Reviews 2023
Leaderboard
Tldr: I'm still very happy to have written Against Almost Every Theory of Impact of Interpretability, even if some of the claims are now incorrect. Overall, I have updated my view towards more feasibility and possible progress of the interpretability agenda — mainly because of the SAEs (even if I think some big problems remain with this approach, detailed below) and representation engineering techniques. However, I think the post remains good regarding the priorities the community should have.
First, I believe the post's general motivation of red-teaming a ...
I think this paper was great. I'm very proud of it. It's a bit hard to separate out this paper from the follow-up post arguing for control, but I'll try to.
This paper led to a bunch of research by us and other people; it helped AI control become (IMO correctly) one of the main strategies discussed for ensuring safety from scheming AIs. It was accepted as an oral at ICML 2024. AI companies and other researchers have since built on this work (Anthropic’s “Sabotage Evaluations”, Mathew et al “Hidden in Plain Text”; I collaborated on Adaptive Deployment of Unt...
I think control research has relatively little impact on X-risk in general, and wrote up the case against here.
Basic argument: scheming of early transformative AGI is not a very large chunk of doom probability. The real problem is getting early AGI to actually solve the problems of aligning superintelligences, before building those superintelligences. That's a problem for which verification is hard, solving the problem itself seems pretty hard too, so it's a particularly difficult type of problem to outsource to AI - and a particularly easy to type of prob...
My sense is that this post holds up pretty well. Most of the considerations under discussion still appear live and important including: in-context learning, robustness, whether jank AI R&D accelerating AIs can quickly move to more general and broader systems, and general skepticism of crazy conclusions.
At the time of this dialogue, my timelines were a bit faster than Ajeya's. I've updated toward the views Daniel expresses here and I'm now about half way between Ajeya's views in this post and Daniel's (in geometric mean).
My read is that Daniel looks som...
Didn't like the post then, still don't like it in 2024. I think there are defensible points interwoven with assumptions and stereotypes.
First: generalizes from personal experiences that are not universal. I think a lot of people don't have this or don't struggle with this or find it worth it, and the piece assumes everyone feels the way the author feels.
Second: the thing it describes is a bias, and I don't think the essay realizes this.
Okay, part of the thing is that this doesn't make a case or acknowledge this romantic factor as being differe...
(Self-review.) I'm as proud of this post as I am disappointed that it was necessary. As I explained to my prereaders on 19 October 2023:
...My intent is to raise the level of the discourse by presenting an engagement between the standard MIRI view and a view that's relatively optimistic about prosaic alignment. The bet is that my simulated dialogue (with me writing both parts) can do a better job than the arguments being had by separate people in the wild; I think Simplicia understands things that e.g. Matthew Barnett doesn't. (The karma system loved my dial
My wife completed two cycles of IVF this year, and we had the sequence data from the preimplantation genetic testing on the resulting embryos analyzed for polygenic factors by the unnamed startup mentioned in this post.
I can personally confirm that the practical advice in this post is generally excellent.
The basic IVF + testing process is pretty straightforward (if expensive), but navigating the medical bureaucracy can be a hassle once you want to do anything unusual (like using a non-default PGT provider), and many clinics aren't going to help you with an...
This post deserves to be remembered as a LessWrong classic.
- It directly tries to solve a difficult and important cluster of problems (whether it succeeds is yet to be seen).
- It uses a new diagrammatic method of manipulating sets of independence relations.
- It's a technical result! These feel like they're getting rarer on LessWrong and should be encouraged.
There are several problems that are fundamentally about attaching very different world models together and transferring information from one to the other.
- Ontology identification involves taking a
I remain both skeptical some core claims in this post, and convinced of its importance. GeneSmith is one of few people with such a big-picture, fresh, wildly ambitious angle on beneficial biotechnology, and I'd love to see more of this genre.
One one hand on the object level, I basically don't buy the argument that in-vivo editing could lead to substantial cognitive enhancement in adults. Brain development is incredibly important for adult cognition, and in the maybe 1%--20% residual you're going well off-distribution for any predictors trained on unedite...
I wish this had been called "Duncan's Guidelines for Discourse" or something like that. I like most of the guidelines given, but they're not consensus. And while I support Duncan's right to block people from his posts (and agree with him far on discourse norms far more than with the people he blocked), it means that people who disagree with him on the rules can't make their case in the comments. That feels like an unbalanced playing field to me.
This post introduces Timaeus' "Developmental Interpretability" research agenda. The latter is IMO one of the most interesting extant AI alignment research agendas.
The reason DevInterp is interesting is that it is one of the few AI alignment research agendas that is trying to understand deep learning "head on", while wielding a powerful mathematical tool that seems potentially suitable for the purpose (namely, Singular Learning Theory). Relatedly, it is one of the few agendas that maintains a strong balance of theoretical and empirical research. As such, it...
At the time when I first heard this agenda proposed, I was skeptical. I remain skeptical, especially about the technical work that has been done thus far on the agenda[1].
I think this post does a reasonable job of laying out the agenda and the key difficulties. However, when talking to Davidad in person, I've found that he often has more specific tricks and proposals than what was laid out in this post. I didn't find these tricks moved me very far, but I think they were helpful for understanding what is going on.
This post and Davidad's agenda overall would...
This post seems mostly reasonable in retrospect, except that it doesn't specifically note that it seems unlikely that voluntary RSP commitments would result in AI companies unilaterally pausing until they were able to achieve broadly reasonable levels of safety. I wish the post more strongly emphasized that regulation was a key part of the picture---my view is that "voluntary RSPs are pauses done right" is wrong, but "RSPs via (international) regulation are pauses done right" seems like it could be roughly right. That said, I do think that purely voluntary...
A concise and clear facilitation of a relatively unknown alignment strategy that relies on pursuing other relatively unknown alignment strategies.
If you've ever wondered how many promising alignment strategies never see the light of the day, AE Studio would be the place to ask this question.
Overall, I believe that this strategy will have a positive impact on "widening" the field of AI alignment, which will, in turn, improve our chances of avoiding catastrophic outcomes.
Retrospectives are great, but I'm very confused at the juxtaposition of the Lightcone Offices being maybe net-harmful in early 2023 and Lighthaven being a priority in early 2025. Isn't the latter basically just a higher-production-value version of the former? What changed? (Or after taking the needed "space to reconsider our relationship to this whole ecosystem", did you decide that the ecosystem is OK after all?)
I think it's good that this post was written, shared to LessWrong, and got a bunch of karma. And (though I haven't fully re-read it) it seems like the author was careful to distinguish observation from inference and to include details in defense of Ziz when relevant. I appreciate that.
I don't think it's a good fit for the 2023 review. Unless Ziz gets back in the news, there's not much reason for someone in 2025 or later to be reading this.
If I was going to recommend it, I think the reason would be some combination of
- This is a good example of investigative
I forgot about this one! It's so great! Yudkowsky is a truly excellent fiction writer. I found myself laughing multiple times reading this + some OpenAI capabilities researchers I know were too. And now rereading it... yep it stands the test of time.
I came back to this because I was thinking about how hopeless the situation w.r.t. AGI alignment seems and then a voice in my head said "it could be worse, remember the situation described in that short story?"
I still like this post overall, but various things have changed that interestingly affect the content of the post:
- We'd now be just starting the 3rd year of university in Buck's analogy. Does this seem right? I guess maybe. It feels a bit late to me. (Maybe I feel more like a 2nd year.)
- Redwood is doing less blue-sky research and is much more focused on how to make very straightforward strategies work well, particularly in the context of control. We're also spending more time thinking about exactly what will and should be implemented and what overall plan
I think writing this post was helpful to me in thinking through my career options. I've also been told by others that the post was quite valuable to them as an example of someone thinking through their career options.
Interestingly, I left METR (then ARC Evals) about a month and a half after this post was published. (I continued to be involved with the LTFF.) I then rejoined METR in August 2024. In between, I worked on ambitious mech interp and did some late stage project management and paper writing (including some for METR). I also organized a mech ...
What have you learned since then? Have you changed your mind or your ontology?
I've learned even more chemistry and biology, and I've changed my mind about lots of things, but not the points in this post. Those had solid foundations I understood well and redundant arguments, so the odds of that were low.
What would you change about the post? (Consider actually changing it.)
The post seems OK. I could have handled replies to comments better. For example, the top comment was by Thomas Kwa, and I replied to part of it as follows:
...Regarding 5, my underst
I think this post is very good (note: I am the author).
Nietzsche is brought up often in different contexts related to ethics, politics, and the best way to live. This post is the best summary on the Internet of his substantive moral theory, as opposed to vague gesturing based on selected quotes. So it's useful for people who
- are interested in what Nietzsche's arguments, as a result of their secondhand impressions
- have specific questions like "Why does Nietzsche think that the best people are more important"
- want to know whether something can be well-described
[COI notice: this is a Redwood Research output]
I think this idea, though quite simple and obvious, is very important. I think coup probes are the paradigmatic example of a safety technique that uses model internals access, and they're an extremely helpful concrete baseline to think about in many cases, e.g. when considering safety cases via mech interp. I refer to this post constantly. We followed up on it in Catching AIs red-handed. (We usually call them "off-policy probes" now.)
Unfortunately, this paper hasn't been followed up with as much empirica...
This post argues against alignment protocols based on outsourcing alignment research to AI. It makes some good points, but also feels insufficiently charitable to the proposals it's criticizing.
John make his case by an analogy to human experts. If you're hiring an expert in domain X, but you understand little in domain X yourself then you're going to have 3 serious problems:
- Illusion of transparency: the expert might say things that you misinterpret due to your own lack of understanding.
- The expert might be dumb or malicious, but you will believe them due to
I still basically think all of this, and still think this space doesn't understand it, and thus has an out-of-whack X-derisking portfolio.
If I were writing it today, I'd add this example about search engines from this comment https://www.lesswrong.com/posts/oC4wv4nTrs2yrP5hz/what-are-the-strongest-arguments-for-very-short-timelines?commentId=2XHxebauMi9C4QfG4 , about induction on vague categories like "has capabilities":
...Would you say the same thing about the invention of search engines? That was a huge jump in the capability of our computers. And it look
This is excellent. Before reading this post in 2023, I had the confusion described. Roughly, that Aumann agreement is rationally correct, but this mostly doesn't happen, showing that mostly people aren't rational. After reading this post, I understood that Aumann agreement is extremely common, and the exceptions where it doesn't work are best understood as exceptions. Coming back to read it in 2024, it seems obvious. This is a symptom of the post doing its job in 2023.
This is part of a general pattern. When I think that human behavior is irrational, I know...
Going through the post, I figured I would backtest the mentioned strategies seeing how well they performed.
Starting with NoahK's suggested big stock tickers: "TSM, MSFT, GOOG, AMZN, ASML, NVDA"
If you naively bought these stocks weighted by market cap, you would have made a 60% annual return:
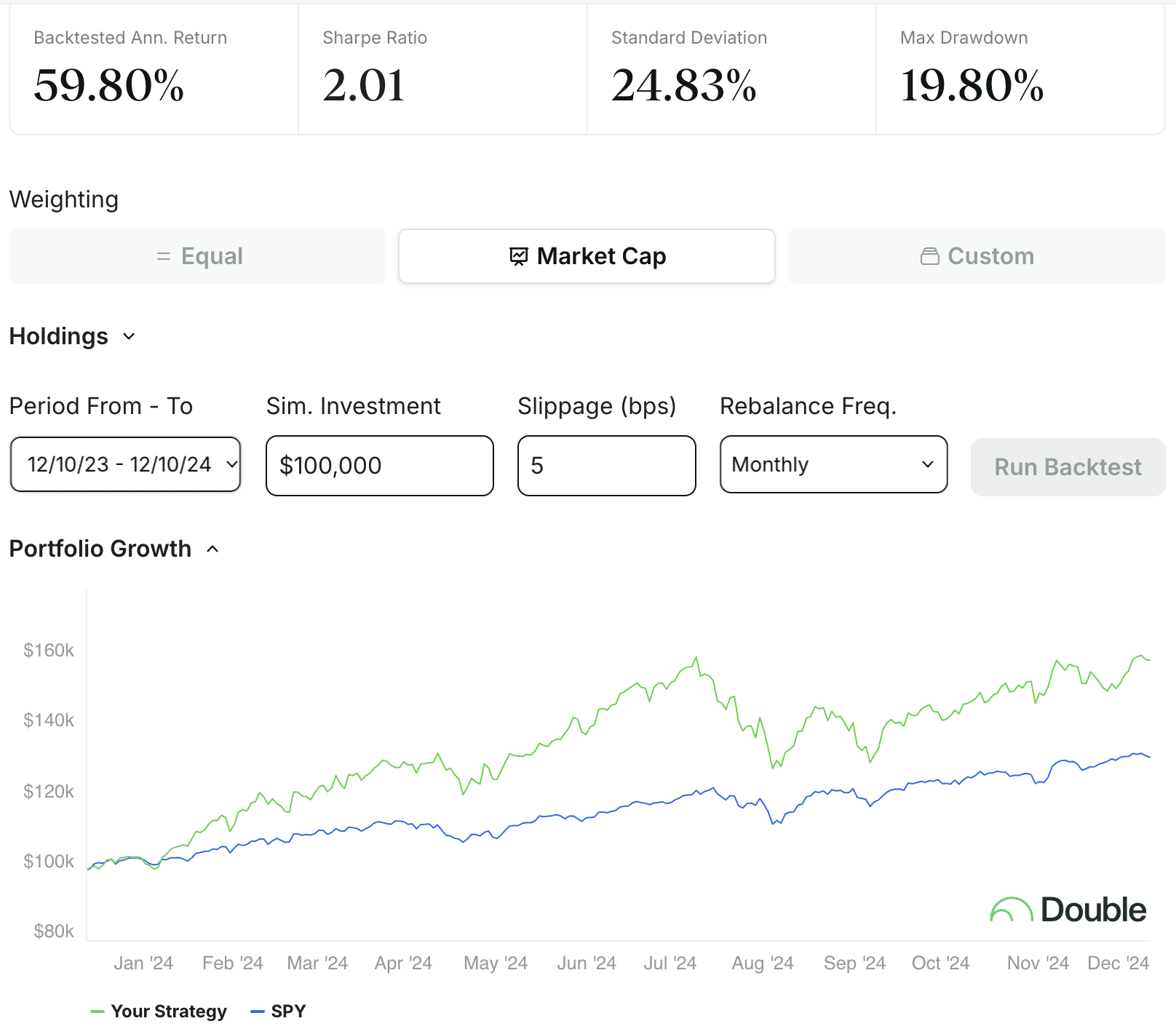
You would have also very strongly outperformed the S&P 500. That is quite good.
Let's look at one of the proposed AI index funds that was mentioned:
...iShares has one under ticket IRBO. Let's see what it holds... Looks like very low concentration (all
Sparse autoencoders have been one of the most important developments in mechanistic interpretability in the past year or so, and significantly shaped the research of the field (including my own work). I think this is in substantial part due to Towards Monosemanticity, between providing some rigorous preliminary evidence that the technique actually worked, a bunch of useful concepts like feature splitting, and practical advice for training these well. I think that understanding what concepts are represented in model activations is one of the most important ...
