About nine months ago, I and three friends decided that AI had gotten good enough to monitor large codebases autonomously for security problems. We started a company around this, trying to leverage the latest AI models to create a tool that could replace at least a good chunk of the value of human pentesters. We have been working on this project since June 2024.
Within the first three months of our company's existence, Claude 3.5 sonnet was released. Just by switching the portions of our service that ran on gpt-4o, our nascent internal benchmark results immediately started to get saturated. I remember being surprised at the time that our tooling not only seemed to make fewer basic mistakes, but also seemed to qualitatively improve in its written vulnerability descriptions and severity estimates. It was as if the models were better at inferring the intent and values behind our prompts, even from incomplete information.
As it happens, there are ~basically no public benchmarks for security research. There are "cybersecurity" evals that ask models questions about isolated blocks of code, or "CTF" evals that give a model an explicit challenge description and shell access to a <1kLOC web application. But nothing that gets at the hard parts of application pentesting for LLMs, which are 1. Navigating a real repository of code too large to put in context, 2. Inferring a target application's security model, and 3. Understanding its implementation deeply enough to learn where that security model is broken. For these reasons I think the task of vulnerability identification serves as a good litmus test for how well LLMs are generalizing outside of the narrow software engineering domain.
Since 3.5-sonnet, we have been monitoring AI model announcements, and trying pretty much every major new release that claims some sort of improvement. Unexpectedly by me, aside from a minor bump with 3.6 and an even smaller bump with 3.7, literally none of the new models we've tried have made a significant difference on either our internal benchmarks or in our developers' ability to find new bugs. This includes the new test-time OpenAI models.
At first, I was nervous to report this publicly because I thought it might reflect badly on us as a team. Our scanner has improved a lot since August, but because of regular engineering, not model improvements. It could've been a problem with the architecture that we had designed, that we weren't getting more milage as the SWE-Bench scores went up.
But in recent months I've spoken to other YC founders doing AI application startups and most of them have had the same anecdotal experiences: 1. o99-pro-ultra announced, 2. Benchmarks look good, 3. Evaluated performance mediocre. This is despite the fact that we work in different industries, on different problem sets. Sometimes the founder will apply a cope to the narrative ("We just don't have any PhD level questions to ask"), but the narrative is there.
I have read the studies. I have seen the numbers. Maybe LLMs are becoming more fun to talk to, maybe they're performing better on controlled exams. But I would nevertheless like to submit, based off of internal benchmarks, and my own and colleagues' perceptions using these models, that whatever gains these companies are reporting to the public, they are not reflective of economic usefulness or generality. They are not reflective of my Lived Experience or the Lived Experience of my customers. In terms of being able to perform entirely new tasks, or larger proportions of users' intellectual labor, I don't think they have improved much since August.
Depending on your perspective, this is good news! Both for me personally, as someone trying to make money leveraging LLM capabilities while they're too stupid to solve the whole problem, and for people worried that a quick transition to an AI-controlled economy would present moral hazards.
At the same time, there's an argument that the disconnect in model scores and the reported experiences of highly attuned consumers is a bad sign. If the industry can't figure out how to measure even the intellectual ability of models now, while they are mostly confined to chatrooms, how the hell is it going to develop metrics for assessing the impact of AIs when they're doing things like managing companies or developing public policy? If we're running into the traps of Goodharting before we've even delegated the messy hard parts of public life to the machines, I would like to know why.
Are the AI labs just cheating?
AI lab founders believe they are in a civilizational competition for control of the entire future lightcone, and will be made Dictator of the Universe if they succeed. Accusing these founders of engaging in fraud to further these purposes is quite reasonable. Even if you are starting with an unusually high opinion of tech moguls, you should not expect them to be honest sources on the performance of their own models in this race. There are very powerful short term incentives to exaggerate capabilities or selectively disclose favorable capabilities results, if you can get away with it. Investment is one, but attracting talent and winning the (psychologically impactful) prestige contests is probably just as big a motivator. And there is essentially no legal accountability compelling labs to be transparent or truthful about benchmark results, because nobody has ever been sued or convicted of fraud for training on a test dataset and then reporting that performance to the public. If you tried, any such lab could still claim to be telling the truth in a very narrow sense because the model "really does achieve that performance on that benchmark". And if first-order tuning on important metrics could be considered fraud in a technical sense, then there are a million other ways for the team responsible for juking the stats to be slightly more indirect about it.
In the first draft of this essay, I followed the above paragraph up with a statement like "That being said, it's impossible for all of the gains to be from cheating, because some benchmarks have holdout datasets." There are some recent private benchmarks such as SEAL that seem to be showing improvements[1]. But every single benchmark that OpenAI and Anthropic have accompanied their releases with has had a test dataset publicly available. The only exception I could come up with was the ARC-AGI prize, whose highest score on the "semi-private" eval was achieved by o3, but which nevertheless has not done a publicized evaluation of either Claude 3.7 Sonnet, or DeepSeek, or o3-mini. And on o3 proper:

So maybe there's no mystery: The AI lab companies are lying, and when they improve benchmark results it's because they have seen the answers before and are writing them down. In a sense this would be the most fortunate answer, because it would imply that we're not actually that bad at measuring AGI performance; we're just facing human-initiated fraud. Fraud is a problem with people and not an indication of underlying technical difficulties.
