivable to somebody from the present generation, but the world was not always as it was now, and it will change if it does not end.
OpenPhil: I don't understand how some of your reasoning could be internally consistent even on its own terms. If, according to you, our 2050 estimate doesn't provide a soft upper bound on AGI arrival times - or rather, if our 2050-centered probability distribution isn't a soft upper bound on reasonable AGI arrival probability distributions - then I don't see how you can claim that the 2050-centered distribution is predictably a directional overestimate.
You can either say that our forecasted pathway to AGI or something very much like it would probably work in principle without requiring very much more computation than our uncertain model components take into account, meaning that the probability distribution provides a soft upper bound on reasonably-estimable arrival times, but that paradigm shifts will predictably provide an even faster way to do it before then. That is, you could say that our estimate is both a soft upper bound and also a directional overestimate. Or, you could say that our ignorance of how to create AI will consume more than one order-of-magnitude of increased computation cost above biology -
Eliezer: Indeed, much as your whole proposal would supposedly cost ten trillion times the equivalent computation of the single human brain that earlier biologically-inspired estimates anchored on.
OpenPhil: - in which case our 2050-centered distribution is not a good soft upper bound, but also not predictably a directional overestimate. Don't you have to pick one or the other as a critique, there?
Eliezer: Mmm... there's some justice to that, now that I've come to write out this part of the dialogue. Okay, let me revise my earlier stated opinion: I think that your biological estimate is a trick that never works and, on its own terms, would tell us very little about AGI arrival times at all. Separately, I think from my own model that your timeline distributions happen to be too long.
OpenPhil: Eliezer.
Eliezer: I mean, in fact, part of my actual sense of indignation at this whole affair, is the way that Platt's law of strong AI forecasts - which was in the 1980s generalizing "thirty years" as the time that ends up sounding "reasonable" to would-be forecasters - is still exactly in effect for what ends up sounding "reasonable" to would-be futurists, in fricking 2020 while the air is filling up with AI smoke in the silence of nonexistent fire alarms.
But to put this in terms that maybe possibly you'd find persuasive:
The last paradigm shifts were from "write a chess program that searches a search tree and run it, and that's how AI eats computing power" to "use millions of data samples, but not in a way that requires a huge separate training phase" to "train a huge network for zillions of gradient descent updates and then run it". This new paradigm costs a lot more compute, but (small) large amounts of compute are now available so people are using them; and this new paradigm saves on programmer labor, and more importantly the need for programmer knowledge.
I say with surety that this is not the last possible paradigm shift. And furthermore, the Stack More Layers paradigm has already reduced need for knowledge by what seems like a pretty large bite out of all the possible knowledge that could be thrown away.
So, you might then argue, the world-ending AGI seems more likely to incorporate more knowledge and less brute force, which moves the correct sort of timeline estimate further away from the direction of "cost to recapitulate all evolutionary history as pure blind search without even the guidance of gradient descent" and more toward the direction of "computational cost of one brain, if you could just make a single brain".
That is, you can think of there as being two biological estimates to anchor on, not just one. You can imagine there being a balance that shifts over time from "the computational cost for evolutionary biology to invent brains" to "the computational cost to run one biological brain".
In 1960, maybe, they knew so little about how brains worked that, if you gave them a hypercomputer, the cheapest way they could quickly get AGI out of the hypercomputer using just their current knowledge, would be to run a massive evolutionary tournament over computer programs until they found smart ones, using 10^43 operations.
Today, you know about gradient descent, which finds programs more efficiently than genetic hill-climbing does; so the balance of how much hypercomputation you'd need to use to get general intelligence using just your own personal knowledge, has shifted ten orders of magnitude away from the computational cost of evolutionary history and towards the lower bound of the computation used by one brain. In the future, this balance will predictably swing even further towards Moravec's biological anchor, further away from Somebody on the Internet's biological anchor.