I'm voting against including this in the Review, at max level, because I think it too-often mischaracterizes the views of the people it quotes. And it seems real bad for a post that is mainly about describing other people's views and the drawing big conclusions from that data to inaccurately describe those views and then draw conclusions from inaccurate data.
I'd be interested in hearing about this from people who favor putting this post in the review. Did you check on the sources for some of Elizabeth's claims and think that she described them well? Did yo...
I think that prior to this paper, the discussion around scheming was pretty confusing, spread throughout many posts which were not all specifically about scheming, and was full of pretty bad arguments. This paper fixed that by bringing together most (all?) main considerations for and against expecting scheming to emerge.
I found this helpful to clarify my thinking around the topic, which makes me more confident in my focus on AI control and made me less confused when I worked on the Alignment faking paper.
It is also helpful as a list of reasons why someone ...
I plugged the stocks mentioned in here into Double's backtesting tool. I couldn't get 6 of the stocks (Samsung, one of the solar ones, 4 other random ones). At least in 2024 the companies listed weighted by market cap produced a return of about 36%, being roughly on par with the S&P 500 (which clearly had an amazing year):
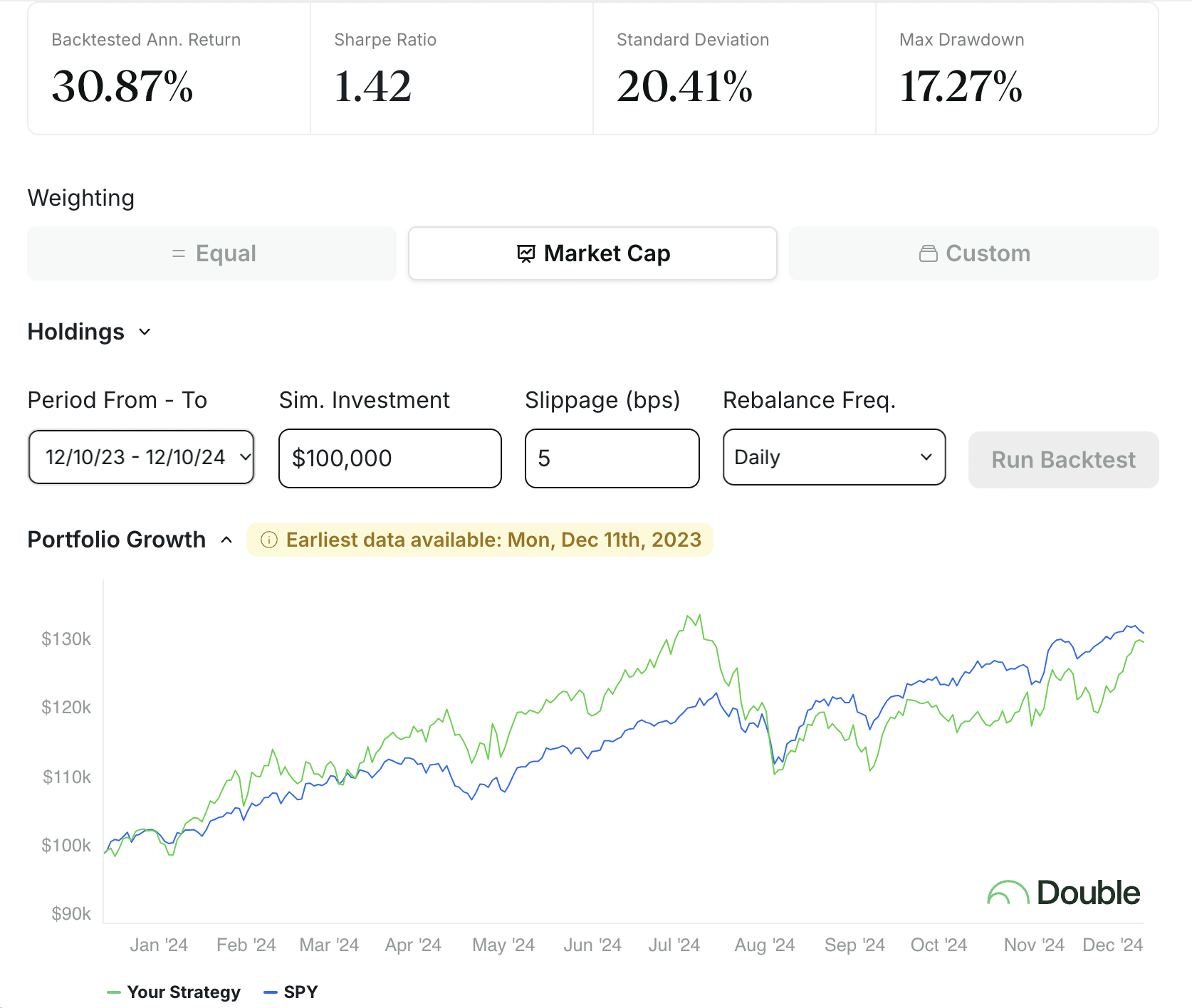
I think this, or something like this, should be in a place of prominence on LessWrong. The Best Of collection might not be the place, but it's the place I can vote on, so I'd like to vote for it here.
I used "or something like this" above intentionally. The format of this post — an introduction of why these guidelines exist, short one or two sentence explanations of the guideline, and then expanded explanations with "ways you might feel when you're about to break the X Guideline" — is excellent. It turns each guideline into a mini-lesson, which can be broke...
I quite liked this post, and strong upvoted it at the time. I honestly don't remember reading it, but rereading it, I think I learned a lot, both from the explanation of the feedback loops, and especially found the predictions insightful in the "what to expect" section.
Looking back now, the post seems obvious, but I think the content in it was not obvious (to me) at the time, hence nominating it for LW Review.
The post studies handicapped chess as a domain to study how player capability and starting position affect win probabilities. From the conclusion:
...In the view of Miles and others, the initially gargantuan resource imbalance between the AI and humanity doesn’t matter, because the AGI is so super-duper smart, it will be able to come up with the “perfect” plan to overcome any resource imbalance, like a GM playing against a little kid that doesn't understand the rules very well.
The problem with this argument is that you can use the exact same reason
By all means, strategically violate social customs. But if you irritate people by doing it, you may be advancing your own epistemics by making them talk to you, but you're actually hurting their epistemics by making them irritated with whatever belief you're trying to pitch. Lack of social grace is very much not an epistemic virtue.
This post captures a fairly common belief in the rationalist community. It's important to understand why it's wrong.
Emotions play a strong role in human reasoning. I finally wrote up at least a little sketch of why that happens....
This post was fun to read, important, and reasonably timeless (I've found myself going back to it and linking to it several times). (Why is it important? Because it was a particularly vivid example of a major corporation deploying an AI that was blatantly, aggressively misaligned, despite presumably making at least some attempt to align it.)
+9. Fatebook has been a game changer for me, in terms of how practical it is to weave predictions into my decisionmaking. I donated $1000 to Sage to support it.
It's not listed here, but one of the most crucial things is the Fatebook Chrome Extension, which makes it possible to frictionless integrate it into my normal orienting process (which I do in google docs. You can also do it in the web version of Roam).
I've started work on "Enriched Fatebook" poweruser view that shows your calibration at a more granular level. I have several ideas for how to build ad...
I like the emphasis in this post on the role of patterns in the world in shaping behaviour, the fact that some of those patterns incentivise misaligned behaviour such as deception, and further that our best efforts at alignment and control are themselves patterns that could have this effect. I also like the idea that our control systems (even if obscured from the agent) can present as "errors" with respect to which the agent is therefore motivated to learn to "error correct".
This post and the sharp left turn are among the most important high-level takes on...
This post provides a mathematical analysis of a toy model of Goodhart's Law. Namely, it assumes that the optimization proxy is a sum of the true utility function and noise , such that:
- and are independent random variables w.r.t. some implicit distribution on the solution space. The meaning of this distribution is not discussed, but I guess we might think of it some kind of inductive bias, e.g. a simplicity prior.
- The optimization process can be modeled as conditioning on a high value of
I kinda like this post, and I think it's pointing at something worth keeping in mind. But I don't think the thesis is very clear or very well argued, and I currently have it at -1 in the 2023 review.
Some concrete things.
- There are lots of forms of social grace, and it's not clear which ones are included. Surely "getting on the train without waiting for others to disembark first" isn't an epistemic virtue. I'd normally think of "distinguishing between map and territory" as an epistemic virtue but not particularly a social grace, but the last two paragraphs m
This post tries to push back against the role of expected utility theory in AI safety by arguing against various ways to derive expected utility axiomatically. I heard many such arguments before, and IMO they are never especially useful. This post is no exception.
The OP presents the position it argues against as follows (in my paraphrasing): "Sufficiently advanced agents don't play dominated strategies, therefore, because of [theorem], they have to be expected utility maximizers, therefore they have to be goal-directed and [other conclusions]". They then p...
This article provides object-level arguments for thinking that deceptive alignment is very unlikely.
Recently, some organizations (Redwood Research, Anthropic) have been focusing on AI control in general and avoiding deceptive alignment in particular. I would like to see future works from these organizations explaining why deceptive alignment is likely enough to spend considerable resources on it.
Overall, while I don't agree that deceptive alignment is <1% likely, this article made me update towards deceptive alignment being somewhat less likely.
This post makes an important point: the words "artificial intelligence" don't necessarily carve reality at the joints, the fact something is true about a modern system that we call AI doesn't automatically imply anything about arbitrary future AI systems, no more than conclusions about e.g. Dendral or DeepBlue carry over to Gemini.
That said, IMO the author somewhat overstates their thesis. Specifically, I take issue with all the following claims:
- LLMs have no chance of becoming AGI.
- LLMs are automatically safe.
- There is nearly no empirical evidence from LLMs
I've been notified that this post was nominated as a finalist for the Less Wrong 2023 Review! This is fantastic news, and I'm deeply honored! As part of the notification I was encouraged to write a self-review, with some example prompts like "Do you still endorse this?" and "What further work do you think should be done exploring the ideas here?”
Fiction is pretty Out Of Distribution for Less Wrong posts. I almost didn’t post it, because what is the point? I mean that literally... what IS the point of fiction on Less Wrong? Most often it’s to help demonstra...
As a rough heuristic: "Everything is fuzzy; every bell curve has tails that matter."
It's important to be precise, and it's important to be nuanced, and it's important to keep the other elements in view even though the universe is overwhelmingly made of just hydrogen and helium.
But sometimes, it's also important to simply point straight at the true thing. "Men are larger than women" is a true thing, even though many, many individual women are larger than many, many individual men, and even though the categories "men" and "women" and "larger" are thems...
I think that someone reading this would be challenged to figure out for themselves what assumptions they think are justified in good discourse, and would fix some possible bad advice they took from reading Sabien's post. I give this a +4.
(Below is a not especially focused discussion of some points raised; perhaps after I've done more reviews I can come back and tighten this up.)
Sabien's Fifth guideline is "Aim for convergence on truth, and behave as if your interlocutors are also aiming for convergence on truth."
My guess is that the idea that motivates Sab...
I still agree with a lot of that post and am still essentially operating on it.
I also think that it's interesting to read the comments because at the time the promise of those who thought my post was wrong was that Anthropic's RSP would get better and that this was only the beginning. With RSP V2 being worse and less specific than RSP V1, it's clear that this was overoptimistic.
Now, risk management in AI has also gone a lot more mainstream than it was a year ago, in large parts thanks to the UK AISI who started operating on it. People have also...
This was a hasty and not exactly beautifully-written post. It didn't get much traction here on LW, but it had more engagement on its EA Forum crosspost (some interesting debate in the comments).
I still endorse the key messages, which are:
- don't rule out international and inter-bloc cooperation!
- it's realistic and possible, though it hangs in the balance
- it might be our only hope
- lazy generalisations have power
- us-vs-them rhetoric is self-reinforcing
Not content with upbraiding CAIS, I also went after Scott Alexander later in the month for similar l...
I find myself linking back to this often. I don't still fully endorse quite everything here, but the core messages still seem true even with things seeming further along.
I do think it should likely get updated soon for 2025.
(Self review) Does this essay belong in the Best Of collection? That's a good question. Do people go back and read all the Best Of posts? Do they read the Best Of posts from previous years? Speaking as the person who wrote this, if there was a collection of posts everyone on LessWrong read when they joined, I might not need this essay included in that collection because the essay would have already succeeded. I'd want basically any other essay that taught an object-level thing.
Then again, this essay is a useful pointer to why a group might repeat informati...
Most LessWrong readers do not attend meetups, and this is basically useless to them. Some readers do attend meetups, which Ziz will not attend because the organizers are aware of this and are will keep Ziz out. Some organizers aren't aware, and this is a useful thing to be able to point to in that case, though since this was written describing a developing situation it would be kind of nice to have a conclusion or update somewhere near the top.
Overall, I wouldn't want this in the Best Of collection, but I do expect to link people to it in the future.
Tentative +9, I aim to read/re-read the whole sequence before the final vote and write a more thorough review.
My current quickly written sense of the sequence is that it is a high-effort, thoughtfully written attempt to help people with something like 'generating the true hypotheses' rather than 'evaluating the hypotheses that I already have'. Or 'how to do ontological updates well and on-purpose'.
Skimming the first few posts, there's an art here that I don't see other people talking about unprompted very much (as a general thing one can do well, of course...
This article studies a potentially very important question: is improving connectomics technology net harmful or net beneficial from the perspective of existential risk from AI? The author argues that it is net beneficial. Connectomics seems like it would help with understanding the brain's reward/motivation system, but not so much with understanding the brain's learning algorithms. Hence it arguably helps more with AI alignment than AI capability. Moreover, it might also lead to accelerating whole brain emulation (WBE) which is also helpful.
The author ment...
I think 2023 was perhaps the peak for discussing the idea that neural networks have surprisingly simple representations of human concepts. This was the year of Steering GPT-2-XL by adding an activation vector, cheese vectors, the slightly weird lie detection paper and was just after Contrast-consistent search.
This is a pretty exciting idea, because if it’s easy to find human concepts we want (or don’t want) networks to possess, then we can maybe use that to increase the chance that systems that are honest, kind, loving (and can ask them...
Perhaps the largest, most detailed piece of AI risk skepticism of 2023. It engages directly with one of the leading figures on the "high p(doom)" side of the debate.
The article generated a lot of discussion. As of January 4, 2025, it had 230 comments.
Overall, this article updated me towards strongly lowering my p(doom). It is thorough, it is clearly written and it proposes object-level solutions to problems raised by Yudkowski.
The thing I want most from LessWrong and the Rationality Community writ large is the martial art of rationality. That was the Sequences post that hooked me, that is the thing I personally want to find if it exists. Therefore, posts that are actually trying to build a real art of rationality (or warn of failed approaches) are the kind of thing I'm going to pay attention to, and if they look like they actually might work I'm going to strongly vote for including them in the Best Of LessWrong collection.
Feedbackloop-first Rationality sure looks like an actual ...
The TLDR has multiple conclusions but this is my winner:
My conclusion -- springing to a great degree from how painful seeking clear predictions in 700 pages of words has been -- is that if anyone says "I have a great track record" without pointing to specific predictions that they made, you should probably ignore them, or maybe point out their lack of epistemic virtue if you have the energy to spare for doing that kind of criticism productively.
There is a skill in writing things that, when read later, are likely to be interpreted as correct predictions...