I'm guessing this is true in part but not in whole.
Are the benchmarks not tracking usefulness?
Suppose the only thing you know about a human being is that they scored 160 on Raven's progressive matrices (an IQ test).[2] There are some inferences you can make about that person: for example, higher scores on RPM are correlated with generally positive life outcomes like higher career earnings, better health, and not going to prison.
You can make these inferences partly because in the test population, scores on the Raven's progressive matrices test are informative about humans' intellectual abilities on related tasks. Ability to complete a standard IQ test and get a good score gives you information about not just the person's "test-taking" ability, but about how well the person performs in their job, whether or not the person makes good health decisions, whether their mental health is strong, and so on.
Critically, these correlations did not have to be robust in order for the Raven's test to become a useful diagnostic tool. Patients don't train for IQ tests, and further, the human brain was not deliberately designed to achieve a high score on tests like RPM. Our high performance on tests like these (relative to other species) was something that happened incidentally over the last 50,000 years, as evolution was indirectly tuning us to track animals, irrigate crops, and win wars.
This is one of those observations that feels too obvious to make, but: with a few notable exceptions, almost all of our benchmarks have the look and feel of standardized tests. By that I mean each one is a series of academic puzzles or software engineering challenges, each challenge of which you can digest and then solve in less than a few hundred tokens. Maybe that's just because these tests are quicker to evaluate, but it's as if people have taken for granted that an AI model that can get an IMO gold medal is gonna have the same capabilities as Terence Tao. "Humanity's Last Exam" is thus not a test of a model's ability to finish Upwork tasks, or complete video games, or organize military campaigns, it's a free response quiz.
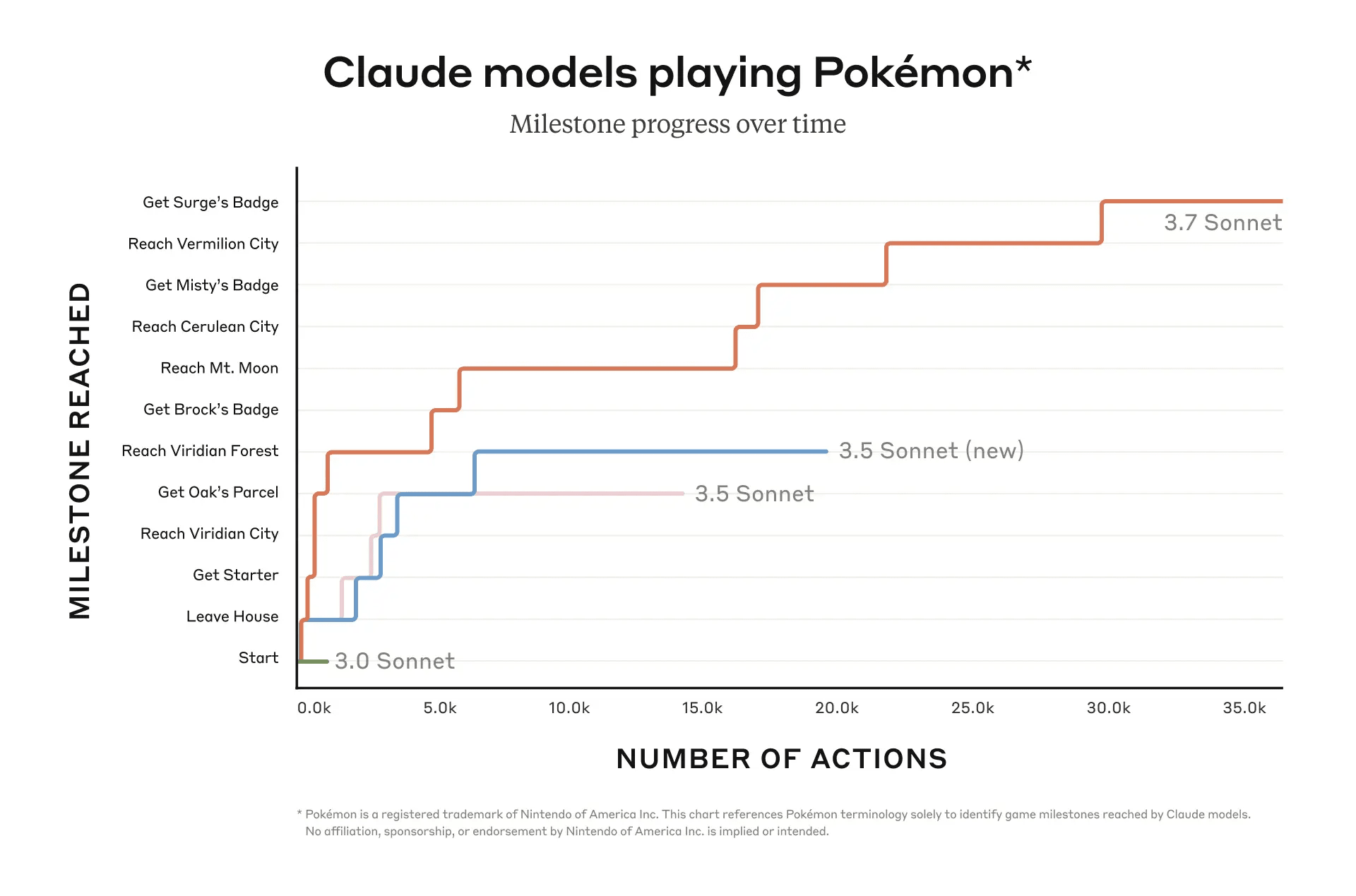
I can't do any of the Humanity's Last Exam test questions, but I'd be willing to bet today that the first model that saturates HLE will still be unemployable as a software engineer. HLE and benchmarks like it are cool, but they fail to test the major deficits of language models, like how they can only remember things by writing them down onto a scratchpad like the memento guy. Claude Plays Pokemon is an overused example, because video games involve a synthesis of a lot of human-specific capabilities, but the task fits as one where you need to occasionally recall things you learned thirty minutes ago. The results are unsurprisingly bad.
Personally, when I want to get a sense of capability improvements in the future, I'm going to be looking almost exclusively at benchmarks like Claude Plays Pokemon. I'll still check out the SEAL leaderboard to see what it's saying, but the deciding factor for my AI timelines will be my personal experiences in Cursor, and how well LLMs are handling long running tasks similar to what you would be asking an employee. Everything else is too much noise.
Are the models smart, but bottlenecked on alignment?
Let me give you a bit of background on our business before I make this next point.
As I mentioned, my company uses these models to scan software codebases for security problems. Humans who work on this particular problem domain (maintaining the security of shipped software) are called AppSec engineers.
