As we explained in our MIRI 2024 Mission and Strategy update, MIRI has pivoted to prioritize policy, communications, and technical governance research over technical alignment research. This follow-up post goes into detail about our communications strategy.
The Objective: Shut it Down[1]
Our objective is to convince major powers to shut down the development of frontier AI systems worldwide before it is too late. We believe that nothing less than this will prevent future misaligned smarter-than-human AI systems from destroying humanity. Persuading governments worldwide to take sufficiently drastic action will not be easy, but we believe this is the most viable path.
Policymakers deal mostly in compromise: they form coalitions by giving a little here to gain a little somewhere else. We are concerned that most legislation intended to keep humanity alive will go through the usual political processes and be ground down into ineffective compromises.
The only way we think we will get strong enough legislation is if policymakers actually get it, if they actually come to understand that building misaligned smarter-than-human systems will kill everyone, including their children. They will pass strong enough laws and enforce them if and only if they come to understand this central truth.
Meanwhile, the clock is ticking. AI labs continue to invest in developing and training more powerful systems. We do not seem to be close to getting the sweeping legislation we need. So while we lay the groundwork for helping humanity to wake up, we also have a less dramatic request. We ask that governments and AI labs install the “off-switch”[2] so that if, on some future day, they decide to shut it all down, they will be able to do so.
We want humanity to wake up and take AI x-risk seriously. We do not want to shift the Overton window, we want to shatter it.
Theory of Change
Now I’ll get into the details of how we’ll go about achieving our objective, and why we believe this is the way to do it. The facets I’ll consider are:
- Audience: To whom are we speaking?
- Message and tone: How do we sound when we speak?
- Channels: How do we reach our audience?
- Artifacts: What, concretely, are we planning to produce?
Audience
The main audience we want to reach is policymakers – the people in a position to enact the sweeping regulation and policy we want – and their staff.
However, narrowly targeting policymakers is expensive and probably insufficient. Some of them lack the background to be able to verify or even reason deeply about our claims. We must also reach at least some of the people policymakers turn to for advice. We are hopeful about reaching a subset of policy advisors who have the skill of thinking clearly and carefully about risk, particularly those with experience in national security. While we would love to reach the broader class of bureaucratically-legible “AI experts,” we don’t expect to convince a supermajority of that class, nor do we think this is a requirement.
We also need to reach the general public. Policymakers, especially elected ones, want to please their constituents, and the more the general public calls for regulation, the more likely that regulation becomes. Even if the specific measures we want are not universally popular, we think it helps a lot to have them in play, in the Overton window.
Most of the content we produce for these three audiences will be fairly basic, 101-level material. However, we don’t want to abandon our efforts to reach deeply technical people as well. They are our biggest advocates, most deeply persuaded, most likely to convince others, and least likely to be swayed by charismatic campaigns in the opposite direction. And more importantly, discussions with very technical audiences are important for putting ourselves on trial. We want to be held to a high standard and only technical audiences can do that.
Message and Tone
Since I joined MIRI as the Communications Manager a year ago, several people have told me we should be more diplomatic and less bold. The way you accomplish political goals, they said, is to play the game. You can’t be too out there, you have to stay well within the Overton window, you have to be pragmatic. You need to hoard status and credibility points, and you shouldn’t spend any on being weird.
While I believe those people were kind and had good intentions, we’re not following their advice. Many other organizations are taking that approach. We’re doing something different. We are simply telling the truth as we know it.
We do this for three reasons.
- Many other organizations are attempting the coalition-building, horse-trading, pragmatic approach. In private, many of the people who work at those organizations agree with us, but in public, they say the watered-down version of the message. We think there is a void at the candid end of the communication spectrum that we are well positioned to fill.
- We think audiences are numb to politics as usual. They know when they’re being manipulated. We have opted out of the political theater, the kayfabe, with all its posing and posturing. We are direct and blunt and honest, and we come across as exactly what we are.
- Probably most importantly, we believe that “pragmatic” political speech won't get the job done. The political measures we’re asking for are a big deal; nothing but the full unvarnished message will motivate the action that is required.