The takeoffspeeds.com model Davidson et al worked on is still (unfortunately) the world's best model of AGI takeoff. I highly encourage people to play around with it, perhaps even to read the research behind it, and I'm glad LessWrong is a place that collects and rewards work like this.
This was just a really good post. It starts off imaginative and on something I'd never really thought about - hey, spring shoes are a great idea, or at least the dream of them is. It looks at different ways this has sort have been implemented, checks assumptions, and goes down to the basic physics of it, and then explores some related ideas. I like someone who's just interested in a very specific thing exploring the idea critically from different angles and from the underlying principles. I want to read more posts like this. I also, now, want shoes with springs on them.
The original post, the actual bet, and the short scuffle in the comments is exactly the kind of epistemic virtue, basic respect, and straight-talking object-level discussion that I like about LessWrong.
I'm surprised and saddened that there aren't more posts like this one around (prediction markets are one thing; loud, public bets on carefully written LW posts are another).
Having something like this occur every ~month seems important from the standpoint of keeping the garden on its toes and remind everyone that beliefs must pay rent, possibly in the form of PayPal cash transfers.
I think I roughly stand behind my perspective in this dialogue. I feel somewhat more cynical than I did at the time I did this dialogue, perhaps partially due to actual updates from the world and partially because I was trying to argue for the optimistic case here which put me in a somewhat different frame.
Here are some ways my perspective differs now:
- I wish I said something like: "AI companies probably won't actually pause unilaterally, so the hope for voluntary RSPs has to be building consensus or helping to motivate developing countermeasures". I don'
I love Fatebook as a user, and also this feels like an odd fit for the Best Of LessWrong collection.
I usually think of the Best Of LessWrong collection as being the best posts from a given year. The collection used to be physical books, printed on paper, which I could physically hand to someone. By that standard, this isn't very good. What exactly would someone do with this post if they read it in a book? It's kind of just a (well written) advertisement. The magic happens if they go to the website.
But man, the last few years have been a giant leap forward ...
This post didn't get much uptake, but I still think the framing in this post is good and is a pretty good way to explain this sort of distinction in practice. I reasonably often reference this post.
I think Elizabeth is correct here, and also that vegan advocates would be considerably more effective with higher epistemic standards:
I think veganism comes with trade-offs, health is one of the axes, and that the health issues are often but not always solvable. This is orthogonal to the moral issue of animal suffering. If I’m right, animal EAs need to change their messaging around vegan diets, and start self-policing misinformation. If I’m wrong, I need to write some retractions and/or shut the hell up.
The post unfortunately suffers for its length, de...
My views remain similar to when I wrote this post, and the state of nearcasted interventions still looks reasonably similar to me. I have some slightly different thoughts on how we should relate to interventions around communication, but relatively prioritizing communication still seems reasonable to me.
One change in my perspective is that I'm now somewhat less excited about allocating larger fractions of resources toward specifically AI welfare. (I now think 0.2% seems better than 1%.) I've updated toward thinking safety concerns will get a smaller fracti...
Looking back on this post after a year, I haven't changed my mind about the content of the post, but I agree with Seth Herd when he said this post was "important but not well executed".
In hindsight I was too careless with my language in this post, and I should have spent more time making sure that every single paragraph of the post could not be misinterpreted. As a result of my carelessness, the post was misinterpreted in a predictable direction. And while I'm not sure how much I could have done to eliminate this misinterpretation, I do think that I ...
Ok, time to review this post and assess the overall status of the project.
Review of the post
What i still appreciate about the post: I continue to appreciate its pedagogy, structure, and the general philosophy of taking a complex, lesser-known plan and helping it gain broader recognition. I'm still quite satisfied with the construction of the post—it's progressive and clearly distinguishes between what's important and what's not. I remember the first time I met Davidad. He sent me his previous post. I skimmed it for 15 minutes, didn't really understand...
Possibly one of the most impactful AI control papers of 2023. It went far beyond LessWrong, making into a separate 30-minute video dedicated to (positively) reviewing the proposed solution.
The paper also enjoyed some academic success. As of January 3, 2025, it not only has 23 citations on LessWrong, but also 24 citations on Google Scholar.
This paper strongly updated me towards thinking that AI control is possible, feasible and should be actively implemented to prevent catastrophic outcomes.
This post is a solid introduction to the application of Singular Learning Theory to generalization in deep learning. This is a topic that I believe to be quite important.
One nitpick: The OP says that it "seems unimportant" that ReLU networks are not analytic. I'm not so sure. On the one hand, yes, we can apply SLT to (say) GELU networks instead. But GELUs seem mathematically more complicated, which probably translates to extra difficulties in computing the RLCT and hence makes applying SLT harder. Alternatively, we can consider a series of analytical respo...
This post is a great review of the Natural Abstractions research agenda, covering both its strengths and weaknesses. It provides a useful breakdown of the key claims, the mathematical results and the applications to alignment. There's also reasonable criticism.
To the weaknesses mentioned in the overview, I would also add that the agenda needs more engagement with learning theory. Since the claim is that all minds learn the same abstractions, it seems necessary to look into the process of learning, and see what kind of abstractions can or cannot be learned ...
I'm pleased with this dialogue and glad I did it. Outreach to policymakers is an important & complicated topic. No single post will be able to explain all the nuances, but I think this post explains a lot, and I still think it's a useful resource for people interested in engaging with policymakers.
A lot has changed since this dialogue, and I've also learned a lot since then. Here are a few examples:
- I think it's no longer as useful to emphasize "AI is a big deal for national/global security." This is now pretty well-established.
- Instead, I would encourag
Does this look like a motte-and-bailey to you?
- Bailey: GPTs are Predictors, not Imitators (nor Simulators).
- Motte: The training task for GPTs is a prediction task.
The title and the concluding sentence both plainly advocate for (1), but it's not really touched by the overall post, and I think it's up for debate (related: reward is not the optimization target). Instead there is an argument for (2). Perhaps the intention of the final sentence was to oppose Simulators? If that's the case, cite it, be explicit. This could be a really easy thing for an editor...
I read this post in full back in February. It's very comprehensive. Thanks again to Zvi for compiling all of these.
To this day, it's infuriating that we don't have any explanation whatsoever from Microsoft/OpenAI on what went wrong with Bing Chat. Bing clearly did a bunch of actions its creators did not want. Why? Bing Chat would be a great model organism of misalignment. I'd be especially eager to run interpretability experiments on it.
The whole Bing chat fiasco is also gave me the impetus to look deeper into AI safety (although I think absent Bing, I would've came around to it eventually).
I often refer to the ideas in this post and think the fundamental point is quite important: structural advantages in quantity, cost, and speed might make AI systems quite useful and thus impactful prior to being broadly superhuman.
(The exact estimates in the post do pretty strongly assume the current rough architecture, scaling laws, and paradigm, so discount accordingly.)
There are now better estimates of many of the relevant quantities done by various people (maybe Epoch, Daniel Kokotajlo, Eli Lifland), but I'm not aware of another updated article which m...
Sometimes when I re-read Yudkowsky's older writings I am still comfortable with the model and conclusion, but the evidence seems less solid than on first reading. In this post, Matthew Barnett poses problems for the evidence from Japan in Yudkowsky's Inadequacy and Modesty. Broadly he claims that Haruhiko Kuroda's policy was not as starkly beneficial as Yudkowsky claims, although he doesn't claim the policy was a mistake.
LessWrong doesn't have a great system for handling (alleged) flaws in older posts. Higher rated posts have become more visible with the "...
(I only discovered this post in 2024, so I'm less sure it will stand the test of time for me)
This post is up there with The God of Humanity, and the God of the Robot Utilitarians as the posts that contributed the most to making me confront the conflict between wanting to live a good life and wanting to make the future go well.
I read this post while struggling half burnt out on a policy job, having lost touch with the fire that drove me to AI safety in the first place, and this imaginary dialogue brought back this fire I had initially found while reading HP...
This post skillfully addressed IMO the most urgent issue in alignment:; bridging the gap between doomers and optimists.
If half of alignment thinkers think alignment is very difficult, while half think it's pretty achievable, decision-makers will be prone to just choose whichever expert opinion supports what they want to do anyway.
This and its following acts are the best work I know of in refining the key cruxes. And they do so in a compact, readable, and even fun form.
I think this isn't the sort of post that ages well or poorly, because it isn't topical, but I think this post turned out pretty well. It gradually builds from preliminaries that most readers have probably seen before, into some pretty counterintuitive facts that aren't widely appreciated.
At the end of the post, I listed three questions and wrote that I hope to write about some of them soon. I never did, so I figured I'd use this review to briefly give my takes.
- This comment from Fabien Roger tests some of my modeling choices for robustness, and finds that t
Tsvi has many underrated posts. This one was rated correctly.
I didn't previously have a crisp conceptual handle for the category that Tsvi calls Playful Thinking. Initially it seemed a slightly unnatural category. Now it's such a natural category that perhaps it should be called "Thinking", and other kinds should be the ones with a modifier (e.g. maybe Directed Thinking?).
Tsvi gives many theoretical justifications for engaging in Playful Thinking. I want to talk about one because it was only briefly mentioned in the post:
...Your sense of fun decor
This post and its precusor from 2018 present a strong and well-written argument for the centrality of mathematical theory to AI alignment. I think the learning-theoretic agenda, as well as Hutter's work on ASI safety in the setting of AIXI, currently seems underrated and will rise in status. It is fashionable to talk about automating AI alignment research, but who is thinking hard about what those armies of researchers are supposed to do? Conceivably one of the main things they should do is solve the problems that Vanessa has articulated here.
T...
It's great to have a LessWrong post that states the relationship between expected quality and a noisy measurement of quality:
(Why 0.5? Remember that performance is a sum of two random variables with standard deviation 1: the quality of the intervention and the noise of the trial. So when you see a performance number like 4, in expectation the quality of the intervention is 2 and the contribution from the noise of the trial (i.e. how lucky you got in the RCT) is also 2.)
We previously had a popular post on this topic, the tai...
My ultimate goal with this post was to use vegan advocacy as an especially legible example of a deepseated problem in effective altruism, which we could use to understand and eventually remove the problem at the root. As far as I know, the only person who has tried to use it as an example is me, and that work didn't have much visible effect either. I haven't seen anyone else reference this post while discussing a different problem. It's possible this happens out of sight (Lincoln Quirk implies this here), but if I'd achieved my goal it would be clearly visible.
(Self-review.) I claim that this post is significant for articulating a solution to the mystery of disagreement (why people seem to believe different things, in flagrant violation of Aumann's agreement theorem): much of the mystery dissolves if a lot of apparent "disagreements" are actually disguised conflicts. The basic idea isn't particularly original, but I'm proud of the synthesis and writeup. Arguing that the distinction between deception and bias is less decision-relevant than commonly believed seems like an improvement over hang-wringing over where the boundary is.
This essay is an example of the ancient LessWrong genre, "dumb mistakes your brain might be making which feel obvious once someone points them out." I love this genre, and think You Don't Get To Have Cool Flaws should be included in the Best Of LessWrong posts.
It's so easy to make this mistake! In fiction, complex and beloved characters have flaws. Fiction can set examples we try to live up to. Flaws are easier to emulate than virtues. I can't train as hard as Batman, and I can't be as wealthy as Batman, but I can brood! Brooding is easy! But the flaw isn'...
I think this post makes an important and still neglected claim that people should write their work more clearly and get it published in academia, instead of embracing the norms of the narrower community they interact with. There has been significant movement in this direction in the past 2 years, and I think this posts marks a critical change in what the community suggests and values in terms of output.
This remains the best overview of the learning-theoretic agenda to-date. As a complementary pedagogic resource, there is now also a series of video lectures.
Since the article was written, there were several new publications:
- Gergely Szűcs's article on interpreting quantum mechanics using infra-Bayesian physicalism.
- My paper on linear infra-Bayesian bandits.
- An article on infra-Bayesian haggling by my MATS scholar Hanna Gabor. This approach to multi-agent systems did not exist when the overview was written, and currently seems like the most promising direction
This post raises a large number of engineering challenges. Some of those engineering challenges rely on other assumptions being made. For example, the use of energy carrying molecules rather than electricity or mechanical power which can cross vacuum boundaries easily. Overall a lot of "If we solve X via method Y (which is the only way to do it) problem Z occurs" without considering making several changes at once that synergistically avoid multiple problems.
"Too much energy" means too much to be competitive with normal biological processes.
That goalpos...
This is a very nice meta-level discussion of why consciousness discourse gets so bad, and I do genuinely appreciate trying to get cruxes and draw out the generators of a disagreement, which is useful in difficult situations.
One factor that is not really discussed, but amplifies the problem of discourse around consciousness is that people use the word consciousness to denote a scientific and a moral thing, and people often want to know the answer to whether something is conscious because they want to use it to determine whether uploading is good, or whether...
I think this post is really helpful and has clarified my thinking about the different levels of AI alignment difficulty. It seems like a unique post with no historical equivalent, making it a major contribution to the AI alignment literature.
As you point out in the introduction, many LessWrong posts provide detailed accounts of specific AI risk threat models or worldviews. However, since each post typically explores only one perspective, readers must piece together insights from different posts to understand the full spectrum of views.
The new alignment dif...
Was a widely impactful piece of work, beyond the bounds of the less wrong community
This post attempts to describe a key disagreement between Karnofsky and Soares (written by Karnofsky) pertaining to the alignment protocol "train an AI to simulate an AI alignment researcher". The topic is quite important, since this is a fairly popular approach.
Here is how I view this question:
The first unknown is how accurate is the simulation. This is not really discussed in the OP. On the one hand, one might imagine that with more data, compute and other improvements, the AI should ultimately converge on an almost perfect simulation of an AI alignment ...
I often find myself revisiting this post—it has profoundly shaped my philosophical understanding of numerous concepts. I think the notion of conflationary alliances introduced here is crucial for identifying and disentangling/dissolving many ambiguous terms and resolving philosophical confusion. I think this applies not only to consciousness but also to situational awareness, pain, interpretability, safety, alignment, and intelligence, to name a few.
I referenced this blog post in my own post, My Intellectual Journey to Dis-solve the Hard Problem of Conscio...
This post argues that, while it's traditional to call policies trained by RL "agents", there is no good reason for it and the terminology does more harm than good. IMO Turner has a valid point, but he takes it too far.
What is an "agent"? Unfortunately, this question is not discussed in the OP in any detail. There are two closely related informal approaches to defining "agents" that I like, one more axiomatic / black-boxy and the other more algorithmic / white-boxy.
The algorithmic definition is: An agent is a system that can (i) learn models of its environm...
This series explains why we like some things and not others, including ideas. It's cutting edge psychological theory.
The truth should be rewarded. Even if it's obvious. Everyday this post is more blatantly correct.
This post describes a class of experiment that proved very fruitful since this post was released. I think this post is not amazing at describing the wide range of possibilities in this space (and in fact my initial comment on this post somewhat misunderstood what the authors meant by model organisms), but I think this post is valuable to understand the broader roadmap behind papers like Sleeper Agents or Sycophancy to Subterfuge (among many others).
This post makes an easy to digest and compelling case for getting serious about giving up flaws. Many people build their identity around various flaws, and having a post that crisply makes the case that doing so is net bad is helpful to be able to point people at when you see them suffering in this way.
