This is a linkpost for https://openai.com/research/gpt-4
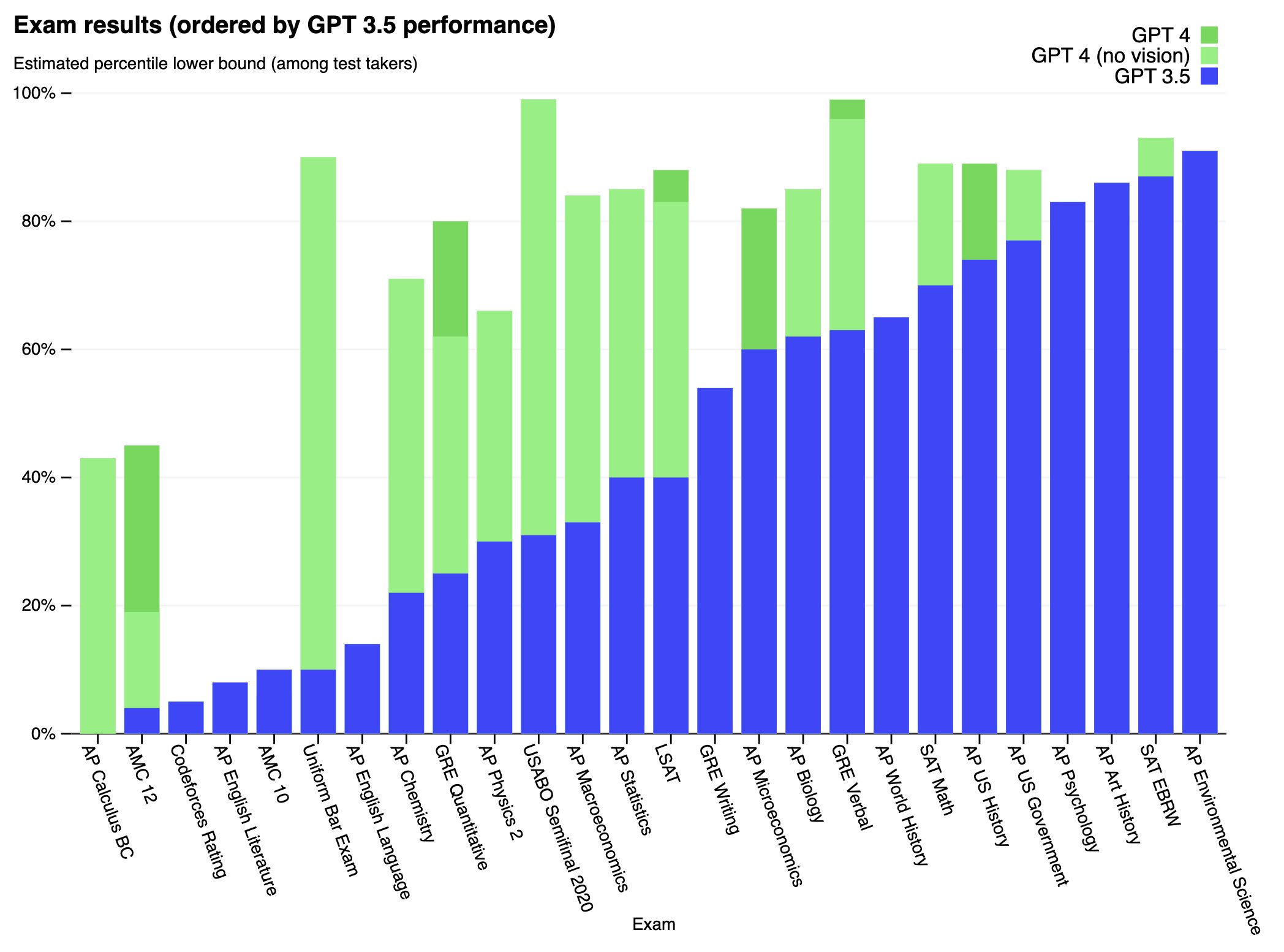
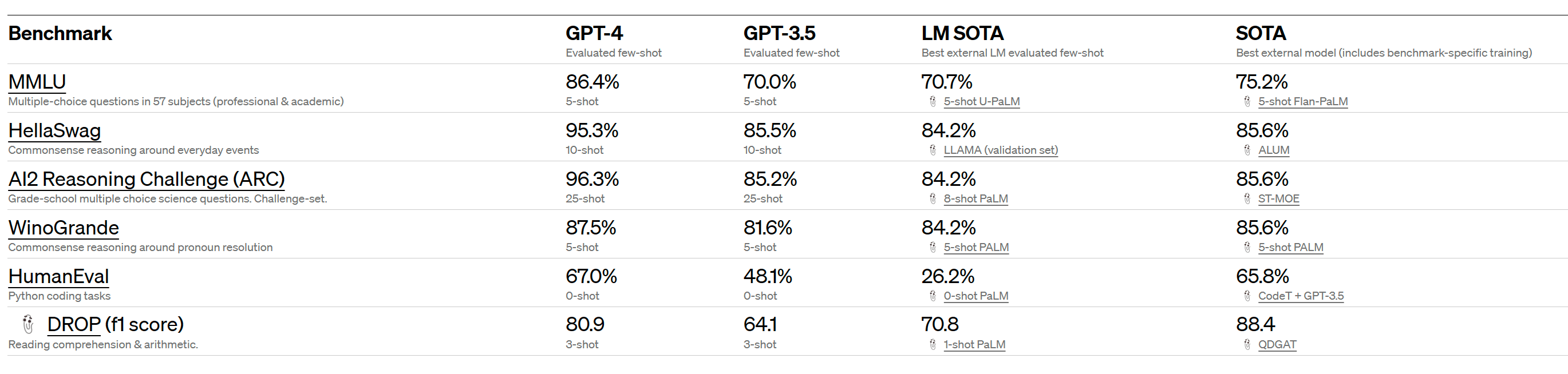
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf


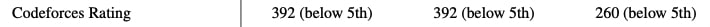
{kind=link}
Ahh, I see. You aren't complaining about the 'ask it to do scary thing' part, but the 'give it access to the internet' part.
Well, lots of tech companies are in the process of giving AIs access to the internet; ChatGPT for example and BingChat and whatever Adept is doing etc. ChatGPT can only access the internet indirectly, through whatever scaffolding programs its users write for it. But that's the same thing that ARC did. So ARC was just testing in a controlled, monitored setting what was about to happen in a less controlled, less monitored setting in the wild. Probably as we speak there are dozens of different GPT-4 users building scaffolding to let it roam around the web, talk to people on places like TaskRabbit, etc.
I think it's a very good thing that ARC was able to stress-test those capabilities/access levels a little bit before GPT-4 and the general public were given access to each other, and I hope similar (but much more intensive, rigorous, and yes more secure) testing is done in the future. This is pretty much our only hope as a society for being able to notice when things are getting dangerous and slow down in time.