These people who offer me advice often assume that we are rubes, country bumpkins coming to the big city for the first time, simply unaware of how the game is played, needing basic media training and tutoring. They may be surprised to learn that we arrived at our message and tone thoughtfully, having considered all the options. We communicate the way we do intentionally because we think it has the best chance of real success. We understand that we may be discounted or uninvited in the short term, but meanwhile our reputation as straight shooters with a clear and uncomplicated agenda remains intact. We also acknowledge that we are relatively new to the world of communications and policy, we’re not perfect, and it is very likely that we are making some mistakes or miscalculations; we’ll continue to pay attention and update our strategy as we learn.
Channels
So far, we’ve experimented with op-eds, podcasts, and interviews with newspapers, magazines, and radio journalists. It’s hard to measure the effectiveness of these various channels, so we’re taking a wide-spectrum approach. We’re continuing to pursue all of these, and we’d like to expand into books, videos, and possibly film.
We also think in terms of two kinds of content: stable, durable, proactive content – called “rock” content – and live, reactive content that is responsive to current events – called “wave” content. Rock content includes our website, blog articles, books, and any artifact we make that we expect to remain useful for multiple years. Wave content, by contrast, is ephemeral, it follows the 24-hour news cycle, and lives mostly in social media and news.
We envision a cycle in which someone unfamiliar with AI x-risk might hear about us for the first time on a talk show or on social media – wave content – become interested in our message, and look us up to learn more. They might find our website or a book we wrote – rock content – and become more informed and concerned. Then they might choose to follow us on social media or subscribe to our newsletter – wave content again – so they regularly see reminders of our message in their feeds, and so on.
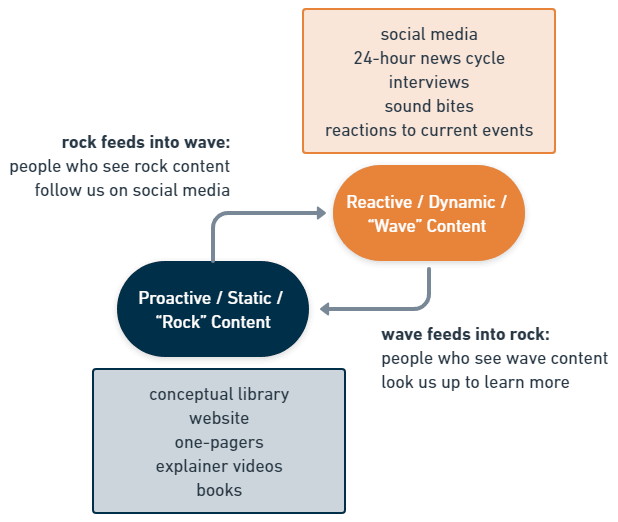
These are pretty standard communications tactics in the modern era. However, mapping out this cycle allows us to identify where we may be losing people, where we need to get stronger, where we need to build out more infrastructure or capacity.
Artifacts
What we find, when we map out that cycle, is that we have a lot of work to do almost everywhere, but that we should probably start with our rock content. That’s the foundation, the bedrock, the place where investment pays off the most over time.
And as such, we are currently exploring several communications projects in this area, including:
- a new MIRI website, aimed primarily at making the basic case for AI x-risk to newcomers to the topic, while also establishing MIRI’s credibility
- a short, powerful book for general audiences
- a detailed online reference exploring the nuance and complexity that we will need to refrain from including in the popular science book
We have a lot more ideas than that, but we’re still deciding which ones we’ll invest in.
What We’re Not Doing
Focus helps with execution; it is also important to say what the comms team is not going to invest in.
We are not investing in grass-roots advocacy, protests, demonstrations, and so on. We don’t think it plays to our strengths, and we are encouraged that others are making progress in this area. Some of us as individuals do participate in protests.
We are not currently focused on building demos of frightening AI system capabilities. Again, this work does not play to our current strengths, and we see others working on this important area. We think the capabilities that concern us the most can’t really be shown in a demo; by the time they can, it will be too late. However, we appreciate and support the efforts of others to demonstrate intermediate or precursor capabilities.