I think this post is quite important because it is about Skin in the Game. Normally we love it, but here is the doubly-interesting case of wanting to reduce the financial version in order to allow the space for better thinking.
The content of the question is good by itself as a moment in time of thinking about the problem. The answers to the question are good both for what they contain, and also for what they do not contain, by which I mean what we want to see come up in questions of this kind to answer them better.
As a follow-up, I would like to see a more...
(Self review) I stand by this post, I think it's an important idea, I think not enough people are using this technique, and this adds nothing but a different way of writing something that was already in the rationalist canon.
If you do not sometimes stop, start a timer, think for five minutes, come to a conclusion and then move on, I believe you are missing an important mental skill and you should fix that. This skill helps me. I have observed some of the most effective people I know personally use this skill. You should at least try it.
You know what follow...
Speaking as someone in the process of graduating college fifteen years late, this is what I wish I knew twenty years ago. Send this to every teenager you know.
(Self review.) Bystander effect is fairly well known in the rationalist community. Quietly fading is not as widely recognized. Since writing this post, two people have told me and other people about projects they were dropping, specifically citing this post as the reason they said that aloud instead of just showing up less.
Mission (partially) accomplished.
Since crystalizing this concept, I've started paying more attention to 1. who owns a project and 2. when I last saw motion on that project. I stand by this post: it spotlights a real problem and makes a couple useful suggestions.
I think this is the most important statement on AI risk to date. Where ChatGPT brought "AI could be very capable" into the overton window, the CAIS Statement brought in AI x-risk. When I give talks to NGOs, or business leaders, or government officials, I almost always include a slide with selected signatories and the full text:
Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.
I believe it's true, that it was important to say, and that it's had an ongoing, large, and positive impact. Thank you again to the organizers and to my many, many co-signatories.
On the one hand, I agree with Paradiddle that the methodology used doesn't let us draw the conclusion stated at the end of this post, and thus this is an anti-example of a study I want to see on LW.
On the other hand, I do think the concept here is valuable, and I do have a high prior probability that something like a conflationary alliance is going on with consciousness, because it's often an input into questions of moral worth, and thus there is an incentive to both fight over the word, and make the word's use as wide or as narrow as possible.
I have to give this a -1 for it's misleading methodology (and not realizing this), for local validity reasons.
This post describes an intriguing empirical phenomenon in particular language models, discovered by the authors. Although AFAIK it was mostly or entirely removed in contemporary versions, there is still an interesting lesson there.
While non-obvious when discovered, we now understand the mechanism. The tokenizer created some tokens which were very rare or absent in the training data. As a result, the trained model mapped those tokens to more or less random features. When a string corresponding to such a token is inserted into the prompt, the resulting reply...
This post caused me to no longer use the standard evolution analogies when talking/thinking about alignment, and instead think more about the human reward system, how that is created via evolution, and how non-genome-encoded concepts are connected to value in human learning[1].
Notable as well is the implicit argument from a mismatch in amount of feedback-information received by current AI systems vs. the amount of feedback the human reward architecture has gotten through evolution—the former (through gradient descent) is much higher than the latter. The st...
Previously, I think I had mostly read this through the lens of "what worked for Elizabeth?" rather than actually focusing on which of this might be useful to me. I think that's a tradeoff on the "write to your past self" vs "attempt to generalize" spectrum – generalizing in a useful way is more work.
When I reread it just now, I found the "Ways to Identify Fake Ambition" the most useful section (both for the specific advice of "these emotional reactions might correspond to those motivations", and the meta-level advice of "check for your emotional reactions ...
This post proposes an approach to decision theory in which we notion of "actions" is emergent. Instead of having an ontologically fundamental notion of actions, the agent just has beliefs, and some of them are self-fulfilling prophecies. For example, the agent can discover that "whenever I believe my arm will move up/down, my arm truly moves up/down", and then exploit this fact by moving the arm in the right direction to maximize utility. This works by having a "metabelief" (a mapping from beliefs to beliefs; my terminology, not the OP's) and allowing the ...
I found this post very helpful in laying out a very good argument for weak claims that many truth seeking people with different values may be able to agree on. It clarifies a lot of the conversation about veganism so that misleading/confused arguments can be avoided.
The author says that her goal is to be clear and easy to argue with, and I think she succeeded in that goal.
It's striking that there are so few concrete fictional descriptions of realistic AI catastrophe, despite the large amount of fiction in the LessWrong canon. The few exceptions, like Gwern's here or Gabe's here, are about fast take-offs and direct takeover.
I think this is a shame. The concreteness and specificity of fiction make it great for imagining futures, and its emotional pull can help us make sense of the very strange world we seem to be heading towards. And slower catastrophes, like Christiano's What failure looks like, are a large fraction of a lot...
This post was an early articulation of many of the arguments and concepts that we mostly workshopped into the AI control research direction.
In particular, I think the final paragraph of the conclusion holds up really well:
...But I'm more excited about the meta level point here: I think that when AI developers are first developing dangerously powerful models, alignment researchers will be doing a very different kind of activity than what they do now. Right now, alignment researchers have to do a lot of long range extrapolation: they don't have access to either
I think about this post several times a year when evaluating plans.
(Or actually, I think about a nearby concept that Nate voiced in person to me, about doing things that you actually believe in, in your heart. But this is the public handle for that.)
This is the craziest shit I have ever read on LessWrong, and I am mildly surprised at how little it is talked about. I get that it's very close to home for a lot of people, and that it's probably not relevant to either rationality as a discipline or the far future. But like, multiple unsolved murders by someone involved in the community is something that I would feel compelled to write about, if I didn't get the vague impression that it'd be defecting in some way.
(Self review) I stand by this essay, and in particular I like having this essay to point to as an example of why some organizations are not holding the idiot ball quite as much as people might assume. This essay is somewhat self defense? I work like this most of the time these days.
Followup work on how to better juggle balls is useful, and basically leads into an existing field of management. If One Day Sooner is unusual startup mode, Never Drop A Ball is a very normal middle and end stage of many organizations, and for good reasons. It's also a genuinely ...
(Self-Review.)
I still endorse every claim in this post. The one thing I keep wondering is whether I should have used real examples from discussion threads on LessWrong to illustrate the application of the two camp model, rather than making up a fictional discussion as I did in the post. I think that would probably help, but it would require singling out someone and using them as a negative example, which I don't want to do. I'm still reading every new post and comment section about consciousness and often link to this post when I see something that looks l...
(Self-review.) I think this pt. 2 is the second most interesting entry in my Whole Dumb Story memoir sequence. (Pt. 1 deals with more niche psychology stuff than the philosophical malpractice covered here; pt. 3 is a more of a grab-bag of stuff that happened between April 2019 and January 2021; pt. 4 is the climax. Expect the denouement pt. 5 in mid-2025.)
I feel a lot more at peace having this out there. (If we can't have justice, sanity, or language, at least I got to tell my story about trying to protect them.)
The 8 karma in 97 votes is kind of funny in ...
I continue to be a fan of people trying to accomplish something in the world and reporting back on what happened. This is a good example of the genre, and on a subject near and dear to (part of) LessWrong's collective heart.
I confidently expect somebody will read a bunch of things on LessWrong, get excited about AI, and try to get the American government to Do Something. By default this attempt will not be particularly well aimed or effective, and every piece of information we can give on the obstacles will be useful. There have been updates since 2023 on ...
This site is a cool innovation but missing pieces required to be really useful. I’m giving it +1. I might give it +4 to subsidize ‘actually build shit’.
I think this site is on-the-path to something important but a) the UI isn't quite there and b) there's this additional problem where, well, most news doesn't matter (in that it doesn't affect my decisions).
During Ukraine nuclear scares, I looked at BaseRateTimes sometimes to try and orient, but I think it was less helpful than other compilations of prediction markets that Lightcone made specifically to help...
I sometimes use the notion of natural latents in my own thinking - it's useful in the same way that the notion of Bayes networks is useful.
A frame I have is that many real world questions consist of hierarchical latents: for example, the vitality of a city is determined by employment, number of companies, migration, free-time activities and so on, and "free-time activities" is a latent (or multiple latents?) on its own.
I sometimes get use of assessing whether a topic at hand is a high-level or low-level latent and orienting accordingly. For example: ...
There seems to be a largish group of people who are understandably worried about AI advances but have no hope of changing it, so start panicking. This post is a good reminder that yes, we're all going to die, but since you don't know when, you have to prepare for multiple eventualities.
Shorting life is good if you can pull it off. But the same caveats apply as to shorting the market.
I think this was a very good summary/distillation and a good critique of work on natural abstractions; I'm less sure it has been particularly useful or impactful.
I'm quite proud of our breakdown into key claims; I think it's much clearer than any previous writing (and in particular makes it easier to notice which sub-claims are obviously true, which are daring, which are or aren't supported by theorems, ...). It also seems that John was mostly on board with it.
I still stand by our critiques. I think the gaps we point out are important and might not be obvi...
This is an important distinction, otherwise you risk getting into unproductive discussions about someone's intent instead of focusing on whether a person's patterns are compatible with your or your group/community's needs.
It doesn't matter if someone was negligent or malicious: if they are bad at reading your nonverbal cues and you are bad at explicitly saying no to boundary crossing behaviors, you are incompatible and that is reason enough to end the relationship. It doesn't matter if someone is trying their best: if their best is still disruptive to your...
TL;DR: I still really like this text, but am unhappy I didn't update it/work on it in the last year. There's now research on the exact topic, finding attention spans have plausibly increased in adults.
Out of the texts I wrote in 2023, this one is my favorite: I had a question, tried to figure out the truth, saw that there was no easy answer and then dug deeper into the literature, producing the (at the time) state-of-the-art investigation into attention spans—sometimes often answered questions haven't been actually checked, yet everyone spouts nonsense abo...
Every time I think about rational discourse I think of this post. And I smile and chuckle a little.
I keep meaning to write a little followup titled something like:
An overlooked goddamn basic of rational discourse: Be Fucking Nice.
If you're fucking irritating, people are going to be irritated at the points you're making too, and they'll find reasons to disbelieve them. This is goddam motivated reasoning, and it's the bias fucking ruining our goddamn civilization. Don't let it ruin your rational fucking discourse.
Being fucking nice does not mean saying you a...
The main insight of the post (as I understand it) is this:
- In the context of a discussion of whether we should be worried about AGI x-risk, someone might say “LLMs don't seem like they're trying hard to autonomously accomplish long-horizon goals—hooray, why were people so worried about AGI risk?”
- In the context of a discussion among tech people and VCs about how we haven't yet made an AGI that can found and run companies as well as Jeff Bezos, someone might say “LLMs don't seem like they're trying hard to autonomously accomplish long-horizon goals—alas, let'
I think this is a useful concept that I use several times a year. I don't use the term Dark Forest I'm not sure how much that can be attributed to this post, but this post is the only relevant thing in the review so we'll go with that.
I also appreciate how easy to read and concise this post is. It gives me a vision of how my own writing could be shorter without losing impact.
This post didn't do well in the games of LessWrong karma, but it was probably the most personally fruitful use of my time on the site in 2023. It helped me clarify my own views which I had already formed but hadn't put to paper, or cohered properly.
I also got to think about the movement as a whole, and really enjoyed some of what Elizabeth had to share. Particularly I remember her commentary on the lack of positivity in the movement, and have taken that to heart and really thought about how I can add more positivity in.
This was a quick and short post, but some people ended up liking it a lot. In retrospect I should've written a bit more, maybe gone into the design of recent running shoes. For example, this Nike Alphafly has a somewhat thick heel made of springy foam that sticks out behind the heel of the foot, and in the front, there's a "carbon plate" (a thin sheet of carbon fiber composite) which also acts like a spring. In the future, there might be gradual evolution towards more extreme versions of the same concept, as recent designs become accepted. Running shoes wi...
I really enjoy this post, for two reasons: as a slice out of the overall aesthetic of the Bay Area Rationalist; and, as an honest-to-goodness reference for a number of things related to good interior decorating.
I'd enjoy seeing other slices of anthropology on the Rationalist scene, e.g. about common verbal tics ("this seems true" vs "that seems true," or "that's right," or "it wouldn't be crazy"), or about some element of history.
Knowing how much time we've got is important to using it well. It's worth this sort of careful analysis.
I found most of this to be wasted effort based on too much of an outside view. The human brain gives neither an upper nor lower bound on the computation needed to achieve transformative AGI. Inside views that include gears-level models of how our first AGIs will function seem much more valuable; thus Daniel Kokatijlo's predictions seem far better informed than the others here.
Outside views like "things take longer than they could, often a lot longer" are...
I appreciated the narrow focus of this post on a specific bug in PCEV and a specific criteria to use to catch similar bugs in the future. I was previously suspicious of CEV-like proposals so this didn't especially change my thinking, but it did affect others. In particular the arbital page on cev now has a note:
...Thomas Cederborg correctly observes that Nick Bostrom's original parliamentary proposal involves a negotiation baseline where each agent has a random chance of becoming dictator, and that this random-dictator baseline gives an outsized and potenti
I'd give this a +9 if I could*. I've been using this technique for 7 years. I think it's clearly paid off in "clear, legible lessons about how to think." But the most interesting question is "did the subtler benefits pay off, in 7 years of practice?"
Let's start with the legible
This was essentially the first step on the path towards Feedbackloop-first Rationality. The basic idea here is "Watch your thoughts as they do their thinking. Notice where your thoughts could be better, and notice where they are particularly good. Do more of that."
When I've ran...
I'm mildly against this being immortalized as part of the 2023 review, though I think it serves excellently as a community announcement for Bay Area rats, which seems to be its original purpose.
I think it has the most long-term relevant information (about AI and community building) back loaded and the least relevant information (statistics and details about a no-longer-existent office space in the Bay Area) front loaded. This is a very Bay Area centric post, which I don't think is ideal.
A better version of this post would be structured as a round up of the main future-relevant takeaways, with specifics from the office space as examples.
I think this essay is worth including in the Best Of LessWrong collection for introducing a good conceptual handle for a phenomenon it convinced me exists in a more general form than I'd thought.
It's talking about a phenomenon that's easy to overlook. I think the phenomenon is real; for a trivial example, look at any self reported graph of height and look at the conspicuous shortage at 5'11". It comes with lots of examples. Testing this is maddeningly tricky (it's hiding from you!) but doable, especially if you're willing to generalize from one or two exam...
My favorite Less Wrong posts are almost always the parables and the dialogues. I find it easier to process and remember information that is conveyed in this way. They're also simply more fun to read.
This post was originally written as an entry for the FTX Future Fund prize, which, at the time of writing the original draft, was a $1,000,000 prize, which I did not win, partly because it wasn't selected as the winner and partly because FTX imploded and the prize money vanished. (There is a lesson about the importance of proper calibration of the extrema of pr...
This post was a blog post day project. For its purpose of general sanity waterline-raising, I'm happy with how it turned out. If I still prioritized the kinds of topics this post is about, I'd say more about things like:
- "equilibrium" and how it's a misleading and ill-motivated frame for game theory, especially acausal trade;
- time-slice rationality;
- why the logical/algorithmic ontology for decision theory is far from obviously preferable.
But I've come to think there are far deeper and higher-priority mistakes in the "orthodox rationalist worldview" (scare quo...