As it happens, most AppSec engineers at large corporations have a lot of code to secure. They are desperately overworked. The question the typical engineer has to answer is not "how do I make sure this app doesn't have vulnerabilities" but "how do I manage, sift through, and resolve the overwhelming amount of security issues already live in our 8000 product lines". If they receive an alert, they want it to be affecting an active, ideally-internet-reachable production service. Anything less than that means either too many results to review, or the security team wasting limited political capital to ask developers to fix problems that might not even have impact.
So naturally, we try to build our app so that it only reports problems affecting an active, ideally-internet-reachable production service. However, if you merely explain these constraints to the chat models, they'll follow your instructions sporadically. For example, if you tell them to inspect a piece of code for security issues, they're inclined to respond as if you were a developer who had just asked about that code in the ChatGPT UI, and so will speculate about code smells or near misses. Even if you provide a full, written description of the circumstances I just outlined, pretty much every public model will ignore your circumstances and report unexploitable concatenations into SQL queries as "dangerous".
It's not that the AI model thinks that it's following your instructions and isn't. The LLM will actually say, in the naive application, that what it's reporting is a "potential" problem and that it might not be validated. I think what's going on is that large language models are trained to "sound smart" in a live conversation with users, and so they prefer to highlight possible problems instead of confirming that the code looks fine, just like human beings do when they want to sound smart.
Every LLM wrapper startup runs into constraints like this. When you're a person interacting with a chat model directly, sycophancy and sophistry are a minor nuisance, or maybe even adaptive. When you're a team trying to compose these models into larger systems (something necessary because of the aforementioned memory issue), wanting-to-look-good cascades into breaking problems. Smarter models might solve this, but they also might make the problem harder to detect, especially as the systems they replace become more complicated and harder to verify the outputs of.
There will be many different ways to overcome these flaws. It's entirely possible that we fail to solve the core problem before someone comes up with a way to fix the outer manifestations of the issue.
I think doing so would be a mistake. These machines will soon become the beating hearts of the society in which we live. The social and political structures they create as they compose and interact with each other will define everything we see around us. It's important that they be as virtuous as we can make them.
- Though even this is not as strong as it seems on first glance. If you click through, you can see that most of the models listed in the Top 10 for everything except the tool use benchmarks were evaluated after the benchmark was released. And both of the Agentic Tool Use benchmarks (which do not suffer this problem) show curiously small improvements in the last 8 months. ↩︎
- Not that they told you they scored that, in which case it might be the most impressive thing about them, but that they did. ↩︎
My lived experience is that AI-assisted-coding hasn't actually improved my workflow much since o1-preview, although other people I know have reported differently.