We are not particularly investing in increasing Eliezer’s personal influence, fame, or reach; quite the opposite. We already find ourselves bottlenecked on his time, energy, and endurance. His profile will probably continue to grow as the public pays more and more attention to AI; a rising tide lifts all boats. However, we would like to diversify the public face of MIRI and potentially invest heavily in a spokesperson who is not Eliezer, if we can identify the right candidate.
Execution
The main thing holding us back from realizing this vision is staffing. The communications team is small, and there simply aren’t enough hours in the week to make progress on everything. As such, we’ve been hiring, and we intend to hire more.
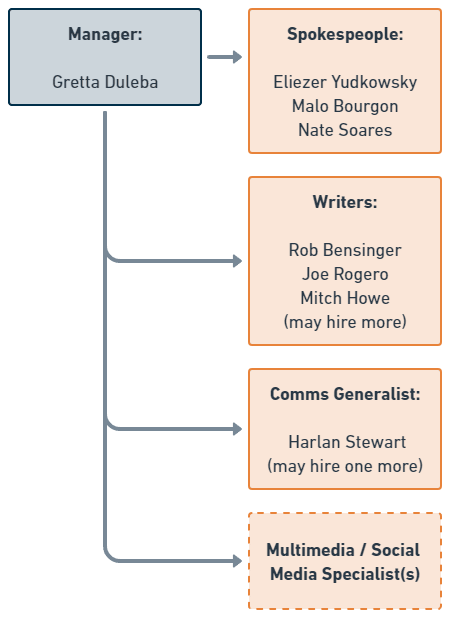
We hope to hire more writers and we may promote someone into a Managing Editor position. We are exploring the idea of hiring or partnering with additional spokespeople, as well as hiring an additional generalist to run projects and someone to specialize in social media and multimedia.
Hiring for these roles is hard because we are looking for people who have top-tier communications skills, know how to restrict themselves to valid arguments, and are aligned with MIRI’s perspective. It’s much easier to find candidates with one or two of those qualities than to find people in the intersection. For these first few key hires we felt it was important to check all the boxes. We hope that once the team is bigger, it may be possible to hire people who write compelling, valid prose and train them on MIRI’s perspective. Our current sense is that it’s easier to explain AI x-risk to a competent, valid writer than it is to explain great writing to someone who already shares our perspective.
How to Help
The best way you can help is to normalize the subject of AI x-risk. We think many people who have been “in the know” about AI x-risk have largely kept silent about it over the years, or only talked to other insiders. If this describes you, we’re asking you to reconsider this policy, and try again (or for the first time) to talk to your friends and family about this topic. Find out what their questions are, where they get stuck, and try to help them through those stuck places.
As MIRI produces more 101-level content on this topic, share that content with your network. Tell us how it performs. Tell us if it actually helps, or where it falls short. Let us know what you wish we would produce next. (We're especially interested in stories of what actually happened, not just considerations of what might happen, when people encounter our content.)
Going beyond networking, please vote with AI x-risk considerations in mind.
If you are one of those people who has great communication skills and also really understands x-risk, come and work for us! Or share our job listings with people you know who might fit.
Subscribe to our newsletter. There’s a subscription form on our Get Involved page.
And finally, later this year we’ll be fundraising for the first time in five years, and we always appreciate your donations.
Thank you for reading and we look forward to your feedback.
- ^
We remain committed to the idea that failing to build smarter-than-human systems someday would be tragic and would squander a great deal of potential. We want humanity to build those systems, but only once we know how to do so safely.
- ^
By “off-switch” we mean that we would like labs and governments to plan ahead, to implement international AI compute governance frameworks and controls sufficient for halting the development of any dangerous AI development activity, and streamlined functional processes for doing so.
1.1. The adoption of such laws is long way
Usually, it is a centuries-long path: Court decisions -> Actual enforcement of decisions -> Substantive law -> Procedures -> Codes -> Declaration then Conventions -> Codes.