This is just a self-study list for people who want to understand and/or contribute to the learning-theoretic AI alignment research agenda. I'm not sure why people thought it deserves to be in the Review. FWIW, I keep using it with my MATS scholars, and I keep it more or less up-to-date. A complementary resource that became available more recently is the video lectures.
This post describes important true characteristics of a phenomenon present in the social reality we inhabit. But importantly the phenomenon is a blind spot which is harder to notice when acting or speaking with a worldview constructed from background facts which suffer from the blind spot. It hides itself from the view of those who don't see it and act as if it isn't there. Usually bits of reality you are ignorant of will poke out more when acting in ignorance, not less. But if you speak as if you don't know about the dark matter you will be broadcasting t...
I stand by what I said here: this post asks an important question but badly mangles the discussion. I don't believe this fictional person weighed the evidence and came to a conclusion she is advocating for as best she can: she's clearly suffering from distorted thoughts and applying post-hoc justifications.
This is the story I use to express what a world where we fail looks like to left-leaning people who are allergic to the idea that AI could be powerful. It doesn't get the point across great, due to a number of things that continue to be fnords for left leaning folks which this story uses, but it works better than most other options. It also doesn't seem too far off what I expect to be the default failure case; though the factories being made of low-intelligence robotic operators seems unrealistic to me.
I opened it now to make this exact point.
I think this post cleanly and accurately elucidates a dynamic in conversations about consciousness. I hadn't put my finger on this before reading this post, and I noe think about it every time I hear or participate in a discussion about consciousness.
I'm glad I read this, and it's been a repeating line in my head when I've tried to make long term plans. I'd like this to be included in the Best Of LessWrong posts.
Even if you are doing something fairly standard and uncomplicated, there are likely multiple parts to what you do. A software engineer can look at a bunch of tickets, some code reviews, the gap where good documentation can be, and the deployment pipeline before deciding that the team is dropping the ball on documentation. A schoolteacher might look at the regular classes, the extracurricular pr...
MCE is a clear, incisive essay. Much of it clarified thoughts I already had, but framed them in a more coherent way; the rest straightforwardly added to my process of diagnosing interpersonal harm. I now go about making sense of most interpersonal issues through its framework.
Unlike Ricki/Avital, I haven't found that much use from its terminology with others, though I often come to internal conclusions generated by explicitly using its terminology then communicate those conclusions in more typical language. I wouldn't be surprised if I found greater ...
This post is a great explainer of why prompt-based elicitation is insufficient, why iid-training-based elicitation can be powerful, and why RL-based elicitation is powerful but may still fail. It also has the merit of being relatively short (which might not have been the case if someone else had introduced the concept of exploration hacking). I refer to this post very often.
Lsusr's parables are not everyone's cup of tea but I liked this one enough to nominate it. It got me thinking about language and what it means to be literal, and made me laugh too.
I give this a +9, one of the most useful posts of the year.
I think that a lot of these are pretty non-obvious guidelines that make sense when explained, and I continue to put effort in to practicing them. Separating observations and inferences is pro-social, making falsifiable claims is pro-social, etc.
I like this document both for carefully condensing the core ideas into 10 short guidelines, and also having longer explanations for those who want to engage with them.
I like that it’s phrased as guidelines rather than rules/norms. I do break these from time ...
I think this post is quite good, and gives a heuristic important to modeling the world. If you skipped it because of title + author, you probably have the wrong impression of its contents and should give it a skim. Its main problem is what's left unsaid.
Some people in the comments reply to it that other people self-deceive, yes, but you should assume good faith. I say - why not assume the truth, and then do what's prosocial anyways?
[Perfunctory review to get this post to the final phase]
Solid post. Still good. I think a responsible developer shouldn't unilaterally pause but I think it should talk about the crazy situation it's in, costs and benefits of various actions, what it would do in different worlds, and its views on risks. (And none of the labs have done this; in particular Core Views is not this.)
In addition to being hauntingly beautiful, this story helped me adjust to the idea of the trans/posthuman future.
14 years ago, I very much did not identify with the Transhuman Vision. It was too alien, too much, and I didn't feel ready for it. I also didn't actively oppose it. I knew that slowly, as I hung out around rationalists, I would probably slowly come to identify more with humanity's longterm future.
I have indeed come to identify more with the longterm future and all of it's weirdness. It was mostly not because of this story, but I did particularly...
Just a quick review: I think this is a great text for intuitive exploration of a few topics
- how do the embedding spaces look like?
- how do vectors not projecting to "this is a word" look like
- how can poetry work, sometimes (projecting non-word meanings)
Also I like the genre of through phenomenological investigations, seems under-appreciated
This post suggests an analogy between (some) AI alignment proposals and shell games or perpetuum mobile proposals. Pertuum mobiles are an example how an idea might look sensible to someone with a half-baked understanding of the domain, while remaining very far from anything workable. A clever arguer can (intentionally or not!) hide the error in the design wherever the audience is not looking at any given moment. Similarly, some alignment proposals might seem correct when zooming in on every piece separately, but that's because the error is always hidden aw...
I think this post was useful in the context it was written in and has held up relatively well. However, I wouldn't active recommend it to anyone as of Dec 2024 -- both because the ethos of the AIS community has shifted, making posts like this less necessary, and because many other "how to do research" posts were written that contain the same advice.
Background
This post was inspired by conversations I had in mid-late 2022 with MATS mentees, REMIX participants, and various bright young people who were coming to the Bay to work on AIS (collectively, "kid...
This post is a collection of claims about acausal trade, some of which I find more compelling and some less. Overall, I think it's a good contribution to the discussion.
Claims that I mostly agree with include:
- Acausal trade in practice is usually not accomplished by literal simulation (the latter is mostly important as a convenient toy model) but by abstract reasoning.
- It is likely to be useful to think of the "acausal economy" as a whole, rather just about each individual trade separately.
Claims that I have some quibbles with include:
- The claim that there is
Much like "Let's think about slowing down AI" (Also by KatjaGrace, ranked #4 from 2022), this post finds a seemly "obviously wrong" idea and takes it completely seriously on its own terms. I worry that this post won't get as much love, because the conclusions don't feel as obvious in hindsight, and the topic is much more whimsical.
I personally find these posts extremely refreshing, and they inspire me to try to question my own assumptions/reasoning more deeply. I really hope to see more posts like this.
This post fits well on LessWrong because it is both about AI risk and about rationality. W.r.t. the latter, this post explores the concept of predictable updating (what it means & what to do about it) with a vivid real world example from the author's own life.
As I already commented, I think the numbers here are such that the post should be considered quite important even though I agree that it fails at establishing that fish can suffer (and perhaps lacks comparison to fish in the wild). If there was another post with a more nuanced stance on this point, I'd vote for that one instead, but there isn't. I think fish wellbeing should be part of the conversation more than it is right now.
It's also very unpleasant to think or write about these things, so I'm also more willing to overlook flaws than I'd be by default.
I don't think this really qualifies for year's best. It's interesting if you think or have to explain to someone who thinks "just raise an RL mechanism in a human environment and it would come out aligned, right?" I'm surprised anyone thinks that, but here's a pretty good writeup of why you shouldn't.
The biggest portion is about why we shouldn't expect an AGI to become aligned by exposing an RL system to a human - like environment. A child, Alexander says, might be punished for stealing a cookie, and it could internalize the rule "don't get caught stealing...
I'm very grateful I found Tristan and we were able to have this discussion.
My series on vegan nutrition epistemics generated a lot of friction and hostility. Tristan was one of very few vegan advocates I felt I learned things from, and the things I learned were valuable and beautiful. The frame of impractical reverence continues to come up and I'm glad I can recognize it now. I am also happy this primed me to recognize what I don't like about reverence as a frame, and refine my articulation of my own values.
A neat stylised fact, if it's true. It would be cool to see people checking it in more domains.
I appreciate that Ege included all of examples, theory, and predictions of the theory. I think there's lots of room for criticism of this model, which it would be cool to see tried. In particular, as far as I understand the formalism, it doesn't seem like it is obviously discussing the costs of the investments, as opposed to their returns.
But I still like this as a rule of thumb (open to revision).
I continue to think there's something important in here!
I haven't had much success articulating why. I think it's neat that the loop-breaking/choosing can be internalized, and not need to pass through Lob. And it informs my sense of how to distinguish real-world high-integrity vs low-integrity situations.
The general exercise of reviewing prior debate, now that ( some of ) the evidence is come in, seems very valuable, especially if one side of the debate is making high level claims that their veiw has been vindicated.
That said, I think there were several points in this post where I thought the author's read of the current evidence is/was off or mistaken. I think this overall doesn't detract too much from the value of the post, especially because it prompted discussion in the comments.
This early control post introduced super important ideas: trusted monitoring plus the general point
if you think about approaches to safely using AIs that are robust to deceptive alignment and which can be used right now, a core dynamic is trying to use your dumb trusted models together with your limited access to trusted humans to make it hard for your untrusted smart models to cause problems.
I think this post was and remains important and spot-on. Especially this part, which is proving more clearly true (but still contested):
It does not matter that those organizations have "AI safety" teams, if their AI safety teams do not have the power to take the one action that has been the obviously correct one this whole time: Shut down progress on capabilities. If their safety teams have not done this so far when it is the one thing that needs done, there is no reason to think they'll have the chance to take whatever would be the second-best or third-best actions either.
"The ants and the grasshopper" is a beautifully written short fiction piece that plays around with the structure and ending of the classic Aesop fable: the ants who prepare for winter, and the grasshopper who does not.
I think there's often a gap between how one thinks through the implications that a certain decision process would have on various difficult situations in the abstract, and how one actually feels while following through (or witnessing others follow through). It's pretty easy to point at that gap's existence, but pretty hard to reason well abou...
TL;DR: This post gave me two extremely useful handles to talk about a kind of internal struggle I've been grappling with for as long as I've been in the EA community.
This post seemed obviously true when I read it and I started reusing the concept in conversations, but it did not lead to a lot of internal changes. However, a few months later, having completely forgotten this post, I started practicing self therapy using Internal Family Systems, and then I uncovered a large conflict which after multiple sessions seemed to map really well to the two archetype...
I really like this paper (though, obviously, am extremely biased). I don't think it was groundbreaking, but I think it was an important contribution to mech interp, and one of my favourite papers that I've supervised.
Superposition seems like an important phenomena that affects our ability to understand language models. I think this paper was some of the first evidence that it actually happens in language models, and on what it actually looks like. Thinking about eg why neurons detecting compound words (eg blood pressure) were unusually easy to represent in...
This post engages substantively and clearly with IMO the first or second most important thing we could be accomplishing on LW: making better estimates of how difficult alignment will be.
It analyzes how people who know a good deal about alignment theory could say something like "AI is easy to control" in good faith - and why that's wrong, in both senses.
What Belrose and Pope were mostly saying, without being explicit about it, is that current AI is easy to control, then extrapolating from there by basically assuming we won't make any changes to AI in the future that might dramatically change this situation.
This post addresses this and more subtle points, clarifying the discussion.
I find myself going back to this post again and again for explaing the Natural Abstraction Hypothesis. When this came out I was very happy as I finally had something I could share on John's work that made people understand it within one post.
This article studies a natural and interesting mathematical question: which algebraic relations hold between Bayes nets? In other words, if a collection of random variables is consistent with several Bayes nets, what other Bayes nets does it also have to be consistent with? The question is studied both for exact consistency and for approximate consistency: in the latter case, the joint distribution is KL-close to a distribution that's consistent with the net. The article proves several rules of this type, some of them quite non-obvious. The rules have conc...
I think this should be included in the Best Of LessWrong posts.
This post exemplifies the virtue of scholarship, of looking at every field and skillset as one more source of information. It's well packaged into specific lessons and it comes from someone who can speak in both the Rationalist idiom and the local idiom. It's also on a subject many of us are working on: EA and LW nonprofits do work alongside 'normal' charities, and it's helpful to see their different views and frames. I'd be delighted by a dozen posts like this, field reports from other fields ...
It's a fine post, but I don't love this set of recommendations and justifications, and I feel like rationalist norms & advice should be held to a high standard, so I'm not upvoting it in the review. I'll give some quick pointers to why I don't love it.
- Truth-Seeking: Seems too obvious to be useful advice. Also I disagree with the subpoint about never treating arguments like soldiers, I think two people inhabiting opposing debate-partners is sort of captured by this and I think this is a healthy truth-seeking process.
- Non-Violence: All the examples of thi
+9. This argues that some key puzzle pieces of genius include "solitude," and "sitting with confusion until open-curiosity allows you to find the right questions." This feels like an important key that I'm annoyed at myself for not following up on more.
The post is sort of focused on "what should an individual do, if they want to cultivate the possibility of genius?".
One of the goals I have, in my work at Lightcone, is to ask "okay but can we do anything to foster genius at scale, for the purpose of averting x-risk?". This might just be an impossible ...
I think this is an interesting answer, and it does have some use even outside of the scenario, but I do think that the more likely answer to the problem probably rests upon the rareness of life, and in particular the eukaryote transition is probably the most likely great filter, because natural selection had to solve a coordination problem, combined with this step only happening once in earth's history, compared to all the other hard steps.
That said, I will say some more on this topic, if only to share my models:
...
- The universe might be too large for expon
(Self review) I stand by this essay and think more people should read it, though they don't need to read it deeply.
I think some people knew this kind of work and so this serves as a pointer to "yeah, that thing we did at my last company" and some people did not realize this was an option. Making people aware of potentially exciting options they could choose in life is (in my opinion) a good use of an essay. In my ideal world everyone would read something describing the One Day Sooner mindset as they were choosing their first careers so they could hav...
Discussed tangible directions for research in agent foundations, which was really useful for helping me find a foothold for what people in this field "actually" work on.
I'm also keen in general of this approach of talking about your plans and progress yearly, I think it would be great if everyone doing important things (research and else) would publish something similar. It helps with perspective building of both the person writing the post itself, but also about how the field has changed as seen through their eyes.
(Self review) Do I stand by this post? Eh. Kinda sorta but I think it's incomplete.
I think there's something important in truth-telling, and getting everyone on the same page about what we mean by the truth. Since everyone will not just start telling the literal truth all the time and I don't even particularly want them to, we're going to need to have some norms and social lubricant around how to handle the things people say that aren't literal truth.
The first thing I disagree with when rereading it is sometimes even if someone is obviously and strai...
I might be a niche example, but the Dark Forest Theory as applied to meetups was novel to me and affects how I approach helping rationality meetups.
Sometimes they're not advertised for good reasons, even if those reasons aren't articulated. It sure does seem to make accurate claims about meetups from my observation, where when I notice an odd dearth of meetups in an area where it seems like there should be more meetups, sometimes I find out they exist they're just not as public and also nobody seems to have told the more frustrating quarter of the lo...
This article provides a concrete, object-level benchmark for measuring the faithfulness of CoT. In addition to that, a new method for improving CoT faithfulness is introduced (something that is mentioned in a lot of alignment plans).
The method is straightforward and relies on breaking questions into subquestions. Despite its simplicity, it is surprisingly effective.
In the future, I hope to see alignment plans relying on CoT faithfulness incorporate this method into their toolkit.
So I think the first claim here is wrong.