I admit, from my perspective this is nothing but a clever argument that tries to persuade people who are making errors that can't all be corrected by me, so that they can make mostly the same errors but get a slightly better answer. In my own mind I tend to contemplate the Textbook from the Future, which would tell us how to build AI on a home computer from 1995, as my anchor of 'where can progress go', rather than looking to the brain of all computing devices for inspiration.
But, if you insist on the error of anchoring on biology, you could perhaps do better by seeing a spectrum between two bad anchors. This lets you notice a changing reality, at all, which is why I regard it as a helpful thing to say to you and not a pure persuasive superweapon of unsound argument. Instead of just fixating on one bad anchor, the hybrid of biological anchoring with whatever knowledge you currently have about optimization, you can notice how reality seems to be shifting between two biological bad anchors over time, and so have an eye on the changing reality at all. Your new estimate in terms of gradient descent is stepping away from evolutionary computation and toward the individual-brain estimate by ten orders of magnitude, using the fact that you now know a little more about optimization than natural selection knew; and now that you can see the change in reality over time, in terms of the two anchors, you can wonder if there are more shifts ahead.
Realistically, though, I would not recommend eyeballing how much more knowledge you'd think you'd need to get even larger shifts, as some function of time, before that line crosses the hardware line. Some researchers may already know Thielian secrets you do not, that take those researchers further toward the individual-brain computational cost (if you insist on seeing it that way). That's the direction that economics rewards innovators for moving in, and you don't know everything the innovators know in their labs.
When big inventions finally hit the world as newspaper headlines, the people two years before that happens are often declaring it to be fifty years away; and others, of course, are declaring it to be two years away, fifty years before headlines. Timing things is quite hard even when you think you are being clever; and cleverly having two biological anchors and eyeballing Reality's movement between them, is not the sort of cleverness that gives you good timing information in real life.
In real life, Reality goes off and does something else instead, and the Future does not look in that much detail like the futurists predicted. In real life, we come back again to the same wiser-but-sadder conclusion given at the start, that in fact the Future is quite hard to foresee - especially when you are not on literally the world's leading edge of technical knowledge about it, but really even then. If you don't think you know any Thielian secrets about timing, you should just figure that you need a general policy which doesn't get more than two years of warning, or not even that much if you aren't closely non-dismissively analyzing warning signs.
OpenPhil: We do consider in our report the many ways that our estimates could be wrong, and show multiple ways of producing biologically inspired estimates that give different results. Does that give us any credit for good epistemology, on your view?
Eliezer: I wish I could say that it probably beats showing a single estimate, in terms of its impact on the reader. But in fact, writing a huge careful Very Serious Report like that and snowing the reader under with Alternative Calculations is probably going to cause them to give more authority to the whole thing. It's all very well to note the Ways I Could Be Wrong and to confess one's Uncertainty, but you did not actually reach the conclusion, "And that's enough uncertainty and potential error that we should throw out this whole deal and start over," and that's the conclusion you needed to reach.
OpenPhil: It's not clear to us what better way you think exists of arriving at an estimate, compared to the methodology we used - in which we do consider many possible uncertainties and several ways of generating probability distributions, and try to combine them together into a final estimate. A Bayesian needs a probability distribution from somewhere, right?
Eliezer: If somebody had calculated that it currently required an IQ of 200 to destroy the world, that the smartest current humans had an IQ of around 190, and that the world would therefore start to be destroyable in fifteen years according to Moore's Law of Mad Science - then, even assuming Moore's Law of Mad Science to actually hold, the part where they throw in an estimated current IQ of 200 as necessary is complete garbage. It is not the sort of mistake that can be repaired, either. No, not even by considering many ways you could be wrong about the IQ required, or considering many alternative different ways of estimating present-day people's IQs.
The correct thing to do with the entire model is chuck it out the window so it doesn't exert an undue influence on your actual thinking, where any influence of that model is an undue one. And then you just should not expect good advance timing info until the end is in sight, from whatever thought process you adopt instead.