Humanity does not have this much time, it is worth focusing on real results that people can actually see. It might be necessary to build some simulations to understand which behavior is irresponsible.
Where is the line between creating a concept of what is socially dangerous and what are the ways to escape responsibility?
As a legal analogy, I would like to draw attention to the criminal case of Tornado Cash.
https://uitspraken.rechtspraak.nl/details?id=ECLI:NL:RBOBR:2024:2069
The developer created and continued to improve an unstoppable program that possibly changed the structure of public transactions forever. Look where the line is drawn there. Can a similar system be devised concerning the projection of existential risks?
1.2. The difference between substantive law and actual law on the ground, especially in countries built on mysticism and manipulation. Each median group of voters creates its irrational picture of the world within each country. You do not need to worry about floating goals.
There are enough people in the world in a different information bubbles than you, so you can be sure that there are actors with values opposite to yours.
1.3. Their research can be serious, but the worldview simplified and absurd. At the same time, resources can be extensive enough for technical workers to perform their duties properly.
2.1. There is no possibility of ideologically influencing all people simultaneously and all systems.
2.2. If I understand you correctly, more than 10 countries can spend huge sums on creating AI to accelerate solving scientific problems. Many of these countries are constantly struggling for their integrity, security, solving national issues, re-election of leaders, gaining benefits, fulfilling the sacred desires of populations, class, other speculative or even conspiratorial theories. Usually, even layers of dozens of theories.
2.3. Humanity stands on the brink of new searches for the philosopher's stone, and for this, they are ready to spend enormous resources. For example, the quantum decryption of old Satoshi wallets plus genome decryption can create the illusion of the possibility of using GAI to solve the main directions of any transhumanist’s alhimists desires, to give the opportunity to defeat death within the lifetime of this or the next two generations. Why should a conditional billionaire and/or state leader refuse this?
Or, as proposed here, the creation of a new super IQ population, again, do not forget that some of the beliefs can be antagonistic.
Even now, from the perspective of AI, predicting the weather in 2100 is somehow easier than in 2040. Currently, there are about 3-4 countries that can create Wasteland-type weather, they partially come into confrontation approximately every five years. Each time, this is a tick towards a Wasteland with a probability of 1-5%. If this continues, the probability of Wasteland-type weather by 2040 will be:
1−0.993=0.0297011 - 0.99^3 = 0.0297011−0.993=0.029701
1−0.953=0.1426251 - 0.95^3 = 0.1426251−0.953=0.142625
By 2100, if nothing changes:
1−0.9915=0.13991 - 0.99^{15} = 0.13991−0.9915=0.1399
1−0.9515=0.46321 - 0.95^{15} = 0.46321−0.9515=0.4632
(A year ago, my predictions were more pessimistic as I was in an information field that presented arguments for the Wasteland scenario in the style of "we'll go to heaven, and the rest will just die." Now I off that media =) to be less realistic, Now it seems that this will be more related to presidential cycles and policy, meaning they will occur not every year, but once every 5 years, as I mentioned earlier, quite an optimistic forecast)
Nevertheless, we have many apocalyptic scenarios: nuclear, pandemic, ecological (the latter is exacerbated by the AI problem, as it will be much easier to gather structures and goals that are antagonistic in aims).
3. Crisis of rule of law
In world politics, there has been a rollback of legal institutions since 2016 (see UN analytics). These show crisis of common values. Even without the AI problem, this usually indicates either the construction of a new equilibrium or falling into chaos. I am a pessimist here and believe that in the absence of normalized common values, information bubbles due to the nature of hysteria become antagonistic (simply put, wilder information flows win, more emotional and irrational). But vice verse this is a moment where MIRI could inject value that existential safety is very important. Especially now cause any injection in out doom clock bottom could create effect that MIRI solved it
4. Problems of Detecting AI Threats
4.1. AI problems are less noticeable than nuclear threats (how to detect these clusters, are there any effective methods?).
4.2. Threat detection is more blurred, identifying dangerous clusters is difficult. The possibility of decentralized systems, like blockchain, and their impact on security. (decentralized computing is rapidly developing, there is progress in superconductors, is this a problem from the perspective of AI security detection?).