Let’s start with one of those insights that are as obvious as they are easy to forget: if you want to master something, you should study the highest achievements of your field. If you want to learn writing, read great writers, etc.
If you want to master something, you should do things that causally/counter factually increase your ability (in the order of most to least cost-effective). You should adopt interventions that actually make you better compared to the case that you haven't done them.
Any intervent...
I think this post was important, and pointing out a very real dynamic. It also seems to have sparked some conversations about moderation on the site, and so feels important as a historical artifact. I don't know if it should be in the Best Of, but I think something in this reference class should be.
An (intentionally) shallow collection of AI alignment agendas that different organizations are working on.
This is the post I come back to when I want to remind myself what agendas different organizations are pursuing.
Overall, it is a solid and comprehensive post that I found very useful.
This letter was an important milestone in the evolution of MIRI's strategy over 2020-2024. As of October 2023 Yudkowsky is MIRI's chair and "the de facto reality (is) that his views get a large weight in MIRI strategic direction".
MIRI used to favor technical alignment over policy work. In April 2021, in comments to Death with Dignity Yudkowsky argued that:
...How about if you solve a ban on gain-of-function research first, and then move on to much harder problems like AGI? A victory on this relatively easy case would result in a lot of valuable gained exper
I have been thinking about interpretability for neural networks seriously since mid-2023. The biggest early influences on me that I recall were Olah's writings and a podcast that Nanda did. The third most important is perhaps this post, which I valued as an opposing opinion to help sharpen up my views.
I'm not sure it has aged well, in the sense that it's no longer clear to me I would direct someone to read this in 2025. I disagree with many of the object level claims. However, especially when some of the core mechanistic interpretability work is not being subjected to peer review, perhaps I wish there was more sceptical writing like this on balance.
One of the few high-quality papers on automatic deception detection in black-box LLMs.
Asking completely unrelated questions is a simple yet effective way of catching AI red-handed. In addition, this lie detector generalizes well to 1) other LLM architectures, 2) LLMs fine-tuned to lie, 3) sycophantic lies, and 4) lies emerging in real-life scenarios such as sales.
Despite the solution's simplicity, the paper has been relatively overlooked in LessWrong community. I am hoping to see more future work combining this lie detector with techniques like those presented in Bürger et al., 2024
This article is an excellent foundation for alignment plans relying on faithful CoT reasoning.
Its main contributions include 1) evaluating the density of hidden information that steganography schemes can maintain in the presence of various defenses and 2) developing an effective mitigation strategy (paraphrasing).
Overall, this article is easy to follow, detailed, and insightful.
(Self review)
Basically I stand by this post and I think it makes a useful addition to the conversation.
"Motte and bailey" is one of the pieces of rationalist lexicon that has wound up fairly widespread. It's also easy to misuse, because "America" or "Catholics" or "The military industrial complex" are made up of lots of different people who might legitimately different views. The countercharm is recognizing that, and talking to specific people. "Here's a way to be wrong, here's a way to be less wrong" seems a worthwhile addition to LessWrong.
Does it make a...
Zack complicates the story in Causal Diagrams and Causal Models, in an indirect way. There's a bit of narrative thrown in for fun. I enjoyed this in 2023 but less on re-reading.
I don't know if the fictional statistics have been chosen carefully to allow multiple interpretations, or if any data generated by a network similar to the "true" network would necessarily also allow the "crazy" network. Maybe it's the second, based on Wentworth's comment that there are "equivalent graph structures" (e.g. A -> B -> C vs A <- B <- C vs A <- B -> C)....
Self-review: It's been long enough that I've forgotten most of the details of the post, so it's a good time to re-read it and get a sense of what it reads like for someone who's discovering the content for the first time. I still believe most of the ideas here are correct. My goal here was to write a bottom-up overview of how the basic molecular structure of DNA might "inevitably" lead to stuff like sexually-dimorphic ornaments, after a long chain of events. The point I wanted to get at was that the male/female binary, which human cultures often depict as ...
I think this post made an important point that's still relevant to this day.
If anything, this post is more relevant in late 2024 than in early 2023, as the pace of AI makes ever more people want to be involved, while more and more mentors have moved towards doing object level work. Due to the relative reduction of capacity in evaluating new AIS researchers, there's more reliance on systems or heuristics to evaluate people now than in early 2023.
Also, I find it amusing that without the parenthetical, the title of the post makes another important point: "evals are noisy".
What would happen if I got some friends together and we all decided to be really dedicatedly rational?
This is an important scenario to reason about if I want to be a rationalist, and I think my predictions about that scenario are more calibrated than they would be in a world where I didn't read this post. Specifically, my predictions in light of this post have way, way fatter tails.
My recommendation for this essay's inclusion in the Best Of LessWrong collection comes down to two questions.
- Are the places decorated like this actually that nice?
- Is this a useful guide for creating those spaces?
Having been to Lighthaven (Lightcone's venue) a lot over the last year, I think the answer to 1. is a straightforward yes. Lots of other people love Lighthaven. It's possible that this style doesn't work if you're putting less oomph into it than Lightcone put into Lighthaven. I've visited a couple of homes decorated like this and think the style wo...
I found Steven Byrnes valence concept really useful for my own thinking about psychology more broadly and concretely when reading text messages from my contextualizing friend (in that when a message was ambiguous, guessing the correct interpretation based on valence worked surprisingly well for me).
I think this was a valuable post, albeit ending up somewhat incorrect about whether LLMs would be agentic - not because they developed the capacity on their own, but because people intentionally built and are building structure around LLMs to enable agency. That said, the underlying point stands - it is very possible that LLMs could be a safe foundation for non-agentic AI, and many research groups are pursuing that today.
This was fun to look back on a year later.
I like how thoroughly I owned it. How it's clearly wild speculation that tries to weave together some questionable observations. I also like the questions it raises. I remember how the basic hypothesis — that sexual signaling maybe evolved largely to aim at one's own sex in the human social context — helped me to notice some interesting questions I hadn't picked up on before. (E.g., why does slut-shaming seem to more target women who doll up for the male gaze instead of women who are actually pretty openly DTF when...
Mostly, I think it should be acknowledged that certain people saw dynamics developing beforehand and called it out. This is not a highly upvoted post but with the recent uptick in US vs China rhetoric it seems good to me to give credit where credit is due.
This post helped nudge me toward Feedbackloop Rationality, but the stated solution feels kinda cheating – it wouldn't have occurred to me that doing a complete run-to-the-end-of-the-ramp was allowed (it seems like the rules explicitly imply they can't?).
I haven't actually done this exercise, nor used it in my workshops. I think it's probably a mistake that I haven't actually tried it at all. As I sit and think about it now, it doesn't seem that hard to patch the exercise so it doesn't feel like cheating, and a fixed version seems worth trying at Cogn...
I... think that reading personal accounts of psychotic people is useful for understand the range of the human psyche and what insanity looks like? My guess is that on the margin it would be good for most people to have a better understanding of that, and reading this post will help, so I'm giving this a +1 for the LW review.
I missed the review notification while it would have been timely, but it's worth writing a self-review now that I've seen the notification.
I continue to endorse this post in full and believe subsequent events have borne out my decision to write and publish it as I did, when I did. At the time, Lightcone mentioned they were working on another reply to Nonlinear, and it would have been better to wait before writing a comprehensive reaction. Almost a year and a half later, no reply ever came. Looking back at this sequence of events, I remain impressed with th...
This story is moved me a lot, and I am giving it a substantial vote,
But... I do still really wish this line...
And they turn away and go back to their work—all except for one, who brushes past the grasshopper and whispers “Meet me outside at dusk and I’ll bring you food. We can preserve the law and still forgive the deviation.”
Came where it originally was located, significantly later in the post, after these sections:
...The ants start to receive dozens of requests for food, then hundreds—and while many are fraudulent, enough are real that they are moved to act
This is an interesting post, that while not very relevant on it's own, might become relevant in the future.
More importantly, it's a scenario where rational agents can outperform irrational agents.
+1 for this, which while minor, still matters.
Evidence that adult cognition can be improved is heartening. I'd always had a small amount of fear regarding being "locked in" to my current level of intelligence with no meaningful scope for improvement. Long ago, in a more naive age, it was the prospect of children being enhanced to leave their parents in the dirt. Now, it looks like AI is improving faster than our biotechnology is.
It's always a pleasure to read deep dives into genetic engineering, and this one was uniquely informative, though that's to be expected from GeneSmith.
For this review, I'd probably give it a +4, mostly for nicely summarizing the book well, but also because Daniel Dennett made some very useful productive mistakes, and identified a very important property that has to be explained, no matter what theory you choose, and I'll describe it here.
The important property is that the brain is distributed, and this matters.
For the most likely theory by far on how consciousness actually works in the general case, see my review of Anil Seth's theory, and the summary is that Anil Seth's theory broadly solves the hard pr...
I basically think @sunwillrise got it correct, so I'm basically going to link to it, but I will expand on the implications below:
I'd probably put somewhat less weight on the innateness of it, but still very valuable here.
I'd especially signal boost this, which argues for being more specific, and I basically agree with that recommendation, but also I think this is why we need to be able to decouple moral/valence assignments from positive facts, and yo...
This post is essentially talking about an issue that arises even without AI alignment, and that is relevant for capitalism, and the big issue is that AI will by default give people the ability to replace humans, making those humans essentially superfluous, and often it's not good when a human has no leverage.
This post is a +4 for me, if only because this is the first good argument against something like a capitalist economic order surviving AGI for me, and importantly doesn't ideologize like so many critiques of capitalism do.
As a New User to LessWrong, my calculations show that the post certainly did its job! (n=1 p=0)
At the time, I remarked to some friends that it felt weird that this was being presented as a new insight to this audience in 2023 rather than already being local conventional wisdom.[1] (Compare "Bad Intent Is a Disposition, Not a Feeling" (2017) or "Algorithmic Intent" (2020).) Better late than never!
The "status" line at the top does characterize it as partially "common wisdom", but it's currently #14 in the 2023 Review 1000+ karma voting, suggesting novelty to the audience. ↩︎
This post states and speculates on an important question: are there different mind types that are in some sense "fully general" (the author calls it "unbounded") but are nevertheless qualitatively different. The author calls these hypothetical mind taxa "cognitive realms".
This is how I think about this question, from within the LTA:
To operationalize "minds" we should be thinking of learning algorithms. Learning algorithms can be classified according to their "syntax" and "semantics" (my own terminology). Here, semantics refers to questions such as (i) what...
"POC || GTFO culture" need not be literal, and generally cannot be when speculating about future technologies. I wouldn't even want a proof-of-concept misaligned superintelligence!
Nonetheless, I think the field has been improved by an increasing emphasis on empiricism and demonstrations over the last two years, in technical research, in governance research, and in advocacy. I'd still like to see more carefully caveating of claims for which we have arguments but not evidence, and it's useful to have a short handle for that idea - "POC || admit you're unsure", perhaps?
I broadly agree with the post on the Free Energy Principle, but I do think some clarifications are called for here, so I'll do so:
For example, I'll elaborate on what these quotes mean here:
It is widely accepted that FEP is an unfalsifiable tautology, including by proponents—see for example Beren Millidge, or Friston himself.
...By the same token, once we find a computer-verified proof of any math theorem, we have revealed that it too is an unfalsifiable tautology. Even Fermat’s Last Theorem is now known to be a direct logical consequence of the axioms of
This is a surprisingly easy post to review, and my take is that the core mathematical result is accurate, given the assumptions (it's very hard to predict where the pinball will go next exactly without infinite compute, even over a surprisingly low amount of bounces), but the inferred result that this means that there are limits to what an intelligence could do in controlling the world is wrong, because the difficulty of predicting something is unrelated to the difficulty of controlling something, and more importantly this claim here is wrong, and it's eas...
This was a helpful post in the sporadic LessWrong theme of "how to say technically correct things instead of technically incorrect things". It's in the LLM context, but of course it applies to humans too. When a child says "I am a fairy", I record that in my diary as "Child claims to be fairy" not "Child is fairy", because I am not quite that "gullible".
Like many technically incorrect things, "gullibility" is common and practical. My diary might also say "Met John. Chemist. Will visit me on Friday lunch to discuss project". It would be more technically cor...
This post resonated with me when it came out, and I think its thesis only seems more credible with time. Anthropic's seminal "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet" (the Golden Gate Claude paper) seems right in line with these ideas. We can make scrutable the inscrutable as long as the inscrutable takes the form of something organized and regular and repeatable.
This article gets bonus points for me for being succinct and while still making its argument clearly.
I remember reading this and getting quite excited about the possibilities of using activation steering and downstream techniques. The post is well written with clear examples.
I think that this directly or indirectly influenced a lot of later work in steering llms.
I think this a helpful overview post. It outlines challenges to a mainstream plan (bootstrapped alignment) and offers a few case studies of how entities in other fields handle complex organizational challenges.
I'd be excited to see more follow-up research on organizational design and organizational culture. This work might be especially useful for helping folks think about various AI policy proposals.
For example, it seems plausible that at some point the US government will view certain kinds of AI systems as critical national security assets. At that...
I really liked this post when I read it, even though I didn't quite understand it to my satisfaction (and still don't).
As far as I understand the post, it proposes a concrete & sometimes fleshed-out solution for the perennial problem of asking forecasting questions: How do I ask a forecasting question that actually resolves the way I want it to, in retrospective, and doesn't just fall on technicalities?
The proposed solution is latent variables and creating prediction markets on them: The change in the world (e.g. AI learning to code) is going to affect...
Have agentized LLMs changed the alignment landscape? I'm not sure.
People are doing a bunch of work on LLM alignment, which is definitely useful for aligning an agent built on top of that LLM. But it's not the whole picture, and I don't see as many people as I'd like thinking about agent-specific alignment issues.
But I still expect agentized LLMs to change the alignment landscape. They still seem pretty likely to be the first transformative and dangerous AGIs.
Progress has been a bit slower than I expected. I think there are two main reasons:
Chain of thought...
On the object level, this is a study about personality, and it majorly changed the way I view some personality traits:
- I now see conservatism/progressivism as one of the main axes of personality,
- It further cemented my perception that "well-being", or "extraversion minus neuroticism", is the strongest of the traditional personality dimensions, and that maybe also this raises questions about what personality even means (for instance, surely well-being is not simply a biological trait),
- I'm now much more skeptical about how "real" many personality traits are, i
Prediction markets are good at eliciting information that correlates with what will be revealed in the future, but they treat each piece of information independently. Latent variables are a well-established method of handling low-rank connections between information, and I think this post does a good job of explaining why we might want to use that, as well as how we might want to implement them in prediction markets.
Of course the post is probably not entirely perfect. Already shortly after I wrote it, I switched from leaning towards IRT to leaning towards ...
I think this post is very funny (disclaimer: I wrote this post).
A number of commenters (both here and on r/slatestarcodex) think it's also profound, basically because of its reference to the anti-critical-thinking position better argued in the Michael Huemer paper that I cite about halfway through the post.
The question of when to defer to experts and when to think for yourself is important. This post is fun as satire or hyperbole, though it ultimately doesn't take any real stance on the question.
As someone who expects LLMs to be a dead end, I nonetheless think this post makes a valid point and does so using reasonable and easy to understand arguments. I voted +1.
