Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
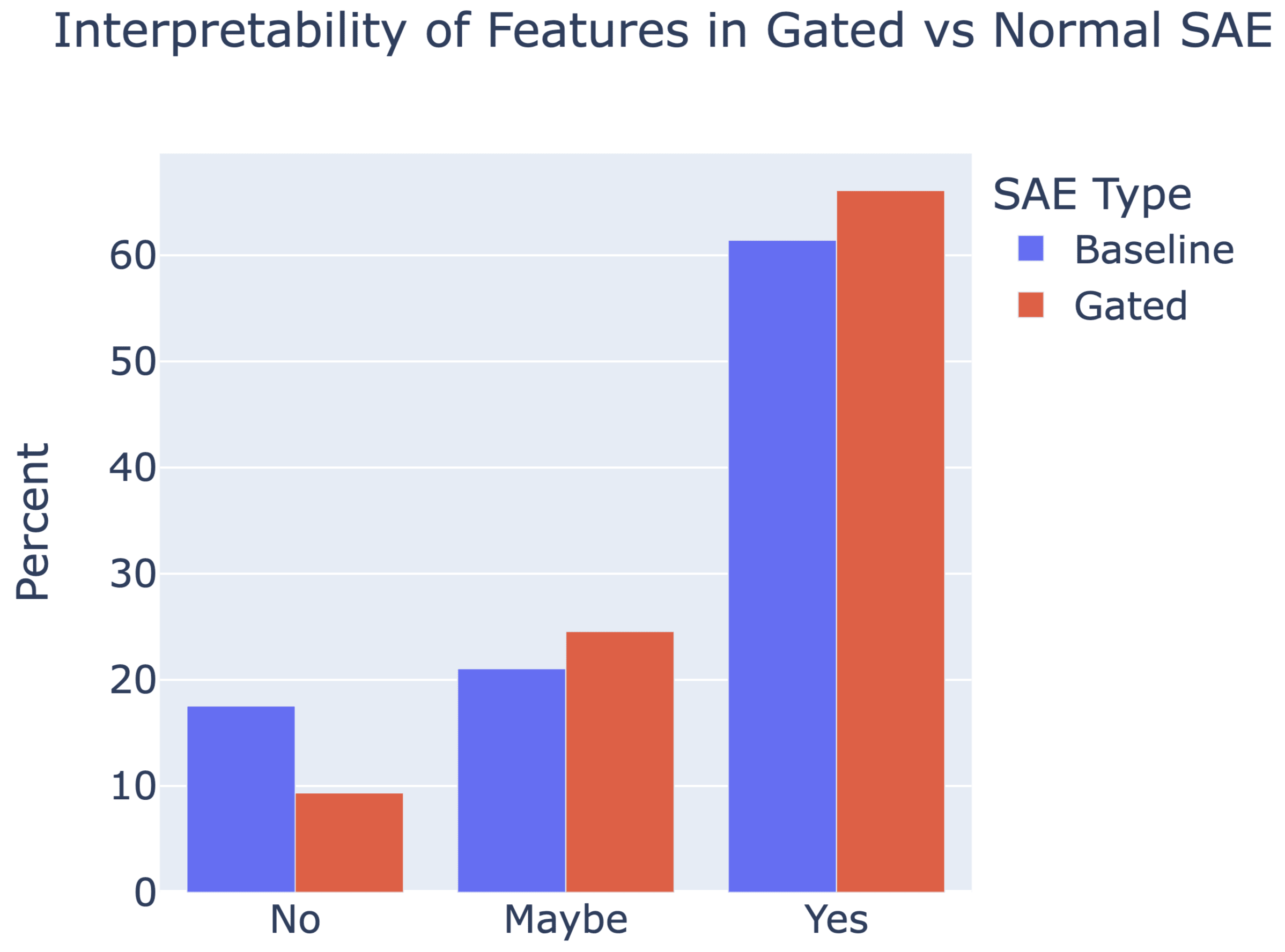
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!

Nice work! I'm not sure I fully understand what the "gated-ness" is adding, i.e. what the role the Heaviside step function is playing. What would happen if we did away with it? Namely, consider this setup:
Let f and ^x be the encoder and decoder functions, as in your paper, and let x be the model activation that is fed into the SAE.
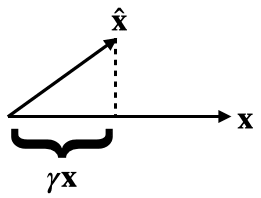
The usual SAE reconstruction is ^x(f(x)), which suffers from the shrinkage problem.
Now, introduce a new learned parameter t∈Rnfeatures, and define an "expanded" reconstruction yexpanded=^x(t⊙f(x)), where ⊙ denotes elementwise multiplication.
Finally, take the loss to be:
L=||^xcopy(f(x))−x||22+||yexpanded−x||22+λ||f(x)||1.
where ^xcopy ensures the decoder gets no gradients from the first term. As I understand it, this is exactly the loss appearing in your paper. The only difference in the setup is the lack of the Heaviside step function.
Did you try this setup? Or does it fail for an obvious reason I missed?
This suggestion seems less expressive than (but similar in spirit to) the "rescale & shift" baseline we compare to in Figure 9. The rescale & shift baseline is sufficient to resolve shrinkage, but it doesn't capture all the benefits of Gated SAEs.
The core point is that L1 regularization adds lots of biases, of which shrinkage is just one example, so you want to localize the effect of L1 as much as possible. In our setup L1 applies to ReLU(πgate(x)), so you might think of πgate as "tainted", and want to use it as little as possible. T... (read more)