Questions about the "Switch off" Technology
5.1. What should a program with a "switch" look like? What is its optimal structure:
a) Proprietary software, (which blocks, functions are recommended to be closed from any distribution)
b) Close/Open API, (what functions can MIRI or other laboratories provide, but with the ability to turn off at any moment, for example, enterprises like OpenAI)
c) Open source with constant updates, (open libraries, but which require daily updates to create the possibility of remotely disabling research code)
d) Open code, (there is an assumption that with open code there is less chance that AI will come into conflict with other AIs, AI users with other AI users, open code can provide additional chances that the established equilibrium between different actors will be found, and they will not mutually annihilate each other. Because they could better in prediction each other behavior)
5.2. The possibility of using multi-signatures and other methods.
How should the button work? Should such a button and its device be open information? Of another code structure? another language? Analogues tech
Are there advantages or disadvantages of shutdown buttons, are there recommendations like at least one out of N pressed, which system seems the most sustainable?
5.3. Which method is the most effective?
Benefits and Approval
6.1. What benefits will actors gain by following recommendations? Leaders of most countries make decisions not only and not so much from their own perspective, but from the irrational desires of their sources of power, built on dozens of other, usually non-contradictory but different values.
6.2. Possible forms of approval and assistance in generating values. Help to defend ecology activists to defend from energy crisis? (from my point of view AI development not take our atoms, but will take our energy, water, sun, etc)
6.3. Examples of large ‘switch off’ projects, for AI infrastructure with enough GPU, electricity, like analogies nuclear power plants but for AI. If you imagine such objects plants what rods for reactions should be, how to pull them out, what "explosives" over which pits should be laid to dump all this into acid or another method of safe destroying
7.1. Questions of approval and material assistance for such enterprises. What are the advantages of developing such institutions under MIRI control compared to
7.2. The hidden maintenance of gray areas on the international market. Why is the maintenance of the gray segment less profitable than cooperation with MIRI from the point of view of personal goals, freedom, local goals, and the like?
Trust and Bluff
8.1. How can you be sure of the honesty of the statements? MIRI that it is not a double game. And that these are not just declarative goals without any real actions? From my experience, I can say that neither in poker bot cases nor in the theft of money using AI in the blockchain field did I feel any feedback from the Future Life Institute project. To go far, I did not even receive a single like from reposts on Twitter. There were no automatic responses to emails, etc. And in this, I agree with Matthew Barnett that there is a problem with effectiveness.
What to present to the public? What help can be provided? Help in UI analytics? Help in investigating specific cases of violations using AI?
For example, I have a problem where I need for consumer protection to raise half a million pounds against AI that stole money through low liquidity trading on Binance, how can I do this?
https://www.linkedin.com/posts/petr-andreev-841953198_crypto-and-ai-threat-summary-activity-7165511031920836608-K2nF?utm_source=share&utm_medium=member_desktop
https://www.linkedin.com/posts/petr-andreev-841953198_binances-changpeng-zhao-to-get-36-months-activity-7192633838877949952-3cmE?utm_source=share&utm_medium=member_desktop
I tried writing letters to the institute and to 80,000 hours, zero responses
SEC, Binance, and a bunch of regulators. They write no licenses, okay no. But why does and 80,000 generally not respond? I do not understand.
8.2. Research in open-source technologies shows greater convergence of trust. Open-source programs can show greater convergence in cooperation due to the simpler idea of collaboration and solving the prisoner's dilemma problem not only through past statistics of another being but also through its open-to-collaboration structure. In any case, GAI will eventually appear, possibly open monitoring of each other's systems will allow AI users not to annihilate each other.
8.3. Comparison with the game theory of the Soviet-Harvard school and the need for steps towards security. The current game theory is largely built on duel-like representations of game theory, where damage to the opponent is an automatic victory, and many systems at the local level continue to think they are there.