This is a strong candidate for best of the year. Clarifying the arguments for why alignment is hard seems like one of the two most important things we could be working on. If we could make a very clear argument for alignment being hard, we might actually have a shot at getting a slowdown or meaningful regulations. This post goes a long way toward putting those arguments in plain language. It stands alongside Zvi's On A List of Lethalities, Yudkowsky's original AGI Ruin: A List of Lethalities, Ruthenis' A Case for the Least Forgiving Ta...
A great, short post. I think it retreads some similar ground that I aim to point at in A Sketch of Good Communication, and I think in at least one important regard it does much better. I give this +4.
I like something about this post. It might just be the way it's setting up to save conversations that are going sideways. Anyway, I'd be interested to hear from the author how much use this post ended up getting. For now, I'll give it a positive vote in the review.
I re-read about 1/3rd of this while looking through posts to nominate. I think it's an account of someone who believes in truth-seeking, engaging with the messy political reality of an environment that cared about the ideals of truth-seeking far more than most other places on earth, and finding it to either fall short or sometimes betray those ideals. Personally I find a post like this quite helpful to ruminate on and read, to think about my ideals and how they can be played out in society.
I can't quickly tell if it is the right thing for the LW review or ...
Perhaps one of the more moving posts I've read recently, of direct relevance to many of us.
I appreciate the simplicity and brevity in expressing a regret that resonate strongly with.
This was a fun little exercise. We get many "theory of rationality" posts on this site, so it's very good to also have some chances to practice figuring out confusing things also mixed in. The various coins each teach good lessons about ways the world can surprise you.
Anyway, I think this was an underrated post, and we need more posts in this general category.
Self review: I really like this post. Combined with the previous one (from 2022), it feels to me like "lots of people are confused about Kelly betting and linear/log utility of money, and this deconfuses the issue using arguments I hadn't seen before (and still haven't seen elsewhere)". It feels like small-but-real intellectual progress. It still feels right to me, and I still point people at this when I want to explain how I think about Kelly.
That's my inside view. I don't know how to square that with the relative lack of attention the post got, and it fe...
This post helped me distinguish capabilities-y information that's bad to share from capabilities-y information that's fine/good to share. (Base-model training techniques are bad; evals and eval results are good; scaffolding/prompting/posttraining techniques to elicit more powerful capabilities without more spooky black-box cognition is fine/good.)
I really like cohabitive games. I enjoy playing this one. I'm somewhat mixed on this post in particular being in the Best Of LessWrong collection. Cohabitive Games So Far looks like it's doing two things; it's outlining what a cohabitive game is and why it's interesting, and it's describing one specific cohabitive game but not in enough detail to play it.
For the first part (outlining what a cohabitive game is and why it's interesting) I prefer Competitive, Cooperative, and Cohabitive. (Though I wrote Competitive, Cooperative, and Cohabitive, so I mig...
That most developed countries, and therefore most liberal democracies, are getting significantly worse over time at building physical things seems like a Big Problem (see e.g. here). I'm glad this topic got attention on LessWrong through this post.
The main criticism I expect could be levelled on this post is that it's very non-theoretical. It doesn't attempt a synthesis of the lessons or takeaways. Many quotes are presented but not analysed.
(To take one random thing that occurred to me: the last quote from Anduril puts significant blame on McNamara. From m...
This post rings true to me because it points in the same direction as many other things I've read on how you cultivate ideas. I'd like more people to internalise this perspective, since I suspect that one of the bad trends in the developed world is that it keeps getting easier and easier to follow incentive gradients, get sucked into an existing memeplex that stops you from thinking your own thoughts, and minimise the risks you're exposed to. To fight back against this, ambitious people need to have in their heads some view of how uncomfortable chasing of ...
I don't know how to quickly convey why I find this point so helpful, but I find this to be a helpful pointer to a key problem, and the post is quite short, and I hope someone else positively votes on it. +4.
I think there's a decent chance this post inspires someone to develop methods for honing a highly neglected facet of collective rationality. The methods might not end up being a game. Games are exercises but most practical learning exercises aren't as intuitively engaging or strategically deep as a game. I think the article holds value regardless just for having pointed out that there is this important, neglected skill.
Despite LW's interest in practical rationality and community thereof, I don't think there's been any discussion of this social skill of ack...
This post made me deeply ruminate on what a posthuman future would look like, particularly the issue of "fairness" or what humanity (or recognizable descendants) could plausibly ask of far more optimized beings. Beings that may or may not be altruistic or hold charitable thoughts towards theirs progenitors and their more direct descendants.
The blogpost this points to was an important contribution at the time, more clearly laying out extreme cases for the future. (The replies there were also particularly valuable.)
+9. This is at times hilarious, at times upsetting story, of how a man gained a massive amount of power and built a corrupt empire. It's a psychological study, as well as a tale of a crime, hand-in-hand with a lot of naive ideologues.
I think it is worthwhile for understanding a lot about how the world currently works, including understanding individuals with great potential for harm, the crooked cryptocurrency industry, and the sorts of nerds in the world who falsely act in the name of good.
I don't believe that all the details here are fully accurate, but ...
I'm not super sure what I think of this project. I endorse the seed of the idea re "let's try to properly reverse engineer what representing facts in superposition looks like" and think this was a good idea ex ante. Ex post, I consider our results fairly negative, and have mostly confused that this kind of thing is cursed and we should pursue alternate approaches to interpretability (eg transcoders). I think this is a fairly useful insight! But also something I made from various other bits of data. Overall I think this was a fairly useful conclusion re upd...
Sharing well-informed, carefully-reasoned scenarios of how things might go right or wrong helps figure out how to steer the future.
This post was important in retrospect.
If only we'd all read it and listened.
The central point was "don't fan the flames of an AI race with China by carelessly suggesting it's already happening or inevitable".
The central example is that saying something like "China has made numerous attempts to bypass restrictions on chip imports" is inflammatory when the truth is something more like "some companies in China have been getting chips in ways that bypass restrictions on chip imports, but we don't think the Chinese government probably had anything to do with it".
I personally believe that this post is very important for claims between Shard Theory vs Sharp Left Turn. I often find that other perspectives on the deeper problems in AI alignment are expressed and I believe this to be a lot more nuanced take compared to Quentin Pope's essay on the Sharp Left Turn as well as the MIRI conception of evolution.
This is a field of study and we don't know what is going on, the truth is somewhere in between and acknowledging anything else is not being epistemically humble.
The post showcases the inability of the aggregate LW community to recognize locally invalid reasoning: while the post reaches a correct conclusion, the argument leading to it is locally invalid, as explained in comments. High karma and high alignment forum karma shows a combination of famous author and correct conclusion wins over the argument being correct.
I think this post is important because it brings old insights from cybernetics into a modern frame that relates to how folks are thinking about AI safety today. I strongly suspect that the big idea in this post, that ontology is shaped by usefulness, matters greatly to addressing fundamental problems in AI alignment.
I disagree with the first half of this post, and agree with the second half.
"Physicist Motors" makes sense to me as a topic. If I imagine it as a book, I can contrast it with other books like "Motors for Car Repair Mechanics" and "Motors for Hobbyist Boat Builders" and "Motors for Navy Contract Coordinators". These would focus on other aspects of motors such as giving you advice for materials to use and which vendors to trust or how to evaluate the work of external contractors, and give you more rules of thumb for your use case that don't rely on a great d...
This post was extremely important but not well executed. The resulting discussion essentially failed to make progress, but it was attempting perhaps the most important question currently on the table: why do some alignment thinkers believe alignment is very difficult, while others think it's fairly easy?
The Doomimir and Simplicia dialogues dialogues did a much better job of refining the key questions, but they may have been inspired by the chaotic discussion this post inspired.
I am torn in nominating this post, because Barnett's rather confrontational and ...
I think the model of "Burnout as shadow values" is quite important and loadbearing in my own model of working with many EAs/Rationalists. I don't think I first got it from this post but I'm glad to see it written up so clearly here.
Fun post, but insofar as it's mostly expository of some basic game theory ideas, I think it doesn't do a good enough job of communicating that the starting assumption is that one is in a contrived (but logically possible) equilibrium. Scott Alexander's example is clearer about this. So I am not giving it a positive vote in the review (though I would for an edited version that fixed this issue).
+4. I most like the dichotomoy of "stick to object level" vs "full contact psychoanalysis." And I think the paragraphs towards the end are important:
...The reason I don't think it's useful to talk about "bad faith" is because the ontology of good vs. bad faith isn't a great fit to either discourse strategy.
If I'm sticking to the object level, it's irrelevant: I reply to what's in the text; my suspicions about the process generating the text are out of scope.
If I'm doing full-contact psychoanalysis, the problem with "I don't think you're here in good faith" is
I have embarrassingly not actually reviewed this, and yet something like this post is probably one of my core worldview principles, and in particular it's use of examples across the industry is refreshing.
+4 for both putting a grounded argument, and being well articulated.
One of my perennial criticisms that LW thankfully is doing better on is undervaluing the power of high-speed stupidity, combined with it's arguments against doing so being surprisingly weak.
(For example, I consider tailcalled's response here to a detailed comment of mine that, if the comm...
While this post didn't yield a comprehensive theory of how fact finding works in neural networks, it's filled with small experimental results that I find useful for building out my own intuitions around neural network computation.
I think that's speaks to how well these experiments are scoped out that even a set of not-globally-coherent findings yield useful information.
A very helpful collection of measures humanity can take to reduce risk from advanced AI systems.
Overall, this post is both detailed and thorough, making it a good read for people who want to learn about potential AI threat models as well as promising countermeasures we can take to avoid them.
This delightful piece applies thermodynamic principles to ethics in a way I haven't seen before. By framing the classic "Ones Who Walk Away from Omelas" through free energy minimization, the author gives us a fresh mathematical lens for examining value trade-offs and population ethics.
What makes this post special isn't just its technical contribution - though modeling ethical temperature as a parameter for equality vs total wellbeing is quite clever. The phase diagram showing different "walk away" regions bridges the gap between mathematical precision and ...
A very promising non-mainstream AI alignment agenda.
Learning-Theoretic Agenda (LTA) attempts to combine empirical and theoretical data, which is a step in the right direction as it avoids a lot of "we don't understand how this thing works, so no amount of empirical data can make it safe" concerns.
I'd like to see more work in the future integrating LTA with other alignment agendas, such as scalable oversight or Redwood's AI control.
While many of the review requirements aren’t applicable to this writing. It doesn’t lessen the impact it has.
This is a horror I would like to avoid. I think Sci-fi of this sort helps to prevent that future. This is something my non-technical Mother could understand. Something I could show people to explain the worst.
I will think of this post as the future goes on. I am desperately trying to make this story one that we look back on and laugh at. “What silly worries” we’ll say. “How naive.”
How do you supervise an AI system that is more capable than its overseer? This is the question this article sets to answer.
It brings together two somewhat different approaches: scalable oversight and weak-to-strong generalization. The article then shows how a unified solution would work under different assumptions (with or without scheming).
Overall, the solution seems quite promising. In the future, I'd like the unified solution to be (empirically) tested and separately compared with just scalable oversight or just weak-to-strong generalization to prove its increased effectiveness.
I hope I will get around to rereading the post and edit this comment to write a proper review, but I'm pretty busy, so in case I don't I now leave this very shitty review here.
I think this is probably my favorite post from 2023. Read the post summary to see what it's about.
I don't remember a lot of the details from the post and so am not sure whether I agree with everything, but what I can say is:
- When I read it several months ago, it seemed to me like an amazingly good explanation for why and how humans fall for motivated reasoning.
- The concept of valence t
Bounded Distrust is an important addition to my personal lexicon, and this is a decent explanation of how to use it with news organizations. Zvi is perhaps a bit cynical, but the thesis is in part that this level of cynicism is warranted.
I haven't been using Bounded Distrust as much when thinking about news organizations, but I do use it when thinking about other vectors for information. (Including people.) That's a bit odd, since the original essays (both Scott's and Zvi's) are very much about news agencies. The general lesson is something like, what ways...
One of the stated purposes of the LessWrong Review is to decide what posts stood the test of time, looking back at the last year. We have yet to do a LessWrong Review that looked back at the last decade, but wouldn't it be awesome if we did?
That's what this essay offers. It's short! I wish it had a little more data, or went into details like what nervous system training was tried (what about Yoga works?) but if the biggest complaint I have about an essay is 'I wish it was longer' that's a really good problem to have!
I'd like to encourage people to wr...
This post was hard for me to read. A few months after I wrote it I developed medical issues that are still ongoing and really sapped my ability to work. Right now I feel on the precipice of developing Large Scale Ambitions, and that I'd probably have taken the plunge to something bigger if I'd hadn't gotten so sick for so long.
On the other hand, I spent the past 2 years trying to dramatically reform Effective Altruism. I expected to quit in May but got sucked back in via my work with Timothy TL. I didn't think of this as ambitious, but looking ...
Solid story. I like it. Contains a few useful frames and is memorable as a story.
I found this post to be a really interesting discussion of why organisms that sexually reproduce have been successful and how the whole thing emerges. I found the writing style, where it switched rapidly between relatively serious biology and silly jokes very engaging.
Many of the sub claims seem to be well referenced (I particularly liked the swordless ancestor to the swordfish liking mates who had had artificial swords attached).
When this paper came out, I don't think the results were very surprising to people who were paying attention to AI progress. However, it's important to the "obvious" research and demos to share with the wider world, and I think Apollo did a good job with their paper.
I enjoyed this but I didn't understand the choice of personality for Alice and Charlie, it felt distracting. I would have liked A&C to have figured out why this particular Blight didn't go multi-system.
I think I was already doing what this post suggested before it was published, but the distilled phrase was good and I thought about it quite often since.
Where it meets me personally - I'm shocked at how Liberals are dropping the ball on Liberalism. It is incredibly important, and yet Liberals don't properly understand it and don't know how to defend it, at a time where it's under an onslaught by anti-liberals. To be slightly glib, I basically believe that everyone is wrong about Liberalism. I don't know of anyone who shares my understanding of it. So I'm trying to finally pick up the ball by writing a book about how to fix Liberalism (and actually, a year ago today is exactly when I began writing it).
Almost two years after writing this post, this is still a concept I encounter relatively often. Maybe less so in myself, as, I like to think, I have sufficiently internalized the idea to not fall into the "fake alternative trap" anymore very often. But occasionally this comes up in conversations with others, when they're making plans, or we're organizing something together.
With some distance, and also based on some of the comments, I think there is room for improvement:
- the Gym membership example is a tricky one, as "getting a gym membership to go to the gy
I love the interior decorating advice, it's quite different from the other posts but is really useful when designing and buying for a new room.
This post is important to setting a lower bound on AI capabilities required for an AI takeover or pivotal act. Biology as an existence proof that some kind of "goo" scenario is possible. It somewhat lowers the bar compared to Yudkowsky's dry nanotech scenario but still requires AI to practically build an entire scientific/engineering discipline from scratch. Many will find this implausible.
Digital tyranny is a better capabilities lower bound for a pivotal act or AI takeover strategy. It wasn't nominated though which is a shame.
I really like the idea of creating a Good ABC book, and the author executed it well. Out of the recreational posts of 2023, this is the one I've liked the most. I can't articulate why exactly, but the visuals are great, it Creates A Thing, and it's an example of things I'd like there to be more in the world. It inspired me create my own version. I give it a +9 for the 2023 review.