OpenPhil: What if, uh, somebody knows a Thielian secret, or has... narrowed the rivers of their knowledge to closer to reality's tracks? We're not sure exactly what's supposed to be allowed, on your worldview; but wasn't there something at the beginning about how, when you're unsure, you should be careful about criticizing people who are more unsure than you?
Eliezer: Hopefully those people are also able to tell you bold predictions about the nearer-term future, or at least say anything about what the future looks like before the whole world ends. I mean, you don't want to go around proclaiming that, because you don't know something, nobody else can know it either. But timing is, in real life, really hard as a prediction task, so, like... I'd expect them to be able to predict a bunch of stuff before the final hours of their prophecy?
OpenPhil: We're... not sure we see that? We may have made an estimate, but we didn't make a narrow estimate. We gave a relatively wide probability distribution as such things go, so it doesn't seem like a great feat of timing that requires us to also be able to predict the near-term future in detail too?
Doesn't your implicit probability distribution have a median? Why don't you also need to be able to predict all kinds of near-term stuff if you have a probability distribution with a median in it?
Eliezer: I literally have not tried to force my brain to give me a median year on this - not that this is a defense, because I still have some implicit probability distribution, or, to the extent I don't act like I do, I must be acting incoherently in self-defeating ways. But still: I feel like you should probably have nearer-term bold predictions if your model is supposedly so solid, so concentrated as a flow of uncertainty, that it's coming up to you and whispering numbers like "2050" even as the median of a broad distribution. I mean, if you have a model that can actually, like, calculate stuff like that, and is actually bound to the world as a truth.
If you are an aspiring Bayesian, perhaps, you may try to reckon your uncertainty into the form of a probability distribution, even when you face "structural uncertainty" as we sometimes call it. Or if you know the laws of coherence, you will acknowledge that your planning and your actions are implicitly showing signs of weighing some paths through time more than others, and hence display probability-estimating behavior whether you like to acknowledge that or not.
But if you are a wise aspiring Bayesian, you will admit that whatever probabilities you are using, they are, in a sense, intuitive, and you just don't expect them to be all that good. Because the timing problem you are facing is a really hard one, and humans are not going to be great at it - not until the end is near, and maybe not even then.
That - not "you didn't consider enough alternative calculations of your target figures" - is what should've been replied to Moravec in 1988, if you could go back and tell him where his reasoning had gone wrong, and how he might have reasoned differently based on what he actually knew at the time. That reply I now give to you, unchanged.
Humbali: And I'm back! Sorry, I had to take a lunch break. Let me quickly review some of this recent content; though, while I'm doing that, I'll go ahead and give you what I'm pretty sure will be my reaction to it:
Ah, but here is a point that you seem to have not considered at all, namely: what if you're wrong?
Eliezer: That, Humbali, is a thing that should be said mainly to children, of whatever biological wall-clock age, who've never considered at all the possibility that they might be wrong, and who will genuinely benefit from asking themselves that. It is not something that should often be said between grownups of whatever age, as I define what it means to be a grownup. You will mark that I did not at any point say those words to Imaginary Moravec or Imaginary OpenPhil; it is not a good thing for grownups to say to each other, or to think to themselves in Tones of Great Significance (as opposed to as a routine check).
It is very easy to worry that one might be wrong. Being able to see the direction in which one is probably wrong is rather a more difficult affair. And even after we see a probable directional error and update our views, the objection, "But what if you're wrong?" will sound just as forceful as before. For this reason do I say that such a thing should not be said between grownups -
Humbali: Okay, done reading now! Hm... So it seems to me that the possibility that you are wrong, considered in full generality and without adding any other assumptions, should produce a directional shift from your viewpoint towards OpenPhil's viewpoint.
Eliezer (sighing): And how did you end up being under the impression that this could possibly be a sort of thing that was true?
Humbali: Well, I get the impression that you have timelines shorter than OpenPhil's timelines. Is this devastating accusation true?
