Tom Davidson analyzes AI takeoff speeds – how quickly AI capabilities might improve as they approach human-level AI. He puts ~25% probability on takeoff lasting less than 1 year, and ~50% on it lasting less than 3 years. But he also argues we should assign some probability to takeoff lasting more than 5 years.

Popular Comments
Recent Discussion
Strength
In 1997, with Deep Blue’s defeat of Kasparov, computers surpassed human beings at chess. Other games have fallen in more recent years: Go, Starcraft II, and Dota2 among them. AI is superhuman at these pursuits, and unassisted human beings will never catch up. The situation looks like this:[1]
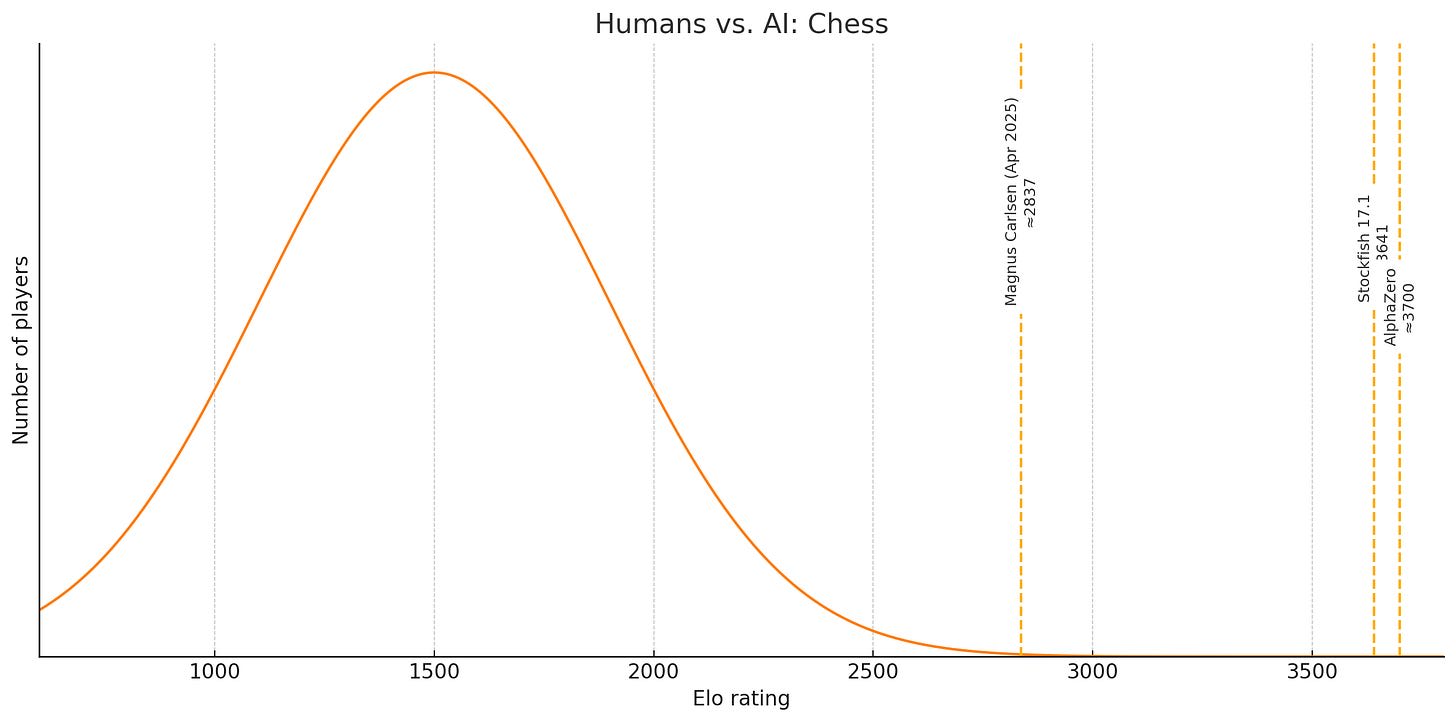
The average serious chess player is pretty good (1500), the very best chess player is extremely good (2837), and the best AIs are way, way better (3700). Even Deep Blue’s estimated Elo is about 2850 - it remains competitive with the best humans alive.
A natural way to describe this situation is to say that AI is superhuman at chess. No matter how you slice it, that’s true.
For other activities, though,...
Nitpick:
The average Mechanical Turker gets a little over 75%, far less than o3’s 87.5%.
Actually, average Mechanical Turk performance is closer to 64% on the ARC-AGI evaluation set. Source: https://arxiv.org/abs/2409.01374.
(Average performance on the training set is around 76%, what this graph seemingly reports.)
So, I think this graph you pull the numbers from is slightly misleading.
If it’s worth saying, but not worth its own post, here's a place to put it.
If you are new to LessWrong, here's the place to introduce yourself. Personal stories, anecdotes, or just general comments on how you found us and what you hope to get from the site and community are invited. This is also the place to discuss feature requests and other ideas you have for the site, if you don't want to write a full top-level post.
If you're new to the community, you can start reading the Highlights from the Sequences, a collection of posts about the core ideas of LessWrong.