I wrote this after watching Oppenheimer and noticing with horror that I wanted to emulate the protagonist in ways entirely unrelated to his merits. Not just unrelated but antithetical: cargo-culting the flaws of competent/great/interesting people is actively harmful to my goals! Why would I do this!? The pattern generalized, so I wrote a rant against myself, then figured it'd be good for LessWrong, and posted it here with minimal edits.
I think the post is crude and messily written, but does the job.
Meta comment: I notice I'm surprised that out ...
This argument against subagents is important and made me genuinely less confused. I love the concrete pizza example and the visual of both agent's utility in this post. Those lead me to actually remember the technical argument when it came up in conversation.
In this post Matthew Barnett notices that we updated our beliefs between ~2007 and ~2023. I say "we" rather than MIRI or "Yudkowsky, Soares, and Bensinger" because I think this was a general update, but also to defuse the defensive reactions I observe in the comments.
What did we change our mind about? Well, in 2007 we thought that safely extracting approximate human values into a convenient format would be impossible. We knew that a superintelligence could do this. But a superintelligence would kill us, so this isn't helpful. We knew that human values are ...
I followed up on this with a year exploring various rationality exercises and workshops. My plans and details have evolved a bunch since then, but I still think the opening 7 bullets (i.e. "Deliberate Practice, Metacognition" etc, with "actually do the goddamn practice" and "the feedbackloop is the primary product") are quite important guiding lights.
I've written up most of my updates as they happened over the year, in:
...For the 2023 review, I'd give it a +9, and perhaps even higher here, mostly due to the well-presented way that the review was structured, and most importantly has for all intents and purposes dissolved a lot of confusions around vexing questions, and the stuff it gets wrong is patchable such that the theory broadly works.
It's an excellent example of taking a confused question and dissolving it, and I'll probably refer to this in the future.
Now onto the review itself:
I broadly agree with Anil Seth's framing of the situation on consciousness, but unlike him,...
A practical exercise which is both fun and helps me think better? Sign me up.
I definitely enjoyed doing thinking physics exercises in my free time, they feel similar to chess in the way that they're a fun activity to do in my free time while also making me feel like I'm spending my time doing something really useful, which is really great to feel.
They also provide a tangible way of seeing your "prediction ability" for your own thinking and planning improve, which is helpful in staying motivated in regard to self-improvement exercises.
I can recommend to anyone on the fence about this to try their hands at a few thinking physics exercises!
I had a vaguely favorable reaction to this post when it was first posted.
When I wrote my recent post on corrigibility, I grew increasingly concerned about the possible conflicts between goals learned during pretraining and goals that are introduced later. That caused me to remember this post, and decide it felt more important now than it did before.
I'll estimate a 1 in 5000 chance that the general ideas in this post turn out to be necessary for humans to flourish.
...For those who don't want to, the gist is: Given the same level of specificity, people will naturally give more credit to the public thinker that argues that society or industry will change, because it's easy to recall active examples of things changing and hard to recall the vast amount of negative examples where things stayed the same. If you take the Nassim Taleb route of vapidly predicting, in an unspecific way, that interesting things are eventually going to happen, interesting things will eventually happen and you will be revered as an oracle. If you
I wish more people 1. tried practicing the skills and techniques they think are important as rationalists and 2. reported back on how it went. Thank you Olli for doing so and writing up what happened!
Being well calibrated is something I aspire to, and so the advice on particular places where one might stumble (pointing out the >90% region is difficult, pointing out that ones gut may get anchored on a particular percentage for no good reason, pointing out switching domains threw things off for a little) is helpful. I'm a little nervous about how changing...
This is an important topic, about which I find it hard to reason and on which I find the reasoning of others to be lower quality than I would like, given its significance. For that reason I find this post valuable. It would be great if there were longer, deeper takes on this issue available on LW.
The complaints I remember about this post seem mostly to be objecting to how some phrases were distilled into the opening short "guideline" section. When I go reread the details it mostly seems fine. I have suggestions on how to tweak it.
(I vaguely expect this post to get downvotes that are some kind of proxy for vague social conflict with Duncan, and I hope people will actually read what's written here and vote on the object level. I also encourage more people to write up versions of The Basics of Rationalist Discourse as they seem them)
The things I'd wan...
I have listened to this essay about 3 times and I imagine I might do so again. Has been a valuable addition to my thinking about whether people have contact with reality and what their social goals might be.
I have used this dichotomy, 5 - 100 times during the last few years. I am glad it was brought to my attention.
I didn't keep good track of them, but this post led to me receiving many DMs that it had motivated someone to get tested. I also occasionally indirectly hear about people who got tested, so I think the total impact might be up to 100 people, of which maybe 1/3 had a deficiency (wide confidence intervals on both numbers). I'm very happy with that impact.
I do wish I'd created a better title. The current one is very generic, and breaks LW's "aim to inform not persuade" guideline.
Another piece of the "how to be okay in the face of possible existential loss" puzzle. I particularly liked the "don't locate your victory conditions inside people/things you can't control" frame. (I'd heard that elsewhere I think but it felt well articulated here)
I appreciated both this and Mako Yass' Cohabitive Games so Far (I believe Screwtape's post actually introduced the term "cohabitive", which Mako adopted). I think both posts
I have an inkling that cohabitive games may turn out to be important for certain kinds of AI testing and evaluation – can an AI not only win games with rutheless optimization, but also be a semi-collaborative player in an opended context? (This idea is shaped in part by some ideas I got reading about Encultured)
A simple but important point, that has shaped my frame for how to be an emotionally healthy and productive person, even if the odds seem long.
I'm nominating this! On skimming, this is a very readable dialogue with an AI about ethics, lots of people seem to have found it valuable to read. I hope to give it a full read and review in the review period.
I appreciated reading this layout of a perspective for uncollaborative truth-seeking discourse, even though I disagree with many parts of it. I'll give it a positive vote here in the last two hours of the nominations period, I hope someone else gives it one too.
A dissenting voice on info-hazards. I appreciate the bulleted list starting of premises and building towards conclusions. Unfortunately I don't think all the reasoning holds up to close scrutiny. For example, the conclusion that "infohoarders are like black holes for infohazards" conflicts with the premise that "two people can keep a secret if one of them is dead". The post would have been stronger if it had stopped before getting into community dynamics.
Still, this post moved and clarified my thinking. My sketch at a better argument for a similar conclusi...
This post presented the idea of RSPs and detailed thoughts on them, just after Anthropic's RSP was published. It's since become clear that nobody knows how to write an RSP that's predictably neither way too aggressive nor super weak. But this post, along with the accompanying Key Components of an RSP, is still helpful, I think.
This is the classic paper on model evals for dangerous capabilities.
On a skim, it's aged well; I still agree with its recommendations and framing of evals. One big exception: it recommends "alignment evaluations" to determine models' propensity for misalignment, but such evals can't really provide much evidence against catastrophic misalignment; better to assume AIs are misaligned and use control once dangerous capabilities appear, until much better misalignment-measuring techniques appear.
I like this essay. I am not a paladin and do not particularly plan to become one. I do not think all the people setting out to maximize utility would stand behind this particular version of the rallying cry.
But I do think paladins exist, I want them to have a rallying cry, and when it works — when they do manage to point themselves at the right target, and are capable of making a dent, then I appreciate that they exist and chose to do that. I also appreciate the "if you want to save the world, then here's how" framing.
I don't quite think someone coul...
+4. This doesn't offer a functional proposal, but it makes some important points about the situation and offers an interesting reframe, and I hope it gets built upon. Key paragraph:
In other words: from a libertarian perspective, it makes really quite a lot of sense (without compromising your libertarian ideals even one iota) to look at the AI developers and say "fucking stop (you are taking far too much risk with everyone else's lives; this is a form of theft until and unless you can pay all the people whose lives you're risking, enough to offset the risk)".
I think this is a pretty good post that makes a point some people should understand better. There is, however, something I think it could've done better. It chooses a certain gaussian and log-normal distribution for quality and error, and the way that's written sort of implies that those are natural and inevitable choices.
I would have preferred something like:
...Suppose we determine that quality has distribution X and error has distribution Y. Here's a graph of those superimposed. We can see that Y has more of a fat tail than X, so if measured quality is ve
I still think this post is cool. Ultimately, I don't think the evidence presented here bares that strongly on the underlying question: "can humans get AIs to do their alignment homework?". But I think it bares on it at all, and was conducted quickly and competently.
I would like to live in a world where lots of people gather lots of weak pieces of evidence on important questions.
It does seem worth having a term here! +4 for pointing it out and the attempt.
I think the analogy in this post makes a great point v clearly, and improves upon the discussion of how those who control the flow of information mislead people. +4
I have various disagreements with some of the points in this post, and I don't think it adds enough new ideas to be strongly worthy of winning the annual review, but I am grateful to have read it, and for worthwhile topics it helps to retread the same ground in slightly different ways with some regularity. I will give this a +1 vote.
(As an example disagreement, there's a quote of a fictional character saying "There will be time enough for love and beauty and joy and family later. But first we must make the world safe for them." A contrary hypothesis I beli...
Interesting point, written up really really well. I don't think this post was practically useful for me but it's a good post regardless.
(Self Review) I stand by this post, and if the Best Of LessWrong posts are posts we want everyone in the community to have read then this seems worth the space.
Tapping out is a piece of rationalist jargon that has a definition in the LessWrong tags and has been used in the community for years, but doesn't really have a canonical post explaining why we use it. The tag definition is a good explanation of what it means and it's shorter, which is good. I think tapping out is a good and useful tool when having debates or discussions, and it's one that works bes...
(Brief self-review for LW 2023 review.)
Obviously there's nothing original in my writeup as opposed to the paper it's about. The paper still seems like an important one, though I haven't particularly followed the literature and wouldn't know if it's been refuted or built upon by other later work. In particular, in popular AI discourse one constantly hears things along the lines of "LLMs are just pushing symbols around and don't have any sort of model of the actual world in them", and this paper seems to me to be good evidence that transformer networks, even...
As AI continues to accelerate, the central advice presented in this post to be at peace with doom will become incresingly important to help people stay sane in a world where it may seem like there is no hope. But really there is hope so long as we keep working to avert doom, even if it's not clear how we do that, because we've only truly lost when we stop fighting.
I'd really like to see more follow up on the ideas made in this post. Our drive to care is arguably why we're willing to cooperate, and making AI that cares the same way we do is a potentially viable path to AI aligned with human values, but I've not seen anyone take it up. Regardless, I think this is an important idea and think folks should look at it more closely.
I found this post to be incredibly useful to get a deeper sense of Logan's work on naturalism.
I think his work on Naturalism is a great and unusual example of original research happening in the rationality community and what actually investigating rationality looks like.
This was an intriguing read. Initially, kindness seems to deteriment both sides, but over time and battles, the ants find a way to use the grasshoppers without either being fully destroyed. The real question is whether the grasshopper is still itself, despite its consciousness being taken by the ants. In my opinion, the ants should have massacred all of the grasshoppers as food and eliminated the issue completely, but that discounts their feelings and survival. If they assisted in gathering food together, I think it would have worked as a symbiotic relationship.
You're encouraged to write a self-review, exploring how you think about the post today. Do you still endorse it? Have you learned anything new that adds more depth? How might you improve the post? What further work do you think should be done exploring the ideas here?
Still endorse. Learning about SIA/SSA from the comments was interesting. Timeless but not directly useful, testable or actionable.
I am 60 yrs old and I have never heard it claimed that salt reduces the time it takes to cook pasta. However, I have observed that it does bring the water to a boil faster, which reduces overall cooking time.
I love this kind of post which gives a name to a specific behavior and also gives good examples for identifying it. They feel very validating for noticing the same fallacy that annoys me, but which I encounter so infrequently that it's hard to notice any pattern and articulate what feels wrong about it.
Good reference for decorating in an intentional manner, I really like these kinds of posts discussing various aspects we tend to just do automatically, and bring a "smarter" way to approach them. It made me reconsider the importance of lighting in my room and helped me realize that "oh, yeah, that's actually important, and this is actually a good idea! I'll do that." I hope we can start seeing more posts like this.
A new method for reducing sycophancy. Sycophantic behavior is present in quite a few AI threat models, so it's an important area to work on.
The article not only uses activation steering to reduce sycophancy in AI models but also provides directions for future work.
Overall, this post is a valuable addition to the toolkit of people who wish to build safe advanced AI.
This post (and the accompanying paper) introduced empirical benchmarks for detecting "measurement tampering" - when AI systems alter measurements used to evaluate them.
Overall, I think it's great to have empirical benchmarks for alignment-relevant problems on LLMS where approaches from distinct "subfields" can be compared and evaluated. The post and paper do a good job of describing and motivating measurement tampering, justifying the various design decisions (though some of the tasks are especially convoluted).
A few points of criticism:
- the d...
Perhaps I am missing something, but I do not understand the value of this post. Obviously you can beat something much smarter than you if you have more affordances than it does.
FWIW, I have read some of the discourse on the AI Boxing game. In contrast, I think those posts are valuable. They illustrate that even with very little affordances a much more intelligent entity can win against you, which is not super intuitive especially in the boxed context.
So the obvious question is, how does differences in affordances lead to differences in winning (i.e.,...
This is an enjoyable, somewhat humorous summary of a very complicated topic, spanning literally billions of years. So it naturally skips and glosses over a bunch of details, while managing to give relatively simple answers to:
- why sex
- why 2 sexes
- why have one sex bigger than the other
I really appreciated the disclaimers at the top - every time I discuss biology, I bump into these limitations, so it's very appropriate for an intro article to explicitly state them.
The post makes clear that two very different models of the world will lead to very different action steps, and the "average" of those steps isn't what follows the average of probabilities. See how the previous sentence felt awkward and technical, compared to the story? Sure, it's much longer, but the point gets across better, that's the value. I have added this story to my collection of useful parables.
Re-reading it, the language remains technical, one needs to understand a bit more probability theory to get the latter parts. I would like to see a retelling of the story, same points, different style, to test if it speaks to a different audience.
TL; DR: This post gives a good summary of how models can get smarter over time, but while they are superhuman at some tasks, they can still suck at others (see the chart with Naive Scenario v. Actual performance). This is a central dynamic in the development of machine intelligence and deserves more attention. Would love to hear other's thoughts on this—I just realized that it needed one more positive vote to end up in the official review.
In other words, current machine intelligence and human intelligence are compliments, and human + AI will be more produc...
I think this post brought up some interesting discussion and I'm glad I made it. Not sure if it's 'best of 2023' material but I liked the comments/responses quite a bit and found them enlightening.
I recall thinking this article got a lot right.
I remain confused about the non-linear stuff, but I have updated to thinking that norms should be that stories are accurate not merely informative with caveats given.
I am glad people come into this community to give critique like this.
Anthropic releasing their RSP was an important change in the AI safety landscape. The RSP was likely a substantial catalyst for policies like RSPs—which contain if-then commitments and more generally describe safety procedures—becoming more prominent. In particular, OpenAI now has a beta Preparedness Framework, Google DeepMind has a Frontier Safety Framework but there aren't any concrete publicly-known policies yet, many companies agreed to the Seoul commitments which require making a similar policy, and SB-1047 required safety and security protocols.
Howev... (read more)