Eliezer: I consider naming particular years to be a cognitively harmful sort of activity; I have refrained from trying to translate my brain's native intuitions about this into probabilities, for fear that my verbalized probabilities will be stupider than my intuitions if I try to put weight on them. What feelings I do have, I worry may be unwise to voice; AGI timelines, in my own experience, are not great for one's mental health, and I worry that other people seem to have weaker immune systems than even my own. But I suppose I cannot but acknowledge that my outward behavior seems to reveal a distribution whose median seems to fall well before 2050.
Humbali: Okay, so you're more confident about your AGI beliefs, and OpenPhil is less confident. Therefore, to the extent that you might be wrong, the world is going to look more like OpenPhil's forecasts of how the future will probably look, like world GDP doubling over four years before the first time it doubles over one year, and so on.
Eliezer: You're going to have to explain some of the intervening steps in that line of 'reasoning', if it may be termed as such.
Humbali: I feel surprised that I should have to explain this to somebody who supposedly knows probability theory. If you put higher probabilities on AGI arriving in the years before 2050, then, on average, you're concentrating more probability into each year that AGI might possibly arrive, than OpenPhil does. Your probability distribution has lower entropy. We can literally just calculate out that part, if you don't believe me. So to the extent that you're wrong, it should shift your probability distributions in the direction of maximum entropy.
Eliezer: It's things like this that make me worry about whether that extreme cryptivist view would be correct, in which normal modern-day Earth intellectuals are literally not smart enough - in a sense that includes the Cognitive Reflection Test and other things we don't know how to measure yet, not just raw IQ - to be taught more advanced ideas from my own home planet, like Bayes's Rule and the concept of the entropy of a probability distribution. Maybe it does them net harm by giving them more advanced tools they can use to shoot themselves in the foot, since it causes an explosion in the total possible complexity of the argument paths they can consider and be fooled by, which may now contain words like 'maximum entropy'.
Humbali: If you're done being vaguely condescending, perhaps you could condescend specifically to refute my argument, which seems to me to be airtight; my math is not wrong and it means what I claim it means.
Eliezer: The audience is herewith invited to first try refuting Humbali on their own; grandpa is, in actuality and not just as a literary premise, getting older, and was never that physically healthy in the first place. If the next generation does not learn how to do this work without grandpa hovering over their shoulders and prompting them, grandpa cannot do all the work himself. There is an infinite supply of slightly different wrong arguments for me to be forced to refute, and that road does not seem, in practice, to have an end.
Humbali: Or perhaps it's you that needs refuting.
Eliezer, smiling: That does seem like the sort of thing I'd do, wouldn't it? Pick out a case where the other party in the dialogue had made a valid point, and then ask my readers to disprove it, in case they weren't paying proper attention? For indeed in a case like this, one first backs up and asks oneself "Is Humbali right or not?" and not "How can I prove Humbali wrong?"
But now the reader should stop and contemplate that, if they are going to contemplate that at all:
Is Humbali right that generic uncertainty about maybe being wrong, without other extra premises, should increase the entropy of one's probability distribution over AGI, thereby moving out its median further away in time?
Humbali: Are you done?
Eliezer: Hopefully so. I can't see how else I'd prompt the reader to stop and think and come up with their own answer first.
Humbali: Then what is the supposed flaw in my argument, if there is one?
Eliezer: As usual, when people are seeing only their preferred possible use of an argumentative superweapon like 'What if you're wrong?', the flaw can be exposed by showing that the argument Proves Too Much. If you forecasted AGI with a probability distribution with a median arrival time of 50,000 years from now*, would that be very unconfident?
(*) Based perhaps on an ignorance prior for how long it takes for a sapient species to build AGI after it emerges, where we've observed so far that it must take at least 50,000 years, and our updated estimate says that it probably takes around as much more longer than that.
Humbali: Of course; the math says so. Though I think that would be a little too unconfident - we do have some knowledge about how AGI might be created. So my answer is that, yes, this probability distribution is higher-entropy, but that it reflects too little confidence even for me.