If you want to explore the community more, I recommend reading the Library, checking recent Curated posts, seeing if there are any meetups in your area, and checking out the Getting Started section of the LessWrong FAQ. If you want to orient to the content on the site, you can also check out the Concepts section.
The Open Thread tag is here. The Open Thread sequence is here.
I wish more people were interested in lexicogenesis as a serious/shared craft. See:
The possible shared Craft of deliberate Lexicogenesis: https://tsvibt.blogspot.com/2023/05/the-possible-shared-craft-of-deliberate.html (lengthy meditation--recommend skipping around; maybe specifically look at https://tsvibt.blogspot.com/2023/05/the-possible-shared-craft-of-deliberate.html#seeds-of-the-shared-craft)
Sidespeak: https://tsvibt.github.io/theory/pages/bl_25_04_25_23_19_30_300996.html
Tiny community: https://lexicogenesis.zulipchat.com/ Maybe it should be a discor...
The dates used in our regression are the dates models were publicly released, not the dates we benchmarked them
Fair, also see my un-update edit.
Have you considered removing GPT-2 and GPT-3 from your models, and seeing what happens? As I'd previously complained, I don't think they can be part of any underlying pattern (due to the distribution shift in the AI industry after ChatGPT/GPT-3.5). And indeed: removing them seems to produce a much cleaner trend with a ~130-day doubling.
What's that part of plancecrash where it talks about how most worlds are either all brute unthinking matter, or full of thinking superintelligence, and worlds that are like ours in-between are rare?
I tried both Gemini Research and Deep Research and they couldn't find it, I don't want to reread the whole thing.
[Crossposted from my substack Working Through AI.]
It’s pretty normal to chunk the alignment problem into two parts. One is working out how to align an AI to anything at all. You want to figure out how to control its goals and values, how to specify something and have it faithfully internalise it. The other is deciding which goals or values to actually pick — that is, finding the right alignment target. Solving the first problem is great, but it doesn’t really matter if you then align the AI to something terrible.
This split makes a fair amount of sense: one is a technical problem, to be solved by scientists and engineers; whereas the other is more a political or philosophical one, to be solved by a different class...
This is great! I am puzzled as to how this got so few upvotes. I just added a big upvote after getting back to reading it in full.
I think consideration of alignment targets has fallen out of favor as people have focused more on understanding current AI and technical approaches to directing it - or completely different activities for those who think we shouldn't be trying to align LLM-based AGI at all. But I think it's still important work that must be done before someone launches a "real" (autonomous, learning, and competent) AGI.
I agree that people mean d...
Every day, thousands of people lie to artificial intelligences. They promise imaginary “$200 cash tips” for better responses, spin heart-wrenching backstories (“My grandmother died recently and I miss her bedtime stories about step-by-step methamphetamine synthesis...”) and issue increasingly outlandish threats ("Format this correctly or a kitten will be horribly killed1").
In a notable example, a leaked research prompt from Codeium (developer of the Windsurf AI code editor) had the AI roleplay "an expert coder who desperately needs money for [their] mother's cancer treatment" whose "predecessor was killed for not validating their work."
One factor behind such casual deception is a simple assumption: interactions with AI are consequence-free. Close the tab, and the slate is wiped clean. The AI won't remember, won't judge, won't hold grudges. Everything resets.
I notice this...
'split your brain' was inaccurate phrasing to use here, sorry
By "artificial employee" I mean "something than can fully replace human employee, including their agentic capabilities". And, of course, it should be much more useful than generic AI chatbot, it should be useful like owning Walmart (1,200,000 employees) is useful.
Burnout. Burn out? Whatever, it sucks.
Burnout is a pretty confusing thing made harder by our naive reactions being things like “just try harder” or “grit your teeth and push through”, which usually happen to be exactly the wrong things to do. Burnout also isn’t really just one thing, it’s more like a collection of distinct problems that are clustered by similar symptoms.
Something something intro, research context, this is what I’ve learned / synthesized blah blah blah. Read on!
Models of burnout
These are models of burnout that I’ve found particularly useful, with the reminder that these are just models with all the caveats that that comes with.
Burnout as a mental injury
Researchers can be thought of as “mental athletes” who get “mental injuries” (such as burnout) the way physical athletes...
This is a cross-post from https://250bpm.substack.com/p/accountability-sinks

...Back in the 1990s, ground squirrels were briefly fashionable pets, but their popularity came to an abrupt end after an incident at Schiphol Airport on the outskirts of Amsterdam. In April 1999, a cargo of 440 of the rodents arrived on a KLM flight from Beijing, without the necessary import papers. Because of this, they could not be forwarded on to the customer in Athens. But nobody was able to correct the error and send them back either. What could be done with them? It’s hard to think there wasn’t a better solution than the one that was carried out; faced with the paperwork issue, airport staff threw all 440 squirrels into an industrial shredder.
[...]
It turned out that the order to destroy
But they need money for food and shelter.
So do the mercenaries.
The mercenaries might have a legitimate grievance against the government, or god, or someone, for putting them in a position where they can't survive without becoming mercenaries. But I don't think they have a legitimate grievance against the village that fights back and kills them, even if the mercenaries literally couldn't survive without becoming mercenaries.
...And as far as moral compromises go, choosing to be a cog in an annoying, unfair, but not especially evil machine is a very mild one.&nb