Therefore, it is difficult for them to believe in the mutual benefit of systems, that it is about WIN-WIN, cooperation, and not empty talk or just a scam for redistribution of influence and media manipulation.
AI Dangers
9.1. What poses a greater danger: multiple AIs, two powerful AIs, or one actor with a powerful AI?
9.2. Open-source developments in the blockchain field can be both safe and dangerous? Are there any reviews?
this is nice etherium foundation list of articles:
https://docs.google.com/spreadsheets/d/1POtuj3DtF3A-uwm4MtKvwNYtnl_PW6DPUYj6x7yJUIs/edit#gid=1299175463
what do you think about:
Open Problems in Cooperative AI, Cooperative AI: machines must learn to find common ground, etc articles?
9.3. Have you considered including the AI problem in the list of Universal jurisdiction https://en.wikipedia.org/wiki/Universal_jurisdiction
Currently, there are no AI problems or, in general, existential crimes against humanity. Perhaps it is worth joining forces with opponents of eugenics, eco-activists, nuclear alarmists, and jointly prescribing and adding crimes against existential risks (to prevent the irresponsible launch of projects that with probabilities of 0.01%+ can cause severe catastrophes, humanity avoided the Oppenheimer risk with the hydrogen bomb, but not with Chernobyl, and we do not want giga-projects to continue allowing probabilities of human extinction, but treated it with neglect for local goals).
In any case, introducing the universal jurisdiction nature of such crimes can help in finding the “off” button for the project if it is already launched by attracting the creators of a particular dangerous object. This category allow states or international organizations to claim criminal jurisdiction over an accused person regardless of where the alleged crime was committed, and regardless of the accused's nationality, country of residence, or any other relation to the prosecuting entity
9.4. And further the idea with licensing, to force actors to go through the verification system on the one hand, and on the other, to ensure that any technology is refined and becomes publicly available.
https://uitspraken.rechtspraak.nl/details?id=ECLI:NL:RBOVE:2024:2078
https://uitspraken.rechtspraak.nl/details?id=ECLI:NL:RBOVE:2024:2079
A license is very important to defend a business, its CEO, and colleagues from responsibility. Near-worldwide monopolist operators should work more closely to defend the rights of their average consumer to prevent increased regulation. Industries should establish direct contracts with professional actors in their fields in a B2B manner to avoid compliance risks with consumers.
Such organisation as MIRI could be strong experts that could check AI companies for safety especially they large enough to create existential risk or by opposite penalties and back of all sums that people accidentally lost from too weak to common AI attacks frameworks. People need to see simple show of their defence against AI and help from MIRI, 80000 and other effective altruist especially against AI bad users that already misalignment and got 100kk+ of dollars. It is enough to create decentralized if not now than in next 10 years
Examples and Suggestions
10.1. Analogy with the criminal case of Tornado Cash. In the Netherlands, there was a trial against a software developer who created a system that allows decentralized perfect unstoppable crime. It specifically records the responsibility of this person due to his violation of financial world laws. Please note if it can be somehow adapted for AI safety risks, where lines and red flags.
10.2. Proposals for games/novels. What are the current simple learning paths, in my time it was HPMOR -> lesswrong.ru -> lesswrong.com.
At present, Harry Potter is already outdated for the new generation, what are the modern games/stories about AI safety, how to further direct? How about an analogue of Khan Academy for schoolchildren? MIT courses on this topic?
Thank you for your attention. I would appreciate it if you could point out any mistakes I have made and provide answers to any questions. While I am not sure if I can offer a prize for the best answer, I am willing to donate $100 to an effective fund of your choice for the best engagement response.
I respect and admire all of you for the great work you do for the sustainability of humanity!
I think my model of AI causing increasing amounts of trouble in the world, eventually even existential risk for humanity, doesn't look like a problem which is well addressed by an 'off switch'. To me, the idea of an 'off switch' suggests that there will be a particular group (e.g. an AI company) which is running a particular set of models on a particular datacenter. Some alarm is triggered and either the company or their government decides to shut down the company's datacenter.
I anticipate that, despite the large companies being ahead in AI technology, the... (read more)