I think you're crazy overconfident, yourself, and in a way that I find personally distasteful to boot, but that doesn't mean I advocate zero confidence. I try to be less arrogant than you, but my best estimate of what my own eyes will see over the next minute is not a maximum-entropy distribution over visual snow. AGI happening sometime in the next century, with a median arrival time of maybe 30 years out, strikes me as being about as confident as somebody should reasonably be.
Eliezer: Oh, really now. I think if somebody sauntered up to you and said they put 99% probability on AGI not occurring within the next 1,000 years - which is the sort of thing a median distance of 50,000 years tends to imply - I think you would, in fact, accuse them of brash overconfidence about staking 99% probability on that.
Humbali: Hmmm. I want to deny that - I have a strong suspicion that you're leading me down a garden path here - but I do have to admit that if somebody walked up to me and declared only a 1% probability that AGI arrives in the next millennium, I would say they were being overconfident and not just too uncertain.
Now that you put it that way, I think I'd say that somebody with a wide probability distribution over AGI arrival spread over the next century, with a median in 30 years, is in realistic terms about as uncertain as anybody could possibly be? If you spread it out more than that, you'd be declaring that AGI probably wouldn't happen in the next 30 years, which seems overconfident; and if you spread it out less than that, you'd be declaring that AGI probably would happen within the next 30 years, which also seems overconfident.
Eliezer: Uh huh. And to the extent that I am myself uncertain about my own brashly arrogant and overconfident views, I should have a view that looks more like your view instead?
Humbali: Well, yes! To the extent that you are, yourself, less than totally certain of your own model, you should revert to this most ignorant possible viewpoint as a base rate.
Eliezer: And if my own viewpoint should happen to regard your probability distribution putting its median on 2050 as just one more guesstimate among many others, with this particular guess based on wrong reasoning that I have justly rejected?
Humbali: Then you'd be overconfident, obviously. See, you don't get it, what I'm presenting is not just one candidate way of thinking about the problem, it's the base rate that other people should fall back on to the extent they are not completely confident in their own ways of thinking about the problem, which impose extra assumptions over and above the assumptions that seem natural and obvious to me. I just can't understand the incredible arrogance you use as to be so utterly certain in your own exact estimate that you don't revert it even a little bit towards mine.
I don't suppose you're going to claim to me that you first constructed an even more confident first-order estimate, and then reverted it towards the natural base rate in order to arrive at a more humble second-order estimate?
Eliezer: Ha! No. Not that base rate, anyways. I try to shift my AGI timelines a little further out because I've observed that actual Time seems to run slower than my attempts to eyeball it. I did not shift my timelines out towards 2050 in particular, nor did reading OpenPhil's report on AI timelines influence my first-order or second-order estimate at all, in the slightest; no more than I updated the slightest bit back when I read the estimate of 10^43 ops or 10^46 ops or whatever it was to recapitulate evolutionary history.
Humbali: Then I can't imagine how you could possibly be so perfectly confident that you're right and everyone else is wrong. Shouldn't you at least revert your viewpoints some toward what other people think?
Eliezer: Like, what the person on the street thinks, if we poll them about their expected AGI arrival times? Though of course I'd have to poll everybody on Earth, not just the special case of developed countries, if I thought that a respect for somebody's personhood implied deference to their opinions.
Humbali: Good heavens, no! I mean you should revert towards the opinion, either of myself, or of the set of people I hang out with and who are able to exert a sort of unspoken peer pressure on me; that is the natural reference class to which less confident opinions ought to revert, and any other reference class is special pleading.
And before you jump on me about being arrogant myself, let me say that I definitely regressed my own estimate in the direction of the estimates of the sort of people I hang out with and instinctively regard as fellow tribesmembers of slightly higher status, or "credible" as I like to call them. Although it happens that those people's opinions were about evenly distributed to both sides of my own - maybe not statistically exactly for the population, I wasn't keeping exact track, but in their availability to my memory, definitely, other people had opinions on both sides of my own - so it didn't move my median much. But so it sometimes goes!
But these other people's credible opinions definitely hang emphatically to one side of your opinions, so your opinions should regress at least a little in that direction! Your self-confessed failure to do this at all reveals a ridiculous arrogance.
Eliezer: Well, I mean, in fact, from my perspective, even my complete-idiot sixteen-year-old self managed to notice that AGI was going to be a big deal, many years before various others had been hit over the head with a large-enough amount of evidence that even they started to notice. I was walking almost alone back then. And I still largely see myself as walking alone now, as accords with the Law of Continued Failure: If I was going to be living in a world of sensible people in this future, I should have been living in a sensible world already in my past.
Since the early days more people have caught up to earlier milestones along my way, enough to start publicly arguing with me about the further steps, but I don't consider them to have caught up; they are moving slower than I am still moving now, as I see it. My actual work these days seems to consist mainly of trying to persuade allegedly smart people to not fling themselves directly into lava pits. If at some point I start regarding you as my epistemic peer, I'll let you know. For now, while I endeavor to be swayable by arguments, your existence alone is not an argument unto me.
If you choose to define that with your word "arrogance", I shall shrug and not bother to dispute it. Such appellations are beneath My concern.
Humbali: Fine, you admit you're arrogant - though I don't understand how that's not just admitting you're irrational and wrong -
Eliezer: They're different words that, in fact, mean different things, in their semantics and not just their surfaces. I do not usually advise people to contemplate the mere meanings of words, but perhaps you would be well-served to do so in this case.
Humbali: - but if you're not infinitely arrogant, you should be quantitatively updating at least a little towards other people's positions!
Eliezer: You do realize that OpenPhil itself hasn't always existed? That they are not the only "other people" that there are? An ancient elder like myself, who has seen many seasons turn, might think of many other possible targets toward which he should arguably regress his estimates, if he was going to start deferring to others' opinions this late in his lifespan.
Humbali: You haven't existed through infinite time either!
Eliezer: A glance at the history books should confirm that I was not around, yes, and events went accordingly poorly.
Humbali: So then... why aren't you regressing your opinions at least a little in the direction of OpenPhil's? I just don't understand this apparently infinite self-confidence.
Eliezer: The fact that I have credible intervals around my own unspoken median - that I confess I might be wrong in either direction, around my intuitive sense of how long events might take - doesn't count for my being less than infinitely self-confident, on your view?
Humbali: No. You're expressing absolute certainty in your underlying epistemology and your entire probability distribution, by not reverting it even a little in the direction of the reasonable people's probability distribution, which is the one that's the obvious base rate and doesn't contain all the special other stuff somebody would have to tack on to get your probability estimate.
Eliezer: Right then. Well, that's a wrap, and maybe at some future point I'll talk about the increasingly lost skill of perspective-taking.
OpenPhil: Excuse us, we have a final question. You're not claiming that we argue like Humbali, are you?
Eliezer: Good heavens, no! That's why "Humbali" is presented as a separate dialogue character and the "OpenPhil" dialogue character says nothing of the sort. Though I did meet one EA recently who seemed puzzled and even offended about how I wasn't regressing my opinions towards OpenPhil's opinions to whatever extent I wasn't totally confident, which brought this to mind as a meta-level point that needed making.
OpenPhil: "One EA you met recently" is not something that you should hold against OpenPhil. We haven't organizationally endorsed arguments like Humbali's, any more than you've ever argued that "we have to take AGI risk seriously even if there's only a tiny chance of it" or similar crazy things that other people hallucinate you arguing.
Eliezer: I fully agree. That Humbali sees himself as defending OpenPhil is not to be taken as associating his opinions with those of OpenPhil; just like how people who helpfully try to defend MIRI by saying "Well, but even if there's a tiny chance..." are not thereby making their epistemic sins into mine.
The whole thing with Humbali is a separate long battle that I've been fighting. OpenPhil seems to have been keeping its communication about AI timelines mostly to the object level, so far as I can tell; and that is a more proper and dignified stance than I've assumed here.
Edit (12/23): Holden replies here.